ELK搭建以及運行和ElasticStarch的詳細使用(7.X版本之上)
ELK初體驗
1.官網
2.需要安裝JDK
ElasticSearch 是一個基於Lucene的搜索伺服器。它提供了一個分散式多用戶能力的全文搜索引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作為Apache許可條款下的開放源碼發布,是當前流行的企業級搜索引擎。設計用於雲計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用方便。
所採用的是倒排索引
1.正排索引: 由文檔指向關鍵詞
文檔–> 單詞1 ,單詞2
單詞1 出現的次數 單詞出現的位置; 單詞2 單詞2出現的位置 …
2.倒排索引: 由關鍵詞指向文檔
單詞1—>文檔1,文檔2,文檔3
單詞2—>文檔1,文檔2
倒排的優缺點和正排的優缺點整好相反。倒排在構建索引的時候較為耗時且維護成本較高,但是搜索耗時短。
我們使用Elasticsearch來完成日誌的檢索、分析工作。
bin目錄下
elasticsearch-service.bat後面還可以執行這些命令
install: 安裝Elasticsearch服務
remove: 刪除已安裝的Elasticsearch服務(如果啟動則停止服務)
start: 啟動Elasticsearch服務(如果已安裝)
stop: 停止服務(如果啟動)
manager:啟動GUI來管理已安裝的服務
Logstash 是一個用於管理日誌和事件的工具,你可以用它去收集日誌、轉換日誌、解析日誌並將他們作為數據提供給其它模組調用,例如搜索、存儲等。
我們使用Logstash來完成日誌的解析、存儲工作。
Kibana 是一個優秀的前端日誌展示框架,它可以非常詳細的將日誌轉化為各種圖表,為用戶提供強大的數據可視化支援。
我們使用Kibana來進行日誌數據的展示工作。
Beats:安裝在每台需要收集日誌的伺服器上,將日誌發送給Logstash進行處理,所以Beats是一個「搬運工」,將你的日誌搬運到日誌收集伺服器上。Beats分為很多種,每一種收集特定的資訊。常用的是Filebeat,監聽文件變化,傳送文件內容。一般日誌系統使用Filebeat就夠了。
使用分析
1.優點?
ELK 是 Elasticsearch、Logstash、Kibana 三個開源軟體的組合。在實時數據檢索和分析場合,三者通常是配合共用,而且又都先後歸於 Elastic.co 公司名下,故有此簡稱。
ELK 在最近兩年迅速崛起,成為機器數據分析,或者說實時日誌處理領域,開源界的第一選擇。和傳統的日誌處理方案相比,ELK Stack 具有如下幾個優點:
- 處理方式靈活:Elasticsearch 是實時全文索引;
- 配置簡易上手
- 檢索性能高效:
- 集群線性擴展:(分散式功能);
- 前端操作炫麗:Kibana 介面上,只需要點擊滑鼠,就可以完成搜索、聚合功能,生成炫麗的儀錶板
- 有很多相關的 配套插件
- ………
2.缺點?
- 數據不是實時性(近實時性)
- 功能點:告警、許可權管理、關聯分析等還是不太行
- 缺點也有:各個版本的收費情況 (//blog.csdn.net/vkingnew/article/details/91549698)
- 還是 比較吃記憶體的 吃配置的
- ………
3.為什麼使用? 用途 ?
1
- 數據(日誌)的日益增多
- 開源
- ELK 本身非常易用,有一個非常好的社區
- ………
2
- 問題排查
- 監控和預警
- 關聯事件
- 數據分析
4.一般的使用場景是?
