SnowNLP——獲取關鍵詞(keywords(1))
一、SnowNLP的獲取文本關鍵詞
前面介紹了SnowNLP的獲取關鍵詞的方法,這裡再重現一下
1 from snownlp import SnowNLP 2 # 提取文本關鍵詞,總結3個關鍵詞 3 text = '隨着頂層設計完成,全國政協按下信息化建設快進鍵:建設開通全國政協委員移動履職平台,開設主題議政群、全國政協書院等欄目,建設委員履職數據庫,拓展網上委員履職綜合服務功能;建成網絡議政遠程協商視頻會議系統,開展視頻調研、遠程討論活動,增強網絡議政遠程協商實效;建立修訂多項信息化規章制度,優化電子政務網絡。' 4 s = SnowNLP(text) 5 print(s.keywords(3)) 6 7 --->['全國', '政協', '遠程']
二、源碼分析
我們進入SnowNLP的源碼看一下
1、SnowNLP(text)
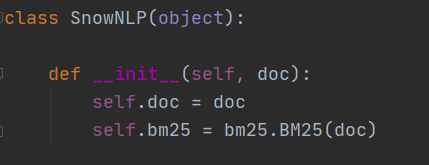
這裡我們記住self.doc是我們傳入的文本
2、keywords(self, limit=5, merge=False)

這是SnowNLP源碼中keywords方法的源碼,我們一行一行的看下具體流程:
70 def keywords(self, limit=5, merge=False):
limit參數:這個參數對應的是調用 keywords(3)方法時傳入的形參,默認為5,即默認會返回五個關鍵詞。
71 doc = [] 72 sents = self.sentences
這是做了一個賦值,我看看下源碼:
self.sentences是對輸入文本的整理,對文本分句、分詞

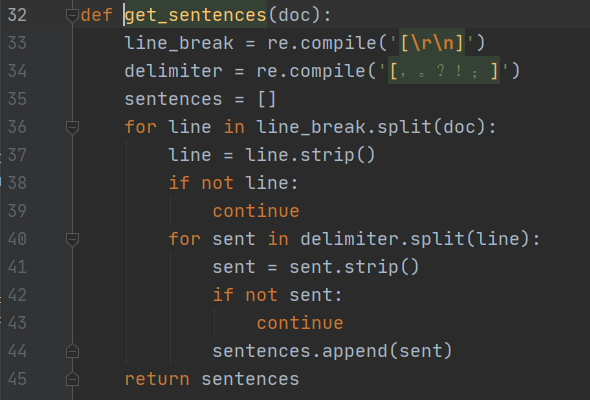
上圖參數中的doc是我們傳入的文本,這個方法主要功能是將我們傳入的文本進行整理
33行、34行:定義了兩個正則表達式,分別是篩選換行符、部分中文標點
36行:是根據換行符對文本進行切割後進行遍歷。
40行:再上一次循環中,又將文本根據中文標點符號進行分割。
44行:將得到的句子放到一個list中,即sentences。
我們再回到keywords方法中:
72 sents = self.sentences
由此得到一個sents,裏面存儲的是我們輸入文本分割成的句子的list
73 for sent in sents: #對sents進行遍歷,得到每個句子 74 words = seg.seg(sent) #對句子進行分詞 75 words = normal.filter_stop(words) #去除停用詞 76 doc.append(words) #將得到的每個句子的分詞加到doc中
77 rank = textrank.KeywordTextRank(doc) #得到一個KeywordTextRank對象 78 rank.solve() #計算詞語的關鍵度,並進行關鍵排序
這裡我們看一下KeywordTextRank()類以及rank.solve()方法:
rank.solve()是計算關鍵度的方法,是獲取關鍵詞的核心!!
