EDG奪冠!用Python分析22.3萬條數據:粉絲都瘋了!
一、EDG奪冠信息
11月6日,在英雄聯盟總決賽中,EDG戰隊以3:2戰勝韓國隊,獲得2021年英雄聯盟全球總決賽冠軍,這個比賽在全網各大平台也是備受矚目:
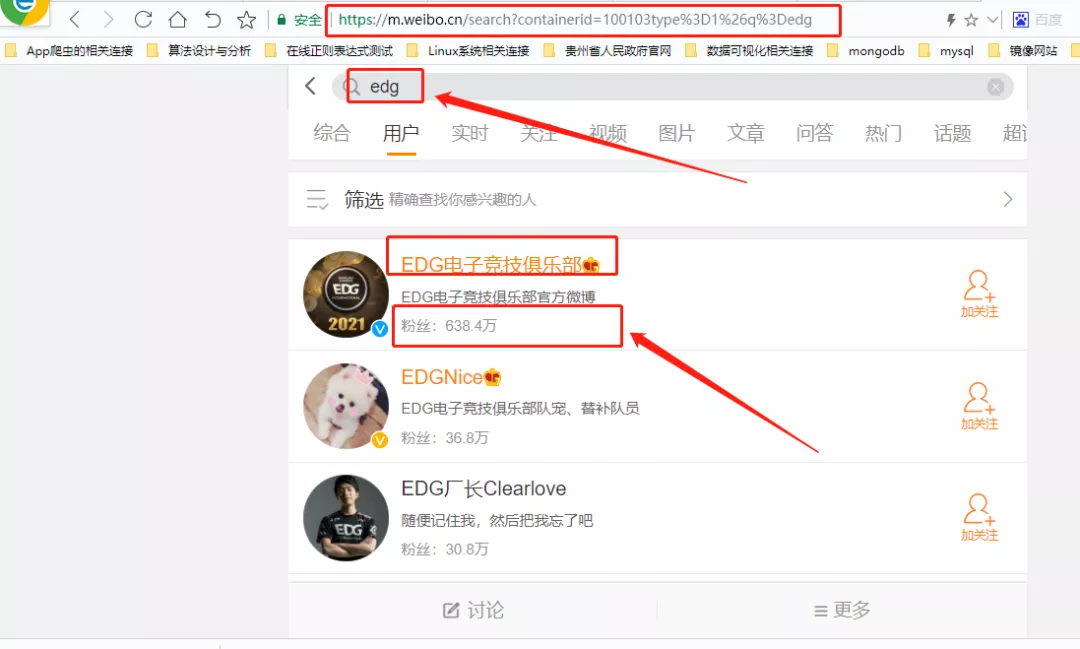
1、微博熱搜第一名,截止2021-11-10已有億級觀看量,微博粉絲數到達638.4萬
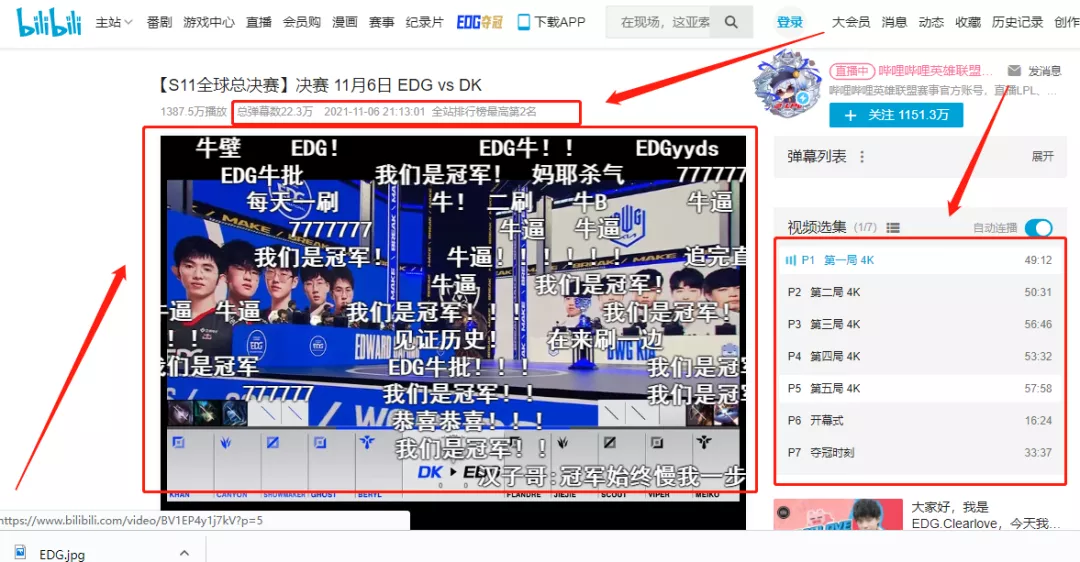
2、嗶哩嗶哩已有幾億人氣,總彈幕有22.3萬,全站排行榜最高第2名,B站粉絲已有219.9萬