大數據日誌分析, 大量的訂單數據等等, 分散式整合收集各種日誌 統一查看等等
注意一些點
- 修改默認的 Elasticsearch 集群名稱
- 不要暴露 Elasticsearch 在公網上
- 不要以 root 身份運行 Elasticsearch
- 定期對 Elasticsearch 進行備份
- 安裝Elasticsearch的許可權系統插件-SearchGuard
- 利用作業系統防火牆設置規避9200埠開放問題
離線的方式(也是所推薦的)
常見的三種
· Beats ==> Elasticsearch ==> Kibana
· Beats ==> Logstash ==> Elasticsearch ==> Kibana
· Beats ==> Kafka ==> Logstash ==> Elasticsearch ==>Kibana (未嘗試成功……)

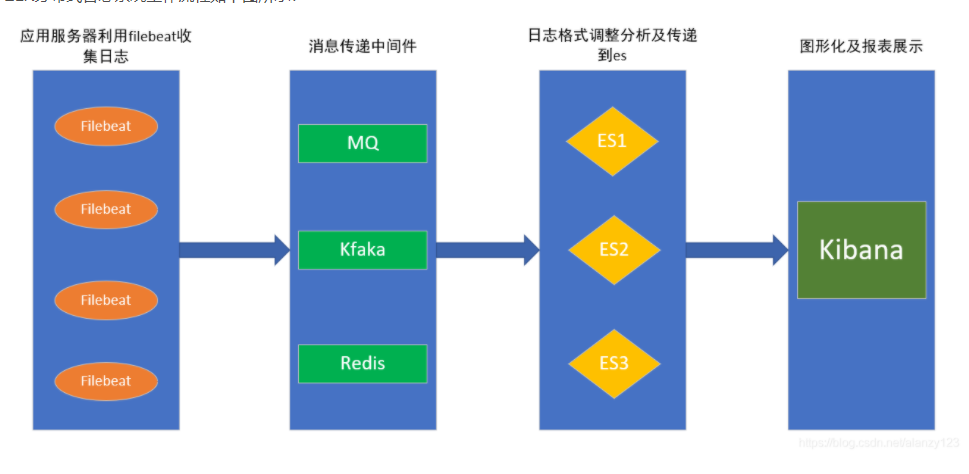
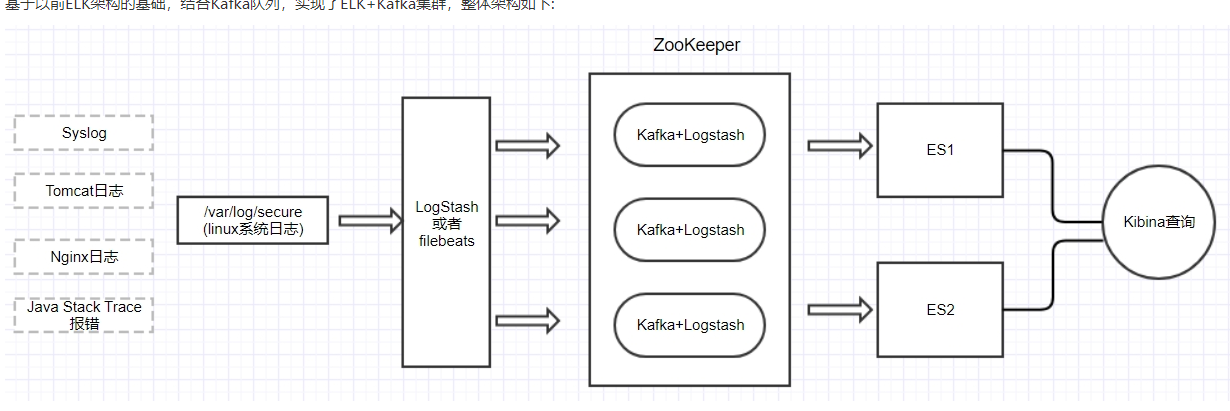
安裝包:

收集、查詢、顯示,正對應logstash、elasticsearch、kibana的功能。
6.X以上需要添加此設置
默認不支援索引類型 需要開啟
include_type_name=true
RESTFul API 請求相關內容
1.API基本格式://ip:port/<索引>/<類型>/<文檔id>
2.常用HTTP動詞:GET/PUT/POST/DELETE
欄位類型:
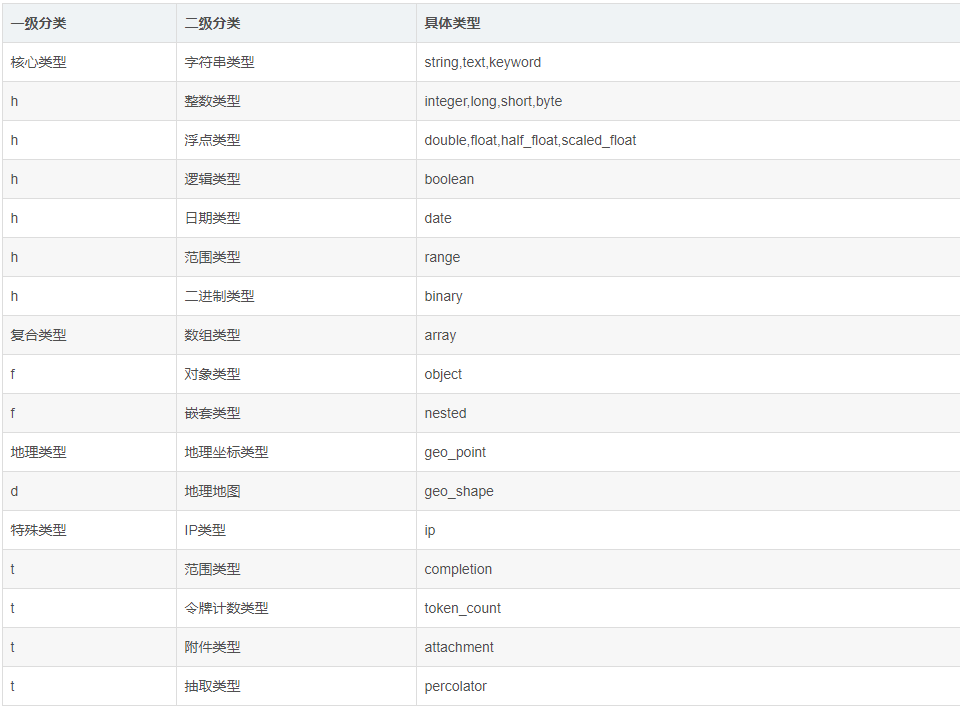
keyword類型
1:支援模糊、排序操作,不進行分詞,支援精確匹配,直接索引,支援聚合 2:keyword類型的最大支援的長度為——32766個UTF-8類型的字元,可以通過設置ignore_above指定自持字元長度,超過給定長度後的數據將不被索引,無法通過term精確匹配檢索返回結果。
