YOLOX-PAI:加速YOLOX,比YOLOV6更快更強
導言

目標檢測(object detection)旨在定位並識別出圖像中的目標物體,一直以來都是計算機視覺領域研究的熱點問題,也是自動駕駛、目標追蹤等任務的基礎。近年來,優秀的目標檢測算法不斷湧現,其中單階段的YOLO系列以其高效、簡潔的優勢,始終是目標檢測算法領域的一個重要分支。2021年,曠視提出YOLOX[1]算法,在速度和精度上構建了新的基線,組件靈活可部署,深受工業界的喜愛。本文基於阿里雲 PAI-EasyCV框架復現YOLOX算法,探究用以實際提升YOLOX精度的實用技巧,並進一步結合阿里巴巴計算平台PAI自研的PAI-Blade推理加速框架優化模型性能。經過我們對社區諸多YOLOX 改進技巧的復現和探索,進一步提升了YOLOX的性能,在速度和精度上都比現階段的40~50mAP 的SOTA的YOLOv6更勝一籌。同時,PAI-EasyCV提供高效簡潔的模型部署和端到端推理接口,供社區快速體驗使用YOLOX-PAI的功能。
總結一下我們的工作貢獻:
- 我們提供了一套Apache License 訓練/優化/推理的代碼庫以及鏡像,可以實現當前社區40+MAP 量級最快(相比 YOLOV6 +0.4mAP/加速13~20%)的目標檢測模型。
- 我們調研了YOLOX相關的改進技術和消融實驗,挑選了其中一些相對有幫助的改進,補齊了40/0.7ms(YOLOXS)~47.6/1.5ms(YOLOXM) 之間的模型,並以配置的方式提供出來。
- 我們對目標檢測的端到端推理進行靈活封裝及速度優化,在V100上的端到端推理為3.9ms,相對原版YOLOX的9.8ms,加速接近250%,供用戶快速完成目標檢測推理任務。
本文,我們將逐一介紹所探索的相關改進與消融實驗結果,如何基於PAI-EasyCV使用PAI-Blade優化模型推理過程,及如何使用PAI-EasyCV進行模型訓練、驗證、部署和端到端推理。歡迎大家關注和使用PAI-EasyCV和PAI-Blade,進行簡單高效的視覺算法開發及部署任務。
PAI-EasyCV項目地址://github.com/alibaba/EasyCV
PAI-BladeDISC項目地址://github.com/alibaba/BladeDISC
YOLOX-PAI-算法改進
YOLOX-PAI 是我們在阿里雲機器學習平台PAI 的開源計算機視覺代碼庫EasyCV(//github.com/alibaba/EasyCV)中集成的 YOLOX 算法。若讀者不了解YOLOX算法,可以自行學習(可參考:鏈接),本節主要介紹我們基於YOLOX算法的改進。
通過對YOLOX 算法的分析,結合檢測技術的調研,我們從以下4個方向對原版的YOLOX進行優化,
- Backbone : repvgg backbone
- Neck : gsconv / asff
- Head : toods / rtoods
- Loss : siou / giou
在算法改進的基礎上,利用PAI-Blade對優化後的模型進行推理優化,開發了如下的PAI-YOLOX模型。篩選有效改進與現有主流算法的對比結果如下:
( -ASFF 代表使用了 NeckASFF, -TOODN代表使用N個中間層的TOODHead取代原有的YOLOXHead)

從結果中可以看到,相比目前同水平(1ms以內)SOTA的YOLO6模型,融合上述改進的YOLOX-PAI在同等精度/速度的條件下有一定的速度/精度優勢。
有關測評需要注意以下幾點:
- YOLOV6 release測試速度不包含 decode和nms,所以我們為了公平對比,也進行了相關測速設置的關閉。(上表所示結果計算了Blade優化後的對應模型在bs32下平均一張圖像模型前向推理所用時間,關於端到端推理的時間(包含圖像前、後處理的總用時)見PAI-EasyCV Export一節)
