深度學習—1cycle策略:實踐中的學習率設定應該是先增再降
深度學習—1cycle策略:實踐中的學習率設定應該是先增再降
本文轉載自機器之心Pro,以作為該段時間的學習記錄
深度模型中的學習率及其相關參數是最重要也是最難控制的超參數,本文將介紹 Leslie Smith 在設置超參數(學習率、動量和權重衰減率)問題上第一階段的研究成果。具體而言,Leslie Smith 提出的 1cycle 策略可以令複雜模型的訓練迅速完成。它表示在 cifar10 上訓練 resnet-56 時,通過使用 1cycle,能夠在更少的迭代次數下,得到和原論文相比相同、甚至更高的精度。
通過採用大學習率,我們可以在 70 個 epoch、不到 7000 次的迭代中,訓練出準確率達到 93% 的模型(作為對比,原論文的訓練共有約為 360 個 epoch、64000 次迭代)。
Jupyter Notebook記錄了所有的相關實驗。實驗中使用了和原論文相同的數據擴張:我們對圖片進行了隨機水平翻轉;除此之外,我們在圖片每邊加入了4像素的填充,並進行隨機裁剪。這裡我們做出了一點小調整:我們沒有使用黑色的填充像素,而是使用了反射填充(reflection padding),因為fastai支持實現這種方式。 這個調整也許能解釋為什麼我們在使用和 Leslie 相同的超參數進行實驗時,得到了比他稍好的結果。
大學習率
可以通過這篇文章學習如何實現Learning Rate Finder,這裡簡述如下:在開始訓練模型的同時,從低到高地設置 學習率,直到損失(loss)變得失控為止。然後將損失和學習率畫在一張圖中,在損失持續下降、即將達到最小值前的範圍上取一個值作為學習率。下例中,可以在 10^-2 到 3×10^-2 之間任意取一個值。
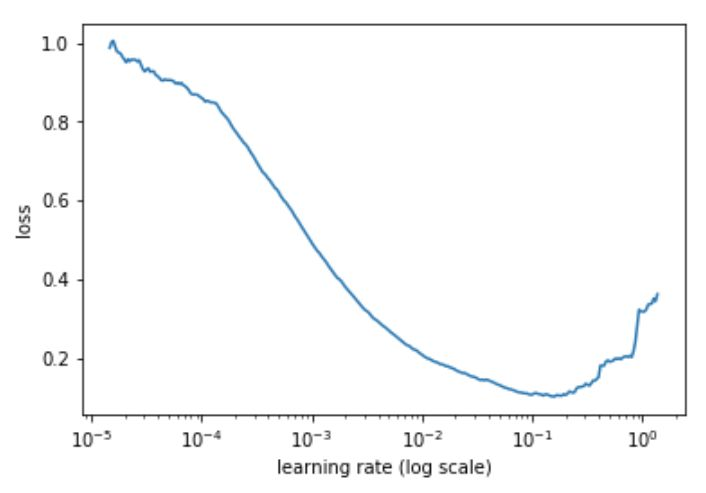
這裡的思想和 Leslie 是一致的,他在論文中提出了一個很好的訓練方法。
Leslie 建議,用兩個等長的步驟組成一個 cycle:從很小的學習率開始,慢慢增大學習率,然後再慢慢降低回最小值。最大學習率應該根據 Learning Rate Finder 來確定,最小值則可以取最大值的十分之一。這個 cycle 的長度應該比總的 epoch 次數略小,在訓練的最後階段,可以將學習率降低到最小值以下幾個數量級。
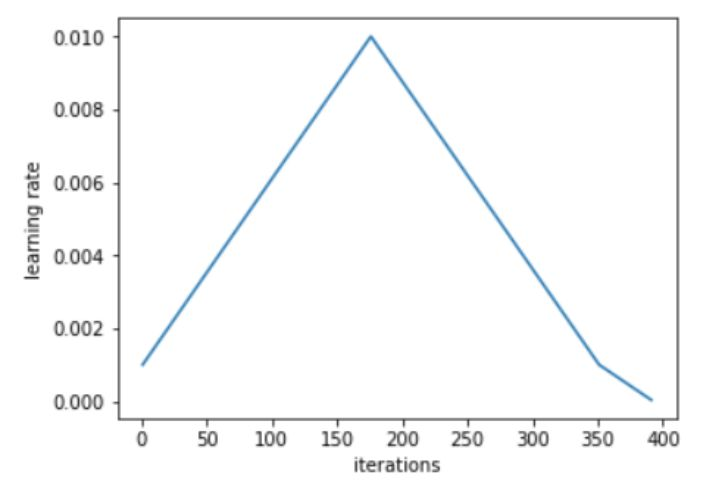
從小學習率開始訓練模型並不新穎:使用較小的學習率來預熱訓練是一種常用的方法,這也正是 Leslie 第一階段的研究目標。Leslie 並不建議直接從大學習率開始,相反,他認為應該從低到高,緩慢地線性提升學習率,然後再用相同的時間緩慢地降低回來。