3、騰訊、愛奇藝、優酷等視頻平台800萬人看過
4、虎牙等直播平台熱度也是居高不下
5、央視新聞也發微博慶祝EDG奪冠


既然比賽熱度這麼高,那麼本次我們就以bilibili為基準,通過採集EDG奪冠比賽視頻在嗶哩嗶哩的22.3萬條彈幕數據,再通過Python來分析進而感受粉絲的熱情
二、實戰目標
1、利用爬蟲技術抓取EDG戰隊在B站奪冠比賽視頻的22.3萬條彈幕數據
2、通過jieba、numpy等Python庫對抓取來的彈幕數據進行分析並且可視化


三、bilibili接口分析
首先進入EDG奪冠比賽視頻URL:
//www.bilibili.com/video/BV1EP4y1j7kV?p=1
嗶哩嗶哩已為大家整理好了EDG比賽視頻,從開幕式到奪冠時刻,共有7個視頻

嗶哩嗶哩彈幕數據接口:
//api.bilibili.com/x/v1/dm/list.so?oid=XXX
這個接口就是B站彈幕數據專用接口,我們可以直接拿來用,這個接口中的oid可以理解為每個視頻中的唯一標識符,它由數字組成,每一個視頻都有唯一的一個oid,那麼我們只要找到oid就可以請求相應比賽視頻彈幕的API接口,從而抓取彈幕數據
獲取oid
打開開發者工具,切換到Network選項,然後找到以pagelist為開頭的請求接口

接着找到Request URL這個請求接口,打開新窗口直接用這個API接口請求,如下圖:

