Elasticsearch 分片集群原理、搭建、與SpringBoot整合
單機es可以用,沒毛病,但是有一點我們需要去注意,就是高可用是需要關注的,一般我們可以把es搭建成集群,2台以上就能成為es集群了。集群不僅可以實現高可用,也能實現海量數據存儲的橫向擴展。
新的閱讀體驗地址: //www.zhouhong.icu/post/138
一、Elasticsearch分片機制:
- 每個索引可以被分片,每個主分片都包含索引的數據。
- 副本分片是主分片的備份,主掛了,備份還是可以訪問,這就需要用到集群了。
- 同一個分片的主與副本是不會放在同一個服務器里的,因為一旦宕機,這個分片就沒了。
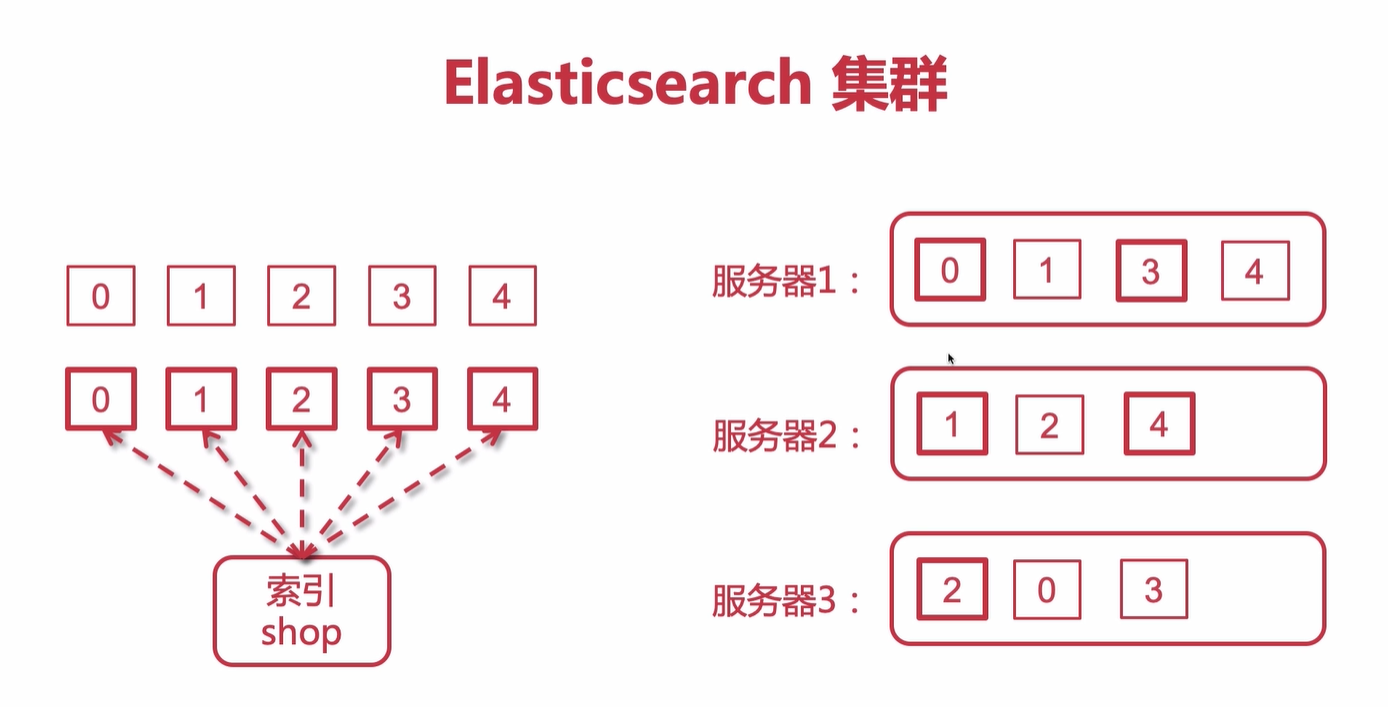
如下圖:左邊每個索引主備分片都會分配在三台服務器上的不同節點上面,右圖粗方框表示主分片,細節點表示備節點。
二、搭建Elasticsearch集群
1、前置操作
- ES中之前的data目錄,一定要清空,這裏面包含了原先的索引庫數據。
- 使用三台服務器:
- 192.168.1.184(主), 192.168.1.185(從), 192.168.1.186(從)
- 關於Elasticsearch單機的簡介、安裝配置請轉到://www.zhouhong.icu/post/128
2、配置集群
- 修改每台服務器上ES的elasticsearch.yml這個配置文件如下,每台服務器node.name不一樣分別為es-node1、es-node2、es-node3.
# 配置集群名稱,保證每個節點的名稱相同,如此就能都處於一個集群之內了 cluster.name: es-cluster # 每一個節點的名稱,必須不一樣 node.name: es-node1 # http端口(使用默認即可) http.port: 9200 # 主節點,作用主要是用於來管理整個集群,負責創建或刪除索引,管理其他非master節點(相當於企業老總) node.master: true # 數據節點,用於對文檔數據的增刪改查 node.data: true # 集群列表 discovery.seed_hosts: ["192.168.1.184", "192.168.1.185", "192.168.1.186"] # 啟動的時候使用一個master節點,未指定ES會進行選舉 cluster.initial_master_nodes: ["es-node1"]
3、最後可以通過如下命令查看配置文件的內容:(過濾掉「#」後面的注釋)
more elasticsearch.yml | grep ^[^#]
4、切換到esuser後啟動,訪問集群各個節點,查看信息:
- //192.168.1.184:9200/
- //192.168.1.185:9200/
- //192.168.1.186:9200/
主節點宕機之後會從生下的兩個從節點選舉新的主節點,主節點恢復後成為從節點。
三、Elasticsearch集群腦裂現象
1、什麼是腦裂
- 如果發生網絡中斷或者服務器宕機,那麼集群會有可能被劃分為兩個部分,各自有自己的master來管理,那麼這就是腦裂。