- YOLOV6 release的精度是在訓練過程中測試的,會出現部分 shape=672的情況,然而測速是在導出到image_size=(640, 640) 的完成,實際上社區也有相關同學補充了YOLOV6在640下的測試精度,所以上表放了兩個測試精度。
- 使用EasyCV的Predictor 接口加載相關模型預測進行從圖片輸入到結果的預測,由於包含了預處理和NMS後處理,相對應的時間會變慢一些,詳細參考端到端優化結果。
下面我們將詳細介紹每一個模塊的改進和消融實驗。
Backbone
RepConv
近期YOLO6 [2],PP-YOLOE [3]等算法都改進了CSPNet[4]的骨幹網絡,基於RepVGG[5]的思想設計了可重參數化的骨幹網絡,讓模型在推理上具有更高效的性能。我們沿用了這一思想,利用YOLO6的EfficientRep代替YOLOX原來的CSPDarkNet-53骨幹網絡。得到的實驗結果與YOLO6相關模型對比如下(YOLOX-Rep表示使用了EfficientRep作為骨幹網絡的YOLOX模型):

RepVGG結構的網絡設計確實會增大參數量和計算量,但實際推理速度都更有優勢,所以我們選擇YOLO6 EfficientRep 作為可以配置的Backbone。
Neck
在更換了骨幹網絡的基礎上,我們對Neck部分分別進行了兩方面的探究。
-
ASSF[6]:基於對PAN輸出特徵維度變換後基於SE-Attention特徵融合的特徵增強,大幅提升參數量和精度,部分降低推理速度。
- ASSF-Sim : 我們選取了參數量更低的特徵融合實現,用較少的參數量(ASFF:5M -> ASFF-Sim:380K)來保留了84%的精度精度提升(+0.98map->+0.85map)。然而,這一改進會讓推理速度變慢,未來我們會針對這個OP實現對應的Plugin完成推理加速。
-
GSNeck[7] :基於DW Conv 對Neck信息融合,降低Neck參數量,輕微提升精度,也會會降低推理速度。
ASFF 信息融合
ASFF,通過進行不同PAN不同特徵圖之間的信息交互,利用attention機制完成Neck部分的信息融合和增強,具體思想如下圖。

ASFF-SIM輕量版
參考YOLO5[8]中的Fcous層的設計,PAI-EasyCV利用切片操作進行特徵通道的增加和特徵圖的縮小。同時,利用求平均操作進行通道的壓縮,基於這種實現的ASFF,我們簡單區分為ASFF-Sim。我們進行特徵圖統一的核心操作(通道擴展和通道壓縮)如下:
def expand_channel(self, x):
# [b,c,h,w]->[b,c*4,h/2,w/2]
patch_top_left = x[..., ::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_left = x[..., 1::2, ::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat(
(
patch_top_left,
patch_bot_left,
patch_top_right,
patch_bot_right,
),
dim=1,
)
return x
def mean_channel(self, x):
# [b,c,h,w]->[b,c/2,h,w]
x1 = x[:, ::2, :, :]
x2 = x[:, 1::2, :, :]
return (x1 + x2) / 2
針對不同的特徵圖,其融合機制如下:


GSConvNeck
