ElasticSearch7.3學習(二十六)—-搜索(Search)參數總結、結果跳躍(bouncing results)問題解析
- 2022 年 5 月 18 日
- 筆記
- 【G】ElasticSearch
1、preference
首先引入一個bouncing results問題,兩個document排序,field值相同;不同的shard上,可能排序不同;每次請求輪詢打到不同的replica shard上;每次頁面上看到的搜索結果的排序都不一樣。這就是bouncing result,也就是跳躍的結果。
這個問題出現最多的地方就是timestamp進行排序,如下圖所示,可能導致每次返回的結果不一致。
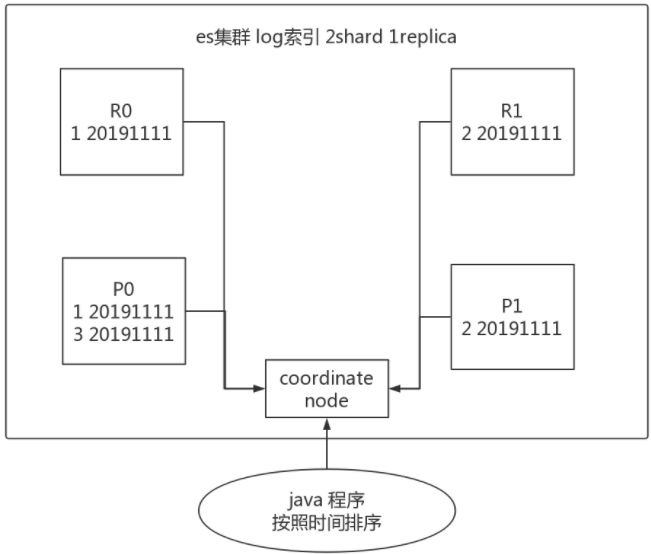
比如當你使用一個timestamp欄位對結果進行排序,因為es中時間格式為%Y-%m-%d,那麼同樣時間的數據會有很多。es如果不做任何設置,將會按round-robined的方式從primary和replica里取了再排序,這樣結果就不能保證每次都一樣的。畢竟primary有的replica里不一定有,尤其是在不停往es里存放數據的情況。
如果有兩份文檔擁有相同的timestamp,因為搜索請求是以一種循環(round-robin)的方式被可用的分片拷貝進行處理的,因此這兩份文檔的返回順序可能因為處理的分片不一樣而不同,比如主分片處理的順序和副本分片處理的順序就可能不一樣。這就是結果跳躍問題:每次用戶刷新頁面都會發現結果的順序不一樣。
解決方案就是設置preference參數,使每個user每次搜索的時候,都使用同一個replica shard去執行,就不會看到bouncing results了
preference參數決定了哪些shard會被用來執行搜索操作
_primary:發送到集群的相關操作請求只會在主分片上執行。_primary_first:指查詢會先在主分片中查詢,如果主分片找不到(掛了),就會在副本中查詢。_replica:發送到集群的相關操作請求只會在副本上執行。_replica_first:指查詢會先在副本中查詢,如果副本找不到(掛了),就會在主分片中查詢。_local: 指查詢操作會優先在本地節點有的分片中查詢,沒有的話再在其它節點查詢。_prefer_nodes:abc,xyz:在提供的節點上優先執行(在這種情況下為』abc』或』xyz』)_shards:2,3:限制操作到指定的分片。 (2和「3」)。這個偏好可以與其他偏好組合,但必須首先出現:_shards:2,3 | _primary_only_nodes:node1,node2:指在指定id的節點裡面進行查詢,如果該節點只有要查詢索引的部分分片,就只在這部分分片中查找,不同節點之間用「,」分隔。
custom(自定義):注意自定義的preference參數不能以下劃線”_”開頭。當preference為自定義時,即該參數不為空,且開頭不以「下劃線」開頭時,特別注意:如果以用戶query作為自定義preference時,一定要處理以下劃線開頭的情況,這種情況下如果不屬於以上8種情況,則會拋出異常。
GET /_search?preference=_shards:2,32、timeout
已經講解過原理了,鏈接:ElasticSearch7.3學習(十七)—-搜索結果欄位解析及time_out欄位解析
簡單來說就是限定在一定時間內,將部分獲取到的數據直接返回,避免查詢耗時過長
GET /_search?timeout=10ms3、routing
詳情請見鏈接:ElasticSearch7.3學習(六)—-文檔(document)內部機制詳解,數據路由部分
document文檔路由,_id路由,routing=user_id,這樣的話可以讓同一個user對應的數據到一個shard上去
GET /_search?routing=user1234、search_type
在講這四種搜索類型的區別之前, 先分析一下分散式搜索背景介紹:
ES 天生就是為分散式而生, 但分散式有分散式的缺點。 比如要搜索某個單詞, 但是數據卻分別在 5 個分片(Shard)上面, 這 5 個分片可能在 5 台主機上面。 因為全文搜索天生就要排序( 按照匹配度進行排名) ,但數據卻在 5 個分片上, 如何得到最後正確的排序呢?
