Nebula 基於 ElasticSearch 的全文搜索引擎的文本搜索
本文首發於 Nebula Graph 公眾號 NebulaGraphCommunity,Follow 看大廠圖資料庫技術實踐。

1 背景
Nebula 2.0 中已經支援了基於外部全文搜索引擎的文本查詢功能。在介紹這個功能前,我們先簡單回顧一下 Nebula Graph 的架構設計和存儲模型,更易於下邊章節的描述。
1.1 Nebula Graph 架構簡介
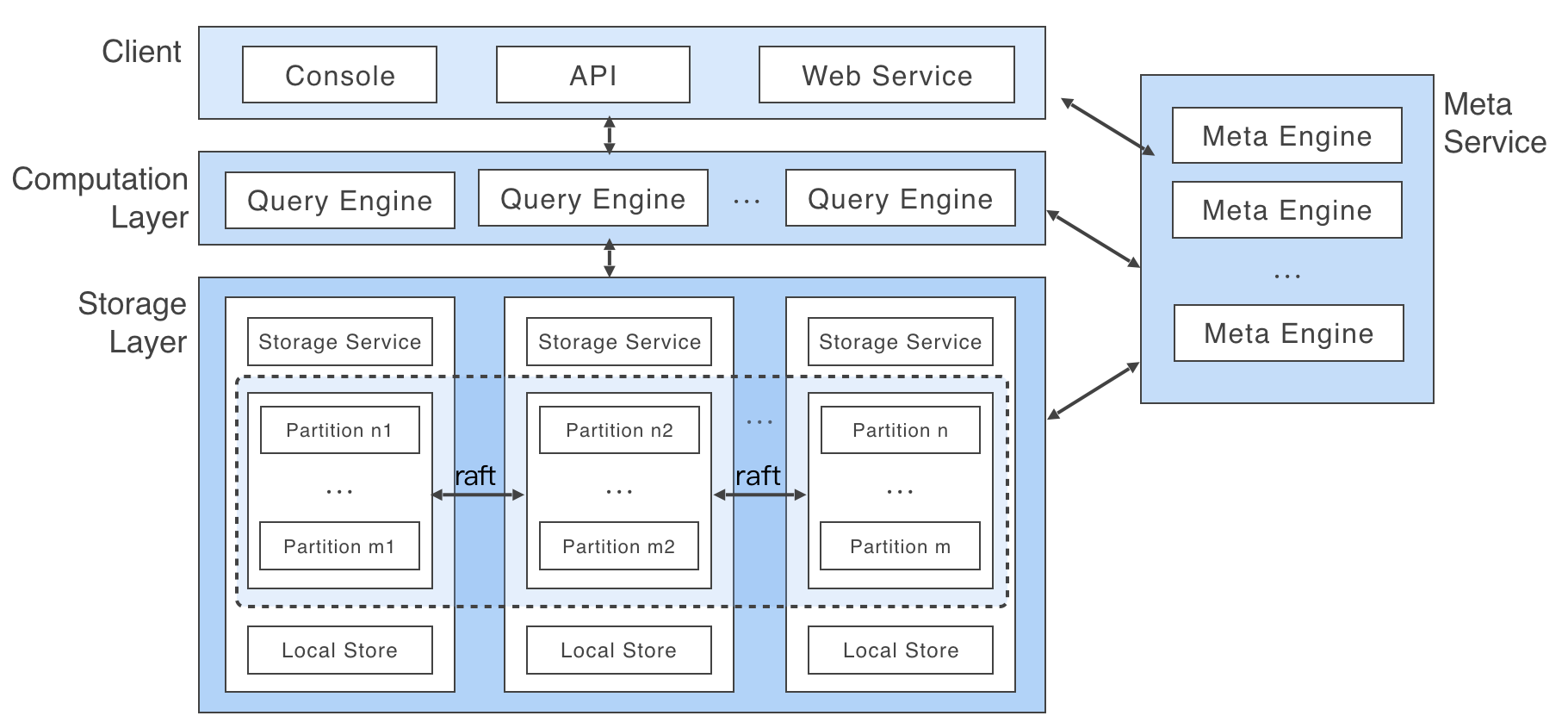
如圖所示,Storage Service 共有三層,最底層是 Store Engine,它是一個單機版 local store engine,提供了對本地數據的get/put/scan/delete操作,相關的介面放在 KVStore / KVEngine.h 文件裡面,用戶完全可以根據自己的需求訂製開發相關 local store plugin,目前 Nebula 提供了基於 RocksDB 實現的 Store Engine。
在 local store engine 之上,便是我們的 Consensus 層,實現了 Multi Group Raft,每一個 Partition 都對應了一組 Raft Group,這裡的 Partition 便是我們的數據分片。目前 Nebula 的分片策略採用了靜態 Hash的方式,具體按照什麼方式進行 Hash,在下一個章節 schema 里會提及。用戶在創建 SPACE 時需指定 Partition 數,Partition 數量一旦設置便不可更改,一般來講,Partition 數目要能滿足業務將來的擴容需求。
在 Consensus 層上面也就是 Storage Service 的最上層,便是我們的Storage Interfaces,這一層定義了一系列和圖相關的 API。 這些 API 請求會在這一層被翻譯成一組針對相應 Partition 的 KV 操作。正是這一層的存在,使得我們的存儲服務變成了真正的圖存儲,否則,Storage Service 只是一個 KV 存儲罷了。而 Nebula 沒把 KV 作為一個服務單獨提出,其最主要的原因便是圖查詢過程中會涉及到大量計算,這些計算往往需要使用圖的 Schema,而 KV 層是沒有數據 Schema 概念,這樣設計會比較容易實現計算下推。
1.2 Nebula Graph 存儲介紹
Nebula Graph 在 2.0 中,對存儲結構進行了改進,其包含點、邊和索引的存儲結構,接下來我們將簡單回顧一下 2.0 的存儲結構。通過存儲結構的解釋,大家基本也可以簡單了解 Nebula Graph 的數據和索引掃描原理。
1.2.1 Nebula 數據存儲結構
Nebula 數據的存儲包含「點」和「邊」的存儲,「點」 和 「邊」 的存儲均是基於 KV 模型存儲,這裡我們主要介紹其 Key 的存儲結構,其結構如下所示
Type: 1 個位元組,用來表示 key 的類型,當前的類型有 vertex、edge、index、system 等。PartID: 3 個位元組,用來表示數據分片 partition,此欄位主要用於 partition 重新分布(balance)時方便根據前綴掃描整個 partition 數據VertexID: n 個位元組, 出邊裡面用來表示源點的 ID, 入邊裡面表示目標點的 ID。Edge Type: 4 個位元組, 用來表示這條邊的類型,如果大於 0 表示出邊,小於 0 表示入邊。Rank: 8 個位元組,用來處理同一種類型的邊存在多條的情況。用戶可以根據自己的需求進行設置,這個欄位可存放交易時間、交易流水號、或某個排序權重。PlaceHolder: 1 個位元組,對用戶不可見,未來實現分散式做事務的時候使用。TagID:4 個位元組,用來表示 tag 的類型。