採用DWConv降低參數量是一種常用技巧,在YOLOX中,GSconv設計了一種新型的輕量級的卷積用來減少模型的參數和計算量。為了解決Depth-wise Separable Convolution (DSC)在計算時通道信息分離的弊端,GSConv(如下圖所示)採用shuffle的方式將標準卷積(SC)和DSC得到的特徵圖進行融合,使得SC的輸出完全融合到DSC中。

此外,GSConv原文指出,如果在整個網絡都使用GSconv,則會大大加深網絡的深度,降低模型的推理速度,而僅在通道信息維度最大,空間信息維度最小的Neck處使用GSConv是一種更優的選擇。我們在YOLOX中利用GSConv優化模型,特別的我們採用了兩種方案分別進行實驗(a: 僅將Neck的部分用GSConv,b: Neck的所有模塊均使用GSConv):
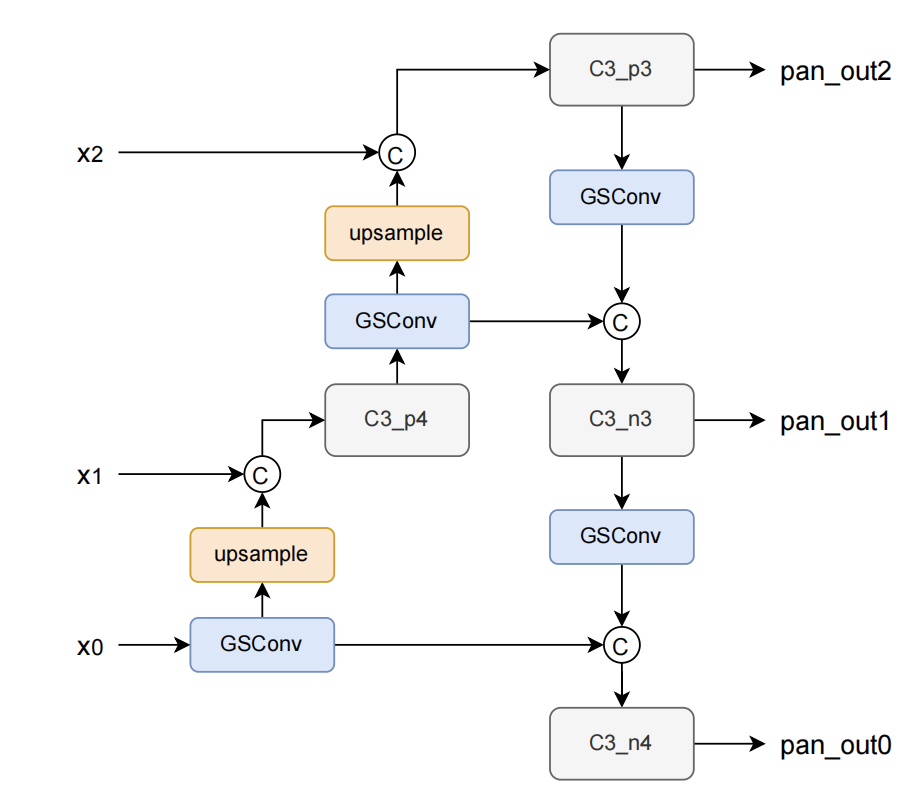
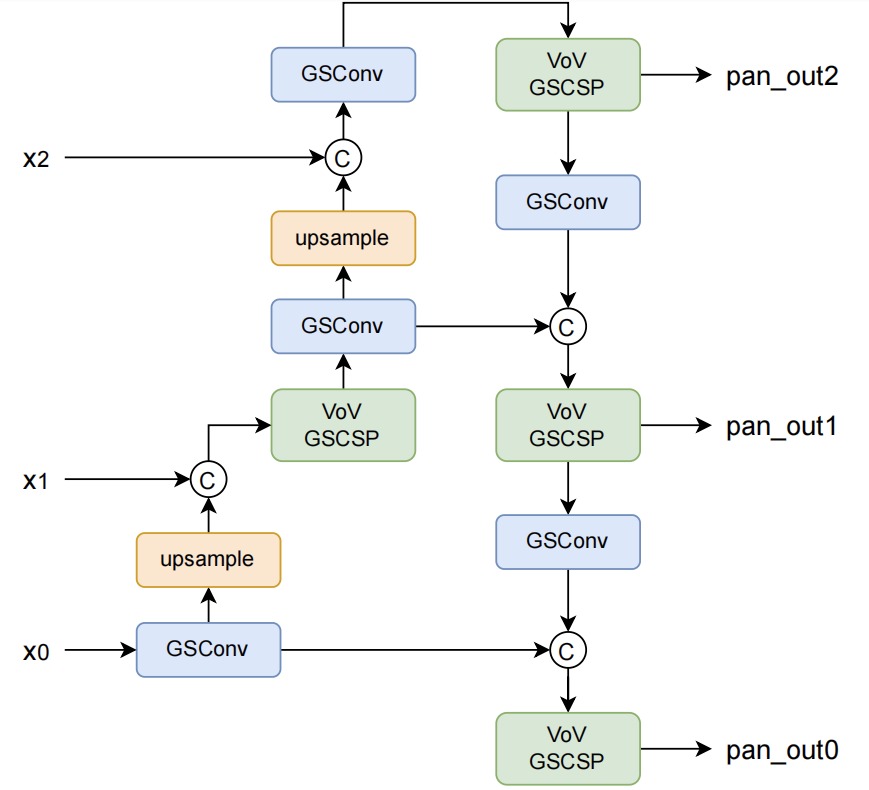
所得到的實驗結果如下(僅統計Neck部分的Params, Flops)。可以看到GSConv對參數量進行了優化,且提升了模型的性能,降低3%的推理速度可以換來0.3mAP的提升。

Head
TOOD
參考PPYOLOE,我們同樣考慮利用TOOD[9]算法中的Task-aligned predictor中的注意力機制(T-Head)分別對分類和回歸特徵進行增強。如下圖所示,特徵先通過解耦頭的stem層(1×1)進行通道壓縮,接着由通過堆疊卷積層得到中間的特徵層,再分別對分類和回歸分支利用注意力機制進行特徵的增強,來解耦兩個任務。
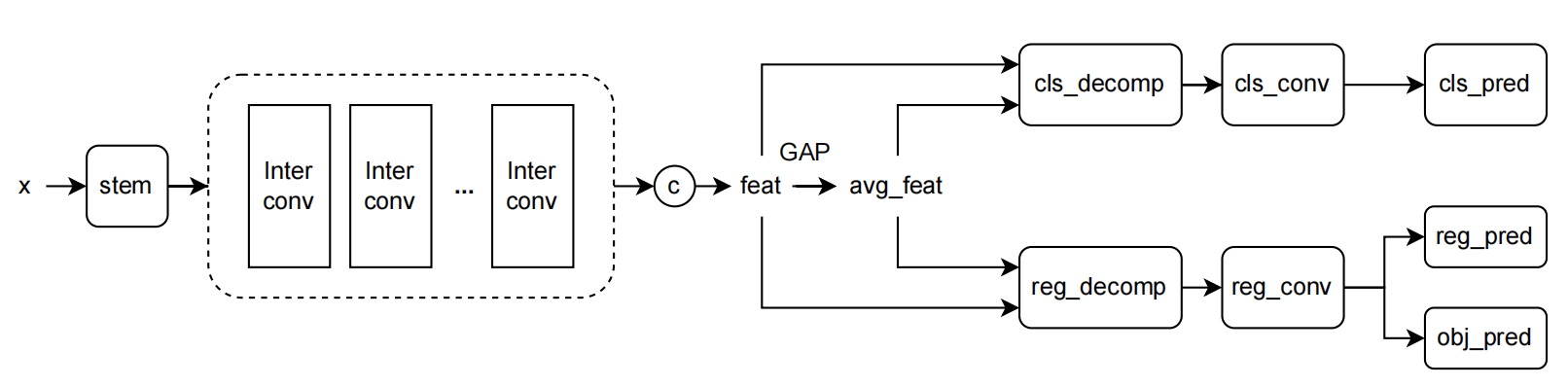
我們對堆疊的中間層個數進行消融實驗,每堆疊可以進一步提升一定的精度,並帶來速度上的一些損失。(下表的Params和Flops只統計了檢測頭部分。測速及精度基於的基線方法為以EfficientRep為backbone + ASFF進行特徵增強。)

此外,我們利用RepVGGBlock分別優化inter_conv,cls_conv/reg_conv層。實驗結果表明用RepVGGBlock實現inter_conv層會帶來性能上的下降,而RepVGGBlock實現的cls_conv/reg_conv層與原始卷積層在stack較大時效果相當,在stack比較小時,RepVGGBlock能起到優化作用。
Loss function
S/G/D/E/CIou
PAI-EasyCV實現了社區常用的集中IOU損失函數,用戶可以通過config自行選擇,特別的,對於最新提出的SIoU[10],在實驗過程中發現原公式中的反三角函數會使得模型訓練不穩定,且計算開銷相對較高,我們對原公式利用三角函數公式化簡可得(符號與論文原文一致,詳見原論文):

實驗結果顯示,在YOLOX上引入SIoU訓練模型的確能加快模型的收斂速度,但在最終精度上使用GIoU[11]性能達到最優。
綜合上述Backbone/Neck/Head/Loss 方向的改進,我們可以獲得如上的YOLOX-PAI模型。進一步,我們採用PAI-Blade 對已經訓練好的模型進行推理優化,實現高性能的端到端推理。
YOLOX-PAI-推理優化
 PAI-EasyCV Predictor
PAI-EasyCV Predictor
 PAI-EasyCV Predictor
PAI-EasyCV Predictor針對使用PAI-EasyCV訓練的YoloX-PAI 模型,用戶可以使用EasyCV自帶的導出(export)功能得到優化後的模型,並使用 EasyCV Predictor 進行端到端的推理。 該導出功能對檢測模型進行了如下優化:
- 使用PAI-Blade優化模型推理速度,簡化對模型的推理加速(TensorRT/編譯優化)開發流程。
