Reasoning with Latent Structure Refinement for Document-Level Relation Extraction 论文笔记
Background
-
论文动机
-
现有的方法基于语法树(syntactic tress)、公指(co-references)或启发式方法(heuristics)来构建静态文档级图,以建模非结构化文本的依赖关系。
-
对于文档关系抽取来说,模型需要丰富的非局部信息交互以此来推断两个实体之间的关系。

-
问题定义
The document-level relation extraction, where a system needs to ==comprehend multiple sentences to infer the relations== among entities by synthesizing relevant information from the entire document(文档层面的关系提取,模型需要理解多个句子,通过整合整个文档的相关信息来推断实体之间的关系)
-
解决办法
- 多实例学习
- 使用结构信息建模非局部依赖关系
- dependency graph
- heterorgeneous graph(异质图)
-
-
-
论文贡献
- 通过学习归纳一个动态潜在的文档级图(Inducing the latent document-level)来赋予跨句子的关系推理能力,本文将图结构视为一个潜在变量,并以端到端的方式对其进行归纳。(以往无法捕捉==rich non-local interactions==进行推理)
- 模型建立在结构化注意力的基础上,基于变体的矩阵树定理,能够==生成任务特定的依赖结构==,以此来捕获实体之间的非局部交互。
- 提出一种==refinement strategy==,使模型基于上一次迭代dynamically construct a latent structure 汇聚相关的信息,不断地通过迭代捕获复杂的交互信息,改进整个文档中的信息聚合,从而更好地进行多跳推理(multi-hop reasoning)
LSR构建了一个同质网络,不区分边的类型,通过节点信息的传播来更新边的表示,通过动态更新自动的学习到哪些边更重要,从而增强对远程关系的推理能力。

Model
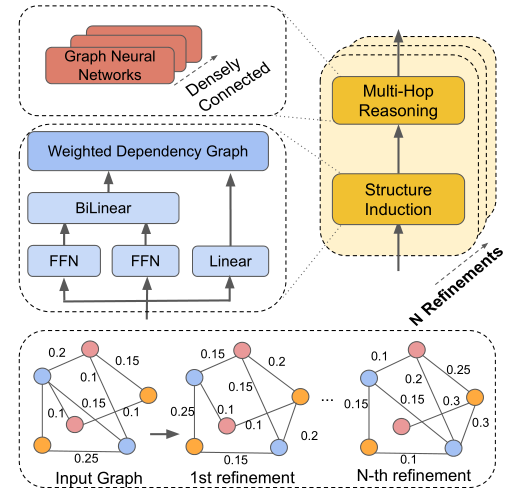
概述:Treats the ==graph structure as a latent variable==
- Our model based on the structured attention.
- 使用 A variant of Matrix-Tree Theorem生成 task-specific dependency structures去捕获非局部的实体信息交互。
- An iterative refinement strategy: the latent structures based on the last iterative,使模型逐渐capture the complex interactions.
Node Constructor: Encoding each sentence of a document and outputs contextual representations,which correspond to mentions and tokens on the SDP are extracted as nodes