Leslie 在實驗中發現,在這個 cycle 的中間階段,大學習率的效果類似於正則方法,可以抑制神經網絡的過擬合。這是因為大學習率更偏好損失函數上相對平緩的極小值,而防止模型收斂到一個陡峭區域上。在 Leslie 的另一篇論文中,他通過使用 1cycle,發現近似 Hessian 的方法會有更小的學習率,這意味着 SGD 搜索的是一個更平坦的區域。
在訓練的最後階段,通過降低學習率直到徹底消失,可以得到損失函數平滑區域中相對陡峭的局部極小值。
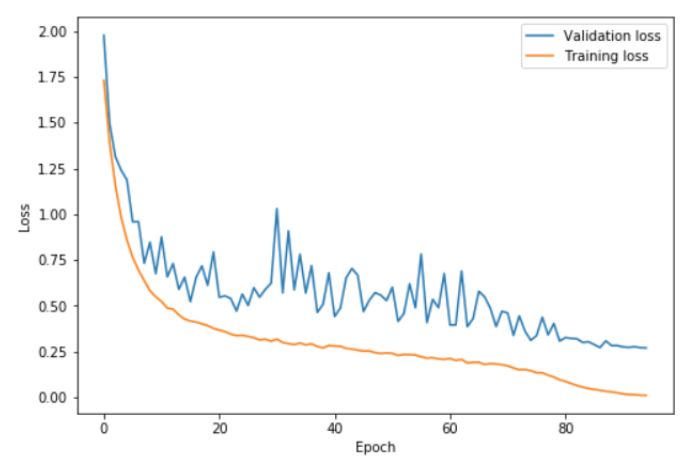
上圖中,在 0 ~ 41 個 epoch 中,學習率從 0.08 提升到 0.8,在隨後的 41 ~ 82 個 epoch 中,學習率降回 0.08,在最後的幾次 epoch 中,學習率降低到 0.08 的百分之一。可以看到,在高學習率階段(基本是 20 ~ 60 個 epoch),驗證損失表現得相對不穩定。但重要的是,平均而言,訓練誤差和驗證誤差之間的距離並沒有增大。只有在 cycle 的最後階段,學習率接近為 0 時,才真正的出現了過擬合。
令人驚訝的是,通過 1cycle,我們甚至可以使用更高的最大學習率,即在根據 Learning Rate Finder 得到的圖中,更接近曲線最低點。這種訓練會相對更加危險,因為損失可能會騙你太遠,以至於出現嚴重的偏差;這時,在採用更低的學習率前,可以嘗試使用更長的 cycle:更長的預熱過程應該會有所幫助。
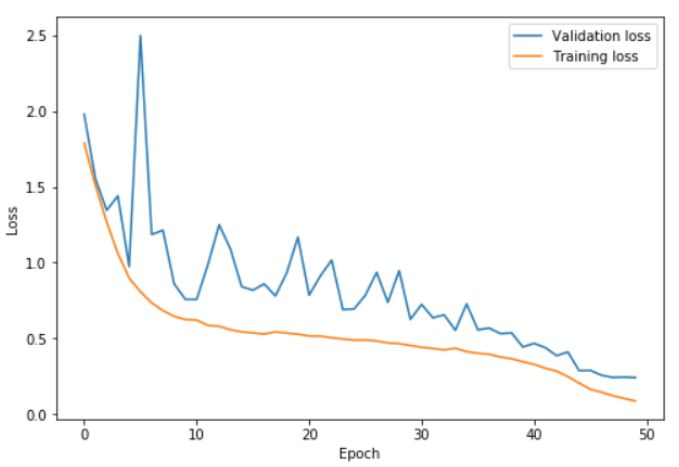
上圖中,在 0 ~ 22.5 個 epoch 中,學習率從 0.15 增加到 3;在 22.5~45 個 epoch 中降回到 0.15,在最後的幾次 epoch 中,學習率降低到 0.15 的百分之一。通過使用這些非常高的學習率,學習完成得更快,同時也防止了過擬合。訓練誤差和驗證誤差之間的差距一直保持在很低的水平,直到學習率接近為 0。通過使用 1cycle 策略,可以僅僅經過 50 次 epoch,就在 cifar10 上訓練出一個準確率 92.3% 的 resnet-56;我們可以利用包含 70 個 epoch 的 cycle 得到 93% 的準確率。
作為對比,下圖展示了使用更小的 cycle 以及更長收斂階段的結果:
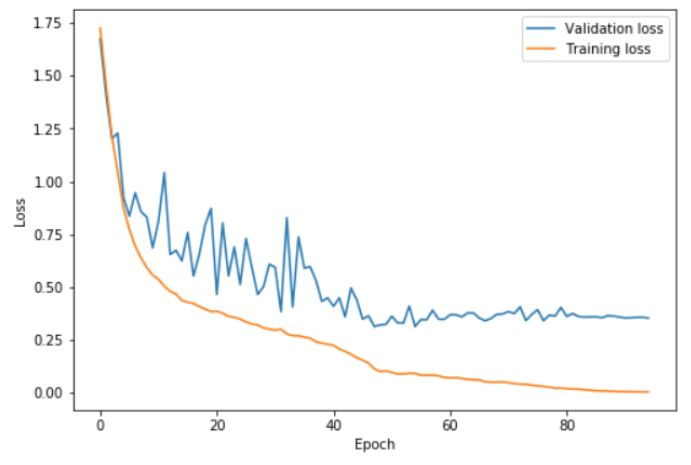
在這裡,學習率變化的兩個步驟在 42 個 epoch 中結束,剩下的訓練過程中使用緩慢遞減的學習率。這時驗證誤差不再下降,進而出現了越來越嚴重的過擬合現象,同時,準確率基本沒有提升。
周期性動量
