MySQL面试题
MySql项目中使用的存储引擎
5.0之前默认存储引擎为MyISAM引擎
-
索引只有一种,被索引的字段值作为索引数据,叶子节点还包含该记录数据页地址
-
不支持事务
-
没有undo log 和redo log
-
仅支持表🔒
-
不支持外键
-
优势:执行增删改会保存表的总行数

5.0之后默认存储引擎为InnoDB
-
索引支
-
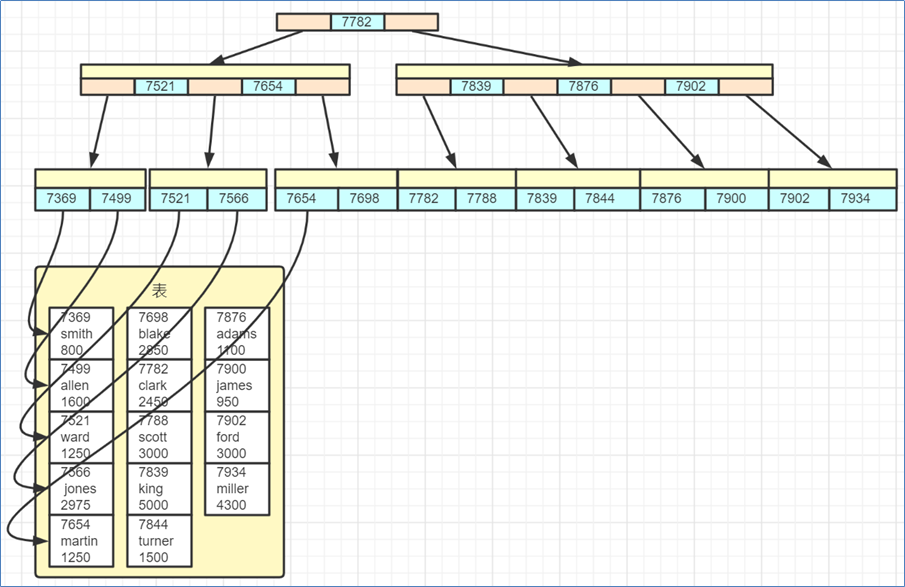
聚簇索引:主键值作为索引数据,叶子节点还包了所有字段数据。!
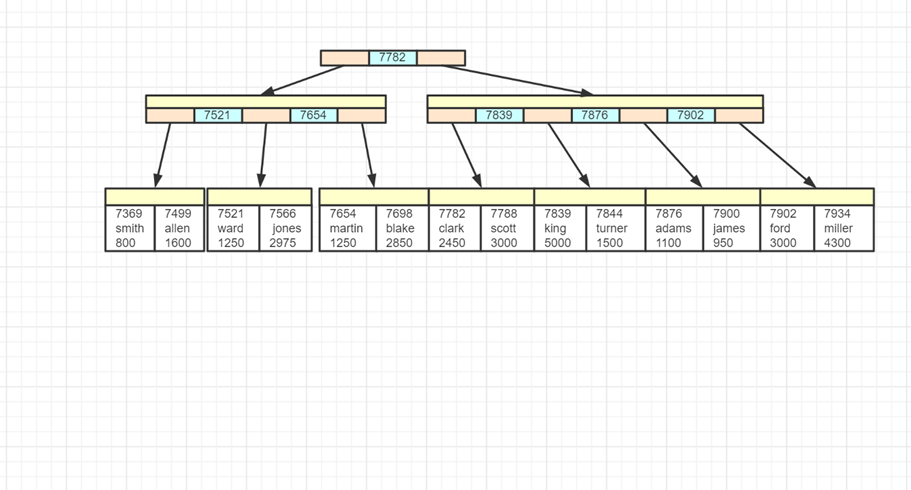
-
非聚簇索引:被索引的字段值作为索引数据,叶子节点还包含了主键值
-


