python Scrapy 從零開始學習筆記(一)
在之前我做了一個系列的關於 python 爬蟲的文章,傳送門://www.cnblogs.com/weijiutao/p/10735455.html,並寫了幾個爬取相關網站並提取有效資訊的案例://www.cnblogs.com/weijiutao/p/10614694.html 等,從本章開始本人將繼續深入學習 python 爬蟲,主要是基於 Scrapy 庫展開,特此記錄,與君共勉!
Scrapy 官方網址://docs.scrapy.org/en/latest/
Scrapy 中文網址://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Scrapy 框架
-
Scrapy是用純Python實現一個為了爬取網站數據、提取結構性數據而編寫的應用框架,用途非常廣泛。
-
框架的力量,用戶只需要訂製開發幾個模組就可以輕鬆的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。
-
Scrapy 使用了 Twisted
['twɪstɪd](其主要對手是Tornado)非同步網路框架來處理網路通訊,可以加快我們的下載速度,不用自己去實現非同步框架,並且包含了各種中間件介面,可以靈活的完成各種需求。
Scrapy架構圖(綠線是數據流向):

-
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、數據傳遞等。 -
Scheduler(調度器): 它負責接受引擎發送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。 -
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理, -
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item欄位需要的數據,並將需要跟進的URL提交給引擎,再次進入Scheduler(調度器), -
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、存儲等)的地方. -
Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件。 -
Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通訊的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
以上是 Scrapy 的架構圖,從流程上看還是很清晰的,我就只簡單的說一下,首先從紅色方框的 Spider 開始,通過引擎發送給調度器任務,再將請求任務交給下載器並處理完後返回結果給 Spider,最後將結果交給關到來處理我們的結果就可以了。
上面的話可能還是會有些拗口,在接下來我們會一點點進行剖析,最後會發現利用 Scrapy 框架來做爬蟲是如此簡單。
Scrapy的安裝
windows 安裝 pip install scrapy
Mac 安裝 sudo pip install scrapy
pip 升級 pip install –upgrade pip
本人目前使用的是Mac電腦,目前使用的是 python3 版本,內容上其實都大同小異,如遇系統或版本問題可及時聯繫,互相學習!
安裝完成後我們在終端輸出 Scrapy 即可安裝是否成功:
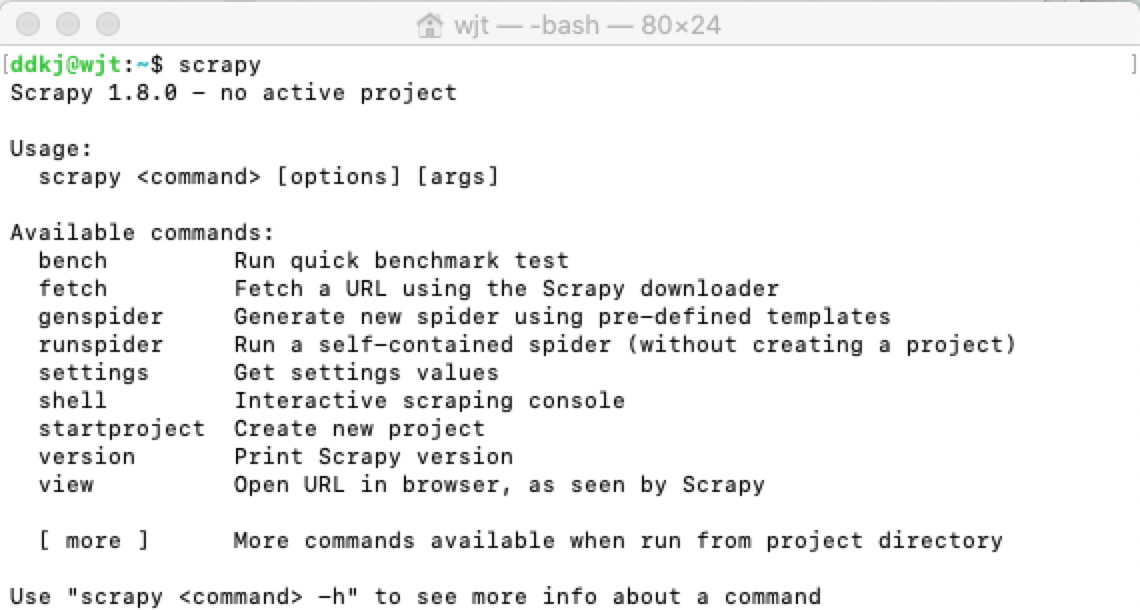
新建項目
在 Scrapy 安裝成功之後,我們就需要用它來開發我們的爬蟲項目了,進入自定義的項目目錄中,運行下列命令:
scrapy startproject spiderDemo
運行上面的命令行就會在我們項目目錄下生成一下目錄結構:
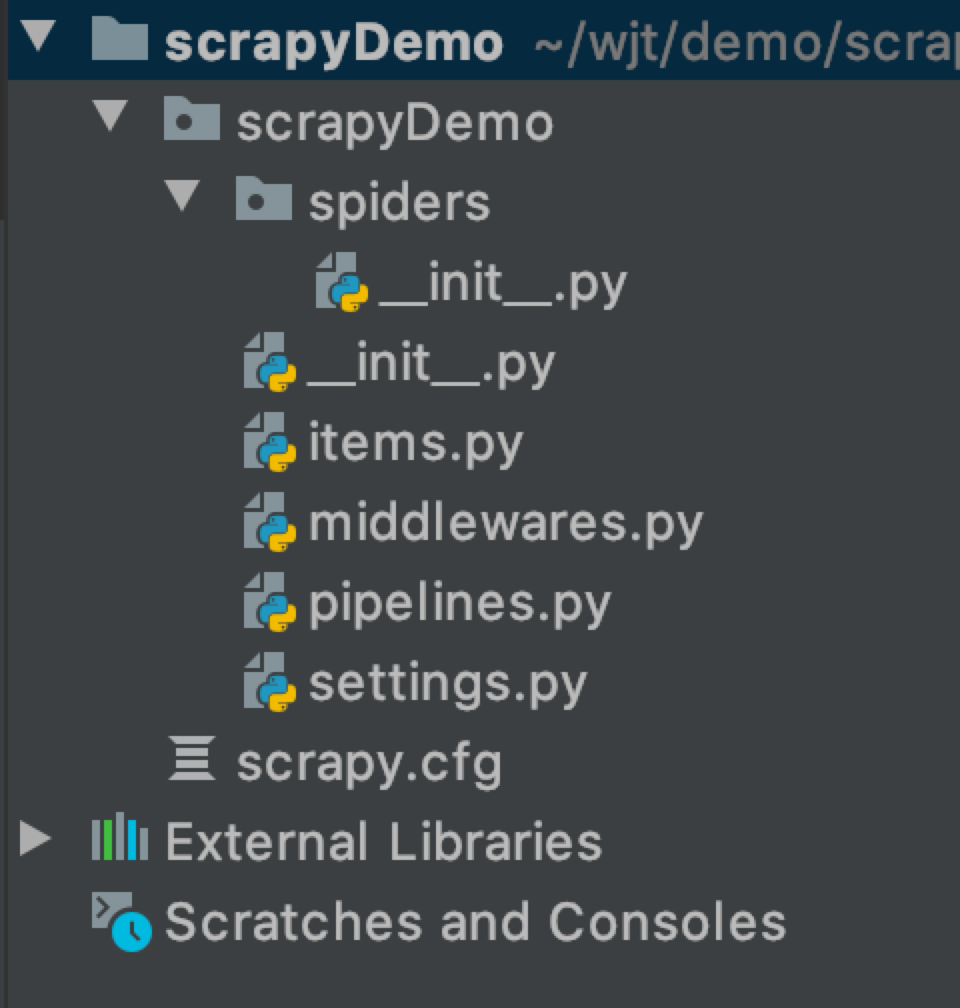
下面來簡單介紹一下各個主要文件的作用:
scrapy.cfg :項目的配置文件
scrapyDemo/ :項目的Python模組,將會從這裡引用程式碼
scrapyDemo/items.py :項目的目標文件
scrapyDemo/middlewares.py :項目的中間件文件
scrapyDemo/pipelines.py :項目的管道文件
scrapyDemo/settings.py :項目的設置文件
scrapyDemo/spiders/ :存儲爬蟲程式碼目錄
接下來我們對各文件里的內容簡單說一下,裡面的程式碼目前都是最簡單的基本程式碼,在接下來做案例的時候我們會再有針對地對文件做一下解釋。
其中的 __init_.py 文件內容都是空的,但是卻不能刪除掉,否則項目將無法啟動。
spiderDemo/items.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # //docs.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class ScrapydemoItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 pass
該文件是用來定義我們通過爬蟲所獲取到的有用的資訊,即 scrapy.Item
