Python爬蟲:為什麼你爬取不到網頁數據
前言:
之前小編寫了一篇關於爬蟲為什麼爬取不到數據文章(文章鏈接為:Python爬蟲經常爬不到數據,或許你可以看一下小編的這篇文章), 但是當時小編也是胡亂編寫的,其實裏面有很多問題的,現在小編重新發佈一篇關於爬蟲爬取不到數據文章,希望各位讀者更加了解爬蟲。

1. 最基礎的爬蟲
通常編寫爬蟲代碼,使用如下三行代碼就可以實現一個網頁的基本訪問了。
from urllib import request
rsp = request.urlopen(url='某某網站')
print(rsp.read().decode('編碼'))
或者
import requests
rsp = requests.get(url='某某網站')
print(rsp.text)
但是,有的網站你使用上述方式訪問時,有可能出現一下情況:
- 直接報錯;
- 沒有報錯,但是給出相應的響應碼,如403;
- 沒有報錯,但是輸出信息沒有在瀏覽器上看到的那麼多(這有可能是網頁使用了動態加載的原因)。
2. 添加請求頭的爬蟲
上述講到的三種情況,怎樣解決呢?基本方式是添加一個請求頭(請求頭的字段通常只需添加user-agent字段即可,用來模擬瀏覽器訪問;然而有的網站用Python爬蟲來訪問時,可能還要添加其他字段,最好是把這個網頁所有請求頭字段信息全部添加上;有的網頁全部請求頭字段信息全部添加上,然而也訪問不到數據,這種情況小編也沒有什麼好的解決辦法,不知道使用selenium模塊直接操控瀏覽器是否可以,沒有試過)。