1.2.1.1 點的存儲結構
| Type (1 byte) | PartID (3 bytes) | VertexID (n bytes) | TagID (4 bytes) |
|---|
1.2.1.2 邊的存儲結構
| Type (1 byte) | PartID (3 bytes) | VertexID (n bytes) | EdgeType (4 bytes) | Rank (8 bytes) | VertexID (n bytes) | PlaceHolder (1 byte) |
|---|
1.2.2 Nebula 索引存儲結構
- props binary (n bytes):tag 或 edge 中的 props 屬性值。如果屬性為 NULL,則會填充 0xFF。
- nullable bitset (2 bytes):標識 prop 屬性值是否為 NULL,共有 2 bytes(16 bit),由此可知,一個 index 最多可以包含 16 個欄位。
1.2.2.1 tag index 存儲結構
| Type (1 byte) | PartID (3 bytes) | IndexID (4 bytes) | props binary (n bytes) | nullable bitset (2 bytes) | VertexID (n bytes) |
|---|
1.2.2.2 edge index 存儲結構
| Type (1 byte) | PartID (3 bytes) | IndexID (4 bytes) | props binary (n bytes) | nullable bitset (2 bytes) | VertexID (n bytes) | Rank (8 bytes) | VertexID (n bytes) |
|---|
1.3 借用第三方全文搜索引擎的原因
由以上的存儲結構推理可以看出,如果我們想要對某個 prop 欄位進行文本的模糊查詢,都需要進行一個 full table scan 或 full index scan,然後逐行過濾,由此看來,查詢性能將會大幅下降,數據量大的情況下,很有可能還沒掃描完畢就出現記憶體溢出的情況。另外,如果將 Nebula 索引的存儲模型設計為適合文本搜索的倒排索引模型,那將背離 Nebula 索引初始的設計原則。經過一番調研和討論,所謂術業有專攻,文本搜索的工作還是交給外部的第三方全文搜索引擎來做,在保證查詢性能的基礎上,同時也降低了 Nebula 內核的開發成本。
2 目標
2.1 功能
2.0 版本我們只對 LOOKUP 支援了文本搜索功能。也就是說基於 Nebula 的內部索引,藉助第三方全文搜索引擎來完成 LOOKUP 的文本搜索功能。對於第三方全文引擎來說,目前只使用了一些基本的數據導入、查詢等功能。如果是要做一些複雜的、純文本的查詢計算的話,Nebula 目前的功能還有待完善和改進,期待廣大的社區用戶提出寶貴的建議。目前所支援的文本搜索表達式如下:
- 模糊查詢
- 前綴查詢
- 通配符查詢
- 正則表達式查詢
