推薦模型AutoRec:原理介紹與TensorFlow2.0實現
1. 簡介
本篇文章先簡單介紹論文思路,然後使用Tensoflow2.0、Keras API復現算法部分。包括:
-
自定義模型
-
自定義損失函數
-
自定義評價指標RMSE
就題目而言《AutoRec: Autoencoders Meet Collaborative Filtering》,自編碼機遇見協同過濾,可見是使用自編碼機結合協同過濾思想進行的算法。論文經過數據集Movielens和Netfix驗證有不錯的效果,更重要的是它是對特徵交叉引入深度學習的開端,論文兩頁,簡單易懂。
2. 算法模型
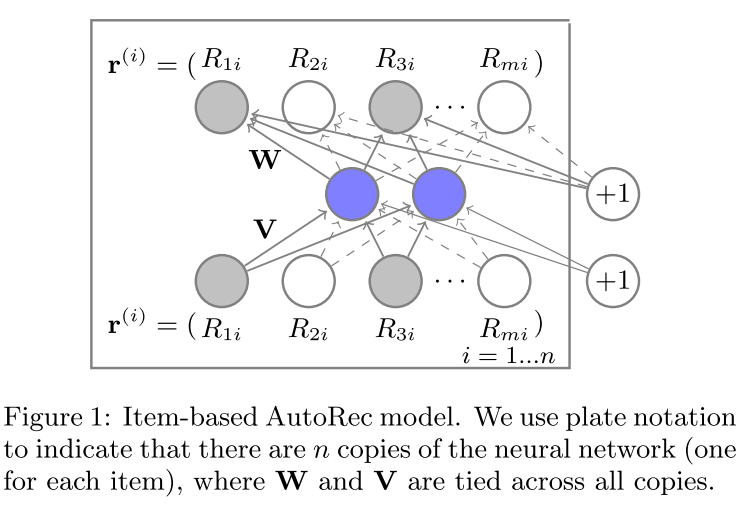
令m個用戶,n個物品,構成用戶-物品矩陣,每個物品對被用戶進行評分。根據協同過濾思想,有基於用戶的方式,也有基於物品的方式,取決於輸入是物品分表示的用戶向量,還是用戶評分表示物品向量$r{i},r{u}$。自編碼機部分將評分向量進行低維壓縮,用低維空間表示評分向量,並對向量不同部分進行交叉,然後重構向量。
算法模型圖為:
採用的模型公式為(基本就是邏輯回歸的方式):
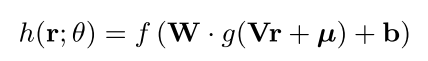
其中,中間的神經元數量,即映射低維空間設為k,則k是一個超參數根據效果進行調控。
需要注意的部分是
-
每個評分向量(無論物品還是用戶向量),都存在稀疏性即沒有用戶對其進行評分,則在反向傳播的過程中不能考慮這部分內容;
-
為了防止過擬合,需要在損失函數中添加W和V參數矩陣正則化:
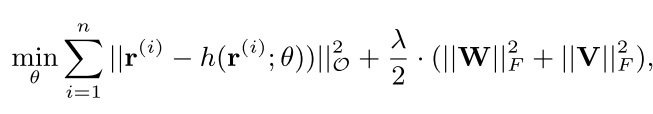
前一部分為真實值與預測值的平方誤差(僅僅計算有評分的部分),第二部分為正則項,所求為F範數。
預測公式:
若是基於物品的AutoRec(I-AutoRec)則,輸入待求的物品向量,到下面預測公式中,得到一個完整的向量,求第幾個用戶就取第幾個維度從而得到此用戶對此物品的評分,即

基於用戶的AutoRec(U-AutoRec)表示類似。
實驗驗證
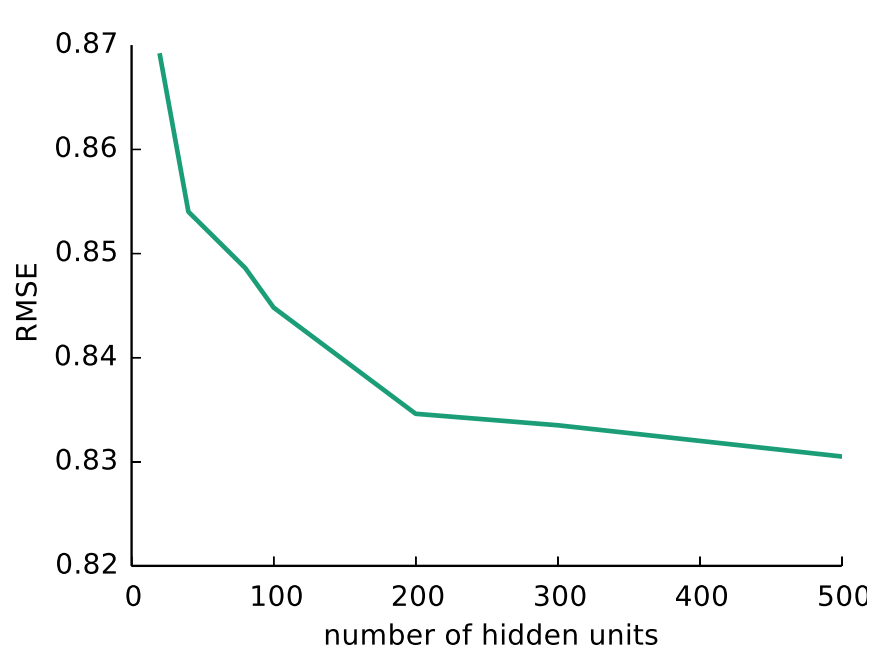
論文的評價方式,使用的RMSE,與其他算法比較得到比較好的參數是k=500,f映射使用線性函數,g映射使用Sigmoid函數。

3. 代碼復現
復現包括網絡模型,損失函數,以及評價指標三部分,由於部分的改動不能直接使用TF原生的庫函數。
首先導入需要使用的工具包:
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
定義模型
基於Keras的API的模型定義需要繼承Model類,重寫方法call(前向傳播過程),如果需要加入dropout的模型需要將訓練和預測分開可以使用參數training=None的方式來指定,這裡不需要這個參數,因此省略。
class AutoRec(keras.Model):
def __init__(self, feature_nums, hidden_units, **kwargs):
super(AutoRec, self).__init__()
self.feature_nums = feature_nums # 基於物品則為物品特徵數-即用戶數,基於用戶則為物品數量
self.hidden_units = hidden_units # 論文中的k參數
self.encoder = keras.layers.Dense(self.hidden_units, input_shape=[self.feature_nums], activation='sigmoid') # g映射
self.decoder = keras.layers.Dense(self.feature_nums, input_shape=[self.hidden_units]) # f映射
def call(self, X):
# 前向傳播
h = self.encoder(X)
y_hat = self.decoder(h)
return y_hat
定義損失函數
