關於git flow的一點思考
本文首發自我的公眾號:成都有娃兒,這裡把三篇文章合一,方便閱讀。
現在相當多的公司或者團隊都在使用git來做版本控制,結合我這些年的工作經歷,我總結了一些個人認為不錯的使用規範和習慣。
脫離背景來講規範有點不切實際,為了更好的闡述不同公司的做法,我們假設存在三種不同情況的公司和項目,分別來說說可能出現的最佳實踐。
第一種情況是創業型公司,基於Scrum的方式來做敏捷開發。假設有多人需要在同一個分支A上進行開發,那麼為了更好的協作,可以採取如下的git操作:
當完成編程工作後,先pull當前分支的遠程代碼,即git pull origin A。
然後可能出現兩種情況,沒有衝突直接就pull成功,這個時候可以繼續完成commit操作,然後進行push到遠程倉庫。還有一種可能是有衝突,無法自動完成pull操作,那麼先撤銷pull操作,把當前的修改先git stash,然後再重新git pull origin A,之後再git stash pop出修改到當前工作區,解決完衝突後再進行commit,最後push。先pull的好處在於不會讓pull直接覆蓋掉你本次修改,從而導致代碼缺失。
簡單總結一下:先pull,再commit,最後push。
第二種情況是分支管理比較清晰的公司,也是基於Scrum方式來開展迭代任務。
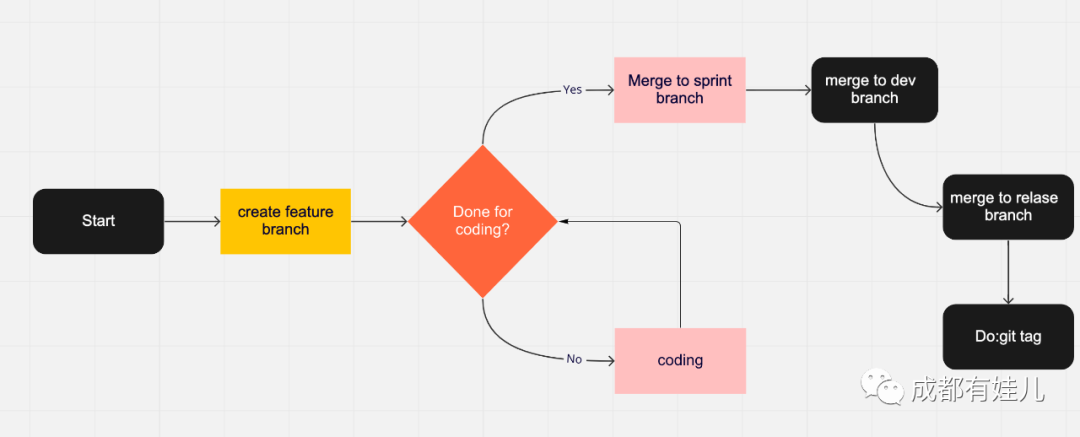
一般來說分成dev分支,master分支(或者叫relase分支)。dev用於測試環境的部署,release分支用於線上生產環境的部署。
根據不同的需求類型,分別建立不同的需求分支。比如針對bug修復的,創建以」bug/「作為開頭的分支,如bug/MYAPP-3101。針對新功能創建如」feature/MYAPP-3102「,看到前綴就能知道這個分支的用途。
如果需求分支開發完畢,那麼就可以往dev分支上合併。當dev分支在測試環境被QA測試完畢無問題後,那麼可以再合併relase分支。如果想對版本進行細膩的標記,那麼還可以使用git tag來記錄版本號,方便版本回退和管理。並且這個tag出來的版本是不可修改的,方便運維去部署不同的代碼庫版本。
常規的流程是這樣的,但是如果出現一個sprint周期裏面feature比較多,可以考慮單獨創建一個sprint分支用來在開發和測試環境裏面去合併需求分支,這樣不會因為有一些代碼還沒確定要發佈的情況下被直接合併到dev分支,要知道計劃總有變化。
為了更直觀地展示這個git flow的過程,我畫了一個流程圖。
最後一種是比較混亂的分支管理方式,但是簡單粗暴。
有一個dev分支和master分支,所有人都在dev分支上直接開發。所以會出現很多合併代碼的衝突,也會有一些需求因為最終沒有上線而被丟棄。經過一系列忙碌的測試和驗證後,最終dev會被合併到master。然後所有研發人員又會奔赴下一次迭代周期裏面。
為了解決部分代碼上線的問題,只能依靠cherry pick的方式去把真正需要上線的代碼修改篩選出來。
最大的問題還在於頻繁地人工審查和合併,代碼就像麵條一樣攪在一起,讓代碼合併和發佈變成了一種心智和體力雙重負擔,有的公司甚至在一個團隊裏面不得不安排一個單獨的人來專門處理代碼合併的事情。我不是不認可這種角色的存在,如果是一個複雜的系統,且開發人員較多,有一個資深的研發人員去做代碼審核,順便merge代碼是很有必要的。但是如果merge代碼成為了一個為混亂而四處救火的事情,那麼就要思考一下git flow是否設計有比較大的缺陷。
在這種如同戰火紛飛一樣混亂的情況下,關於代碼的保存就必須依靠程序員自己了,這有點開歷史倒車,回到了被csv或者svn支配的年代。
針對這些問題,我建議是想辦法儘快轉向我上一篇文章說的分支管理方式:把feature分支建立好,完成各個功能模塊的研發工程師分別創建對應的feature分支,等自測完成後,再合併到dev分支或者sprint分支,我個人認為有個sprint分支是最好的,測試完畢後再合併到master分支去線上部署。
每一個分支就像一個收納盒,把穩定的代碼變化放在其中,最後再幾個盒子一起打包部署。有序,可拆解,按需部署,不是更好?