1.如用urllib模塊來訪問bilibili網站時會報錯,如下:
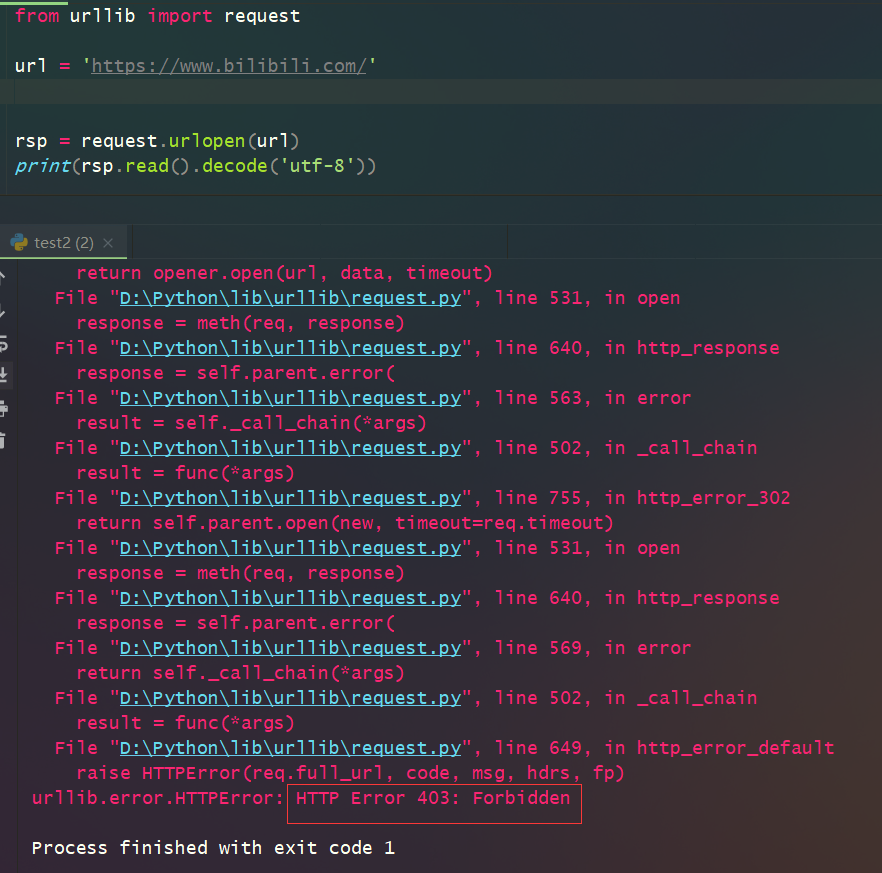
但是添加請求頭之後,就可以正常訪問了。
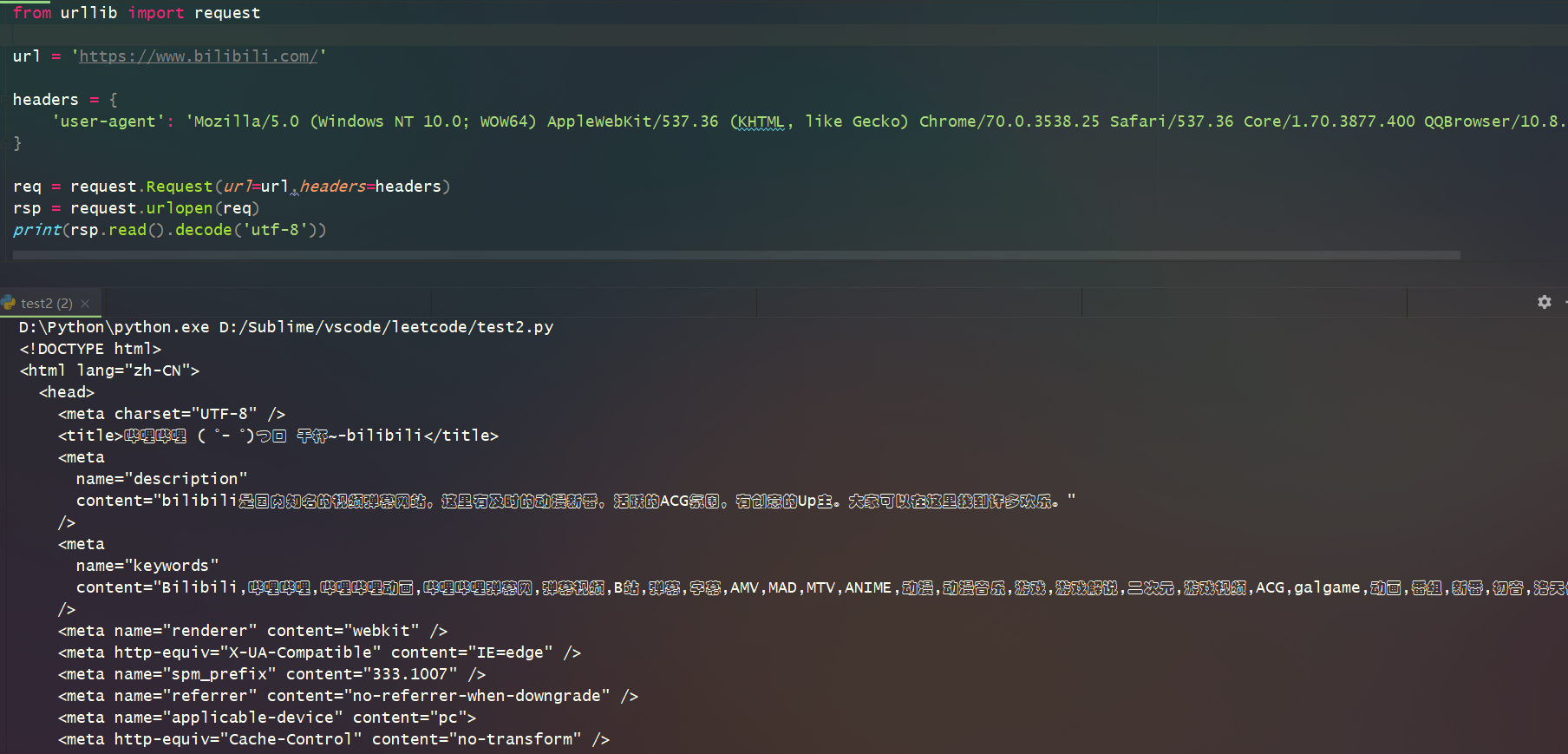
參考代碼如下:
from urllib import request
url = '//www.bilibili.com/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4507.400'
}
req = request.Request(url=url,headers=headers)
rsp = request.urlopen(req)
print(rsp.read().decode('utf-8'))
2.如用urllib模塊來訪問百度網站時會出現如下情況:
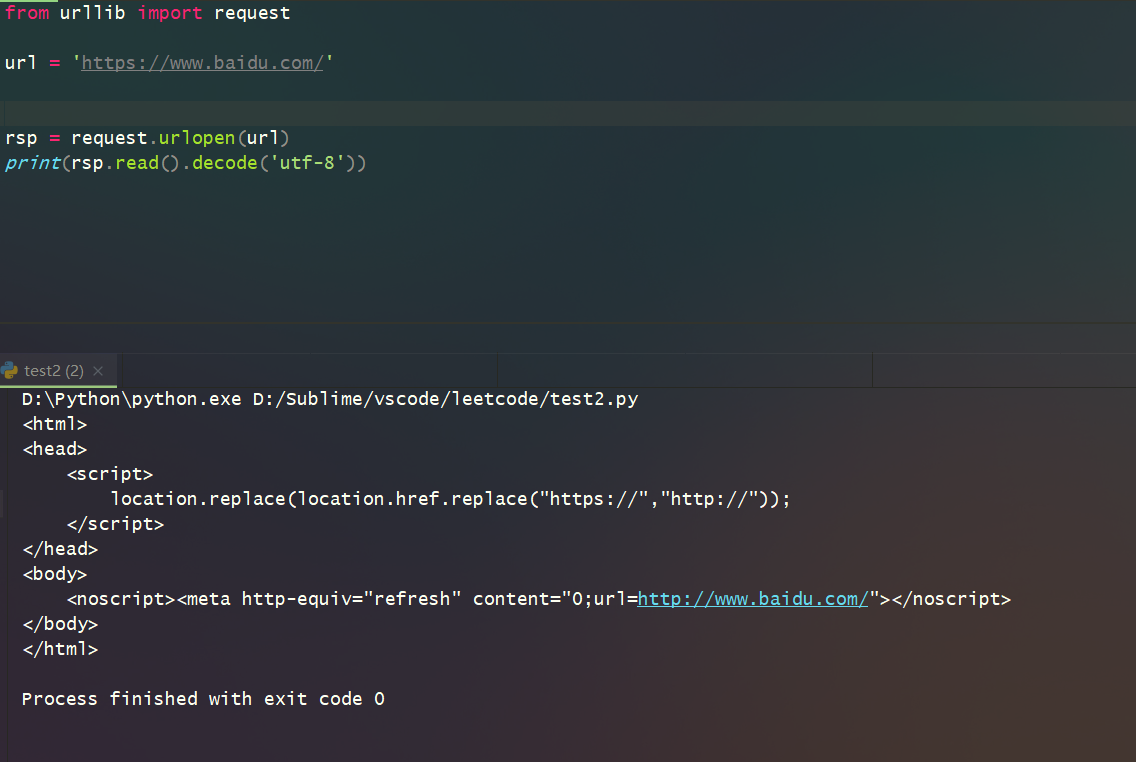
很顯然,這個網頁不可能就這麼點代碼標籤,添加一個請求頭之後,如下:

3. 動態網頁加載的數據
提到動態網頁,讀者首先可以去看看小編的這篇文章:Python爬蟲:什麼是靜態網頁(數據),什麼是動態網頁(數據)、Python爬蟲:爬取動態網頁數據「你」需要知道的事,小編學習過後端知識,大體知道為什麼用上述方式訪問不到相應的數據。why(大概是這樣吧!也有可能講的不對,希望讀者指正[如果有錯誤的話],一般而言,我們用爬蟲爬取得到的數據是當前網頁已經完全加載的,然而動態網頁使用了ajax技術,而執行者一段ajax代碼好像是網頁完全加載之後才執行的,因此你用爬蟲爬取不到那部分數據。)
