【論文筆記】Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges(綜述)
Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges
| Authors | Solmaz Niknam, Harpreet S. Dhillon, Jeffrey H. Reed |
|---|---|
| Keywords | |
| Abstract | 本文介紹了FL的總體思路,討論了在5G網路中可能的應用,描述了無線通訊環境中的關鍵技術挑戰與關於未來研究的開放性問題。 |
| Publication | DATA SCIENCE AND ARTIFICIAL INTELLIGENCE FOR COMMUNICATIONS 2020 |
| DOI | 10.1109/MCOM.001.1900461 |
1 INTRODUCTION
對於無線通訊,採用ML進行系統設計和分析尤其具有吸引力,因為傳統模型驅動的方法不夠豐富以應對現代無線網路不斷增長的複雜度與異構性。單獨利用數據分析(例如被使用在模型驅動的通訊系統設計中)的一種替代選擇是使用大量數據學習模型,以期實現一個無線系統設計的完整的範式轉換。
在無線網路環境下,數據分散在數以十億計的設備上,傳統的集中式ML方案已經不適合於這種情況,因為對數據隱私的要求已經不太可能將隱私數據集中到一起。
分散式ML將數據一直保留在設備本地,在本地做訓練,只需要傳輸一些感興趣的特徵而非原始數據流,大大減少了網路頻寬與電量的消耗。並且促進該方法發展的另一個動力在於它能夠很好地應對延遲敏感應用的實時事務。
聯邦學習(Federated Learning)是一個新興的分散式方法,尤其針對上述挑戰,包括隱私與資源限制。
2 前言與總覽
儘管FL的做法本來就比直接分享原始數據對隱私保護得更好,但是由於本地學習者通過傳輸加密後的模型到聚合器加入了一個額外的保護層(layer),一些模型可能仍然會泄露隱藏資訊。
作為安全多方計算的一類,一種安全的聚合演算法被用於聚合加密的模型,它無需對上傳的加密模型進行解密就可以完成模型聚合[7]。FL概念的一種描述如下圖所示。
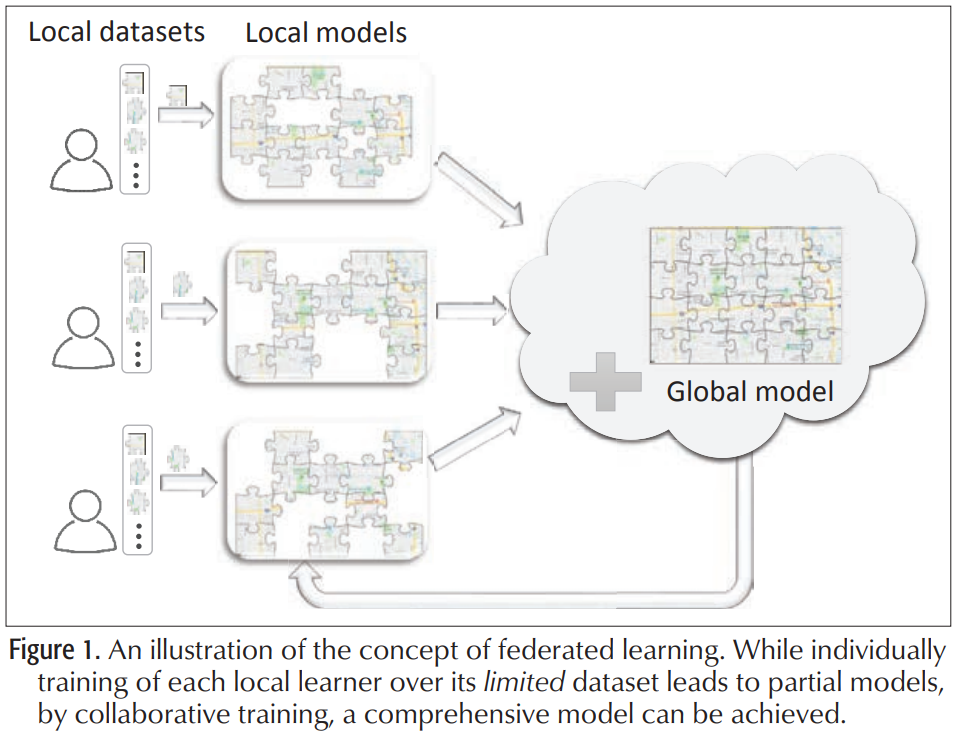
許多重要的方面使得FL區別於現存的分散式學習(Distributed Learning)方案,其中一個就是:分散式學習方案都是各學習者的數據都服從IID的隨機變數的實現;FL環境下,不同的學習者可能會觀察過程的不同部分(它們之間可能有重疊),因此生成的數據不能代表所有數據的分布,本地學習者的數據是Non-IID的。例如,可以考慮為自動駕駛構建高解析度(HD)地圖的任務,其中自動駕駛車輛僅收集與它們所經過路線相關的位置和感測資訊,或者在手寫數字識別任務中,本地學習者具有不同數字的樣本。
其次,數據集的大小不平衡。例如,在HD地圖示例中,由於不同的自動駕駛車輛所經過的環境不同,在不同的自動駕駛車輛上收集的數據集可能大小不同。最後,數據集大量分布在本地學習者之間,每個本地學習者的數據樣本數量小於參與訓練的學習者總數。