- 支持EasyCV配置TorchScript/PAI-Blade對圖像前處理、模型推理、圖像後處理分別優化,供用戶靈活使用
- 支持Predictor 結構端到端的模型推理優化,簡化圖片預測過程。
也可以參考[EasyCV detector.py] 自行組織相應的圖像前處理/後處理過程,或直接使用我們導出好的模型和接口):我們這裡提供一個已經導出好的檢測模型,用戶下載三個模型文件到本地 [preprocess, model, meta]
export_blade/
├── epoch_300_pre_notrt.pt.blade
├── epoch_300_pre_notrt.pt.blade.config.json
└── epoch_300_pre_notrt.pt.preprocess
用戶可以直接使用PAI-EasyCV提供的Predictor接口,通過如下簡單的API調用,高效的進行圖像的檢測任務:
from easycv.predictors import TorchYoloXPredictor
from PIL import Image
img = Image.open(img_path = 'demo.jpg')
pred = TorchYoloXPredictor(export_model_name='epoch_300_pre_notrt.pt.blade',
use_trt_efficientnms=False)
res = pred.predict([img])
PAI-EasyCV Export
下面我們簡單介紹如何通過PAI-EasyCV的配置文件,導出不同的模型(具體的模型部署流程即相應的配置文件說明介紹見鏈接),並展示導出的不同模型進行端到端圖像推理的性能。
為導出不同的模型,用戶需要對配置文件進行修改,配置文件的說明如下:
export = dict(export_type='ori', # 導出的模型類型['ori','jit','blade']
preprocess_jit=False, # 是否用jit對前處理進行加速
static_opt=True, # 是否使用static shape優化,默認True
batch_size=1, # 靜態圖的輸入batch_size
blade_config=dict(
enable_fp16=True,
fp16_fallback_op_ratio=0.05 # 所有的layer都會針對轉fp16前後的輸出
# 的偏移進行排序,會對數值變化最大的層回退到fp32,該參數用於控制回退的比例,
# 如果出現模型輸出漂移太大,影響相關測試結果,可以手動調整該參數。
),
use_trt_efficientnms=False) # 是否使用trt優化的efficientnms
根據不同的模型配置,我們在單卡V100上測試YOLOX-s所有配置下模型的端到端推理性能 (1000次推理的平均值):

下圖,我們展示了由PAI-EasyCV中集成的使用PAI-Blade/JIT優化的模型端到端推理速度與YOLOX官方原版的 不同模型(s/m/l/x)的推理速度對比:
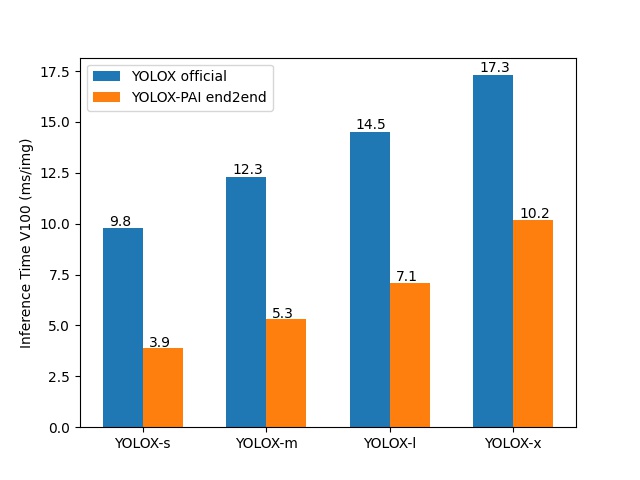
可以看到PAI-EasyCV導出的模型,極大程度的優化了原模型的端到端推理速度,未來我們將進一步優化blade接入trt_efficientnms的速度,提升端到端性能。
PAI-Blade 推理優化
PAI-Blade是由阿里雲機器學習平台PAI開發的模型優化工具,可以針對不同的設備不同模型進行推理加速優化。PAI-Blade遵循易用性,魯棒性和高性能為原則,將模型的部署優化進行高度封裝,設計了統一簡單的API,在完成Blade環境安裝後,用戶可以在不了解ONNX、TensorRT、編譯優化等技術細節的條件下,通過簡單的代碼調用方便的實現對模型的高性能部署。更多PAI-Blade相關技術介紹可以參考 [PAI-Blade介紹]。
