所見即搜,3分鐘教你搭建一個服裝搜索系統!
摘要:用MindSpore+Jina,基於Fashion-MNIST Dataset搭建的服裝搜索系統。
引言
各位算法萌新們,是不是經常訓練了模型卻不知道如何部署和應用?或者只會調參但不會前端後端所以沒法向老闆們解釋這個模型可以做啥?如果有一種非常簡單的方式,讓你在3分鐘內就能建立一個以深度學習為支撐的搜索系統,並能在前端展示出來show給各位老闆們看?想不想嘗試呢?本文來自MindSpore社區技術治理委員會(TSC)的成員肖涵博士——Jina的創始人,用MindSpore+Jina,基於Fashion-MNIST Dataset搭建的服裝搜索系統。
[本文目錄]
- 如何用Jina①步搞定?
- Jina的hello-world是如何運行的?
- 如何使用MindSpore+Jina來搭建搜索系統?
- 創建一個MindSpore Executor
- 修改MindSpore的Encoder和網絡代碼
- 寫一個單元測試
- 準備Dockerfile
- 最後一步:終於可以Build了!
- 來看MindSpore的成品吧!
- 總結
喜歡逛淘寶或者各大海淘網站的各位程序員(的女朋友們),你們在瀏覽服裝的時候,是不是會經常看見模特們身上的衣服,全!都!想!要!但是,不知道從哪兒買,貨號是什麼?就算從各大穿搭博主那兒知道貨號了,也懶得一一去搜索。現在,完全不需要這麼麻煩,只要你花3分鐘建立這個服裝搜索系統,當你的女朋友再看到模特身上的衣服,就可以搜索出最相似的衣服,是不是很贊!
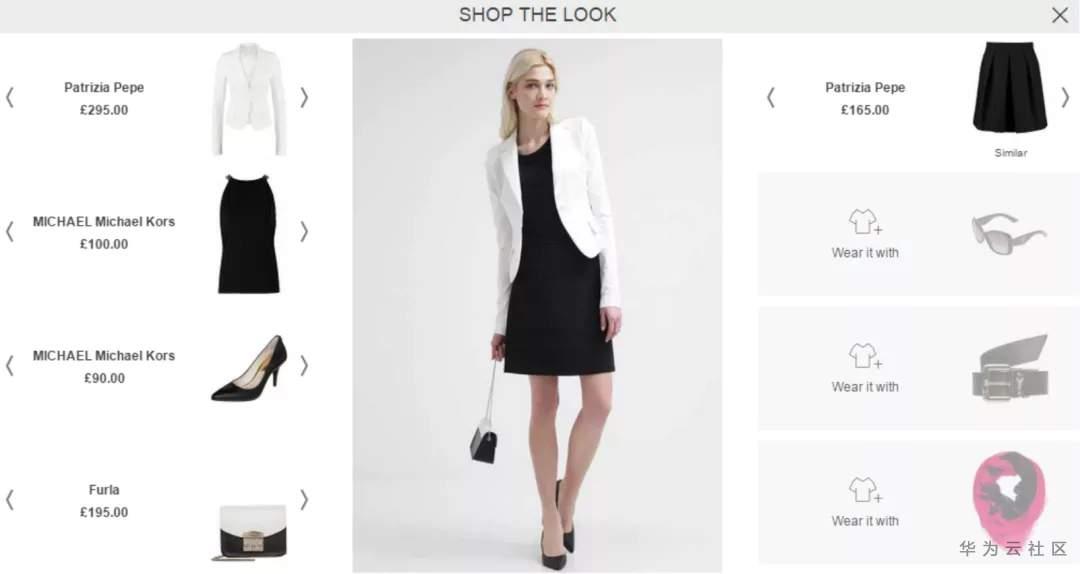
圖1 Shop the look
在做之前,先了解一下我們今天需要使用的兩個框架:MindSpore和Jina
- MindSpore是2020年3月28日華為開源的深度學習框架,它能原生支持自家的昇騰芯片,極大的提升了運行性能!