3.存儲數據時候,不會分詞建立索引
text類型
1:支援模糊、排序操作,支援分詞,也可以精確查詢、全文檢索,不支援聚合 2:test類型的最大支援的字元長度無限制,適合大欄位存儲; 使用場景: 存儲全文搜索數據, 例如: 郵箱內容、地址、程式碼塊、部落格文章內容等。 默認結合standard analyzer(標準解析器)對文本進行分詞、倒排索引。 默認結合標準分析器進行詞命中、詞頻相關度打分。
存儲數據時候,會自動分詞,並生成索引(這是很智慧的,但在有些欄位裡面是沒用的,所以對於有些欄位使用text則浪費了空間
IK分詞具體可以演示(kibana 控制台演示)
使用場景: 存儲郵箱號碼、url、name、title,手機號碼、主機名、狀態碼、郵政編碼、標籤、年齡、性別等數據。 用於篩選數據(例如: select * from x where status=’open’)、排序、聚合(統計)。 直接將完整的文本保存到倒排索引中。
(PUT)創建索引(資料庫)
PUT(mappings) 創建了索引(資料庫),並且設置映射欄位資訊
1.設置映射的mappings欄位等欄位類型等
PUT
//localhost:9200/local_index/cytest/
在POST時
{
"mappings": {
"cytest": {
"id": {
"type": "long"
},
"title": {
"type": "text"
},
"content": {
"type": "keyword"
},
"date": {
"type": "date",
"fromat": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
2. 往對應的映射欄位裡面賦值(鏈接(POST //localhost:9200/local_idx_1/cytest/))
下資料庫_表下增加一個數據)
{
"id": "1",
"title": "測試數據1",