2.2 性能
這裡所說的性能,指數據同步性能和查詢性能。
- 數據同步性能:既然我們使用了第三方的全文搜索引擎,那不可避免的是需要在第三方全文搜索引擎中也保存一份數據。經過驗證,第三方全文搜索引擎的導入性能要低於 Nebula 自身的數據導入性能,為了不影響 Nebula 自身的數據導入性能,我們通過非同步數據同步的方案來進行第三方全文搜索引擎的數據導入工作。具體的數據同步邏輯我們將在以下章節中詳細介紹。
- 數據查詢性能:剛剛我們提到了,如果不藉助第三方全文搜索引擎,Nebula 的文本搜索將是一場噩夢。目前
LOOKUP中通過第三方全文引擎支援了文本搜索,不可避免的性能會慢於 Nebula 原生的索引掃描,有時甚至第三方全文引擎自身的查詢都會很慢,此時我們需要有一個時效機制來保證查詢性能。即LIMIT和TIMEOUT,將在下列章節中詳細介紹。
3 名詞解釋
| 名稱 | 說明 |
|---|---|
| Tag | 用於點上的屬性結構,一個 vertex 可以附加多個 tag,以 tagId 標示。 |
| Edge | 類似於 tag,edge 是用於邊上的屬性結構,以 edgetype 標示。 |
| Property | tag 或 edge 上的屬性值,其數據類型由 tag 或 edge 的結構確定。 |
| Partition | Nebula Graph 的最小邏輯存儲單元,一個 Storage Engine 可包含多個 partition。Partition 分為 leader 和 follower 的角色,raftex 保證了 leader 和 follower 之間的數據一致性。 |
| Graph space | 每個 graph space 是一個獨立的業務 graph 單元,每個 graph space 有其獨立的 tag 和 edge 集合。一個 Nebula Graph 集群中可包含多個 graph space。 |
| Index | 下文中出現的 index 指 Nebula Graph 中點和邊上的屬性索引。其數據類型依賴於 tag 或 edge。 |
| TagIndex | 基於 tag 創建的索引,一個 tag 可以創建多個索引。因暫不支援複合索引,因此一個索引只可以基於一個 tag。 |
| EdgeIndex | 基於 edge 創建的索引。同樣,一個 edge 可以創建多個索引,但一個索引只可以基於一個 edge。 |
| Scan Policy | index 的掃描策略,往往一條查詢語句可以有多種索引的掃描方式,但具體使用哪種掃描方式需要 scan policy 來決定。 |
| Optimizer | 對查詢條件進行優化,例如對 WHERE 子句的表達式樹進行子表達式節點的排序、分裂、合併等。其目的是獲取更高的查詢效率。 |
4 實現邏輯
目前我們兼容的第三方全文搜索引擎是 ElasticSearch,此章節中主要圍繞 ElasticSearch 來進行描述。
4.1 存儲結構
4.1.1 DocID
| partId(10 bytes) | schemaId(10 bytes) | encoded_columnName(32 bytes) | encoded_val(max 344 bytes) |
|---|
- partId:對應於 Nebula 的 partition ID,當前的 2.0 版本中還沒有用到,主要用於今後的查詢下推和 es routing 機制。