- Jina是一個由最先進的AI和深度學習驅動的雲端神經搜索框架,可以在多個平台和架構上實現任何類型的大規模索引和查詢。無論你搜索圖片、視頻片段還是音頻片段,Jina都能處理。

這裡使用的數據集是Fashion-MNIST dataset。它包含70,000張圖片,其中60,000張為訓練集,10,000張為測試集。每張圖片都是28×28的灰度圖像,一共10個類別。下面我們正式開始吧!
如何用Jina①步搞定?
首先你需要一台電腦,確認一下環境是否ok:
- Mac OS or Linux
- Python 3.7, 3.8
- Docker
然後執行以下一行命令即可:
pip install jina && jina hello-world
或者直接用docker:
docker run -v "$(pwd)/j:/j" jinaai/jina hello-world --workdir /j && open j/hello-world.html # replace "open" with "xdg-open" on Linux
現在開始運行程序,就可以看到運行結果了:

圖3 Jina hello-world運行結果
是不是很神奇?那麼Jina是如何實現的呢?可以先花1分鐘時間了解Jina的十個基本組件,在本文中最重要的三個信息分別是:
- YAML config:讓用戶可以自定義的描述對象的屬性。
- Executor:代表了Jina中的算法單元。譬如把圖像編碼成向量、對結果進行排序等算法等都可以用Executor來表述。我們可以用Crafter來把製作/分割和轉化要搜索的內容,然後用 Encoder來將製作好的搜索對象表示為向量,再用Indexer 保存和檢索搜索的向量和鍵值信息,最後用Ranker來對搜索出的結果排序。
- Flow:表示一個高階的任務, 譬如我們所說的索引(index)、搜索(search)、訓練(train),都屬於一個flow。
Jina的hello-world是如何運行的?
想知道hello-world運行的細節嘛?其實在很簡單,在hello-world里,我們使用YAML文件來描述index和search的flow,可以導入YAML文件,並通過.plot() 命令來可視化:
from pkg_resources import resource_filename from jina.flow import Flow f = Flow.load_config(resource_filename('jina', '/'.join(('resources', 'helloworld.flow.index.yml')))).plot()
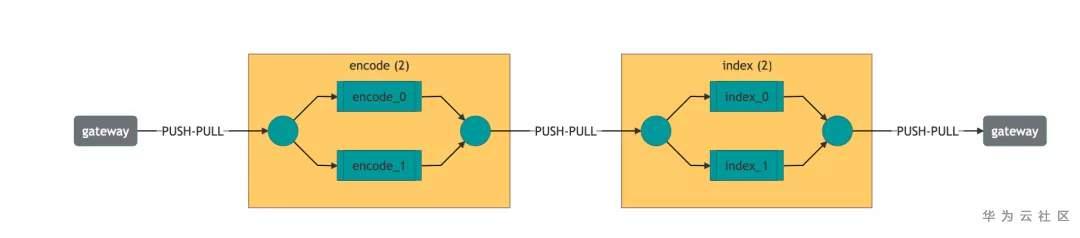
圖4 hello-world YAML文件流程圖
YAML文件里的信息是如何表示成圖的呢?下面可以看看直觀的對比:
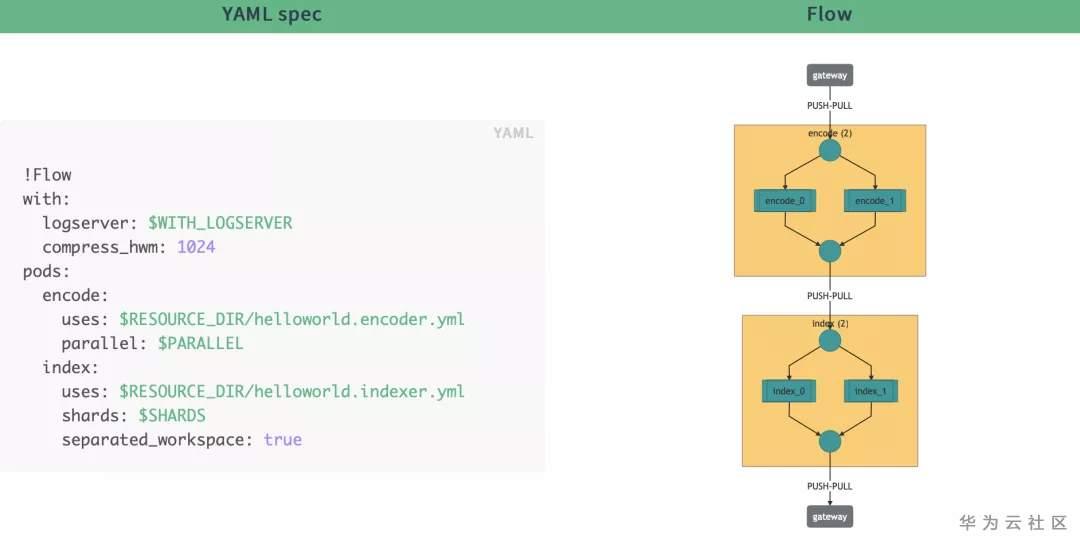
圖5 YAML文件信息
其實,這個flow中包含了兩步(在Jina中也可以叫兩個Pod):第一步它將數據通過並行的方式餵給encoder,輸出向量和meta信息分片存儲在索引器中。查詢flow也是以同樣的方式運行,只不過在參數上有些小變化。
既然原理這麼簡單,如果我們自己訓練的模型,是不是也可以替換呢?下面我們來手把手教大家如何只用4步,就可以用MindSpore+Jina來搭建服裝搜索系統。