PAI-EasyCV中對Blade進行了支持,用戶可以通過PAI-EasyCV的訓練config 中配置相關export 參數,從而對訓練得到的模型進行導出。
這裡我們提供一個 PAI-Blade + PAI-EasyCV 社區版 V100對應的鏡像(cuda11.1/TensorRT8/cudnn8):用戶也可以基於Blade每日發佈的鏡像自行搭建推理環境 [PAI-Blade社區鏡像發佈]
registry.cn-shanghai.aliyuncs.com/pai-ai-test/eas-service:blade_cu111_easycv
用戶執行如下導出命令即可
cd ${EASYCV_ROOT}
export LD_LIBRARY_PATH=/usr/loca/cuda/lib64/:${LD_LIBRARY_PATH}
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH='./'
python tools/export.py yolox_pai_trainconfig.py input.pth export.pth
值得注意的是上文所有的模型的推理速度都限定在 V100 BatchSize=32 靜態Shape (end2end=False)的PAI-Blade優化設置結果。Blade中已經集成了常見OP的優化,針對用戶自定義的op可以參考PAI-EasyCV中的easycv/toolkit/blade/trt_plugin_utils.py 自行實現。
YOLOX-PAI-訓練與復現
我們在PAI-EasyCV框架中復現了原版的YOLOX,及改進的YOLOX-PAI,並利用PAI-Blade對模型進行推理加速。為了更好的方便用戶快速體驗基於PAI-EasyCV和PAI-Blade的YOLOX,接下來,我們提供利用鏡像對YOLOX-PAI進行模型的訓練、測試、及部署工作。更多的關於如何在本地開發環境運行,可以參考該鏈接安裝環境。若使用PAI-DSW進行實驗則無需安裝相關依賴,在PAI-DSW docker中已內置相關環境。
拉取鏡像
sudo docker pull registry.cn-shanghai.aliyuncs.com/pai-ai-test/eas-service:blade_cu111_easycv
啟動容器
sudo nvidia-docker run -it -v path:path --name easycv_yolox_pai --shm-size=10g --network=host registry.cn-shanghai.aliyuncs.com/pai-ai-test/eas-service:blade_cu111_easycv
數據代碼準備
# 數據準備參考 //github.com/alibaba/EasyCV/blob/master/docs/source/prepare_data.md
git clone //github.com/alibaba/EasyCV.git
cd EasyCV
模型訓練
export PYTHONPATH=./ && python -m torch.distributed.launch --nproc_per_node=8 --master_port=29500 tools/train.py config.py --work_dir workdir --launcher pytorch
模型測試
python tools/eval.py config.py pretrain_model.pth --eval
模型導出