- schemaId:對應於 Nebula 的 tagId 或 edgetype。
- encoded_columnName:對應於 tag 或 edge 中的 column name,此處做了一個 md5 的編碼,用以避免 ES DocID 中不兼容的字元。
- encoded_val 之所以最大為 344 個 byte,是因為 prop value 做了一個 base64 的編碼,用於解決 prop 中存在某些 docId 不支援的可見字元的問題。實際的 val 大小被限制在 256 byte。這裡為什麼會將長度限制在 256?設計之初,主要的目的是完成 LOOKUP 中的文本搜索功能。基於 Nebula 自身的 index,其長度也有限制,類似傳統關係資料庫 MySQL 一樣,其索引的欄位長度建議在 256 個字元之內。因此將第三次搜索引擎的長度也限制在 256 之內。此處並沒有支援長文本的全文搜索。
- ES 的 docId 最長為 512 byte,目前有大約 100 個 byte 的保留位元組。
4.1.2 Doc Fields
- schema_id:對應於 Nebula 的 tagId 或 edgetype。
- column_id:nebula tag 或 edge 中 column 的編碼。
- value:對應於 Nebula 原生索引中的屬性值。
4.2 數據同步邏輯
Leader & Listener
上邊的章節中簡單介紹了數據非同步同步的邏輯,此邏輯將在本章節中詳細介紹。介紹之前,先讓我們認識一下 Nebula 的 Leader 和 Listener。
- Leader:Nebula 本身是一個可水平擴展的分散式系統,其分散式協議是 raft。一個分區(Partition)在分散式系統中可以有多種角色,例如 Leader、Follower、Learner 等。當有新數據寫入時,會由 Leader 發起 WAL 的同步事件,將 WAL 同步給 Follower 和 Learner。當有網路異常、磁碟異常等情況發生時,其 partition 角色也會隨之改變。由此保證了分散式資料庫的數據安全。無論是 Leader、Follower,還是 Learner,都是在 nebula-storaged 進程中控制,其系統參數由配置參數
nebula-stoage.conf決定。 - Listener:不同於 Leader、Follower 和 Learner,Listener 由一個單獨的進程式控制制,其配置參數由
nebula-stoage-listener.conf決定。Listener 作為一個監聽者,會被動的接收來自於 Leader 的 WAL,並定時的將 WAL 進行解析,並調用第三方全文引擎的數據插入 API 將數據同步到第三方全文搜索引擎中。對於 ElasticSearch,Nebula 支援PUT和BULK介面。
接下來我們介紹一下數據同步邏輯:
- 通過 Client 或 Console 插入 vertex 或 edge
- graph 層通過 Vertex ID 計算出相關 partition
- graph 層通過 storageClient 將
INSERT請求發送到相關 Partition 的 Leader - Leader 解析
INSERT請求,並將 WAL 同步到 Listener 中 - Listener 會定時處理新同步來的 WAL,並解析 WAL,獲取 tag 或 edge 中欄位類型為 string 的屬性值。
