自己動手實現 HashMap(Python字典),徹底系統的學習哈希表(上篇)——不看血虧!!!
HashMap(Python字典)設計原理與實現(上篇)——哈希表的原理
在此前的四篇長文當中我們已經實現了我們自己的ArrayList和LinkedList,並且分析了ArrayList和LinkedList的JDK源程式碼。 本篇文章主要跟大家介紹我們非常常用的一種數據結構HashMap,在本篇文章當中主要介紹他的實現原理,下篇我們自己動手實現我們自己的HashMap,讓他可以像JDK的HashMap一樣工作。
如果有公式渲染不了,可查看這篇內容相同且可渲染公式的文章
HashMap初識
如果你使用過HashMap的話,那你肯定很熟悉HashMap給我們提供了一個非常方便的功能就是鍵值(key, value)查找。比如我們通過學生的姓名查找分數。
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("學生A", 60);
map.put("學生B", 70);
map.put("學生C", 20);
map.put("學生D", 85);
map.put("學生E", 99);
System.out.println("學生B的分數是:" + map.get("學生B"));
}
我們知道HashMap給我們提供查詢get函數功能的時間複雜度為O(1),他在常數級別的時間複雜度就可以查詢到結果。那它是如何做到的呢?
我們知道在電腦當中一個最基本也是唯一的,能夠實現常數級別的查詢的類型就是數組,數組的查詢時間複雜度為O(1),我們只需要通過下標就能訪問對應的數據。比如我們想訪問下標為6的數據,就可以這樣:
String[] strs = new String[10];
strs[6] = "一無是處的研究僧";
System.out.println(strs[6]);
因此我們要想實現HashMap給我們提供的O(1)級別查詢的時間複雜度的話,就必須使用到數組,而在具體的HashMap實現當中,比如說JDK底層也是採用數組實現的。
HashMap整體設計
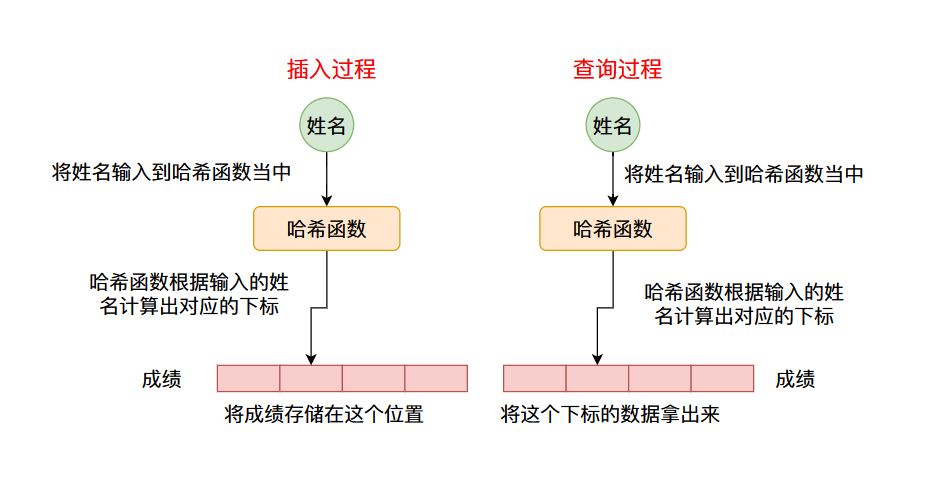
我們實現的HashMap需要滿足的最重要的功能是根據鍵(key)查詢到對應的值(value),比如上面提到的根據學生姓名查詢成績。
因此我們可以有一個這樣的設計,我們可以根據數據的鍵值計算出一個數字(像這種可以將一個數據轉化成一個數字的叫做哈希函數,計算出來的值叫做哈希值我們後續將會仔細說明),將這個哈希值作為數組的下標,這樣的話鍵值和下標就有了對應關係了,我們可以在數組對應的哈希值為下標的位置存儲具體的數據,比如上面談到的成績,整個流程如下圖所示:
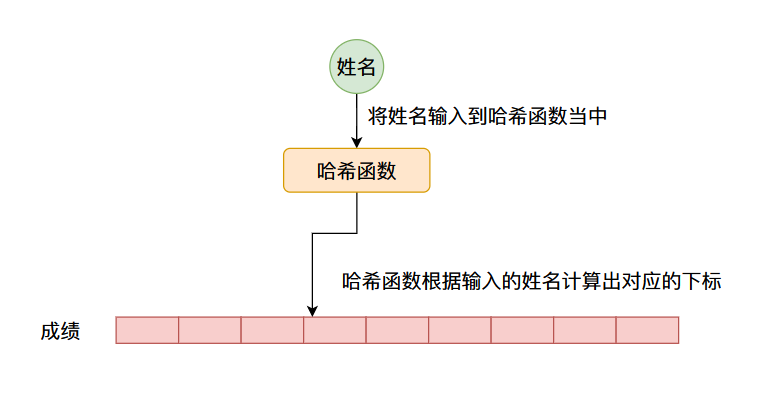