scrapyDemo/middlewares.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your spider middleware 4 # 5 # See documentation in: 6 # //docs.scrapy.org/en/latest/topics/spider-middleware.html 7 8 from scrapy import signals 9 10 11 class ScrapydemoSpiderMiddleware(object): 12 # Not all methods need to be defined. If a method is not defined, 13 # scrapy acts as if the spider middleware does not modify the 14 # passed objects. 15 16 @classmethod 17 def from_crawler(cls, crawler): 18 # This method is used by Scrapy to create your spiders. 19 s = cls() 20 crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 21 return s 22 23 def process_spider_input(self, response, spider): 24 # Called for each response that goes through the spider 25 # middleware and into the spider. 26 27 # Should return None or raise an exception. 28 return None 29 30 def process_spider_output(self, response, result, spider): 31 # Called with the results returned from the Spider, after 32 # it has processed the response. 33 34 # Must return an iterable of Request, dict or Item objects. 35 for i in result: 36 yield i 37 38 def process_spider_exception(self, response, exception, spider): 39 # Called when a spider or process_spider_input() method 40 # (from other spider middleware) raises an exception. 41 42 # Should return either None or an iterable of Request, dict 43 # or Item objects. 44 pass 45 46 def process_start_requests(self, start_requests, spider): 47 # Called with the start requests of the spider, and works 48 # similarly to the process_spider_output() method, except 49 # that it doesn』t have a response associated. 50 51 # Must return only requests (not items). 52 for r in start_requests: 53 yield r 54 55 def spider_opened(self, spider): 56 spider.logger.info('Spider opened: %s' % spider.name) 57 58 59 class ScrapydemoDownloaderMiddleware(object): 60 # Not all methods need to be defined. If a method is not defined, 61 # scrapy acts as if the downloader middleware does not modify the 62 # passed objects. 63 64 @classmethod 65 def from_crawler(cls, crawler): 66 # This method is used by Scrapy to create your spiders. 67 s = cls() 68 crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 69 return s 70 71 def process_request(self, request, spider): 72 # Called for each request that goes through the downloader 73 # middleware. 