"content": "大意了沒有閃",
"date": "2020-11-04"
}
修改的話 得到_id 拼到鏈接後面 傳入數據就是修改
3.簡單查詢 POST (//localhost:9200/local_index/cytest/_search/)
POST //127.0.0.1:9200/myname/_search
{
"query":{
"match":{
"name":"zhangsan"
}
}
}
{
"query":{
"term":{
"Title":"徐若蓬稚"
}
}
}
1 term查詢(精準查詢)
terms 查詢是term的擴展,可以支援多個vlaue匹配,只需要一個匹配就可以了。
2 math查詢(分詞匹配查詢)
match查詢是按ES分詞的倒排表進行查詢,而keyword不會被分詞,match的需要跟keyword的完全匹配可以。可以用於一般性的匹配查詢。
match_all可以用於查詢全部資訊。
multi_match
multi_match是多欄位進行匹配查詢。
3 fuzzy查詢(模糊查詢)
4 wildcard(通配符查詢)
5 bool查詢(布爾查詢)
6其他知識點
取特定欄位(_source)
分頁(size ,from)
排序(sort)
具體的更多詳請訪問
//blog.csdn.net/shu616048151/article/details/102647313
關於設置欄位類型,詳情請看下面的文章
//blog.csdn.net/zx711166/article/details/81667862
欄位具體的圖如下
刪除(DELETE) //127.0.0.1:9200/索引名稱
使用Elasticsearch Sql插件的語法查詢
elasticsearch-sql的安裝
ElasticSeartch 安裝目錄下的 bin下面執行