此損失函數雖然為MSE形式,但是在計算的過程中發現,僅僅計算有評分的部分,無評分部分不進入損失,同時還有正則化,這裡一起寫出來。
基於Keras API的方式,需要繼承Loss類,和方法call初始化傳入model參數為了取出W和V參數矩陣。
mask_zero表示沒有評分的部分不進入損失函數,同時要保證數據類型統一tf.int32,tf.float32否則會報錯。
class Mse_Reg(keras.losses.Loss):
def __init__(self, model, reg_factor=None):
super(Mse_Reg, self).__init__()
self.model = model
self.reg_factor = reg_factor
def call(self, y_true, y_pred) :
y_sub = y_true - y_pred
mask_zero = y_true != 0
mask_zero = tf.cast(mask_zero, dtype=y_sub.dtype)
y_sub *= mask_zero
mse = tf.math.reduce_sum(tf.math.square(y_sub)) # mse損失部分
reg = 0.0
if self.reg_factor is not None:
weight = self.model.weights
for w in weight:
if 'bias' not in w.name:
reg += tf.reduce_sum(tf.square(w)) # 求矩陣的Frobenius範數的平方
return mse + self.reg_factor * 0.5 * reg
return mse
定義RMSE評價指標
定義評價指標需要繼承類Metric,方法update_state和result以及reset,reset方法感覺使用較少,主要是更新狀態和得到結果。
class RMSE(keras.metrics.Metric):
def __init__(self):
super(RMSE, self).__init__()
self.res = self.add_weight(name='res', dtype=tf.float32, initializer=tf.zeros_initializer())
def update_state(self, y_true, y_pred, sample_weight=None):
y_sub = y_true - y_pred
mask_zero = y_true != 0
mask_zero = tf.cast(mask_zero, dtype=y_sub.dtype)
y_sub *= mask_zero
values = tf.math.sqrt(tf.reduce_mean(tf.square(y_sub)))
self.res.assign_add(values)
def result(self):
return self.res
定義數據集
定義好各個部分之後,就可以構造訓練集然後訓練模型了。
get_data表示從path中加載數據,然後加數據通過pandas的透視表功能構造一個行為物品,列為用戶的矩陣;
data_iter表示通過tf.data構造數據集。
# 定義數據
def get_data(path, base_items=True):
data = pd.read_csv(path)
rate_matrix = pd.pivot_table(data, values='rating', index='movieId', columns='userId',fill_value=0.0)
if base_items:
return rate_matrix
else :
return rate_matrix.T
def data_iter(df, shuffle=True, batch_szie=32, training=False) :
df = df.copy()
X = df.values.astype(np.float32)
