
爬蟲的基本原理
- 2022 年 10 月 14 日
- 筆記
一、爬蟲的基本原理 網絡爬蟲的價值其實就是數據的價值,在互聯網社會中,數據是無價之寶,一切皆為數據,誰擁有了大量有用的數 …
Continue Reading一、爬蟲的基本原理 網絡爬蟲的價值其實就是數據的價值,在互聯網社會中,數據是無價之寶,一切皆為數據,誰擁有了大量有用的數 …
Continue Reading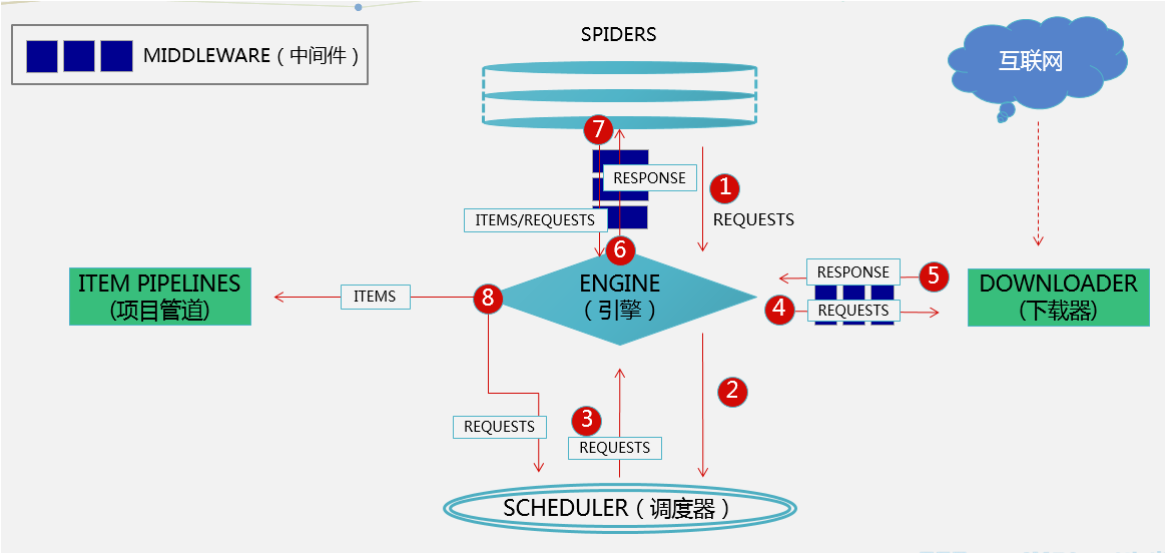
一、Scrapy 介紹 Scrapy是一個Python編寫的開源和協作的框架。起初是用於網絡頁面抓取所設計的,使用它可以 …
Continue Reading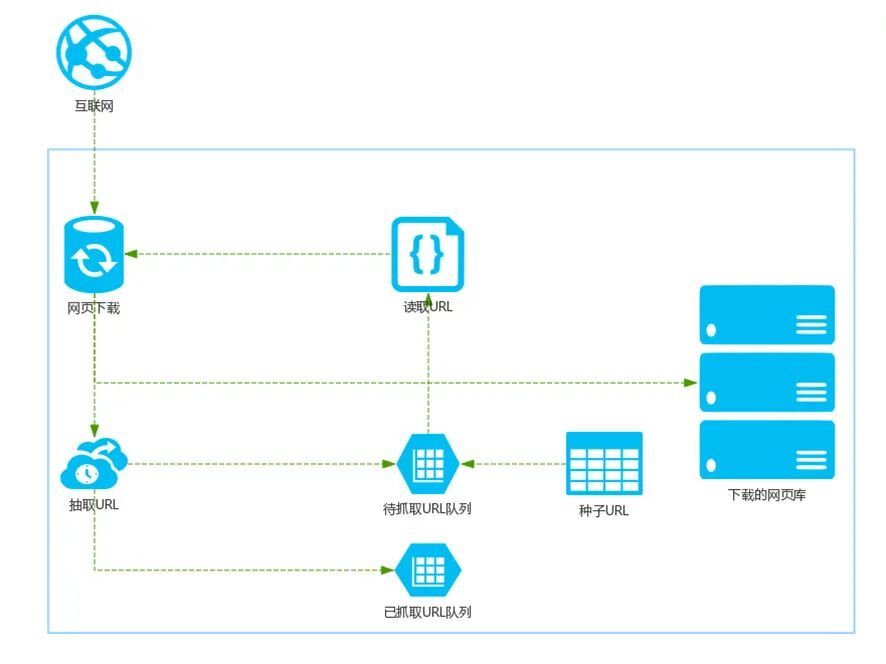
vivo 互聯網安全團隊- Xie Peng 互聯網的大數據時代的來臨,網絡爬蟲也成了互聯網中一個重要行業,它是一種自動 …
Continue Reading
Python逆向爬蟲之初體驗 網絡爬蟲是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。 說起網絡爬蟲,人們常常 …
Continue Reading
前言: 之前小編寫了一篇關於爬蟲為什麼爬取不到數據文章(文章鏈接為:Python爬蟲經常爬不到數據,或許你可以看一下小編 …
Continue Reading
檢查網頁源代碼 首先讓我們來檢查豆瓣top250的源代碼,一切網頁爬蟲都需要從這裡開始。F12打開開發者模式,在元素(e …
Continue Reading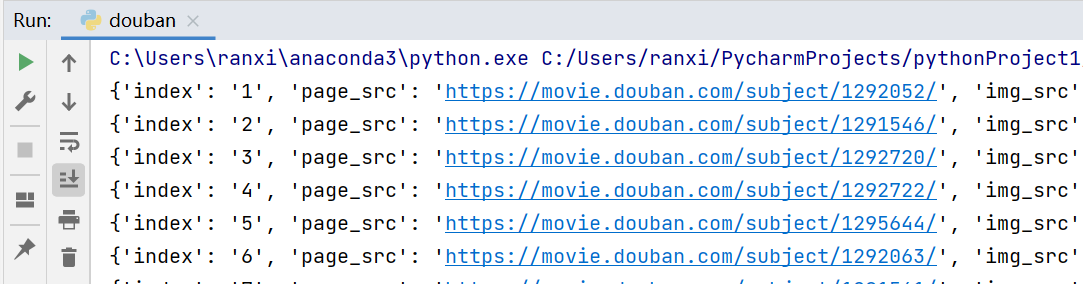
導入包 # json包 import json #正則表達式包 import re import requests fr …
Continue Reading
什麼是正則表達式? 正則表達式是一組由字母和符號組成的特殊文本,它可以用來從文本中找出滿足你想要的格式的句子。 一個正則 …
Continue Reading
摘要:本文講述如何編寫scrapy爬蟲。 本文分享自華為雲社區《學python,怎麼能不學習scrapy呢,這篇博客帶你 …
Continue Reading
目錄 selenium介紹 基本使用 selenium用法 元素操作 等待元素被加載 元素各項屬性 執行js代碼 切換選 …
Continue Reading