ES是這樣做的, 大概分兩步:
- ES 客戶端將會同時向 5 個分片發起搜索請求。
- 這 5 個分片基於本分片的內容獨立完成搜索, 然後將符合條件的結果全部返回。
客戶端將返回的結果進行重新排序和排名,最後返回給用戶。也就是說,ES的一次搜索,是一次scatter/gather過程(這個跟mapreduce也很類似)
然而這其中有兩個問題:
1、 數量問題。 比如, 用戶需要搜索”衣服”, 要求返回符合條件的前 10 條。 但在 5個分片中, 可能都存儲著衣服相關的數據。 所以 ES 會向這 5 個分片都發出查詢請求, 並且要求每個分片都返回符合條件的 10 條記錄。當ES得到返回的結果後,進行整體排序,然後取最符合條件的前10條返給用戶。 這種情況, ES 中 5 個 shard 最多會收到 10*5=50條記錄, 這樣返回給用戶的結果數量會多於用戶請求的數量。
2、 排名問題。 上面說的搜索, 每個分片計算符合條件的前 10 條數據都是基於自己分片的數據進行打分計算的。計算分值使用的詞頻和文檔頻率等資訊都是基於自己分片的數據進行的, 而 ES 進行整體排名是基於每個分片計算後的分值進行排序的(相當於打分依據就不一樣, 最終對這些數據統一排名的時候就不準確了), 這就可能會導致排名不準確的問題。如果我們想更精確的控制排序, 應該先將計算排序和排名相關的資訊( 詞頻和文檔頻率等打分依據) 從 5 個分片收集上來, 進行統一計算, 然後使用整體的詞頻和文檔頻率為每個分片中的數據進行打分, 這樣打分依據就一樣了。
這兩個問題, ES 也沒有什麼較好的解決方法, 最終把選擇的權利交給用戶, 方法就是在搜索的時候指定 search type。
4.1 query and fetch
向索引的所有分片 ( shard)都發出查詢請求, 各分片返回的時候把元素文檔 ( document)和計算後的排名資訊一起返回。
優點:這種搜索方式是最快的。因為相比後面的幾種es的搜索方式,這種查詢方法只需要去shard查詢一次。
缺點:返回的數據量不準確, 可能返回(N*分片數量)的數據並且數據排名也不準確,同時各個shard返回的結果的數量之和可能是用戶要求的size的n倍。
4.2 query then fetch
es 默認的搜索方式,如果你搜索時, 沒有指定搜索方式, 就是使用的這種搜索方式。 這種搜索方式, 大概分兩個步驟:
1、先向所有的 shard 發出請求, 各分片只返迴文檔 id(注意, 不包括文檔 document)和排名相關的資訊(也就是文檔對應的分值), 然後按照各分片返回的文檔的分數進行重新排序和排名, 取前 size 個文檔。
2、根據文檔 id 去相關的 shard 取 document。 這種方式返回的 document 數量與用戶要求的大小是相等的。
優點:返回的數據量是準確的。
缺點:性能一般,並且數據排名不準確。
4.3 DFS query and fetch
這種方式比第一種方式多了一個 DFS 步驟,有這一步,可以更精確控制搜索打分和排名。也就是在進行查詢之前, 先對所有分片發送請求, 把所有分片中的詞頻和文檔頻率等打分依據全部匯總到一塊, 再執行後面的操作、
優點:數據排名準確
缺點:性能一般,返回的數據量不準確, 可能返回(N*分片數量)的數據
4.4 DFS query then fetch
比第 2 種方式多了一個 DFS 步驟。也就是在進行查詢之前, 先對所有分片發送請求, 把所有分片中的詞頻和文檔頻率等打分依據全部匯總到一塊, 再執行後面的操作、
優點:返回的數據量是準確的;數據排名準確
缺點:能最差,這個最差只是表示在這四種查詢方式中性能最慢, 也不至於不能忍受,如果對查詢性能要求不是非常高, 而對查詢準確度要求比較高的時候可以考慮這個
4.5 DFS過程
從 es 的官方網站我們可以發現, DFS 其實就是在進行真正的查詢之前, 先把各個分片的詞頻率和文檔頻率收集一下, 然後進行詞搜索的時候, 各分片依據全局的詞頻率和文檔頻率進行搜索和排名。 顯然如果使用 DFS_QUERY_THEN_FETCH 這種查詢方式, 效率是最低的,因為一個搜索, 可能要請求 3 次分片。 但使用 DFS 方法, 搜索精度是最高的。
總結一下, 從性能考慮 QUERY_AND_FETCH 是最快的, DFS_QUERY_THEN_FETCH 是最慢的。從搜索的準確度來說, DFS 要比非 DFS 的準確度更高。