數據集的這些顯著特徵(即Non-IID、分散式和不平衡的訓練數據)將聯邦ML框架與其他相關方法區分開來,下文將對此進行討論。
分散式學習(Distributed Learning)
該方案中,聚合器收集設備本地訓練的模型,以提供對所研究參數的整體和更準確的估計,但設備本地並不需要通過聚合器的任何回饋來獲取全局模型。
並行學習(Parallel Learning)
並行學習的主要目標是拓展演算法規模、加速學習過程,或者二者兼而有之。在這種類型的學習中,中央參數伺服器上的可用訓練集被劃分為子集,分配給一組工作機器,因此分配給每台工作機器的數據集具有相同的底層分布,隨後,並行執行訓練過程,並將參數回饋給參數伺服器。
這種類型的學習是在數據中心執行的,工作機器從共享存儲中獲取數據,因此,與FL不同,最終將擁有來自同一分布的樣本。此外,每個工作者的平均數據樣本數遠大於參與訓練過程的工作者數,這與數據大規模分布的聯邦環境不同。
分散式集成學習(Distributed Ensemble Learning)
也被稱作Committee-based Learning,是一種多個學習者(例如:分類器、回歸器)結合起來協作改善整體表現的學習方式。該方案中,數據集的不同部分被分配去訓練不同的模型,然後對這些模型進行匯總,以降低選擇不佳模型的可能性。
一般來說,這種學習方法的目標是從模型的混合中學習,而不是通過具有通訊約束的本地學習者聯邦、使用自然分布的數據集改進全局模型。
3 無線通訊中FL應用
3.1 邊緣計算與快取
在無線網路邊緣進行內容快取和數據計算是減少回程流量負載的一種很有前途的方法。總體思路是讓流行內容更接近邊緣終端,即小型基地台(SBS)和接入點(基礎設施快取)甚至用戶設備(無基礎設施快取),以便可以方便地在本地訪問。
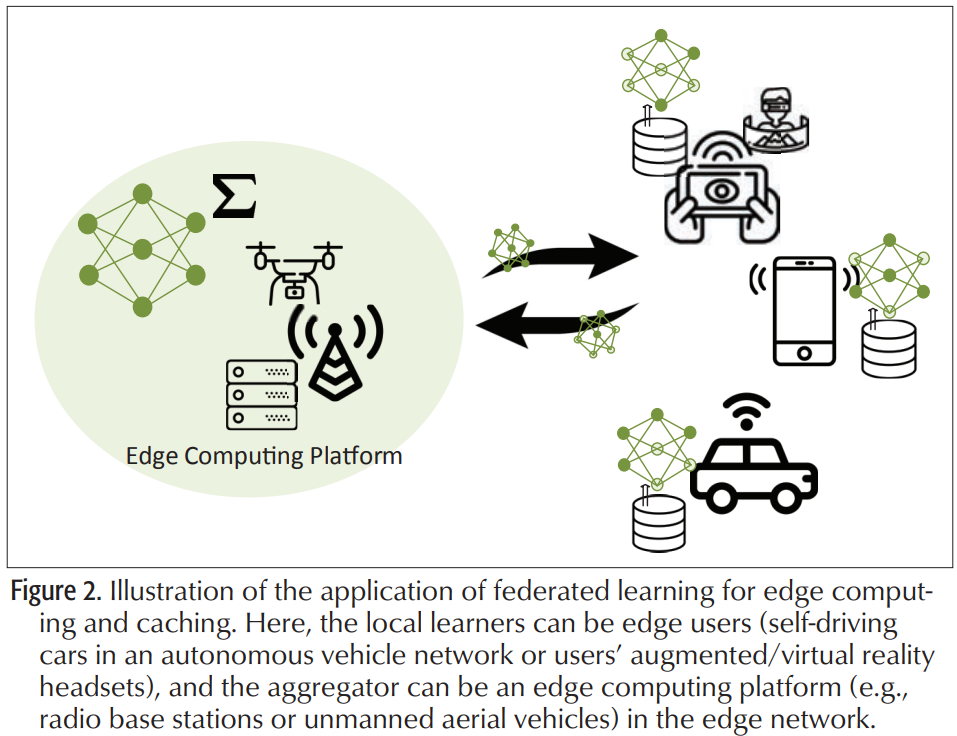
這種模式有可能實現具有嚴格延遲和頻寬要求的應用程式,這種體系結構的成功依賴於精確地確定每個快取中應該放置哪些內容。文獻中通常採用的方法是利用靜態或動態統計模型進行內容流行度識別。然而,模型驅動的內容流行度識別無法考慮影響內容流行度的眾多因素。此外,直接訪問對隱私敏感的用戶數據以進行內容區分在實踐中可能是不可能的。在利用本地訓練的模型而不是直接訪問用戶數據的前提下,聯邦學習似乎是無線網路主動快取中內容流行度預測的絕佳匹配(下圖所示)。
- 例如,在AR中,聯邦學習可以用於從其他用戶那裡學習某些流行的增強元素,而無需直接獲取他們的隱私敏感數據。然後預取這些流行資訊並在本地存儲,以減少延遲。
- 此外,在自動駕駛汽車中,可以使用聯邦學習通過其他車輛學習與交通有關的資訊,並將其預快取在路邊單元中。
3.2 頻譜管理