如何使用MindSpore+Jina來搭建搜索系統?
創建一個MindSpore Executor
MindSpore的ModelZoo里有很多深度學習模型,本文使用的是最經典的CV網絡:LeNet。我們可以通過jina hub來創建一個新的MindSpore Executor,本文使用的Jina Hub版本是v0.7的,可以輸入以下命令安裝:
pip install "jina[hub]"
安裝好後,如果你想創建一個新的executor,可以直接輸入:
jina hub new
執行這個命令後會彈出一下指導命令,按照下面的要求輸入即可,有些設置直接用默認的就行,直接按Enter鍵就可以啦。
比較重要的是這幾個命令:

所有命令輸入完成後,你會看到MindSporeLeNet這個文件夾已經創建成功了。然後下載MindSpore 的LeNet代碼庫和Fashion MNIST的訓練數據,按照下面的方式把它們放到MindSporeLeNet模塊下即可:
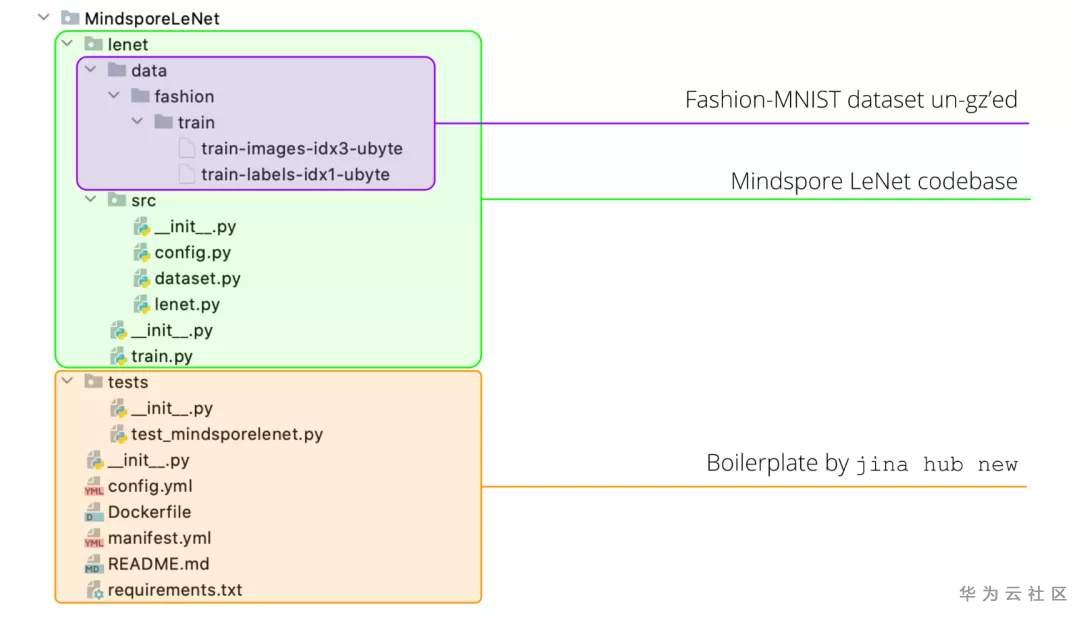
圖7 MindSporeLeNet代碼結構
修改MindSpore的Encoder和網絡結構代碼
- 1.修改__init__.py
這是原始的__init__.py 代碼,有一個基礎類BaseEncoder ,我們要改變一下encode的方式,把它變成 BaseMindsporeEncoder。
from jina.executors.encoders import BaseEncoder class MindsporeLeNet(BaseEncoder): """ :class:`MindsporeLeNet` What does this executor do?. """ def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) # your customized __init__ below raise NotImplementedError def encode(self, data, *args, **kwargs): raise NotImplementedError
BaseMindsporeEncoder 是Jina中的抽象類,它在__init__構造函數中會導入MindSpore模型的checkpoint。此外,它還能通過self.model提供MindSpore模型的屬性接口。下面這張表顯示了MindSporeLeNet通過構造函數繼承的類。
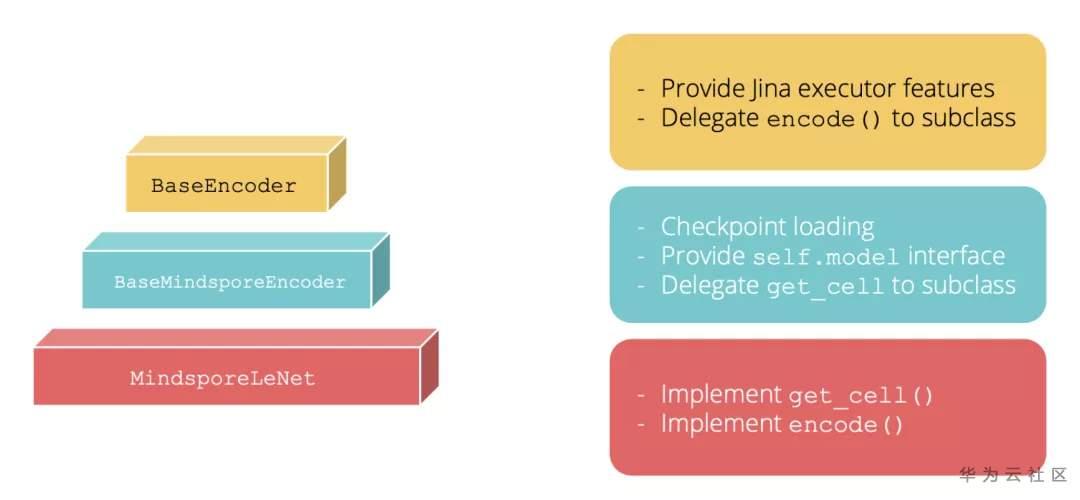
圖8 MindSporeLeNet中繼承的類
修改完以後如下所示:
from jina.executors.encoders.frameworks import BaseMindsporeEncoder class MindsporeLeNet(BaseMindsporeEncoder): """ :class:`MindsporeLeNet` Encoding image into vectors using mindspore. """ def encode(self, data, *args, **kwargs): # do something with `self.model` raise NotImplementedError def get_cell(self): raise NotImplementedError
