Reasoning with Latent Structure Refinement for Document-Level Relation Extraction 論文筆記
Background
-
論文動機
-
現有的方法基於語法樹(syntactic tress)、公指(co-references)或啟發式方法(heuristics)來構建靜態文檔級圖,以建模非結構化文本的依賴關係。
-
對於文檔關係抽取來說,模型需要豐富的非局部信息交互以此來推斷兩個實體之間的關係。

-
問題定義
The document-level relation extraction, where a system needs to ==comprehend multiple sentences to infer the relations== among entities by synthesizing relevant information from the entire document(文檔層面的關係提取,模型需要理解多個句子,通過整合整個文檔的相關信息來推斷實體之間的關係)
-
解決辦法
- 多實例學習
- 使用結構信息建模非局部依賴關係
- dependency graph
- heterorgeneous graph(異質圖)
-
-
-
論文貢獻
- 通過學習歸納一個動態潛在的文檔級圖(Inducing the latent document-level)來賦予跨句子的關係推理能力,本文將圖結構視為一個潛在變量,並以端到端的方式對其進行歸納。(以往無法捕捉==rich non-local interactions==進行推理)
- 模型建立在結構化注意力的基礎上,基於變體的矩陣樹定理,能夠==生成任務特定的依賴結構==,以此來捕獲實體之間的非局部交互。
- 提出一種==refinement strategy==,使模型基於上一次迭代dynamically construct a latent structure 匯聚相關的信息,不斷地通過迭代捕獲複雜的交互信息,改進整個文檔中的信息聚合,從而更好地進行多跳推理(multi-hop reasoning)
LSR構建了一個同質網絡,不區分邊的類型,通過節點信息的傳播來更新邊的表示,通過動態更新自動的學習到哪些邊更重要,從而增強對遠程關係的推理能力。

Model
概述:Treats the ==graph structure as a latent variable==
- Our model based on the structured attention.
- 使用 A variant of Matrix-Tree Theorem生成 task-specific dependency structures去捕獲非局部的實體信息交互。
- An iterative refinement strategy: the latent structures based on the last iterative,使模型逐漸capture the complex interactions.
Node Constructor: Encoding each sentence of a document and outputs contextual representations,which correspond to mentions and tokens on the SDP are extracted as nodes

-
文本編碼-bi-LSTM:使用兩個方向的隱藏層向量的拼接作為token的向量(非常正常的操作 😎)
-
節點構造
Mention nodes : correspond to different mentions of entities in each sentence.()
Entity nodes: The entity node ==is computed as the average of its mentions.==
meta dependency path (MDP 元依賴路徑) nodes
method 1 Use all nodes in the dp-based tree of a sentence method 2 One sentence-level node by averaging all token representation method 3 Use tokens on SDP between mentions in the sentence To build a document-level graph
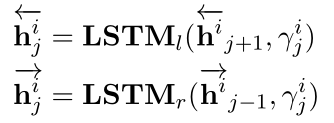
Dynamic Reasoner
-
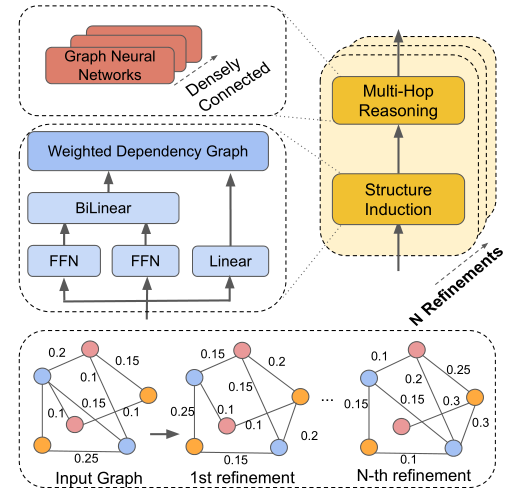
Structure Induction(歸納結構):Used to ==learn a latent structure== of a document-level graph 結構歸納模塊用於學習文檔級圖的潛在結構。
基於structured attention和Matrix-Tree Theorem構建潛在依賴結構:
-
計算pair-wise attention score,LSR對於不同的節點之間採用相同的方式來計算概率,作為邊的表示;
\mathbf{s}_{i j}=\left(\tanh \left(\mathbf{W}_{p} \mathbf{u}_{i}\right)\right)^{T} \mathbf{W}_{b}\left(\tanh \left(\mathbf{W}_{c} \mathbf{u}_{j}\right)\right)
可以理解為利用attention的方式計算兩個節點之間的關聯度。\mathbf{W}_{b}是雙線性變換的權值。
-
計算root score,表示節點i有多大的概率(probability)成為結構中的the root node.
\mathbf{s}_{i}^{r}=\mathbf{W}_{r} \mathbf{u}_{i}
-
計算 ==The weight of the edge between the i-th and j-th,==第i個節點和第j個節點之間的邊的權重。
\mathbf{P}_{i j}=\left\{\begin{array}{ll}0 & \text { if } i=j \\ \exp \left(\mathbf{s}_{i j}\right) & \text { otherwise }\end{array}\right.
-
我們定義拉普拉斯矩陣L以及其變體\hat{L}
\mathbf{L}_{i j}=\left\{\begin{array}{ll}\sum_{i^{\prime}=1}^{n} \mathbf{P}_{i^{\prime} j} & \text { if } i=j \\ -\mathbf{P}_{i j} & \text { otherwise }\end{array}\right.
\hat{\mathbf{L}}_{i j}=\left\{\begin{array}{ll}\exp \left(\mathbf{s}_{i}^{r}\right) & \text { if } i=1 \\ \mathbf{L}_{i j} & \text { if } i>1\end{array}\right.
-
最後計算鄰接矩陣A_{ij}(文檔級實體圖的加權鄰接矩陣)
\begin{aligned} \mathbf{A}_{i j}=&\left(1-\delta_{1, j}\right) \mathbf{P}_{i j}\left[\hat{\mathbf{L}}^{-1}\right]_{i j} \\ &-\left(1-\delta_{i, 1}\right) \mathbf{P}_{i j}\left[\hat{\mathbf{L}}^{-1}\right]_{j i} \end{aligned}
\mathbf{A} \in \mathbb{R}^{n \times n}是weighted adjacency matrix of the document level entity graph.
-
-
Multi-hop Reasoning: Used to perform inference on the induced latent structure. 多跳推理模塊用於對潛在結構進行推理,根據圖中節點的信息聚合更新每個節點的表示。
Give G with n node, which represented with an n*n adjacency matrix A.
\mathbf{u}_{i}^{l}=\sigma\left(\sum_{j=1}^{n} \mathbf{A}_{i j} \mathbf{W}^{l} \mathbf{u}_{i}^{l-1}+\mathbf{b}^{l}\right)
使用==dense connections== to the GCNs in order to ==capture more structural information on large graph.==:
為什麼使用dense connections ?
理解: 使用了多層圖網絡密集連接,以便在大型文檔級圖上捕獲更多的結構信息。在密集連接的幫助下,能夠訓練一個更深層次的模型,捕捉更豐富的局部和非局部信息,以學習更好的圖表示。這個密集連接的圖網絡和多頭注意力機制的原理相似,而聯想到圖中邊是根據兩個節點經過注意力計算得到的,可以推測密集連接和多頭注意力的效果相似,可以捕獲圖中不同的特徵信息。
-
Iterative Refinement(迭代更新): Refine the latent document-level graph for the better reasoning.
Stacking N blocks of the dynamic reasoner in order to induce the document-level structure N times.
更直觀說,最初的淺層結構在最初迭代的時候大部分的信息來自相鄰的鄰居信息,隨着迭代的進行—>
The induction module is able to generate a more informative structure.
為了能夠推斷出超出簡單父子關係的更豐富的結構信息,使用N個動態推理塊來多次歸納文檔級結構。通過與更豐富的非局部信息的交互,結構變得更加細化,歸納模塊能夠生成更合理的結構。

