关于git flow的一点思考
本文首发自我的公众号:成都有娃儿,这里把三篇文章合一,方便阅读。
现在相当多的公司或者团队都在使用git来做版本控制,结合我这些年的工作经历,我总结了一些个人认为不错的使用规范和习惯。
脱离背景来讲规范有点不切实际,为了更好的阐述不同公司的做法,我们假设存在三种不同情况的公司和项目,分别来说说可能出现的最佳实践。
第一种情况是创业型公司,基于Scrum的方式来做敏捷开发。假设有多人需要在同一个分支A上进行开发,那么为了更好的协作,可以采取如下的git操作:
当完成编程工作后,先pull当前分支的远程代码,即git pull origin A。
然后可能出现两种情况,没有冲突直接就pull成功,这个时候可以继续完成commit操作,然后进行push到远程仓库。还有一种可能是有冲突,无法自动完成pull操作,那么先撤销pull操作,把当前的修改先git stash,然后再重新git pull origin A,之后再git stash pop出修改到当前工作区,解决完冲突后再进行commit,最后push。先pull的好处在于不会让pull直接覆盖掉你本次修改,从而导致代码缺失。
简单总结一下:先pull,再commit,最后push。
第二种情况是分支管理比较清晰的公司,也是基于Scrum方式来开展迭代任务。
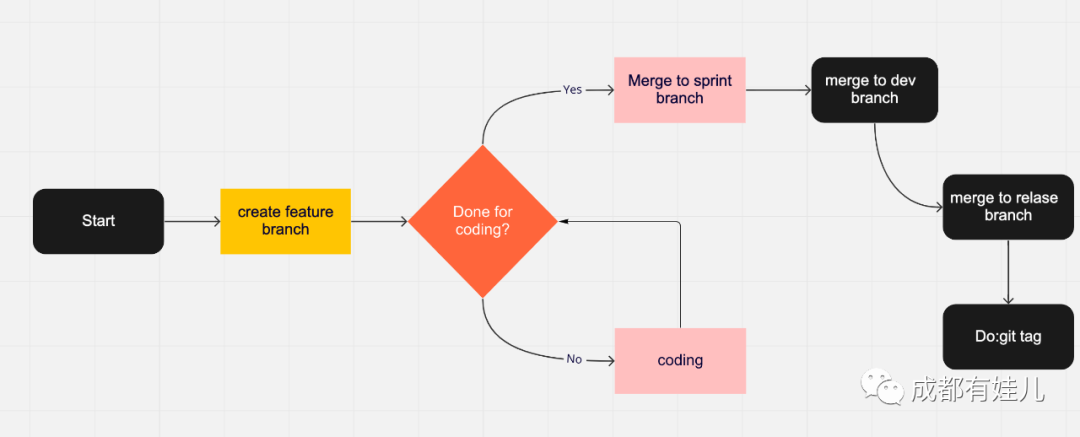
一般来说分成dev分支,master分支(或者叫relase分支)。dev用于测试环境的部署,release分支用于线上生产环境的部署。
根据不同的需求类型,分别建立不同的需求分支。比如针对bug修复的,创建以”bug/“作为开头的分支,如bug/MYAPP-3101。针对新功能创建如”feature/MYAPP-3102“,看到前缀就能知道这个分支的用途。
如果需求分支开发完毕,那么就可以往dev分支上合并。当dev分支在测试环境被QA测试完毕无问题后,那么可以再合并relase分支。如果想对版本进行细腻的标记,那么还可以使用git tag来记录版本号,方便版本回退和管理。并且这个tag出来的版本是不可修改的,方便运维去部署不同的代码库版本。
常规的流程是这样的,但是如果出现一个sprint周期里面feature比较多,可以考虑单独创建一个sprint分支用来在开发和测试环境里面去合并需求分支,这样不会因为有一些代码还没确定要发布的情况下被直接合并到dev分支,要知道计划总有变化。
为了更直观地展示这个git flow的过程,我画了一个流程图。
最后一种是比较混乱的分支管理方式,但是简单粗暴。
有一个dev分支和master分支,所有人都在dev分支上直接开发。所以会出现很多合并代码的冲突,也会有一些需求因为最终没有上线而被丢弃。经过一系列忙碌的测试和验证后,最终dev会被合并到master。然后所有研发人员又会奔赴下一次迭代周期里面。
为了解决部分代码上线的问题,只能依靠cherry pick的方式去把真正需要上线的代码修改筛选出来。
最大的问题还在于频繁地人工审查和合并,代码就像面条一样搅在一起,让代码合并和发布变成了一种心智和体力双重负担,有的公司甚至在一个团队里面不得不安排一个单独的人来专门处理代码合并的事情。我不是不认可这种角色的存在,如果是一个复杂的系统,且开发人员较多,有一个资深的研发人员去做代码审核,顺便merge代码是很有必要的。但是如果merge代码成为了一个为混乱而四处救火的事情,那么就要思考一下git flow是否设计有比较大的缺陷。
在这种如同战火纷飞一样混乱的情况下,关于代码的保存就必须依靠程序员自己了,这有点开历史倒车,回到了被csv或者svn支配的年代。
针对这些问题,我建议是想办法尽快转向我上一篇文章说的分支管理方式:把feature分支建立好,完成各个功能模块的研发工程师分别创建对应的feature分支,等自测完成后,再合并到dev分支或者sprint分支,我个人认为有个sprint分支是最好的,测试完毕后再合并到master分支去线上部署。
每一个分支就像一个收纳盒,把稳定的代码变化放在其中,最后再几个盒子一起打包部署。有序,可拆解,按需部署,不是更好?