當我們直接請求這個API接口時可以看到JSON格式的數據,而在裏面的cid就是我們需要的oid,如下所示:
1 {"code":0,"message":"0","ttl":1,"data":[{"cid":437586584,"page":1,"from":"vupload","part":"第一局 4K","duration":2952,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437626309,"page":2,"from":"vupload","part":"第二局 4K","duration":3031,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437659159,"page":3,"from":"vupload","part":"第三局 4K","duration":3406,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437727348,"page":4,"from":"vupload","part":"第四局 4K","duration":3212,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437729555,"page":5,"from":"vupload","part":"第五局 4K","duration":3478,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437550300,"page":6,"from":"vupload","part":"開幕式","duration":984,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}},{"cid":437717574,"page":7,"from":"vupload","part":"奪冠時刻","duration":2017,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}}]
當然我們也可以點擊Preview選項,點擊data,打開數據,而裏面的JSON數據是摺疊的,包括cid在內,如下圖所示:
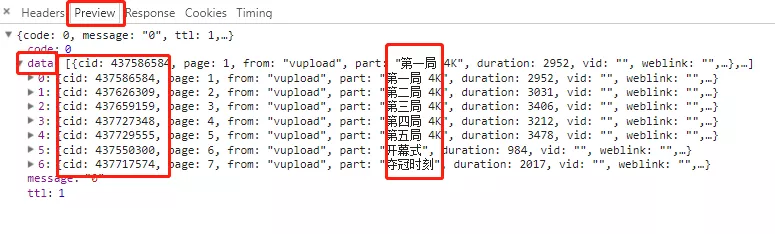
可以看到,每個cid對應每一個比賽視頻。我們也可以點擊Response選項,裏面的數據是真實的數據,意味着數據沒有經過摺疊,與直接請求Request URL返回的JSON數據是一樣的
四、編碼
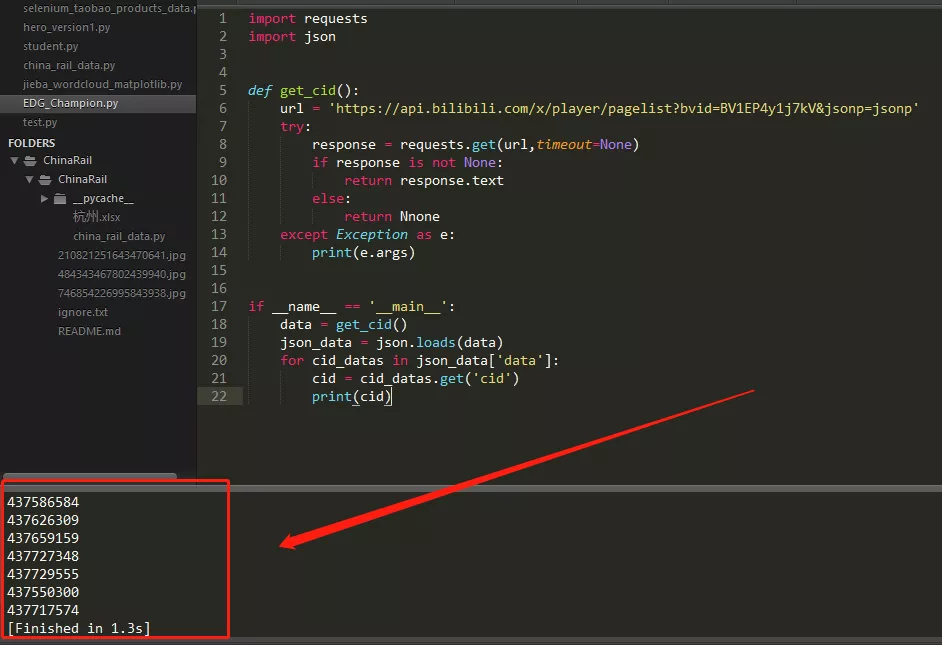
定義一個獲取cid的方法
1 import requests 2 import json 3 4 5 def get_cid(): 6 url = '//api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp' 7 try: 8 response = requests.get(url,timeout=None) 9 if response is not None: 10 return response.text 11 else: 12 return Nnone 13 except Exception as e: 14 print(e.args) 15 16 17 if __name__ == '__main__': 18 data = get_cid() 19 json_data = json.loads(data) 20 for cid_datas in json_data['data']: 21 cid = cid_datas.get('cid') 22 print(cid)
控制台輸出如下:
拼接URL彈幕數據API接口
1 if __name__ == '__main__': 2 data = get_cid() 3 json_data = json.loads(data) 4 base_api = '//api.bilibili.com/x/v1/dm/list.so?oid=' 5 for cid_datas in json_data['data']: 6 cid = cid_datas.get('cid') 7 detail_api = base_api + str(cid) 8 print(detail_api)
控制台輸出如下:
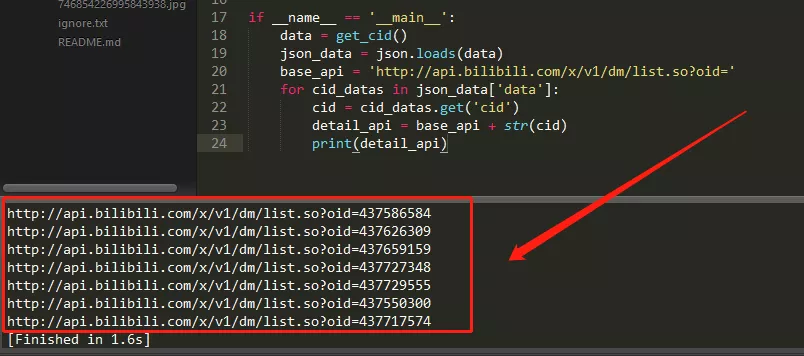
一共有7個網址,對應7個EDG比賽視頻的彈幕數據,我們點開第一個網址查看