但是像這種哈希函數計算出來的數值一般是沒有範圍的,因此我們通常通過哈希函數計算出來的數值通常會經過一個求餘數操作(%),對數組的長度進行求餘數,否則求出來的數值將超過數組的長度。比如數組的長度是16,計算出來的哈希值為186,那麼求餘數之後的結果為186%16=10,那麼我們可以將數據存儲在數組當中下標為10的位置,下次我們來取的時候就取出下標為10位置的數據即可。
如何設計一個哈希函數?
首先我們需要了解一個知識,那就是在電腦世界當中我們所含有的兩種最基本的數據類型就是,整型(short, int, long)和字元串(String),其他的數據類型可以由這些數據類型組合起來,下面我們來分析一下常見的數據類型的哈希函數設計。
整型的哈希函數
對於整型數據,他本來就是一個數值,因此我們可以直接將這個值返回作為他的哈希值,而JDK中也是這麼實現的!JDK中實現整型的哈希函數的方法:
/**
* Returns a hash code for a {@code int} value; compatible with
* {@code Integer.hashCode()}.
*
* @param value the value to hash
* @since 1.8
*
* @return a hash code value for a {@code int} value.
*/
public static int hashCode(int value) {
return value;
}
字元串的哈希函數
我們知道字元串底層存儲的還是用整型數據存儲的,比說說字元串hello world,就可以使用字元數組['h', 'e', 'l', 'l', 'o' , 'w', 'o', 'r', 'l', 'd']進行存儲,因為我們計算出來的這個哈希值需要盡量不和別的數據計算出來的哈希值衝突(這種現象叫做哈希衝突,我們後面會仔細討論這個問題),因此我們要儘可能的充分利用字元串裡面的每個字元資訊。我們來看一下JDK當中是怎麼實現字元串的哈希函數的
public int hashCode() {
// hash 是 String 類當中一個私有的 int 變數,主要作用即存儲計算出來的哈希值
// 避免哈希值重複計算 節約時間
int h = hash; // 如果是第一次調用 hashCode 這個函數 hash 的值為0,也就是說 h 值為 0
// value 就是存儲字元的字元數組
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
// 更新 hash 的值
hash = h;
}
return h;
}
上面的計算hashCode的程式碼,可以用下面這個公式表示:
- 其中
s,表示存儲字元串的字元數組 n表示字元數組當中字元的個數
$$
s[0]31^{(n-1)} + s[1]31^{(n-2)} + … + s[n-1]
$$
自定義類型的哈希函數
比如我們自己定義了一個學生類,我們改設計他的哈希函數,並且計算他的哈希值呢?