1 class KeywordTextRank(object): 2 3 def __init__(self, docs): 4 self.docs = docs 5 self.words = {} 6 self.vertex = {} 7 self.d = 0.85 8 self.max_iter = 200 9 self.min_diff = 0.001 10 self.top = [] 11 12 def solve(self): 13 for doc in self.docs: # self.docs是我們傳入的文本被分詞後的詞語list:[['a','b','c'],['d','e'],['f','g']] 14 que = [] 15 for word in doc: # 遍歷每個句子的詞語,得到該句的詞 16 if word not in self.words: # 如果該詞不存在self.words中,則添加進去 17 self.words[word] = set() # 一個字典集合:{'word':set()} 18 self.vertex[word] = 1.0 # 一個字典集合:{'word':1.0} 19 que.append(word) #將詞加到que中:['word'] 20 if len(que) > 5: 21 que.pop(0) # 如果que的長度大於5則移除第一個詞 22 for w1 in que: # 遍歷que 23 for w2 in que: # 遍歷que 24 if w1 == w2: 25 continue # 如果w1與w2相等則結束這一輪循環,繼續下一輪循環 26 self.words[w1].add(w2) # 將詞加到自己字典中 27 self.words[w2].add(w1) # 28 for _ in range(self.max_iter): # 循環200次 29 m = {} 30 max_diff = 0 31 tmp = filter(lambda x: len(self.words[x[0]]) > 0, 32 self.vertex.items()) # 過濾每個詞,判斷值位的set中是否有值,有的話保留,返回:[('a', 1), ('b', 1), ('c', 1)] 33 tmp = sorted(tmp, key=lambda x: x[1] / len(self.words[x[0]])) # 根據值位的set的長度排序,返回:[('a', 1), ('b', 1), ('c', 1)] 34 for k, v in tmp: # k為詞,v為相關度 35 for j in self.words[k]: # 遍歷每個詞對應的set集合(相關詞) 36 if k == j: 37 continue 38 if j not in m: 39 m[j] = 1 - self.d 40 m[j] += (self.d / len(self.words[k]) * self.vertex[k]) # m值 = 0.85 / set的長度 * 1 41 for k in self.vertex: # {詞1:相關度1,詞2:相關度2} 42 if k in m and k in self.vertex: 43 if abs(m[k] - self.vertex[k]) > max_diff: # 計算本次相關度與上一次相關度之差的絕對值是否符合設定的閾值 44 max_diff = abs(m[k] - self.vertex[k]) # 改變閾值 45 self.vertex = m # 獲取到本次相關度集合 46 if max_diff <= self.min_diff: # 設定退出條件 47 break 48 self.top = list(self.vertex.items()) # 將字典轉成集合 49 self.top = sorted(self.top, key=lambda x: x[1], reverse=True) # 根據相似度進行排序 [('a', 1), ('b', 2), ('c', 3)] 50 51 def top_index(self, limit): 52 return list(map(lambda x: x[0], self.top))[:limit] # 獲取list的值的key,並截取list,[0-limit) 53 54 def top(self, limit): 55 return list(map(lambda x: self.docs[x[0]], self.top)) # 獲取字典中top字段對應值的value
我們再回到keywords方法中:
79 ret = [] 80 for w in rank.top_index(limit): # 獲取按詞語關鍵度排序後並截取長度的list 81 ret.append(w)
82 if merge: 83 wm = words_merge.SimpleMerge(self.doc, ret) 84 return wm.merge() 85 return ret
merge默認為False,如果手動設定為True的話將走SimpleMerge類對結果重新處理
看下SimpleMerge源碼:
# -*- coding: utf-8 -*- from __future__ import unicode_literals class SimpleMerge(object): def __init__(self, doc, words): self.doc = doc self.words = words def merge(self): trans = {} for w in self.words: trans[w] = '' for w1 in self.words: cw = 0 lw = len(w1) for i in range(len(self.doc)-lw+1): if w1 == self.doc[i: i+lw]: cw += 1 for w2 in self.words: cnt = 0 l2 = len(w1)+len(w2) for i in range(len(self.doc)-l2+1): if w1+w2 == self.doc[i: i+l2]: cnt += 1 if cw < cnt*2: trans[w1] = w2 break ret = [] for w in self.words: if w not in trans: continue s = '' now = trans[w] while now: s += now if now not in trans: break tmp = trans[now] del trans[now] now = tmp trans[w] = s for w in self.words: if w in trans: ret.append(w+trans[w]) return ret