- 將 tag 或 edge 的元數據和屬性值組裝成 ElasticSearch 兼容的數據結構
- 通過 ElasticSearch 的
PUT或BULK介面寫入到 ElasticSearch 中。 - 如果寫入失敗,則回到第 5 步,繼續重試失敗的 WAL,直到寫入成功。
- 寫入成功後,記錄成功的 Log ID 和 Term ID,做為下次 WAL 同步的起始值。
- 回到第 5 步的定時器,處理新的 WAL。
在以上步驟中,如果因為 ElasticSearch 集群掛掉,或 Listener 進程掛掉,則停止 WAL 同步。當系統恢復後,會接著上次成功的 Log ID 繼續進行數據同步。在這裡有一個建議,需要 DBA 通過外部監控工具實時監控 ES 的運行狀態,如果 ES 長期處於無效狀態,會導致 Listener 的 log 日誌暴漲,並且無法做正常的查詢操作。
4.3 查詢邏輯
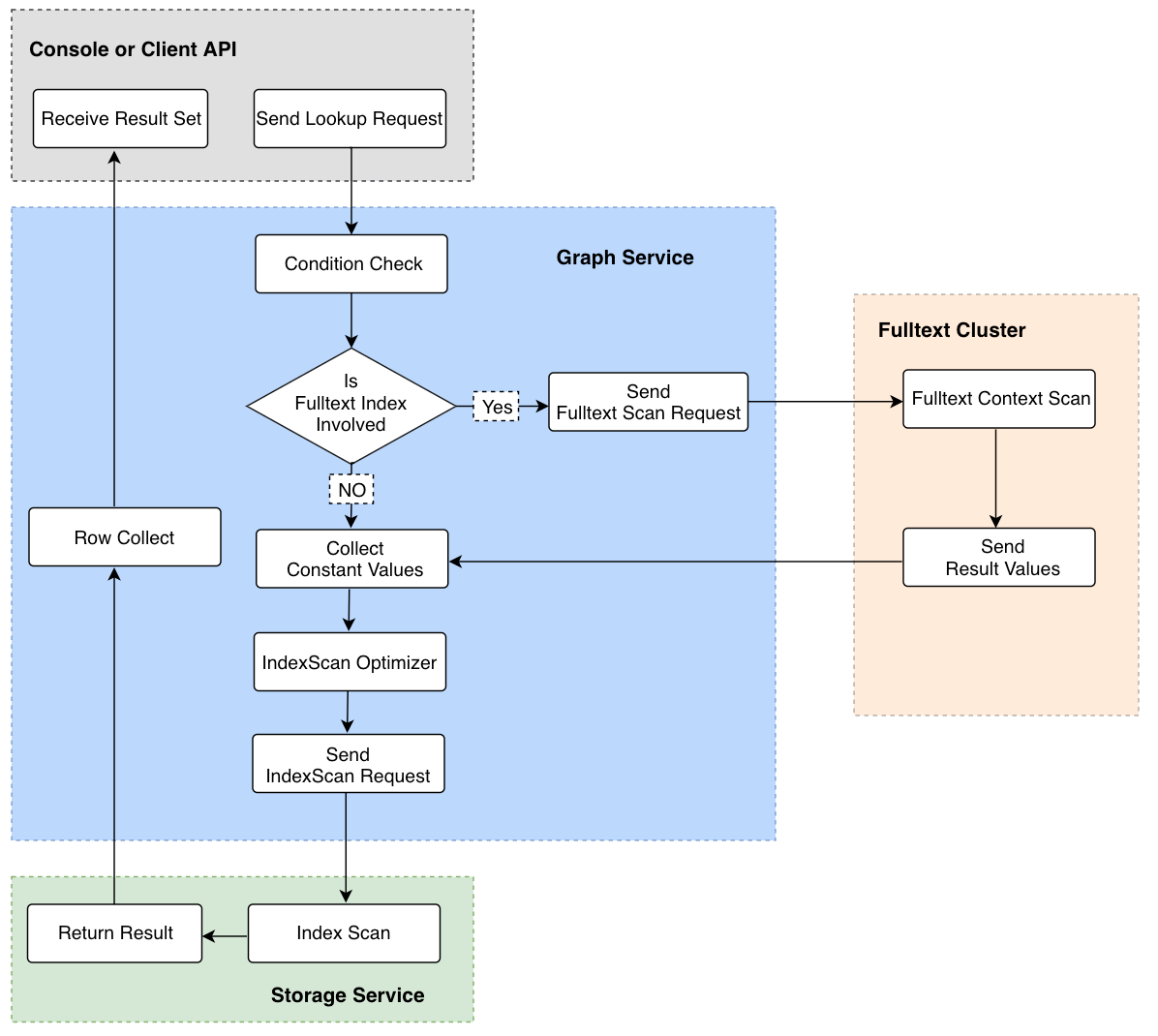
由上圖可知,其文本搜索的關鍵步驟是 「Send Fulltext Scan Request」 → “Fulltext Cluster” → “Collect Constant Values” → “IndexScan Optimizer”。
- Send Fulltext Scan Request: 根據查詢條件、schema ID、Column ID 生成全文索引的查詢請求(即封裝成 ES 的 CURL 命令)
- Fulltext Cluster:發送查詢請求到 ES,並獲取 ES 的查詢結果。
- Collect Constant Values:將返回的查詢結果作為常量值,生成 Nebula 內部的查詢表達式。例如原始的查詢請求是查詢 C1 欄位中以「A」開頭的屬性值,如果返回的結果中包含 「A1」 和 “A2″兩條結果,那麼在這一步,將會解析為 neubla 的表達式
C1 == "A1" OR C1 == "A2"。 - IndexScan Optimizer:根據新生成的表達式,基於 RBO 找出最優的 Nebula 內部 Index,並生成最優的執行計劃。
- 在”Fulltext Cluster”這一步中,可能會有查詢性能慢,或海量數據返回的情況,這裡我們提供了
LIMIT和TIMEOUT機制,實時中斷 ES 端的查詢。
5 演示
5.1 部署外部ES集群
對於 ES 集群的部署,這裡不再詳細介紹,相信大家都很熟悉了。這裡需要說明的是,當 ES 集群啟動成功後,我們需要對 ES 集群創建一個通用的 template,其結構如下:
{
"template": "nebula*",
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"properties" : {
"tag_id" : { "type" : "long" },
"column_id" : { "type" : "text" },
"value" :{ "type" : "keyword"}
}
}
}
5.2 部署 Nebula Listener
- 根據實際環境,修改配置參數
nebula-storaged-listener.conf - 啟動 Listener:
./bin/nebula-storaged --flagfile ${listener_config_path}/nebula-storaged-listener.conf
5.3 註冊 ElasticSearch 的客戶端連接資訊