- 2.執行 encode() 方法。
給定一堆batch size為B的圖像數據(用的numpy 的ndarray來表示,shape為[B, H, W]),encode() 把圖像數據轉換成向量的embeddings(shape為[B, D])。通過self.model 導入MindSpore LeNet 模型後,我們可以通過self.model(Tensor(data)).asnumpy()來進行轉換即可。
注意:self.model的輸入shape很容易出錯。原始的LeNet模型的輸入是三通道的圖片,shape是32×32,所以輸入必須是[B, 3, 32, 32]。然而Fashion-MNIST是灰度圖片,單通道,圖像的shape是28×28,所以我們要麼調整圖片的尺寸,要麼給圖片補零。這裡我們就用簡單的補零操作了。最終的encode()函數如下所示:
def encode(self, data, *args, **kwargs): # LeNet only accepts BCHW format where H=W=32 # hence we need to do some simple padding data = numpy.pad(data.reshape([-1, 1, 28, 28]), [(0, 0), (0, 0), (0, 4), (0, 4)]).astype('float32') return self.model(Tensor(data)).asnumpy()
- 3.執行get_cell()方法。
在MindSpore中,我們通常把神經網絡中的層叫做『cell』,它可以是一個單獨的神經網絡層(譬如conv2d, relu, batch_norm)。為了得到向量的embedding,我們只需要從LeNet中移除classification head 即可(譬如最後一個softmax層)。這個很好實現,只需要從原始的LeNet5類中繼承,然後重寫construct() 函數即可。
def get_cell(self): from .lenet.src.lenet import LeNet5 class LeNet5Embed(LeNet5): def construct(self, x): x = self.conv1(x) x = self.relu(x) x = self.max_pool2d(x) x = self.conv2(x) x = self.relu(x) x = self.max_pool2d(x) x = self.flatten(x) x = self.fc1(x) x = self.relu(x) x = self.fc2(x) x = self.relu(x) return x return LeNet5Embed()
寫一個單元測試
當你在創建一個Jina executor 的時候,一定不要忘了寫單元測試,如果在executor里沒有單元測試的話,是無法通過 Jina Hub API來創建的哦~
在這個樣例中已經生成了一個測試模板,你可以在tests 文件夾裏面找到test_mindsporelenet.py 文件。先檢查下MindSpore是否運行,如果可以運行的話,看看輸出的shape是否是我們所希望的。