./bin/elasticsearch-plugin install //github.com/NLPchina/elasticsearch-sql/releases/download/6.3.1.0/elasticsearch-sql-6.3.1.1.zip
參考鏈接
在下載一個插件(download and extract site.)
啟動
cd site-server npm install express –save node node-server.js
埠被佔用的話
修改 site_configuration.json 配置文件
具體詳情
elasticsearch-plugin install //github.com/NLPchina/elasticsearch-sql/releases/download/6.3.1.0/elasticsearch-sql-6.3.1.1.zip
- cd site-server
- npm install express –save
- node node-server.js
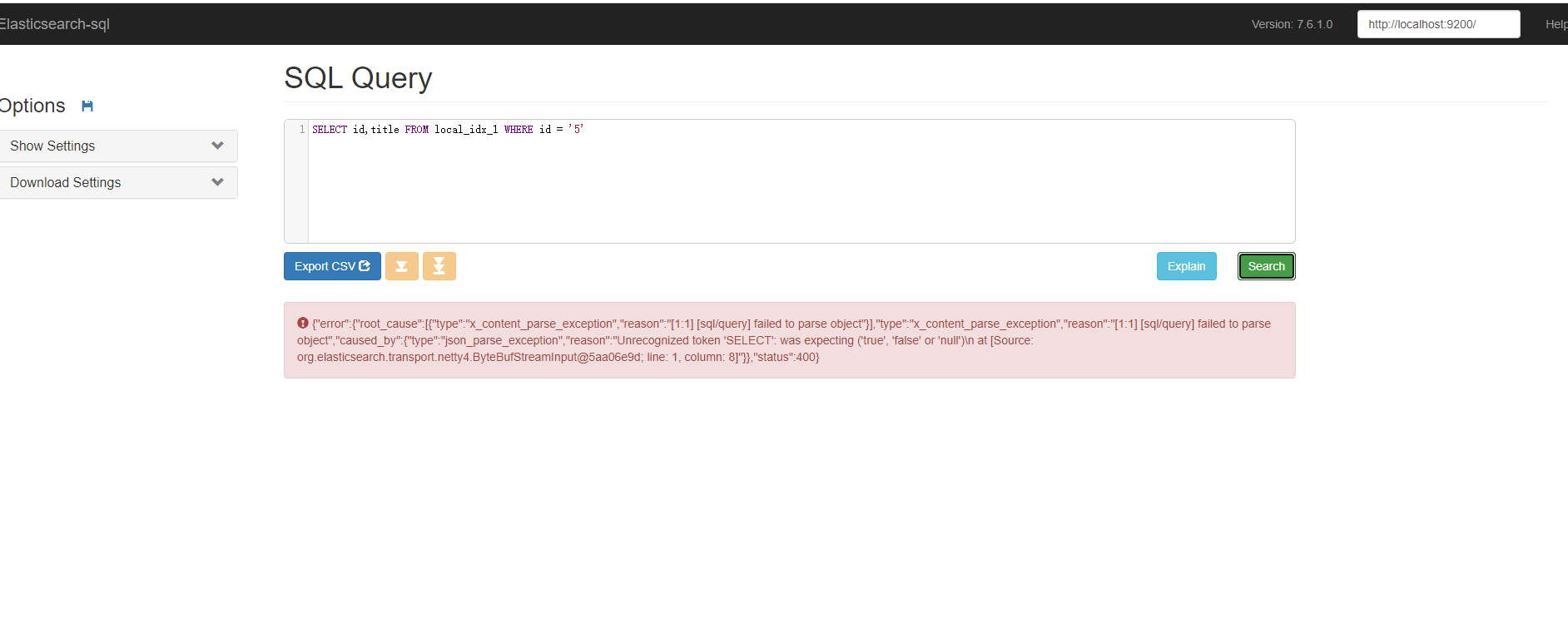
另外 演示 kibana 控制台可以演示 Sql的查詢效果
POST /_sql?format=json { “query”: “SELECT id,title,content,date FROM local_index WHERE content like ‘%哈哈%'” }
IK分詞的相關使用
1.IK分詞的下載地址(最好對應版本)
2.解壓到elasticsearch-7.6.1\plugins目錄的 新建ik 文件下就好了
3. 然後重啟elasticsearch
4.使用kibana 查看效果
1. 索引時用 ik_max_word
2. 在搜索時用 ik_smart
POST _analyze { "analyzer":"ik_max_word", "text":"我愛你中國" }
自定義分詞
1. \plugins\ik\config路徑下 創建test文件, 在創建分詞.dic文件