在未來的5G網路中,為了實現關鍵的5G垂直市場,需要一個低頻和高頻(即微波和毫米波頻段)的混合頻譜環境,以及不同類型的許可。混合頻譜接入需要協作和更自主的頻譜共享策略,以適應5G網路中的環境和應用。然而,以分散式方式動態訪問頻譜是複雜的。可能需要所有收音機的高解析度頻譜利用率數據,由於隱私問題,這些數據可能不容易共享。事實上,所有無線電設備都需要共享其感知數據,如頻譜佔用數據、設備非線性資訊,以及異常訊號(如干擾)的檢測。然而,這些數據對隱私敏感,收音機可能不願意發送與其工作頻率相關的資訊。此外,在頻譜訪問資料庫中收集頻譜使用資訊的集中式策略可能並不總是合適的。此外,對如此龐大的數據進行推斷需要巨大的處理能力和大規模優化,這在計算上是不允許的。
FL(每個無線電傳輸其本地頻譜利用模型)可以用來解決這些問題。聚合器利用本地頻譜利用模型參數來更新全局模型,該模型最終回饋給各個無線電設備,用於頻譜接入決策。值得注意的是,同樣的策略也可用於促進兩個無線系統的共存。
- 當前人們感興趣的一個特定環境是,專用短程通訊(DSRC)和蜂窩連接車輛在同一智慧交通系統(ITS)頻段內與所有設備(c-V2X)共存,這可以從這種解決方案中受益。
3.3 5G核心網路
網路數據分析功能(NWDAF)是3GPP定義的一種新的網路功能,旨在為支援ML的功能提供更多的數據挖掘能力,即使在核心網路中也是如此。它提供了在網路管理系統中使用智慧技術的能力。這使運營商能夠自動化網路管理和配置任務,從而通過減少人機交互降低運營支出。通常,NWDAF能夠連接到任何網路功能(NF)並利用核心網路中的任何數據(下圖所示)。此外,任何NF都可以請求網路分析資訊。
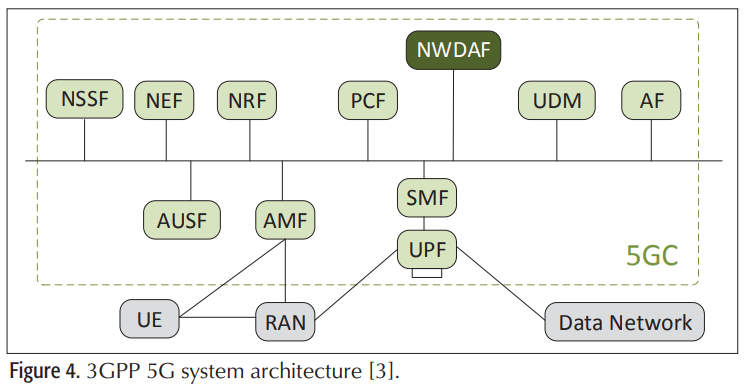
[8]在本地學習者聯邦的基礎上,為縱向分割的數據集引入了縱向FL,在特徵空間中考慮了Non-IID、不平衡和大規模分布的數據集等特性,縱向FL最適合核心網路結構。
例如,訪問移動性管理功能(AMF)和會話管理功能(SMF)分別管理移動性和會話建立(IP地址分配、流量路由等)。在這裡,NWDAF可以充當處理用戶數據聚合的全局節點。用戶的數據集在核心網路中的不同實體上垂直分割,每個實體保留與所有用戶相關的特定數據特徵的記錄。通過使用縱向聯邦學習,核心網路中的每個實體將其由本地收集的數據特徵訓練的本地加密模型傳輸給NWDAF實體,而不是將原始數據發送給NWDAF實體。這可以顯著緩解網路功能虛擬化(NFV)引入的網路拓撲中的大規模網路安全漏洞。
4 挑戰與未來方向
4.1 安全與隱私挑戰及考慮
- [7]提出了一種安全的聚合演算法,無需解密就可以聚合加密的模型。然而,一個特定的本地學習者的參與仍然可以通過分析全局模型被揭露[10]。
- [11]提出了差異私有聯合演算法,以在本地學習者級別提供隱私,而不是保護單個數據樣本。然而,這些演算法犧牲了模型的性能,或者需要額外的計算和特定數量的本地學習者來參與模型訓練。
- 一些神經網路模型可能會無意中記住訓練數據的獨特方面[12]。