Leslie 在實驗中還發現,在增大學習率的同時降低動量,可以得到更好的訓練結果。這也印證了一個直覺:在訓練中,我們希望 SGD 可以迅速調整到搜索平坦區域的方向上,因此就應該對新的梯度賦予更大的權重。Leslie 建議,在真實場景中,可以選取如 0.85 和 0.95 的兩個值,在增大學習率的時候,將動量從 0.95 降到 0.85,在降低學習率的時候,再將動量重新從 0.85 提升回 0.95。
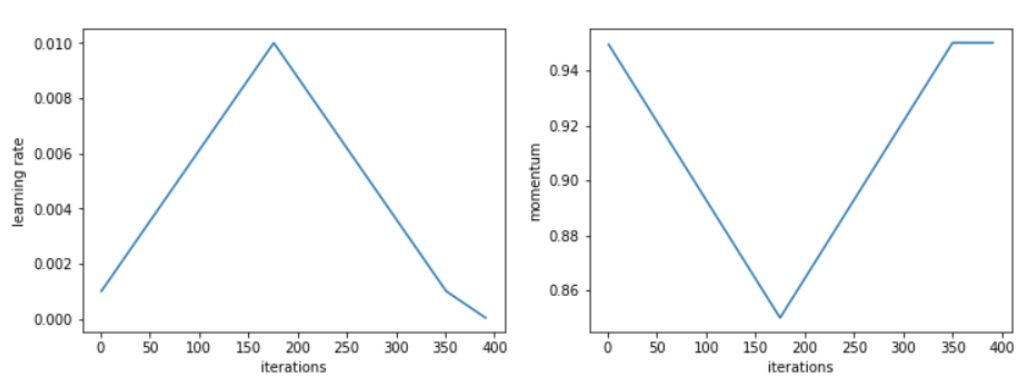
據 Leslie 表示,使用根據完整訓練選取的最優動量,也可以得到相同的最終結果;但使用周期性動量時,我們不需要浪費時間去設立多個動量參數,然後進行多次完整訓練來尋找最優值。
雖然使用周期性動量確實能得到稍好的訓練結果,但我並沒有復現出 Leslie 論文中使用常動量值和使用周期性動量時的差異。
其他參數的影響
在訓練中,調節模型其他超參數的方式也會影響最優學習率。因此在使用 Learning Rate Finder 時,一定要保證訓練是在相同條件下完成的。例:不同的 batch 大小或權重衰減對結果的影響如下。

可以利用這個性質來設置一些超參數,如去做那種衰減率:Leslie 建議,可以在幾組權重衰減率上運行 Learning Rate Finder,在能夠接受使用高最大學習率進行訓練的結果中,選擇最大的一個。我們實驗中選擇的是 10^-4。
Leslie 認為,在內存可接受範圍內,batch 越大越好。而其他可能包含的超參數(如 drop-out)則可以通過和權重衰減相同的方法來調節,或者直接根據一次 cycle 的結果來判斷效果。但無論如何——尤其是當你決定採用一個接近最大可能值的激進學習率時——一定要記住重跑 Learning Rate Finder。
高學習率的 1cycle 策略本身就是一種正則方法,所以在使用 1cycle 時,自然需要減少一些其他形式的常用正則項。但同它們相比,1cycle 的效率相對更高,因為在相當長的訓練中,我們都使用了高學習率。
摘要:儘管近年以來,深度學習已經在圖像、語音、視頻處理的應用場景中取得了令人矚目的成功,但絕大部分訓練所使用的超參數都是非最優的,因此不必要的延長了訓練時間。時至今日,超參數設置依然像一種魔法,需要依賴多年經驗來完成。本文提出了一些設置超參數的高效方法,可以顯著減少所需的訓練時間,並提升模型的表現效果。具體而言,本文展示了如何檢測出訓練在驗證/測試損失函數上輕微的欠擬合或過擬合,並給出了逼近最優平衡點的指導建議。在接下來的部分,本文討論了如何通過增加/減少學習率/動量來加速訓練過程。試驗結果表明,在每個數據集和架構上平衡正則的各個方面極其重要。我們以權重衰減作為正則項為例,展示了其最優值和學習率及動量間的緊密聯繫。