此時,你有兩種解決方式:
- 找到這個ajax的相關網頁鏈接,訪問這個鏈接,從而得到相關數據;
- 直接使用selenium這個模塊,操作瀏覽器訪問。
如果讀者使用第1種解決方式,有可能你訪問的那個鏈接一些參數是加密的,這時你需要利用js斷點(使用谷歌瀏覽器),找到那段加密參數加密之前的數據信息和相關的一些js加密函數,找到加密之前的數據信息的組合規則。關於js加密函數,如果簡單的話,直接用Python模擬出加密效果即可;如果複雜的話,最好使用execjs或者其他Python模塊下的一些方法去執行這些js加密函數。
上述關於使用第1種解決方式,小編過去做過的有Python爬蟲爬取酷狗音樂、網易雲音樂、鬥魚視頻等。
- Python爬蟲:通過js逆向我發現了鬥魚視頻請求參數的加密原理
- Python爬蟲:通過做項目,小編了解了酷狗音樂的加密過程
- python爬蟲:了解JS加密爬取網易雲音樂
- Python反爬:利用js逆向和woff文件爬取貓眼電影評分信息
4. 總結
有的讀者也許會問,如果我ip封掉了,怎樣爬取網頁數據,其實,使用相關ip代理即可,IP代理文章鏈接為:Python爬蟲:製作一個屬於自己的IP代理模塊2、Python爬蟲:運用多線程、IP代理模塊爬取百度圖片上小姐姐的圖片。另外,還有一些高大上的反爬措施,小編並不是很了解,就不在這一一贅述了,如果未來小編真的了解到了,到時候再在本文章後加上吧!