-
文本编码-bi-LSTM:使用两个方向的隐藏层向量的拼接作为token的向量(非常正常的操作 😎)
-
节点构造
Mention nodes : correspond to different mentions of entities in each sentence.()
Entity nodes: The entity node ==is computed as the average of its mentions.==
meta dependency path (MDP 元依赖路径) nodes
method 1 Use all nodes in the dp-based tree of a sentence method 2 One sentence-level node by averaging all token representation method 3 Use tokens on SDP between mentions in the sentence To build a document-level graph
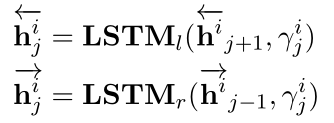
Dynamic Reasoner
-
Structure Induction(归纳结构):Used to ==learn a latent structure== of a document-level graph 结构归纳模块用于学习文档级图的潜在结构。
基于structured attention和Matrix-Tree Theorem构建潜在依赖结构:
-
计算pair-wise attention score,LSR对于不同的节点之间采用相同的方式来计算概率,作为边的表示;
\mathbf{s}_{i j}=\left(\tanh \left(\mathbf{W}_{p} \mathbf{u}_{i}\right)\right)^{T} \mathbf{W}_{b}\left(\tanh \left(\mathbf{W}_{c} \mathbf{u}_{j}\right)\right)
可以理解为利用attention的方式计算两个节点之间的关联度。\mathbf{W}_{b}是双线性变换的权值。
-
计算root score,表示节点i有多大的概率(probability)成为结构中的the root node.
\mathbf{s}_{i}^{r}=\mathbf{W}_{r} \mathbf{u}_{i}
-
计算 ==The weight of the edge between the i-th and j-th,==第i个节点和第j个节点之间的边的权重。
\mathbf{P}_{i j}=\left\{\begin{array}{ll}0 & \text { if } i=j \\ \exp \left(\mathbf{s}_{i j}\right) & \text { otherwise }\end{array}\right.
-
我们定义拉普拉斯矩阵L以及其变体\hat{L}
\mathbf{L}_{i j}=\left\{\begin{array}{ll}\sum_{i^{\prime}=1}^{n} \mathbf{P}_{i^{\prime} j} & \text { if } i=j \\ -\mathbf{P}_{i j} & \text { otherwise }\end{array}\right.
\hat{\mathbf{L}}_{i j}=\left\{\begin{array}{ll}\exp \left(\mathbf{s}_{i}^{r}\right) & \text { if } i=1 \\ \mathbf{L}_{i j} & \text { if } i>1\end{array}\right.
-
最后计算邻接矩阵A_{ij}(文档级实体图的加权邻接矩阵)
\begin{aligned} \mathbf{A}_{i j}=&\left(1-\delta_{1, j}\right) \mathbf{P}_{i j}\left[\hat{\mathbf{L}}^{-1}\right]_{i j} \\ &-\left(1-\delta_{i, 1}\right) \mathbf{P}_{i j}\left[\hat{\mathbf{L}}^{-1}\right]_{j i} \end{aligned}
\mathbf{A} \in \mathbb{R}^{n \times n}是weighted adjacency matrix of the document level entity graph.
-
-
Multi-hop Reasoning: Used to perform inference on the induced latent structure. 多跳推理模块用于对潜在结构进行推理,根据图中节点的信息聚合更新每个节点的表示。
Give G with n node, which represented with an n*n adjacency matrix A.
\mathbf{u}_{i}^{l}=\sigma\left(\sum_{j=1}^{n} \mathbf{A}_{i j} \mathbf{W}^{l} \mathbf{u}_{i}^{l-1}+\mathbf{b}^{l}\right)
使用==dense connections== to the GCNs in order to ==capture more structural information on large graph.==:
为什么使用dense connections ?
理解: 使用了多层图网络密集连接,以便在大型文档级图上捕获更多的结构信息。在密集连接的帮助下,能够训练一个更深层次的模型,捕捉更丰富的局部和非局部信息,以学习更好的图表示。这个密集连接的图网络和多头注意力机制的原理相似,而联想到图中边是根据两个节点经过注意力计算得到的,可以推测密集连接和多头注意力的效果相似,可以捕获图中不同的特征信息。
-
Iterative Refinement(迭代更新): Refine the latent document-level graph for the better reasoning.
Stacking N blocks of the dynamic reasoner in order to induce the document-level structure N times.
更直观说,最初的浅层结构在最初迭代的时候大部分的信息来自相邻的邻居信息,随着迭代的进行—>
The induction module is able to generate a more informative structure.
为了能够推断出超出简单父子关系的更丰富的结构信息,使用N个动态推理块来多次归纳文档级结构。通过与更丰富的非局部信息的交互,结构变得更加细化,归纳模块能够生成更合理的结构。

Classifier
P\left(r \mid \mathbf{e}_{i}, \mathbf{e}_{j}\right)=\sigma\left(\mathbf{e}_{i}^{T} \mathbf{W}_{\mathbf{e}} \mathbf{e}_{j}+\mathbf{b}_{e}\right)_{r}
\mathbf{W}_{e} \in \mathbb{R}^{d \times k \times d} and \mathbf{b}_{e} \in \mathbb{R}^{k},其中 k 是关系类别总数。
Experiment
-
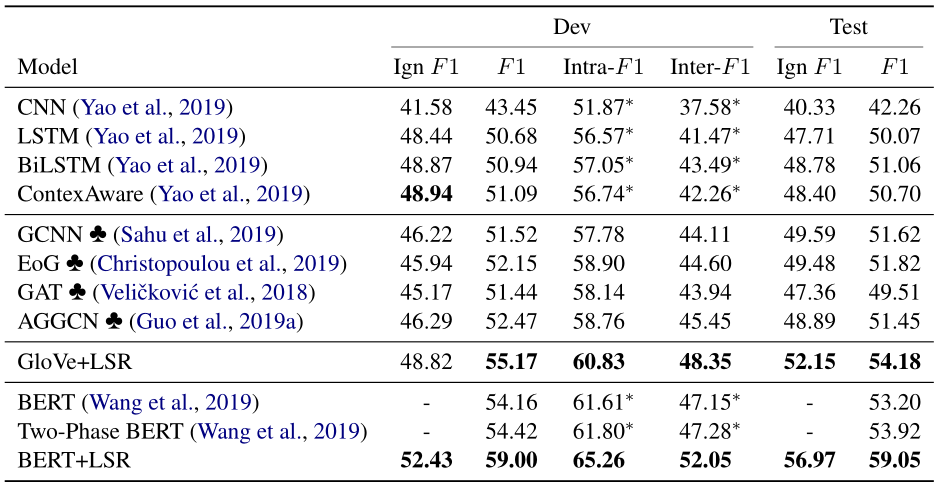
实验数据集
**DocRED&CDR(**Chemical-Disease Reactions )&GDA(Gene-Disease Associations)(后两者是医学数据集)其中DocRED超过40%的关系事实需要对多个句子进行阅读和推理,所以DocRED与以前的句子级别数据集有显着差异。
-
对照实验
Sequence-based Models ContextAware/BiLSTM/CNN Graph-Based Models GCNN/EoG/AGGCN/GAT BERT-Based Models Fine-tune BERT/Two-Phase BERT -
实验结果