class Student {
String name;
int grade;
}
我們可以根據上面提到的兩種哈希函數,仿照他們的設計,設計我們自己的哈希函數,比如像下面這樣。
class Student {
String name;
int grade;
// 我們自己要實現的哈希函數
@Override
public int hashCode() {
return name.hashCode() * 31 + grade;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return grade == student.grade &&
Objects.equals(name, student.name);
}
}
事實上JDK也貼心的為我們實現了一個類,去計算我們自定義類的哈希函數。
// 下面這個函數是我們自己設計的類 Student 的哈希函數
@Override
public int hashCode() {
return Objects.hash(name, grade);
}
// 下面這個函數為 Objects.hash 函數
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
// 下面這個函數為 Arrays.hashCode 函數
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
JDK幫助我們實現的哈希函數,本質上就是將類當中所有的欄位封裝成一個數組,然後像計算字元串的哈希值那樣去計算我們自定義類的哈希值。
集合類型的哈希函數
其實集合類型的哈希函數也可以像字元串那樣設計哈希函數,我們來看一下JDK內部是如何實現集合類的哈希函數的。
public int hashCode() {
int hashCode = 1;
// 遍歷集合當中的對象,進行哈希值的計算
for (E e : this)
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
return hashCode;
}
上述程式碼也可以用之前的公式來表示,其中s[i]表示集合當中第i個數據對象:
$$
s[0]31^{(n-1)} + s[1]31^{(n-2)} + … + s[n-1]
$$
哈希衝突
因為我們用的最終的數組的下標是通過哈希值取餘數得到的,那麼就有可能產生衝突。比如說我們的數組長度為10,有兩個數據他們的哈希值分別為8和28,他們對10取余之後得到的結果都為8那麼改如何解決這個問題呢?
開放地址法(再散列法)
線性探測再散列
假設我們的哈希函數為H,我們的數組長度為m,我們的鍵為key,那麼我計算出來的下標為:
$$
h_i = H(key) % m
$$
當我們有哈希衝突的時候,我們計算下標的方法變為:
$$
h_i = (H(key) + d_i) % m, d_i = i
$$
當我們第一次衝突的時候$d_1 = 1$,如果重新進行計算仍然衝突那麼$d_2 = 2$ ……
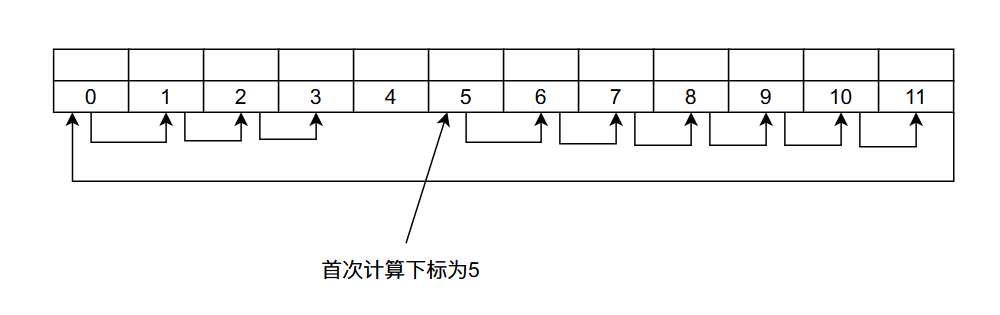