74 75 # Must either: 76 # - return None: continue processing this request 77 # - or return a Response object 78 # - or return a Request object 79 # - or raise IgnoreRequest: process_exception() methods of 80 # installed downloader middleware will be called 81 return None 82 83 def process_response(self, request, response, spider): 84 # Called with the response returned from the downloader. 85 86 # Must either; 87 # - return a Response object 88 # - return a Request object 89 # - or raise IgnoreRequest 90 return response 91 92 def process_exception(self, request, exception, spider): 93 # Called when a download handler or a process_request() 94 # (from other downloader middleware) raises an exception. 95 96 # Must either: 97 # - return None: continue processing this exception 98 # - return a Response object: stops process_exception() chain 99 # - return a Request object: stops process_exception() chain 100 pass 101 102 def spider_opened(self, spider): 103 spider.logger.info('Spider opened: %s' % spider.name)
該文件為中間件文件,名字後面的s表示複數,說明這個文件裡面可以放很多個中間件,我們用到的中間件可以在此定義
spiderDemo/pipelines.py
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: //docs.scrapy.org/en/latest/topics/item-pipeline.html 7 8 9 class ScrapydemoPipeline(object): 10 def process_item(self, item, spider): 11 return item
該文件俗稱管道文件,是用來獲取到我們的Item數據,並對數據做針對性的處理。
scrapyDemo/settings.py
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for scrapyDemo project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # //docs.scrapy.org/en/latest/topics/settings.html 9 # //docs.scrapy.org/en/latest/topics/downloader-middleware.html 10 # //docs.scrapy.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'scrapyDemo' 13 14 SPIDER_MODULES = ['scrapyDemo.spiders'] 15 NEWSPIDER_MODULE = 'scrapyDemo.spiders' 16 17 18 # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 #USER_AGENT = 'scrapyDemo (+//www.yourdomain.com)' 20 21 # Obey robots.txt rules 22 ROBOTSTXT_OBEY = True 23 24 # Configure maximum concurrent requests performed by Scrapy (default: 16) 25 #CONCURRENT_REQUESTS = 32 26 27 # Configure a delay for requests for the same website (default: 0) 28 # See //docs.scrapy.org/en/latest/topics/settings.html#download-delay 29 # See also autothrottle settings and docs 30 #DOWNLOAD_DELAY = 3 31 # The download delay setting will honor only one of: 32 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 33 #CONCURRENT_REQUESTS_PER_IP = 16 34 35 # Disable cookies (enabled by default) 36 #COOKIES_ENABLED = False 37 38 # Disable Telnet Console (enabled by default) 39 #TELNETCONSOLE_ENABLED = False 40 41 # Override the default request headers: 42 #DEFAULT_REQUEST_HEADERS = { 43 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 44 # 'Accept-Language': 'en', 45 #} 46 47 # Enable or disable spider middlewares 48 # See //docs.scrapy.org/en/latest/topics/spider-middleware.html 49 #SPIDER_MIDDLEWARES = { 50 # 'scrapyDemo.middlewares.ScrapydemoSpiderMiddleware': 543, 51 #} 52 53 # Enable or disable downloader middlewares 54 # See //docs.scrapy.org/en/latest/topics/downloader-middleware.html 55 #DOWNLOADER_MIDDLEWARES = { 56 # 'scrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543, 57 #} 58 59 # Enable or disable extensions 60 # See //docs.scrapy.org/en/latest/topics/extensions.html 61 #EXTENSIONS = { 62 # 'scrapy.extensions.telnet.TelnetConsole': None, 63 #} 64 65 # Configure item pipelines 66 # See //docs.scrapy.org/en/latest/topics/item-pipeline.html 67 #ITEM_PIPELINES = { 68 # 'scrapyDemo.pipelines.ScrapydemoPipeline': 300, 69 #} 70 71 # Enable and configure the AutoThrottle extension (disabled by default) 72 # See //docs.scrapy.org/en/latest/topics/autothrottle.html 73 #AUTOTHROTTLE_ENABLED = True 74 # The initial download delay 75 #AUTOTHROTTLE_START_DELAY = 5 76 # The maximum download delay to be set in case of high latencies 77 #AUTOTHROTTLE_MAX_DELAY = 60 78 # The average number of requests Scrapy should be sending in parallel to 79 # each remote server 80 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 81 # Enable showing throttling stats for every response received: 82 #AUTOTHROTTLE_DEBUG = False 83 84 # Enable and configure HTTP caching (disabled by default) 85 # See //docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 86 #HTTPCACHE_ENABLED = True 87 #HTTPCACHE_EXPIRATION_SECS = 0 88 #HTTPCACHE_DIR = 'httpcache' 89 #HTTPCACHE_IGNORE_HTTP_CODES = [] 90 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
該文件為我們的設置文件,一些基本的設置需要我們在此文件中進行配置,如我們的中間件文件當中的兩個類 ScrapydemoSpiderMiddleware,ScrapydemoDownloaderMiddleware 在 settings.py 中就能找到。
在 settings 文件中,我們常會配置到如上面的欄位 如:ITEM_PIPELINES(管道文件),DEFAULT_REQUEST_HEADERS(請求報頭),DOWNLOAD_DELAY(下載延遲)
,ROBOTSTXT_OBEY(是否遵循爬蟲協議)等。
本章我們就先簡單的介紹一下 scrapy 的基本目錄,下一章我們來根據 scrapy 框架實現一個爬蟲案例。