- 如果要查询的数据在非聚簇索引中没有,再通过主键值进行聚簇索引查询

- 事务
- 通过undo log(撤销日志文件)支持事务回滚,当前读(多版本查询)实现原子性
- 通过redo log(重做日志文件)实现持久性
- 通过两阶段提交实现一致性
- 通过当前读,🔒实现隔离性
- 🔒
- 行🔒
- 间隙🔒
- 表级🔒
- 支持外键
数据库的三大范式
第一范式:原子性:保证数据不可再分
第二范式:在满足第一范式下,每张表只描述一件事情,就是主键对应着所有信息
第三范式:满足第一二范式的情况下,保证表中的数据的主键直接相关,而不是间接相关
ACID
A:原子性:在一个事务中,所有操作要么全部完成,要么全部不完成,不可结束在中间某个环节。
C:一致性:事务在开始之前和事务结束以后,数据库的完整性没有被破环。
I:隔离性:数据库允许多个并发数位同时对其数据进行读写和修改能力。
D:持久性:事务处理结束后,对数据的修改就是永久的,即使系统故障也不会丢失,即持久化存在于硬盘中。
事务隔离级别有哪些?MySQL的默认隔离级别是
未提交读
- 脏读:读出的数据无效(可能是其他事务修改后未提交的数据)
- 解决方案:提高隔离级别
提交读RC
- 不可重复读:两次读出的数据不一致(两次操作中间,其他线程执行了修改)
- 解决方案:提供隔离级别
可重复度RR(mysql的默认级别)
- 幻读:读后进行插入操作,可能主键冲突(两次操作汇总,其他线程进行了新增操作)
- 解决方案:加锁避免:for update(间隙🔒),其他线程执行新增时,会被间隙锁阻塞,如何该线程会出现主键冲突。
串行化(影响性能,基本上不用)
- 无错误现象,读写都会阻塞其他事务,可以保证更强的一致性。
B+树与B树的区别,为什么Mysql使用B+树
B树的特点
-
其实本质就是n叉数,分叉多意味着节点的中的孩子(key)多,树的高度就降低了
-
查询时不会出现主键重复,因为每一个key中都会有value!

-
在等值查询中,可能会查到非叶子节点就查到了,完成查询

B+树的特点
-
在B树索引的基础上,索引中仅存放key,这样能进一步增加分叉树,假设key占13字节,那么一页数据分叉树可以到1260,树高可以进一步下降为2
-
可能会存在键的重复,B+树普通节点存放key,叶子节点才存放key+value!

-
在执行等值查询时,都需要查询叶子节点才能查到key和value

使用B+树的原因
数据都是放在了叶子节点,检索的效率比较稳定,非叶子节点最仅存放key,没存放数据,所有非叶子节点能存放key的数量就比较多,树的层级就比较低,所有检索的效率就比较高而稳定。
- mysql索引使用的是B+树,因为索引是用来加快查询的,而B+树通过对数据进行排序,提高了查询效率
- 通过一个节点中可以存储多个元素,从而可以使B+树的高度不会太高
- 在mysql中InnerDB默认为16kb,索引一般情况下一颗两层的B+树可以存2000万左右的数据
- 叶子节点之间有指针,更适合磁盘数据的索引,而MySQL主要针对的就是磁盘数据,且支持等值查询,可以很好的支持全表扫描,范围查询等sql语句。
并发事务带来的问题
- 脏读:读取到了未提交的数据
- 丢失更新:两事务同时对一个字段进行+10,最终结果只进行了+10
- 不可重复读:原来是A的,现在变成B了
- 幻读:原来不存在的,现在存在了
什么字段上不适合建立索引
- 大字段,文本字段,test,blog
- 查询频率比较低的
- 离散度比较低的,如性别
建立了索引的同时也占用了磁盘空间,并且在执行增删改时会产生索引维护
记录价格应该使用什么字段
DECIMAL:Decimal是专门为财务相关问题设计的数据类型,它实际上是以字符串的形式存放的,可在定义时划定整数部分以及小数部分的位数;在对精度要求比较高时(如货币、科学数据),用DECIMAL类型比较好。
如何定位执行效率低的SQL语句
使用慢查询,或者日志查询,这个慢看怎么定义,有对应的变量long_query_time:是指执行超过多久的SQL会被日志记录下来。
找到慢查询SQL后,优化流程是
思路
- 首先检查sql语句是否有问题,如子查询可以改为关联查询
- 有没有用到某个索引?如果没有用,是否需要添加索引?
- 有没有由于什么情况导致索引失效?
列举几个索引失效的场景
- %like,模糊查询like中加了前%
- 在列中进行了函数运算(注意,在值中函数运算不会失效)
- 没有遵循最左前缀原则
- 当两类型需要转换后比较,(本质是列上引用转换函数,导致索引失效)
- 使用 <> 、not in 、not exist、!=
- 字符型字段为数字时在where条件里不添加引号
- 当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况。
聚簇索引和非聚簇索引
- 聚簇索引:主键值作为索引数据,叶子节点还包了所有字段数据。
- 非聚簇索引(二级索引):被索引的字段值作为索引数据,叶子节点还包含了主键值
如果要查询的数据在非聚簇索引中没有,再通过主键值进行聚簇索引查询数据
什么是索引的覆盖 什么是回表
- 索引覆盖:是一种为了避免回表查询的优化策略。索引上的内容也不过是将表上的某些字段以B+树的结构储存起来,如果我们要查询的字段刚好就是索引包括的字段,那就可以在扫描完索引后直接得到结果,不需要回表,这就是覆盖索引
- 回表:先查询非聚簇索引找到主键id,再通过主键查找聚簇索引进而查找到数据,这个过程走了两次索引,就叫回表。
所有在写sql语句时,我们可以尽可能避免select *的出现。
什么是索引条件下推
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。

