
Scrapy入門到放棄01:開啟爬蟲2.0時代
- 2021 年 4 月 21 日
- 筆記
前言 Scrapy is coming!! 在寫了七篇爬蟲基礎文章之後,終於寫到心心念念的Scrapy了。Scrapy開 …
Continue Reading前言 Scrapy is coming!! 在寫了七篇爬蟲基礎文章之後,終於寫到心心念念的Scrapy了。Scrapy開 …
Continue Reading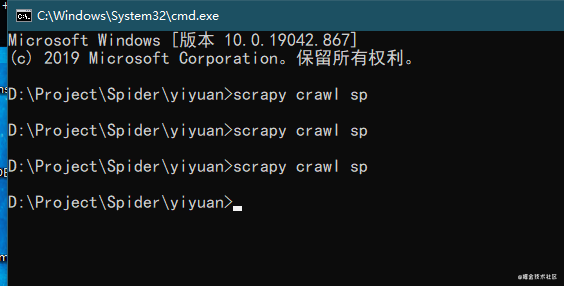
筆者最近對scrapy的學習可謂如火如荼,雖然但是,即使是一整天地學習下來也會有中間兩三個小時的「無效學習」,不是筆者開 …
Continue Reading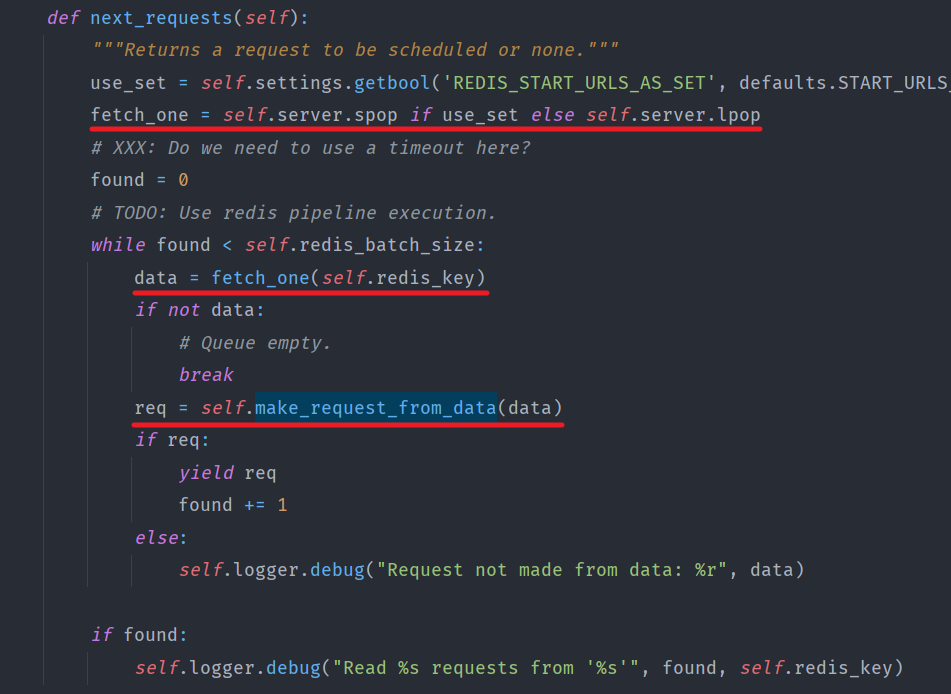
問題描述 默認RedisSpider在啟動時,首先會讀取redis中的spidername:start_urls,如果有 …
Continue Reading本文通過示例簡要介紹一下使用Scrapy抓取網站內容的基本方法和流程。 繼續閱讀之前請確保已安裝了scrapy。 基本安 …
Continue Reading