ds = tf.data.Dataset.from_tensor_slices((X, X)).batch(batch_szie)
if training:
ds = ds.repeat()
return ds
訓練模型
萬事俱備,就準備數據放給模型就好了。
要說明的是,如果fit的時候不設置steps_per_epoch會在數據量和batch大小不能整除的時候報迭代器的超出範圍的錯誤。設置了此參數當然也要加上validation_steps=2,不然還是會報錯,不信可以試試看。
path = 'ratings.csv' # 我這裡用的是10w數據,不是原始的movielens-1m
# I-AutoRec,num_users為特徵維度
rate_matrix = get_data(path)
num_items, num_users = rate_matrix.shape
# 劃分訓練測試集
BARCH = 128
train, test = train_test_split(rate_matrix, test_size=0.1)
train, val = train_test_split(train, test_size=0.1)
train_ds = data_iter(train, batch_szie=BARCH, training=True)
val_ds = data_iter(val, shuffle=False)
test_ds = data_iter(test, shuffle=False)
# 定義模型
net = AutoRec(feature_nums=num_users, hidden_units=500) # I-AutoRec, k=500
net.compile(loss=Mse_Reg(net), #keras.losses.MeanSquaredError(),
optimizer=keras.optimizers.Adam(),
metrics=[RMSE()])
net.fit(train_ds, validation_data=val_ds, epochs=10, validation_steps=2, steps_per_epoch=train.shape[0]//BARCH)
loss, rmse = net.evaluate(test_ds)
print('loss: ', loss, ' rmse: ', rmse)
預測
df = test.copy()
X = df.values.astype(np.float32)
ds = tf.data.Dataset.from_tensor_slices(X) # 這裡沒有第二個X了
ds = ds.batch(32)
pred = net.predict(ds)
# 隨便提出來一個測試集中有的評分看看預測的分數是否正常,pred包含原始為0.0的分數現在已經預測出來分數的。
print('valid: pred user1 for item1: ', pred[1][X[1].argmax()], 'real: ', X[1][X[1].argmax()])
得到結果(沒有達到論文的精度,可能是數據量不足,而valid部分可以看到預測的精度還是湊合的):

4. 小結
本篇文章主要是針對AutoRec論文的主要部分進行了介紹,然後使用TensorFlow2.0的Keras接口實現了自定義的模型,損失,以及指標,並訓練了I-AutoRec模型。
關於AutoRec要說的是,
編碼器部分如果使用深層網絡比如三層會增加預測的準確性;
自編碼器部分的輸出向量經過了編碼過程的泛化相當於對缺失部分有了預測能力,這是自編碼機用於推薦的原因;
I-AutoRec推薦過程,需要輸入物品的矩陣然後得到每個用戶對物品的預測評分,然後取用戶自己評分的Top可以進行推薦,U-AutoRec只需要輸入一次目標用戶的向量就可以重建用戶對所有物品的評分,然後得到推薦列表,但是用戶向量可能稀疏性比較大影響最終的推薦效果。
AutoRec使用了單層網絡,存在表達能力不足的問題,但對於基於機器學習的矩陣分解,協同過濾來說,由於這層網絡的加入特徵的表達能力得到提高。