Classifier
P\left(r \mid \mathbf{e}_{i}, \mathbf{e}_{j}\right)=\sigma\left(\mathbf{e}_{i}^{T} \mathbf{W}_{\mathbf{e}} \mathbf{e}_{j}+\mathbf{b}_{e}\right)_{r}
\mathbf{W}_{e} \in \mathbb{R}^{d \times k \times d} and \mathbf{b}_{e} \in \mathbb{R}^{k},其中 k 是關係類別總數。
Experiment
-
實驗數據集
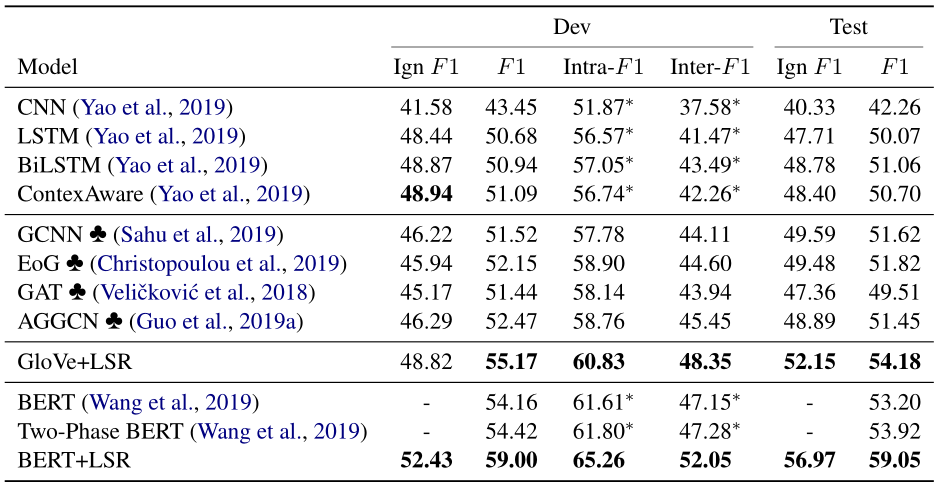
**DocRED&CDR(**Chemical-Disease Reactions )&GDA(Gene-Disease Associations)(後兩者是醫學數據集)其中DocRED超過40%的關係事實需要對多個句子進行閱讀和推理,所以DocRED與以前的句子級別數據集有顯着差異。
-
對照實驗
Sequence-based Models ContextAware/BiLSTM/CNN Graph-Based Models GCNN/EoG/AGGCN/GAT BERT-Based Models Fine-tune BERT/Two-Phase BERT -
實驗結果