寫在前面:本篇文章內容較多,涉及知識較廣,讀完需要大約 20 分鐘,請讀者耐心閱讀。 如今大多數企業都離不開爬蟲,它是獲 …
Continue Reading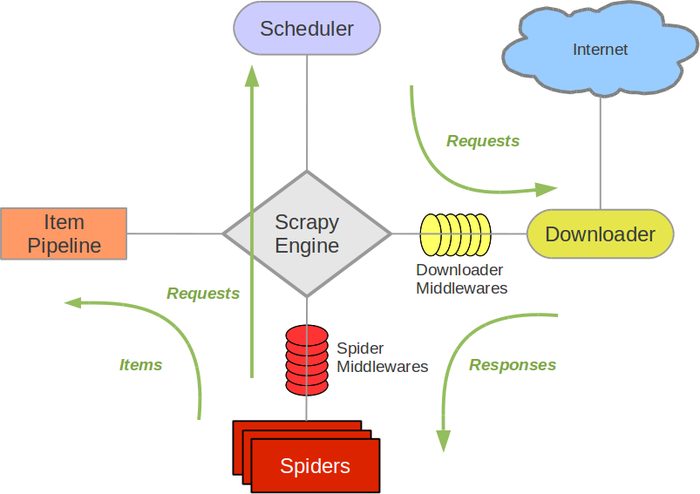
架構及簡介 Scrapy是用純Python實現一個為了爬取網站數據、提取結構性數據而編寫的應用框架,用途非常廣泛。 Sc …
Continue Reading
在做爬蟲服務化時,有這樣一個需求:介面用命令行啟動爬蟲,但是數據入庫時要記錄此次任務的task_id。 簡單說就是,Sc …
Continue Reading
在之前的文章中我們簡單了解了一下Scrapy 框架和安裝及目錄的介紹,本章我們將根據 scrapy 框架實現部落格園首頁 …
Continue Reading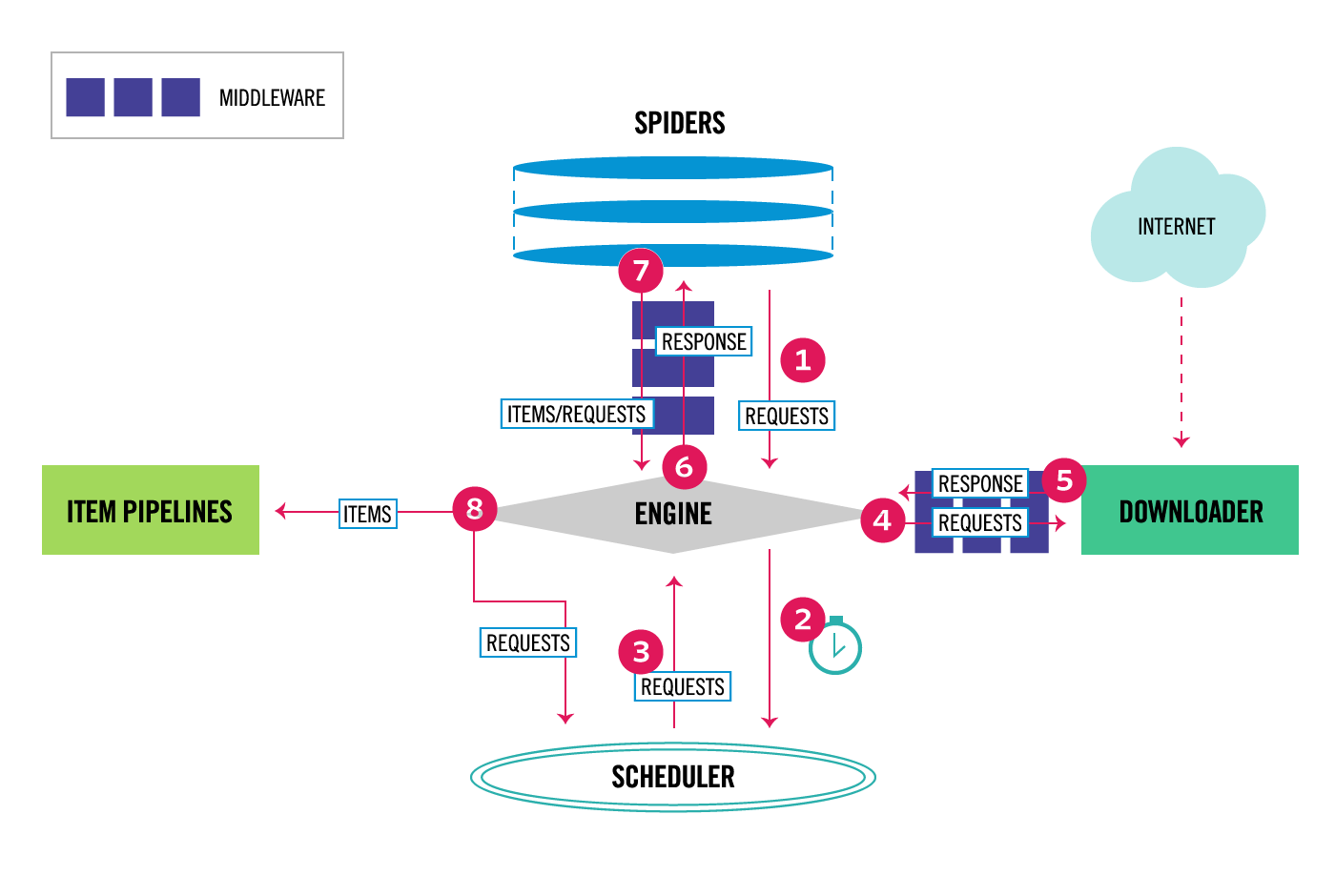
基於Scrapy的B站爬蟲 最近又被叫去做爬蟲了,不得不拾起兩年前搞的東西。 說起來那時也是突發奇想,想到做一個B站的爬 …
Continue Reading
在之前我做了一個系列的關於 python 爬蟲的文章,傳送門://www.cnblogs.com/weijiutao/p …
Continue Reading