import numpy as np from .. import MindsporeLeNet def test_mindsporelenet(): """here is my test code https://docs.pytest.org/en/stable/getting-started.html#create-your-first-test """ mln = MindsporeLeNet(model_path='lenet/ckpt/checkpoint_lenet-1_1875.ckpt') tmp = np.random.random([4, 28 * 28]) # The sixth layer is a fully connected layer (F6) with 84 units. # it is the last layer before the output assert mln.encode(tmp).shape == (4, 84)
準備Dockerfile
python層面的準備工作已經完成了,下面我們準備Docker image。我們可以基於已有的Dockerfile來創建,只需要加一行運行train.py代碼來生成checkpoint文件的代碼即可。
FROM mindspore/mindspore-cpu:1.0.0 # setup the workspace COPY . /workspace WORKDIR /workspace # install the third-party requirements RUN pip install --user -r requirements.txt + RUN cd lenet && \ + python train.py --data_path data/fashion/ --ckpt_path ckpt --device_target="CPU" && \ + cd - # for testing the image RUN pip install --user pytest && pytest -s ENTRYPOINT ["jina", "pod", "--uses", "config.yml"]
這一行使用了MindSpore LeNet代碼庫里的train.py來生成訓練的checkpoint。我們在測試和部署的時候會用到這個checkpoint。在config.yml文件中,需要把checkpoint的文件地址放在model_path這個參數里。requests.on定義了MindSporeLeNet在index和search的request下應該如何執行。如果上面這些內容不理解也沒關係,其實都是從helloworld.encoder.yml這個文件里複製和改動的。
!MindsporeLeNet with: model_path: lenet/ckpt/checkpoint_lenet-1_1875.ckpt metas: py_modules: - __init__.py # - You can put more dependencies here requests: on: [IndexRequest, SearchRequest]: - !Blob2PngURI {} - !EncodeDriver {} - !ExcludeQL with: fields: - buffer - chunks
最後一步:終於可以Build了!