nebula> SIGN IN TEXT SERVICE (127.0.0.1:9200);
nebula> SHOW TEXT SEARCH CLIENTS;
+-------------+------+
| Host | Port |
+-------------+------+
| "127.0.0.1" | 9200 |
+-------------+------+
| "127.0.0.1" | 9200 |
+-------------+------+
| "127.0.0.1" | 9200 |
+-------------+------+
5.4 創建 Nebula Space
CREATE SPACE basketballplayer (partition_num=3,replica_factor=1, vid_type=fixed_string(30));
USE basketballplayer;
5.5 添加 Listener
nebula> ADD LISTENER ELASTICSEARCH 192.168.8.5:46780,192.168.8.6:46780;
nebula> SHOW LISTENER;
+--------+-----------------+-----------------------+----------+
| PartId | Type | Host | Status |
+--------+-----------------+-----------------------+----------+
| 1 | "ELASTICSEARCH" | "[192.168.8.5:46780]" | "ONLINE" |
+--------+-----------------+-----------------------+----------+
| 2 | "ELASTICSEARCH" | "[192.168.8.5:46780]" | "ONLINE" |
+--------+-----------------+-----------------------+----------+
| 3 | "ELASTICSEARCH" | "[192.168.8.5:46780]" | "ONLINE" |
+--------+-----------------+-----------------------+----------+
5.6 創建 Tag、Edge、Nebula Index
此時建議欄位 「name」 的長度應該小於 256,如果業務允許,建議 player 中欄位 name 的類型定義為 fixed_string 類型,其長度小於 256。
nebula> CREATE TAG player(name string, age int);
nebula> CREATE TAG INDEX name ON player(name(20));
5.7 插入數據
nebula> INSERT VERTEX player(name, age) VALUES \
"Russell Westbrook": ("Russell Westbrook", 30), \
"Chris Paul": ("Chris Paul", 33),\
"Boris Diaw": ("Boris Diaw", 36),\
"David West": ("David West", 38),\
