MySQL——關於索引的總結
索引的優缺點
首先說說索引的優點:最大的好處無疑就算提高查詢效率。有的索引還能保證數據的唯一性,比如唯一索引。
而它的壞處很明顯:索引也是文件,我們在創建索引時,也會創建額外的文件,所以會佔用一些硬盤空間。其次,索引也需要維護,我們在增加刪除數據的時候,索引也需要去變化維護。當一個表的索引多了以後,資源消耗是很大的,所以必須結合實際業務再去確定給哪些列加索引。
索引的結構
再說說索引的基本結構。一說到這裡肯定會脫口而出:B+樹!了解B+樹前先要了解二叉查找樹和二叉平衡樹。二叉查找樹:左節點比父節點小,右節點比父節點大,所以二叉查找樹的中序遍歷就是樹的各個節點從小到大的排序。二叉平衡樹:左右子樹高度差不能大於1。B+樹就是結合了它們的特點,當然,不一定是二叉樹。
為什麼要有二叉查找樹的特點??因為查找效率快,二分查找在這種結構下,查找效率是很快的。那為什麼要有平衡樹的特點呢?試想,如果不維護一顆樹的平衡性,當插入一些數據後,樹的形態有可能變得很極端,比如左子樹一個數據沒有,而全在右子樹上,這種情況下,二分查找和遍歷有什麼區別呢?而就是因為這些特點需要去維護,所以就有了上面提到的缺點,當索引很多後,反而增加了系統的負擔。
接著說B+樹。它的結構如下:
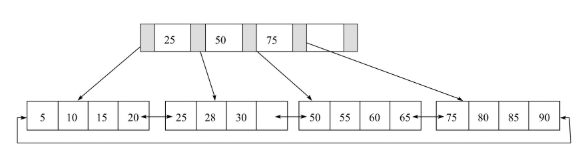
可以發現,葉子節點其實是一個雙向循環鏈表,這種結構的好處就是,在範圍查詢的時候,我只用找到一個數據,就可以直接返回剩餘的數據了。比如找小於30的,只用找到30,其餘的直接通過葉子節點間的指針就可以找到。再說說其他特點:數據只存在於葉子節點。當葉子節點滿了,如果再添加數據,就會拆分葉子節點,父節點就多了個子節點。如果父節點的位置也滿了,就會擴充高度,就是拆分父節點,如25 50 75拆分成:25為左子樹,75為右子樹,50變成新的頭節點,此時B+樹的高度變成了3。它們的擴充的規律如下表,Leaf Page是葉子節點,index Page是非葉子節點。

再說說B樹,B樹相比較B+樹,它所有節點都存放數據,所以在查找數據時,B樹有可能沒到達葉子節點就結束了。再者,B樹的葉子節點間不存在指針。
最後說說Hash索引,相較於B+樹,Hash索引最大的優點就是查找數據快。但是Hash索引最大的問題就是不支持範圍查詢。試想,如果查詢小於30的數據,hash函數是根據數據的值找到其對應的位置,誰又知道小於30的有哪幾個數據。而B+樹正好相反,範圍查詢是它的強項。
附錄:Hash到底是啥??哈希中文名散列,哈希只是它的音譯。為啥都說Hash快??首先有一塊哈希表(散列表),它的數據結構是個數組,一個任意長度的數據通過hash函數都可以變成一個固定長度的數據,叫hash值。然後通過hash值確定在數組中的位置,相同數據的hash值是相同的,所以我們存儲一個數據以後,只需O(1)的時間複雜度就可以找到數據。那hash函數又是啥??算術運算或位運算,很多應用里都有hash函數,但實際運算過程大不一樣。這是Java里String的hashCode方法:
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
還有一個問題,hash函數計算出來的hash值有可能存在碰撞,即兩個不同的數據可能存在相同的hash值,在MySQL或其他的應用中,如Java的HashMap等,如果存在碰撞就會以當前數組位置為頭節點,轉變成一個鏈表。
說到這裡也清楚了為啥Java中引用類型要同時重寫hashCode和equals了。兩個對象,實例就算一模一樣,它們的hash值也不相等,為啥不相等??默認的Object的hashCode方法會根據對象來計算hash值的,實例相同,但它們還是兩個不同的對象啊,所以我們重寫hashCode時,最簡單的方法就是調用Object的hashCode方法,然後傳入該引用類型的屬性,讓hashCode方法只根據這幾個屬性來計算,那麼實例相同的話,它們的hash值也會相等。等hashCode比較完後,如果相等再比較實例內容,也就是equals,確保不是hash碰撞。
索引的分類
主鍵索引:如果我們指定了一個主鍵,那麼這個主鍵就是主鍵索引。如果我們沒有指定,Mysql就會自動找一個非空的唯一索引當主鍵。如果沒有這種字段,Mysql就會創建一個大小為6位元組的自增主鍵。如果有多個非空的唯一索引,那麼就讓第一個定義為唯一索引的字段當主鍵,注意,是第一個定義,而不是建表時出現在前面的。
輔助索引:對於輔助索引來說,它們的B+樹結構稍微有點特殊,它們的葉子節點存儲的是主鍵,而不是整個數據。所以在大部分情況下,使用輔助索引查找數據,需要二次查找。但並不是所有情況都需要二次查找。比如查找的數據正好就是當前索引字段的值,那麼直接返回就行。這裡提一句,B+樹的key就是對應索引字段的內容。
而輔助索引又有一些分類:唯一索引:不能出現重複的值,也算一種約束。普通索引:可以重複、可以為空,一般就是查詢時用到。前綴索引:只適用於字符串類型數據,對字符串前幾個字符創建索引。全文索引:作用是檢測大文本數據中某個關鍵字,這也是搜索引擎的一種技術。
聚集索引:注意,聚集索引、非聚集索引和前面幾個索引的分類並不是一個層面上的。上面的幾個分類是從索引的作用來分析的。聚集、非聚集索引是從索引文件上區分的。主鍵索引就屬於聚集索引,即索引和數據存放在一起,葉子節點存放的就是數據。數據表的.idb文件就是存放該表的索引和數據。
非聚集索引:輔助索引屬於非聚集索引,說到這也就明白了。索引和數據不存放在一起的就是非聚集索引。在MYISAM引擎中,數據表的.MYI文件包含了表的索引, 該表的 葉子節點存儲索引和索引對應數據的指針,指向.MYD文件的數據。
索引的幾點使用經驗
適合創建索引的字段:經常被查詢的字段;經常作為條件查詢的字段;經常用於外鍵連接或普通的連表查詢時進行相等比較字段;不為null的字段;如果是多條件查詢,最好創建聯合索引,因為聯合索引只有一個索引文件。
不適合創建索引的字段:經常被更新的字段、不經常被查詢的字段、存在相同功能的字段