終於可以把MindSporeLeNet build成Docker鏡像了!!執行以下命令:
jina hub build MindsporeLeNet/ --pull --test-uses
- –pull :當你的圖片數據集不在本地時,這個命令會告訴 Hub builder 來下載數據集
- –test-uses :增加一個額外的測試來檢查創建的鏡像是否可以通過 Jina Flow API試運行成功。
現在終端已經開始打印日誌了,如果時間太久的話,可以在MindsporeLeNet/lenet/src/config.py 中將epoch_size調小。
最後成功的信息:
HubIO@51772[I]:Successfully built cfa38dcfc1f9 HubIO@51772[I]:Successfully tagged jinahub/pod.encoder.mindsporelenet:0.0.1 HubIO@51772[I]:building MindsporeLeNet/ takes 57 seconds (57.86s) HubIO@51772[S]: built jinahub/pod.encoder.mindsporelenet:0.0.1 (sha256:cfa38dcfc1) uncompressed size: 1.1 GB
現在你可以通過下面的命令將它作為一個Pod來使用了:
jina pod --uses jinahub/pod.encoder.mindsporelenet:0.0.1
對比jina pod –uses abc.yml, 我們會發現jinahub/pod.encoder.mindsporelenet:0.0.1的日誌信息的開頭處有一個docker容器。這些log日誌是從Docker的container傳輸到host端的,下面描述了兩者具體的差異。

圖9 差異對比
當然,你也可以上傳這個鏡像到Docker倉庫里:
jina hub build MindsporeLeNet/ --pull --test-uses --repository YOUR_NAMESPACE --push
來看MindSpore的成品吧!
最後,直接在index和search的flow中來使用新創建的MindSpore Executor吧,很簡單,只需要替換pods.encode.uses這行代碼就行:
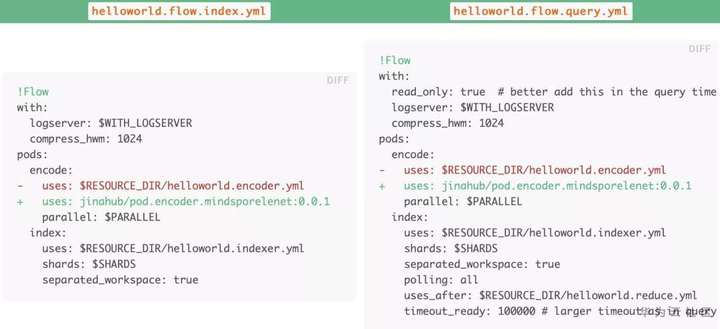
圖10 index與query的YAML文件差異
jina hello-world 的參數可以自定義,只要指定我們剛剛編寫好的index和query的YAML文件,輸入以下命令即可:
jina hello-world --uses-index helloworld.flow.index.yml --uses-query helloworld.flow.query.yml
哈哈,完成了!幾分鐘之內你就可以看到開頭動圖顯示的查詢結果了!
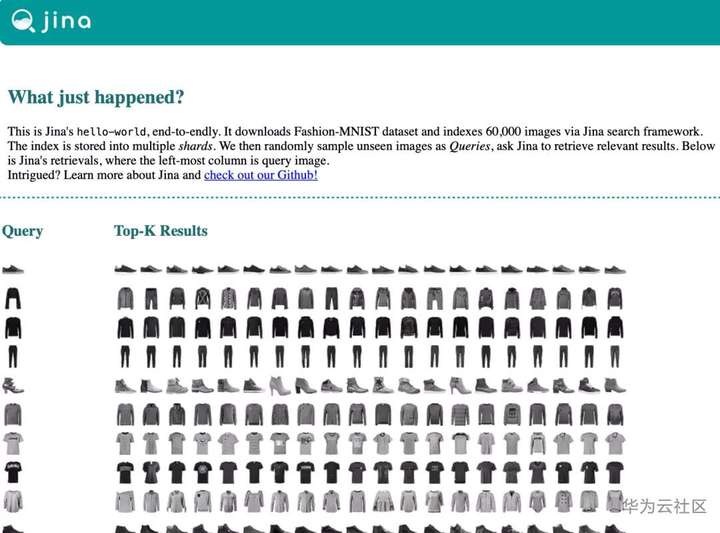
圖11 最終輸出結果
總結
本文中使用了MindSpore+Jina來共同搭建一個服裝搜索系統,代碼非常簡單,其實只要學會修改encode的代碼,根據需要構建網絡層,然後打包成docker的image,修改YAML文件就可以用Jina來實現最終的展示效果了,這樣大家只要可以根據自己的需求,修改少量的代碼,即可自行搭建一個基於MindSpore的搜索系統,是不是非常簡單呢~感興趣的同學可以直接點擊以下鏈接,就可以直接運行://gitee.com/mindspore/community/tree/master/mindspore-jina
本文分享自華為雲社區《3分鐘教你用MindSpore和Jina搭建一個服裝搜索系統!》,原文作者:chengxiaoli 。