2. 然後 IKAnalyzer.cfg.xml 配置分詞文件路徑,如圖:
GET _analyze { “analyzer”: “ik_smart”, “text”:”年輕人不講武德” } GET _analyze { “analyzer”: “ik_smart”, “text”:”大意了沒有閃” }
3.然後 Kibana查看效果
GET _analyze
{
"analyzer": "ik_smart",
"text":"年輕人不講武德"
}
GET _analyze
{
"analyzer": "ik_smart",
"text":"大意了沒有閃"
}
C#對接使用
官方文檔地址:
ElasticSearch官方網站提供了兩個.net客戶端驅動程式
Elasticsearch.Net
NEST 更高級一點
例子採用 NEST 程式
類比傳統關係型資料庫:
//Relational DB -> Databases -> Tables -> Rows -> Columns
//Elasticsearch -> Indices -> Types -> Documents -> Fields
DB使用過程:創建資料庫->創建表(主要是設置各個欄位的屬性)->寫入數 ES使用過程:創建索引->為索引maping一個Type(同樣是設置類型中欄位的屬性)->寫入數
詳情參考文章
很實用的教程
//www.cnblogs.com/johnyong/p/12873386.html
NEST 封裝
實際運行效果圖
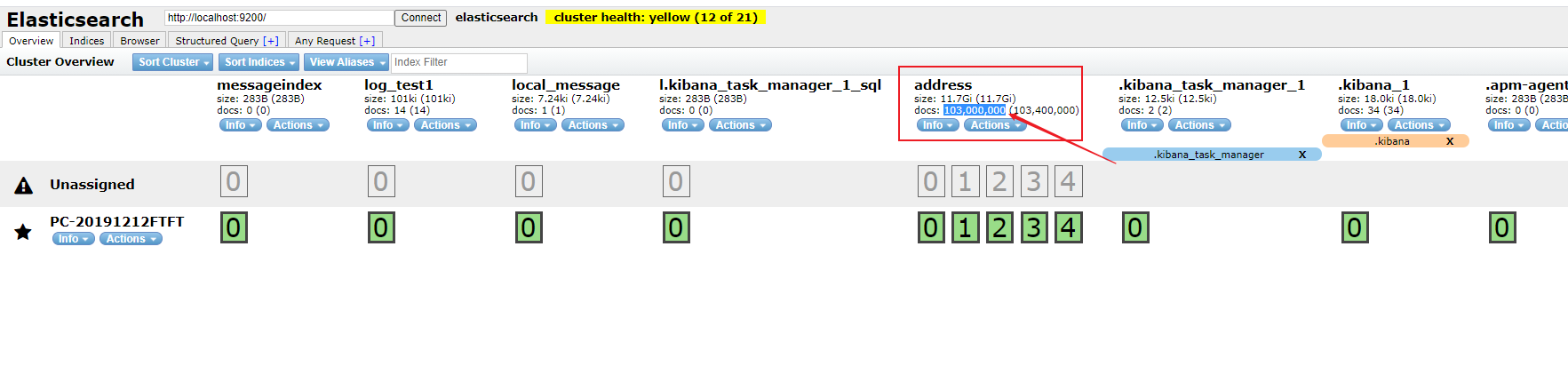
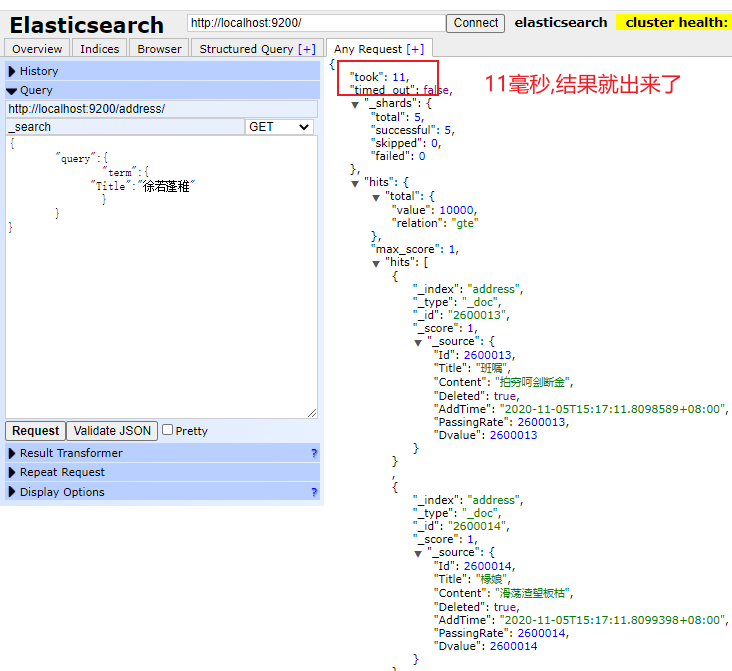
1.實際演示效果 1億千萬的數據量 毫秒查詢(沒時間插入那麼多的數據測試)
2. 具體資源 安裝包文件,.net程式碼,請聯繫部落客…..感謝大家觀看至此…謝謝
3.許多不明確的地方,或者錯誤的地方希望大家多多提意見, 很多都是資源整合,自己實踐的