python tools/export.py config.py pretrain_model.pth export.pth
寫在最後
YOLOX-PAI 是PAI-EasyCV團隊基於曠視YOLOX 復現並優化的在V100BS32的1000fps量級下的SOTA檢測模型。整體工作上集成和對比了很多社區已有的工作:通過對YOLOX的替換基於RepVGG的高性能Backbone, 在Neck中添加基於特徵圖融合的ASFF/GSConv增強,在檢測頭中加入了任務相關的注意力機制TOOD結構。結合PAI-Blade編譯優化技術,在V100Batchsize32 1000FPS的速度下達到了SOTA的精度mAP=43.9,同等精度下比美團YOLOV6 加速13%,並提供了配套一系列算法/訓練/推理優化代碼和環境。
PAI-EasyCV(//github.com/alibaba/EasyCV)是阿里雲機器學習平台深耕一年多的計算機視覺算法框架,已在集團內外多個業務場景取得相關業務落地成果,主要聚焦在自監督學習/VisionTransformer等前沿視覺領域,並結合PAI-Blade等自研技術不斷優化。歡迎大家參與進來一同進步。
YOLOX-PAI未來規劃:
- 基於CustomOP(ASFFSim, EfficientNMS (fp16))實現的加速推理
[1] Ge Z, Liu S, Wang F, et al. Yolox: Exceeding yolo series in 2021[J]. arXiv preprint arXiv:2107.08430, 2021.
[2] YOLOv6, //github.com/meituan/YOLOv6.
[3] Xu S, Wang X, Lv W, et al. PP-YOLOE: An evolved version of YOLO[J]. arXiv preprint arXiv:2203.16250, 2022.
[4] Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020: 390-391.
[5] Ding X, Zhang X, Ma N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13733-13742.
[6] Liu S, Huang D, Wang Y. Learning spatial fusion for single-shot object detection[J]. arXiv preprint arXiv:1911.09516, 2019.
[7] Li H, Li J, Wei H, et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles[J]. arXiv preprint arXiv:2206.02424, 2022.
[8] YOLOv5, //github.com/ultralytics/yolov5.
[9] Feng C, Zhong Y, Gao Y, et al. Tood: Task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE Computer Society, 2021: 3490-3499.
[10] Gevorgyan Z. SIoU Loss: More Powerful Learning for Bounding Box Regression[J]. arXiv preprint arXiv:2205.12740, 2022.
[11] Rezatofighi H, Tsoi N, Gwak J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 658-666.