2、腦裂解決方案
- master主節點要經過多個master節點共同選舉後才能成為新的主節點。就跟班級里選班長一樣,並不是你1個人能決定的,需要班裡半數以上的人決定。
- 解決實現原理:半數以上的節點同意選舉,節點方可成為新的master。
discovery.zen.minimum_master_nodes=(N/2)+1
- N為集群的中master節點的數量,也就是那些 node.master=true 設置的那些服務器節點總數。
3、ES 7.X
- 在最新版7.x中,minimum_master_node這個參數已經被移除了,這一塊內容完全由es自身去管理,這樣就避免了腦裂的問題,選舉也會非常快。『』
四、Elasticsearch集群的文檔讀寫原理
-
文檔寫原理:p1,p2,p0是主節點,r0,r1,r2是副本節點
- 如果客戶端選擇了中間節點進行寫數據,那這個節點就會變成協調節點,接受用戶請求,會對文檔進行路由,計算這個文檔會寫入到哪個主分片中,有主分片把數據同步到副本分片,都寫入完成之後,在跳回到協調節點,由協調節點相應請求。

-
文檔讀原理:p1,p2,p0是主節點,r0,r1,r2是副本節點
- 如果客戶端請求到了第一個節點,那第一個節點也會變成協調節點,然後根據文檔的數據進行路由,然後從主分片或者副本分片輪詢讀數據。不管從主分片還是副本分片讀取數據,最後都會跳回到協調節點,由協調節點相應客戶端

五、Elasticsearch集群與SpringBoot整合
1、創建工程,引入依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
2、配置yml文件:客戶端連接的是 9300
spring: data: elasticsearch: cluster-name: es-cluster cluster-nodes: 192.168.1.184:9300,192.168.1.185:9300,192.168.1.186:9300
版本協調:
目前springboot-data-elasticsearch中的es版本貼合為es-6.4.3,如此一來版本需要統一,把es進行降級。等springboot升級es版本後可以在對接最新版的7.4。
3、解決啟動時 Netty issue fix 問題
在啟動類同一級目錄下創建 ESConfig.java 配置類
@Configuration public class ESConfig { /** * 解決netty引起的issue */ @PostConstruct void init() { System.setProperty("es.set.netty.runtime.available.processors", "false"); } }