與其他ML方法類似,在聯邦學習中,本地模型通常由新收集的數據重新訓練,以反映訓練模型上的變化。因此,對手可以通過嵌入精心設計的樣本數據毒害聯邦學習過程,秘密地影響本地訓練數據集,從而操縱模型的結果。它甚至可以通過發送梯度更新來執行模型中毒攻擊來威脅模型。聯邦學習已經通過對抗的視角進行了分析,以檢查學習過程對模型中毒對手的脆弱性[13]。由於主要形式的聯邦學習易受此類對抗性攻擊的影響,因此迫切需要一種防禦機制。此外,好奇的聚合器甚至本地學習者都可以對其他本地學習者執行成員推理攻擊。在推理攻擊中,攻擊者的目標是推斷特定數據點是否屬於訓練數據集[14]。模型參數的重複更新是提高成員身份攻擊準確性的關鍵因素。存在各種類型的推理攻擊,例如參數推理、輸入推理和屬性推理攻擊,這些攻擊可能會危害本地學習者的隱私。因此,還應該研究聯邦學習對這些攻擊的脆弱性以及相應的防禦機制。
4.2 關於演算法的挑戰與考慮
與幾乎所有分散式演算法相似,聯邦學習的必要考慮之一是受限的通訊與計算資源下演算法的收斂。
- [15]對基於梯度下降的凸損失函數聯邦學習的收斂範圍進行了理論分析。
對演算法收斂於非凸損失函數的情況進行分析評估也是有益的,在包括深度神經網路在內的一些模型中,模型的自然目標是學習非凸函數。
此外,參與全局更新的本地學習者的最佳數量、本地學習者的分組、本地更新和全局聚合的頻率等因素(這些因素導致模型性能和資源保存之間的權衡)依賴於應用程式,值得研究。此外,對於聯邦深度神經網路(federated deep neural Network)等一些模型,即使對於物聯網(IoT)節點等低功耗設備,更新的規模也可能很大。因此,稀疏和壓縮模型參數的方法在計算上是有效的,並減少了資源消耗。
4.3 無線環境中的挑戰與考慮
由於無線信道的容量有限,資訊在通過信道發送之前需要進行量化。由於本地學習者和聚合器需要通過無線信道交換模型參數,這將產生參數量化的聯合學習範式。在這種範式中,一個重要的考慮因素是模型在存在量化誤差時的魯棒性。除了通訊頻寬外,雜訊和干擾也是加劇信道瓶頸的其他因素,還應考慮對這些通道效應的魯棒性。
另一個重要的考慮因素是收斂時間。聚合時間聯邦學習不僅包括本地學習者和聚合器的計算時間,還包括它們之間的通訊時間,這取決於無線信道品質。因此,在優化本地更新和全局聚合的頻率時,應該考慮無線信道品質。
此外,在學習深層模型時,可以使用模型壓縮技術和稀疏訓練方法來降低模型的複雜度並縮小模型參數。這些方法對於處理能力有限的設備學習深度模型非常有用。因此,在降低複雜性和保持模型的準確性之間需要權衡。在無線應用的聯合深度學習中,模型優化還應考慮無線信道的通訊成本和品質。此外,鑒於無線信道的時變特性,可以根據無線信道的品質以自適應方式進行模型壓縮。
除了設備的可用性及其參與學習過程的意願外,全球聚合器和特定本地學習者之間的無線信道的品質也將影響其選擇訓練,並應與其他因素一起考慮。可能存在這樣的情況:特定設備願意參與,但其相應的無線信道不足以以預定品質傳輸模型參數,這可能會降低全局模型的準確性。
5 結語
本文討論了FL在解決主要與5G模式有關的無線通訊中的一些挑戰方面的作用。我們首先介紹FL的概念及其顯著特徵,然後,我們介紹了5G網路中FL的幾個用例,從邊緣到核心網路。還討論了許多需要在這方面進一步研究的問題和公開挑戰。