比如在上圖當中我們首次計算的哈希值$H(key) = 5$的結果等於5,如果有哈希衝突,那麼下次計算出來的哈希值為$(H(key) + 1) % 12 = 6$,如果還是衝突那麼計算出來的哈希值為$(H(key) + 2) % 12 = 7$ ……,直到找到一個空位置。談到這裡你可能會問,萬一都滿了呢?我們在下一小節再談這個問題。
二次探測再散列
$$
h_i = (H(key) + d_i) % m, d_i = (-1)^{i – 1} i^2
$$
這個散列方法和線性探測散列差不多,只不過$d_i$的值變化情況不一樣而已,大家可以參考線性探測進行分析,這個方法可以往數組的兩個方法走,因為前面有一個而線性探測只能往數組的一個方向走。此外這個方法走的距離比線性探測更大,因此可能可以在更小的衝突次數當中找到一個空位置。
偽隨機數再散列
$$
h_i = (H(key) + d_i) % m, d_i = 一個隨機數
$$
這個方式的大致策略和前面差不多,只不過$d_i$上稍微有所差異。
再哈希法
我們可以準備多個哈希函數,當使用一個哈希函數產生衝突的時候,我們可以換一個哈希函數,希望通過不同的哈希函數得到不同的哈希值,以解決哈希衝突的問題。
鏈地址法
這個方法是目前使用比較多的方法,當產生哈希衝突的時候,數據用一個鏈表將衝突的數據鏈接起來,比如像下面這樣:
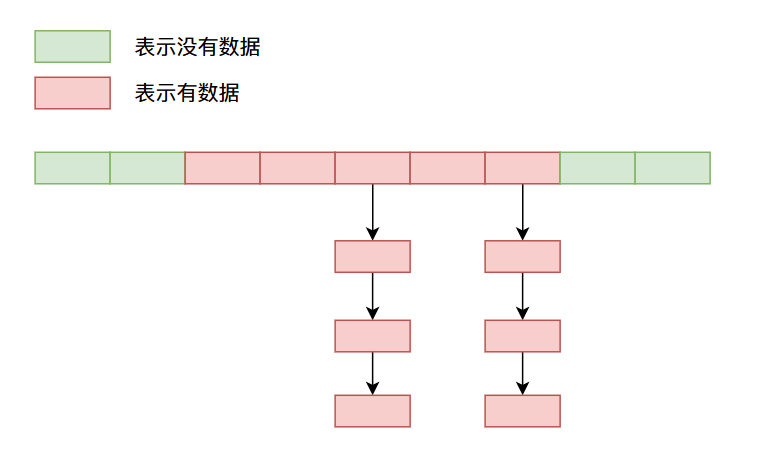
以上就是一些常見的解決哈希衝突的方法,因為都是文字說明沒有程式碼,你可能稍微有些難以理解,比如說我通過上面的方法存儲數據,那麼我之後怎麼拿到我存進去的數據呢?好像放進去就拿不出來了呀🤣🤣🤣!沒事兒,這些疑問我們在下篇自己實現哈希表的時候會一一解開,到時候你就發現原來這些演算法的設計如此巧妙。
擴容
在上面的文章當中我們並沒有談到當數組滿了之後怎麼辦。很簡單嘛,我可以使用一個變數記錄數組當中已經使用了的空間,如果全部使用過了,我們就進行擴容,擴大我們的數組就可以了嘛!然後將原數組當中的數據重新進行哈希存放到新數組當中即可!因為我們在計算存儲下標的時候需要對數組長度進行取余,而當我們申請新數組的時候數組長度已經發生變化了,因此需要重新對數據進行哈希操作。這裡面仍然有很多需要考慮的細節問題,這些問題我們在下篇當中進行程式碼實現的時候會仔細討論。
總結
在本篇文章當中,我們主要談到了如何去設計一個可以使用的哈希表,同時介紹了我們改如何設計一個哈希函數,最終談到了解決哈希衝突和數組滿了的問題!!!
-
HashMap整體的設計結構。 -
設計一個好的哈希函數。
- 整型數據的哈希函數。
- 字元串的哈希函數。
- 自定義類型的哈希函數。
- 集合的哈希函數。
-
解決哈希衝突的辦法。
- 開放地址法
- 線性探測
- 二次探測
- 隨機數探測
- 再哈希法
- 鏈地址地址法
- 開放地址法
-
擴容方法
以上就是本篇文章的所有內容了,我們將在下篇當中自己動手實現一個自己的哈希表MyHashMap,這其中還有很多非常細節的設計,其中涉及到很多位運算操作和很多其他非常巧妙的操作。我是LeHung我們下期再見!!!
更多精彩內容合集,可訪問://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,了解更多電腦知識!!!