索引条件下推其实就是将部分服务层(Server层)负责的事情,交给了下层(引擎层)去处理。
在没有使用ICP的情况下,MySQL的查询:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录(回表);
- 存储引擎把记录交给服务层去检测该记录是否满足Where条件。
使用ICP的情况下,查询过程:
- 存储引擎读取索引;
- 判断WHERE条件部分能否用索引中的列来做检查
- 条件不满足,处理下一行记录(丢弃,减少回表次数);
- 条件满足,用索引中的主键去定位并读取完整的行记录(回表);
- 存储引擎把记录交给服务层,服务层检测该记录是否满足WHERE条件的其余部分。
子查询与连接查询哪一个快?为什么?
连接查询较快
- 子查询需要建立临时表去存储子查询查询的数据
- 引用了子查询的条件不能使用索引下推
大批量数据插入时比较慢咋优化?列出两点即可
- 数据库在保存数据时,尽量保证插入时id有序
- 尽量保证批量插入在同一个事务中进行
- 关闭唯一性校验(前提是能保证插入的数据唯一)
MySql的索引原理
索引:随着查询效率被优化,增删改操作效率一定会被影响,哈希索引就是增删改效率最高的。
其实索引的本质就是一种排好序的数据结构。形象的说,可以看作字典中的目录。
索引并不只有B树和B+树
- 哈希索引
- 理想时间复杂度为O(1)
- 适用场景:适用于等值查询的场景,内存数据的索引
- 典型实现:Redis,MySQL的memory引擎
- 平衡二叉树(二叉树中特殊)
- 查询和更新的时间复杂度都是O(log(n))以2为底
- 适用场景:内存数据的索引,当不适合磁盘数据的索引,可以认为树的高度决定了磁盘I/O的次数,百万数据高度约为20
- 树高公式log(1000000)/log(2)
- BTree索引
-
其实就是n叉数,分叉多意味着节点中的孩子(key)多,树的高度就降低了
-
分叉数由页大小和行(key+value)大小决定
- 假设页大小为16k,每行40字节,那么分叉数就为16k/40=410
- 而分叉为410,则按百万数据树高约为3,仅3次I/O就能找到所需数据
- 假设页大小为16k,每行40字节,那么分叉数就为16k/40=410
-
局部性原理:每次I/O按页为单位读取数据,把多个key相邻的行放在同一页中(每页就是树上一个节点,能进一步减少I/O)
-
查询时不会出现主键重复,每一个key中都会有value!

-
遍历时要用中序遍历,会在叶子节点和非叶子节点来回,会降低性能
-
在等值查询时,可能 会查到非叶子节点就查到了,完成查询
-
- B+树索引
-
在BTree索引的基础上,索引中仅存放key,这样能进一步增加分叉数,假设key占13个字节,那么一页数据分叉数可以到1260,树高可以进一步下降为2
-
可能会存在键的重复,B+树普通节点存放key,叶子节点才存放key+value

-
采用链表连接,可以方便范围查询和全表遍历
-
在执行等值查询时,都需要查询叶子节点才能查到key和value
-