抓取彈幕數據
從上一張圖可以看到,每一條彈幕數據都在每一個<d>標籤中,面對這種格式我們思考一下用哪種解析工具比較合適?答案當然是正則表達式,接下來我們要獲取7個比賽視頻的22.3萬條數據,代碼如下:
1 base_api = '//api.bilibili.com/x/v1/dm/list.so?oid=' 2 all_api = [] 3 for cid_datas in json_data['data']: 4 cid = cid_datas.get('cid') 5 detail_api = base_api + str(cid) 6 all_api.append(detail_api) 7 for api in all_api: 8 edg_datas = get_api_data(detail_api) 9 edg_datas = re.findall('<d.*?>(.*?)</d>',edg_datas,re.S) 10 with open('EDG.txt','a',encoding='utf-8') as f: 11 for edg_data in edg_datas: 12 print(edg_data) 13 f.write(edg_data + '\n')
避免亂碼,加上如下代碼:
1 response.encoding = chardet.detect(response.content)['encoding']
控制台輸出如下:
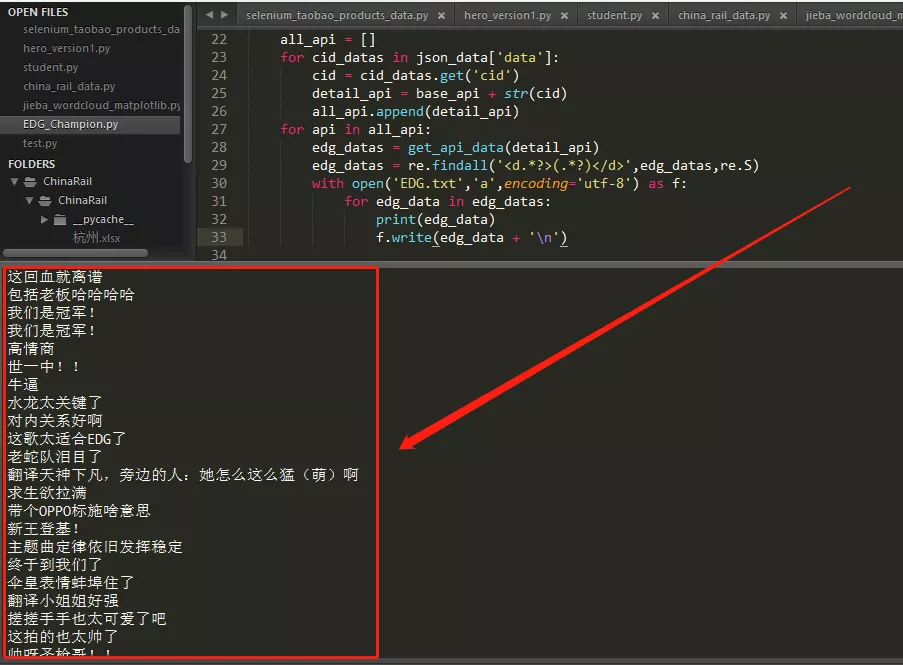
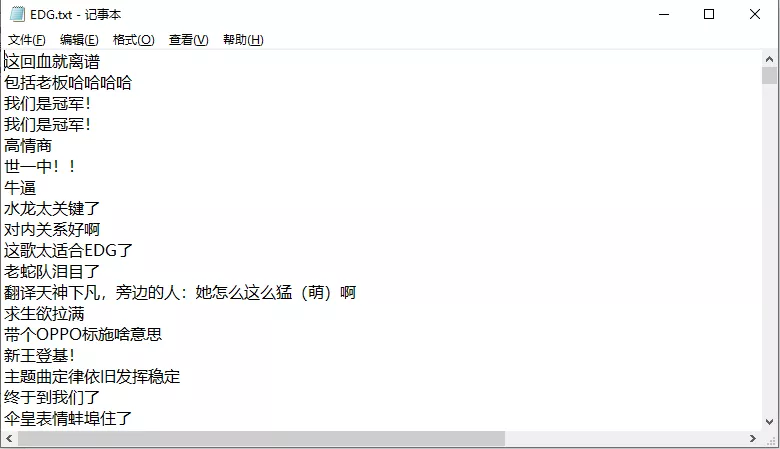
由於彈幕數據共有22.3萬條,這裡僅展示EDG.txt部分彈幕數據,如下圖所示:
詞雲圖製作
我們已經抓取到彈幕數據,接下來利用EDG背景圖做一個詞雲圖

代碼如下:
1 import jieba 2 from wordcloud import WordCloud 3 import matplotlib.pyplot as plt 4 from PIL import Image 5 import numpy as np 6 7 def do_wordcloud(): 8 text = open('EDG.txt','r',encoding='utf-8').read() 9 text = text.replace('\n','').replace('\u3000','') 10 text_cut = jieba.lcut(text) 11 text_cut = ' '.join(text_cut) 12 13 #過濾一些沒有關係的詞 14 stop_words = ['「',',',' ','我','的','是','了',':','?','!','啊','你','嗎','。','我們'] 15 16 background = Image.open("EDG.jpg") 17 graph = np.array(background) 18 19 word_cloud = WordCloud(font_path='simsun.ttc', 20 background_color='white', 21 mask=graph, # 指定詞雲的形狀 22 stopwords=stop_words) 23 24 word_cloud.generate(text_cut) 25 plt.subplots(figsize=(12,8)) 26 plt.imshow(word_cloud) 27 plt.axis('off') 28 plt.show() 29 word_cloud.to_file('edg.png')
控制台輸出如下:
把迪迦奧特曼背景圖片也製作一波吧,哈哈哈!

製作成迪迦奧特曼詞雲圖形狀,如下所示:
當然你也可以使用pyecharts/echarts製作也行,還可以製作成你喜歡的圖片形狀。如果你接觸過情感分析的話,也可以用這些彈幕數據分析一波
五、總結
PIL庫
jieba庫
numpy庫
requests庫
wordcloud庫
matplotlib庫
json,re,chardet庫
六、完整項目及源碼下載
完整項目(包括源碼)獲取方式:文末下載
原創不易,如果覺得有趣好玩,希望可以隨手點個贊,拜謝各位老鐵!
更多獨家精彩內容 請掃碼關注個人公眾號,我們一起成長,一起Coding,讓編程更有趣!
—— —— —— —— — END —— —— —— —— ————
歡迎掃碼關注我的公眾號
小鴻星空科技