"Danny Green": ("Danny Green", 31),\
"Tim Duncan": ("Tim Duncan", 42),\
"James Harden": ("James Harden", 29),\
"Tony Parker": ("Tony Parker", 36),\
"Aron Baynes": ("Aron Baynes", 32),\
"Ben Simmons": ("Ben Simmons", 22),\
"Blake Griffin": ("Blake Griffin", 30);
5.8 查詢
nebula> LOOKUP ON player WHERE PREFIX(player.name, "B");
+-----------------+
| _vid |
+-----------------+
| "Boris Diaw" |
+-----------------+
| "Ben Simmons" |
+-----------------+
| "Blake Griffin" |
+-----------------+
6 問題跟蹤與解決技巧
對於系統環境的搭建過程中,可能某個步驟錯誤導致功能無法正常運行,在之前的用戶回饋中,我總結了三類可能發生的錯誤,對分析和解決問題的技巧概況如下
- Listener 無法啟動,或啟動後不能正常工作
- 檢查 Listener 配置文件,確保 Listener 的
IP:Port不和已有的 nebula-storaged 衝突 - 檢查 Listener 配置文件,確保 Meta 的
IP:Port正確,這個要和 nebula-storaged 中保持一致 - 檢查 Listener 配置文件,確保 pids 目錄和 logs 目錄獨立,不要和 nebula-storaged 衝突
- 當啟動成功後,因為配置錯誤,修改了配置,再重啟後仍然無法正常工作,此時需要清理 meta 的相關元數據。對此提供了操作命令,請參考 nebula 的幫助手冊:文檔鏈接。
- 檢查 Listener 配置文件,確保 Listener 的
- 數據無法同步到 ES 集群
- 檢查 Listener 是否從 Leader 端接受到了 WAL,可以查看
nebula-storaged-listener.conf配置文件中–listener_path的目錄下是否有文件。 - 打開 vlog(
UPDATE CONFIGS storage:v=3),並關注 log 中 CURL 命令是否執行成功,如果有錯誤,可能是 ES 配置或 ES 版本兼容性錯誤
- 檢查 Listener 是否從 Leader 端接受到了 WAL,可以查看
- ES 集群中有數據,但是無法查詢出正確的結果
- 同樣打開 vlog (
UPDATE CONFIGS graph:v=3),關注 graph 的 log,檢查 CURL 命令是什麼原因執行失敗 - 查詢時,只能識別小寫字元,不能識別大寫字元。可能是 ES 的 template 創建錯誤。請對照 nebula 幫助手冊進行創建:文檔鏈接。
- 同樣打開 vlog (
7 TODO
- 針對特定的 tag 或 edge 建立全文索引
- 全文索引的重構(REBUILD)
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~
想要和其他大廠交流圖資料庫技術嗎?NUC 2021 大會等你來交流:NUC 2021 報名傳送門

