MySQL——关于索引的总结
索引的优缺点
首先说说索引的优点:最大的好处无疑就算提高查询效率。有的索引还能保证数据的唯一性,比如唯一索引。
而它的坏处很明显:索引也是文件,我们在创建索引时,也会创建额外的文件,所以会占用一些硬盘空间。其次,索引也需要维护,我们在增加删除数据的时候,索引也需要去变化维护。当一个表的索引多了以后,资源消耗是很大的,所以必须结合实际业务再去确定给哪些列加索引。
索引的结构
再说说索引的基本结构。一说到这里肯定会脱口而出:B+树!了解B+树前先要了解二叉查找树和二叉平衡树。二叉查找树:左节点比父节点小,右节点比父节点大,所以二叉查找树的中序遍历就是树的各个节点从小到大的排序。二叉平衡树:左右子树高度差不能大于1。B+树就是结合了它们的特点,当然,不一定是二叉树。
为什么要有二叉查找树的特点??因为查找效率快,二分查找在这种结构下,查找效率是很快的。那为什么要有平衡树的特点呢?试想,如果不维护一颗树的平衡性,当插入一些数据后,树的形态有可能变得很极端,比如左子树一个数据没有,而全在右子树上,这种情况下,二分查找和遍历有什么区别呢?而就是因为这些特点需要去维护,所以就有了上面提到的缺点,当索引很多后,反而增加了系统的负担。
接着说B+树。它的结构如下:
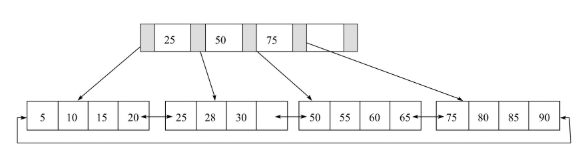
可以发现,叶子节点其实是一个双向循环链表,这种结构的好处就是,在范围查询的时候,我只用找到一个数据,就可以直接返回剩余的数据了。比如找小于30的,只用找到30,其余的直接通过叶子节点间的指针就可以找到。再说说其他特点:数据只存在于叶子节点。当叶子节点满了,如果再添加数据,就会拆分叶子节点,父节点就多了个子节点。如果父节点的位置也满了,就会扩充高度,就是拆分父节点,如25 50 75拆分成:25为左子树,75为右子树,50变成新的头节点,此时B+树的高度变成了3。它们的扩充的规律如下表,Leaf Page是叶子节点,index Page是非叶子节点。

再说说B树,B树相比较B+树,它所有节点都存放数据,所以在查找数据时,B树有可能没到达叶子节点就结束了。再者,B树的叶子节点间不存在指针。
最后说说Hash索引,相较于B+树,Hash索引最大的优点就是查找数据快。但是Hash索引最大的问题就是不支持范围查询。试想,如果查询小于30的数据,hash函数是根据数据的值找到其对应的位置,谁又知道小于30的有哪几个数据。而B+树正好相反,范围查询是它的强项。
附录:Hash到底是啥??哈希中文名散列,哈希只是它的音译。为啥都说Hash快??首先有一块哈希表(散列表),它的数据结构是个数组,一个任意长度的数据通过hash函数都可以变成一个固定长度的数据,叫hash值。然后通过hash值确定在数组中的位置,相同数据的hash值是相同的,所以我们存储一个数据以后,只需O(1)的时间复杂度就可以找到数据。那hash函数又是啥??算术运算或位运算,很多应用里都有hash函数,但实际运算过程大不一样。这是Java里String的hashCode方法:
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
还有一个问题,hash函数计算出来的hash值有可能存在碰撞,即两个不同的数据可能存在相同的hash值,在MySQL或其他的应用中,如Java的HashMap等,如果存在碰撞就会以当前数组位置为头节点,转变成一个链表。
说到这里也清楚了为啥Java中引用类型要同时重写hashCode和equals了。两个对象,实例就算一模一样,它们的hash值也不相等,为啥不相等??默认的Object的hashCode方法会根据对象来计算hash值的,实例相同,但它们还是两个不同的对象啊,所以我们重写hashCode时,最简单的方法就是调用Object的hashCode方法,然后传入该引用类型的属性,让hashCode方法只根据这几个属性来计算,那么实例相同的话,它们的hash值也会相等。等hashCode比较完后,如果相等再比较实例内容,也就是equals,确保不是hash碰撞。
索引的分类
主键索引:如果我们指定了一个主键,那么这个主键就是主键索引。如果我们没有指定,Mysql就会自动找一个非空的唯一索引当主键。如果没有这种字段,Mysql就会创建一个大小为6字节的自增主键。如果有多个非空的唯一索引,那么就让第一个定义为唯一索引的字段当主键,注意,是第一个定义,而不是建表时出现在前面的。
辅助索引:对于辅助索引来说,它们的B+树结构稍微有点特殊,它们的叶子节点存储的是主键,而不是整个数据。所以在大部分情况下,使用辅助索引查找数据,需要二次查找。但并不是所有情况都需要二次查找。比如查找的数据正好就是当前索引字段的值,那么直接返回就行。这里提一句,B+树的key就是对应索引字段的内容。
而辅助索引又有一些分类:唯一索引:不能出现重复的值,也算一种约束。普通索引:可以重复、可以为空,一般就是查询时用到。前缀索引:只适用于字符串类型数据,对字符串前几个字符创建索引。全文索引:作用是检测大文本数据中某个关键字,这也是搜索引擎的一种技术。
聚集索引:注意,聚集索引、非聚集索引和前面几个索引的分类并不是一个层面上的。上面的几个分类是从索引的作用来分析的。聚集、非聚集索引是从索引文件上区分的。主键索引就属于聚集索引,即索引和数据存放在一起,叶子节点存放的就是数据。数据表的.idb文件就是存放该表的索引和数据。
非聚集索引:辅助索引属于非聚集索引,说到这也就明白了。索引和数据不存放在一起的就是非聚集索引。在MYISAM引擎中,数据表的.MYI文件包含了表的索引, 该表的 叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
索引的几点使用经验
适合创建索引的字段:经常被查询的字段;经常作为条件查询的字段;经常用于外键连接或普通的连表查询时进行相等比较字段;不为null的字段;如果是多条件查询,最好创建联合索引,因为联合索引只有一个索引文件。
不适合创建索引的字段:经常被更新的字段、不经常被查询的字段、存在相同功能的字段

