OCR识别扫描版PDF文件(Python版)
概述
扫描版PDF文字识别
Tesseract OCR实现pdf文本识别
tesseract-ocr安装与测试
python实现基于tesseract的pdf文本识别
百度 OCR实现pdf文本识别
准备
python实现基于百度OCR的pdf文本识别
参考
扫描版PDF文字识别
Tesseract OCR实现pdf文本识别
tesseract-ocr安装与测试
python实现基于tesseract的pdf文本识别
百度 OCR实现pdf文本识别
准备
python实现基于百度OCR的pdf文本识别
参考
概述
本文基于OCR识别扫描版PDF文件(不是文字版)。若要处理文字版OCR,百度pdfminer或pdfplumder等使用即可。
依赖:
- 应用程序tesseract-ocr //digi.bib.uni-mannheim.de/tesseract/
- python库pytesseract、pdf2image
基本思路:
- 使用pdf2image.convert_from_path将pdf文件转化为png格式图片;
- 通过pytesseract链接tesseract-ocr,使用pytesseract.image_to_string识别图像中的文字。
扫描版PDF文字识别
Tesseract OCR实现pdf文本识别
tesseract-ocr安装与测试
- tesseract-ocr安装完成后,配置环境变量,即将tesseract的安装路径添加到‘path’系统变量;
- 配置完成后,在cmd窗口输入
tesseract -v会显示配置成功信息。
- 配置完成后,在cmd窗口输入
- 识别简体中文需要下载chi_sim.traindata字库//github.com/tesseract-ocr/tessdata,注意,该字库仅支持Tesseract 4.0.0及更高版本;
- 将下载好的字库放到Tesseract-OCR安装目录下的tessdata文件夹里;
- cmd中进入需要识别图片目录,执行
tesseract *.png result -l eng将图片’*.png’的OCR结果保存至’result.txt’文件夹。-l参数为OCR识别语言,默认英语eng。
- 中文的识别效果不太理想,需要自己训练下。
python实现基于tesseract的pdf文本识别
import pytesseract
from pdf2image import convert_from_path
import os
os.chdir(os.getcwd())
def tess_ocr(fname, lang):
# 将pdf转换为png后,保存在dirname文件夹
dirname = fname.rsplit('.', 1)[0]
if not os.path.exists(dirname):
os.mkdir(dirname)
images = convert_from_path(fname, fmt='png', output_folder=dirname)
text = ''
for img in images:
text += pytesseract.image_to_string(img, lang=lang)
with open('result.txt', 'w', encoding='utf-8') as f:
f.write(text)
return text
fname = 'test.pdf'
text = tess_ocr(fname, lang='chi_sim')
百度 OCR实现pdf文本识别
由于直接使用tesseract识别效果并不理想,尝试百度OCR。
准备
-
安装python库baidu-aip,
pip install baidu-aip; -
在百度智能云创建文本识别应用,获得’APP_ID’ 、’API_KEY’ 和’SECRET_KEY’ 字段;
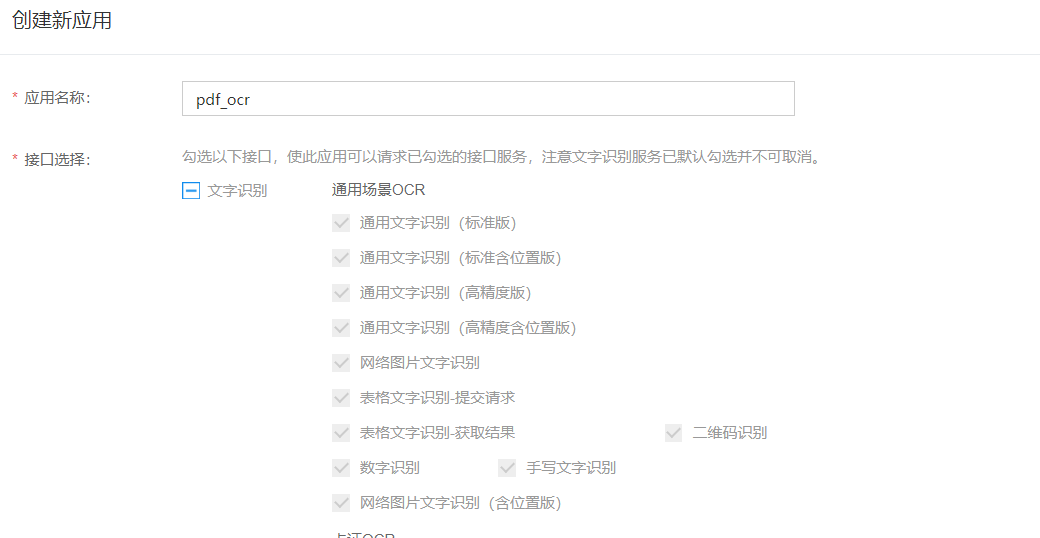

-
标准版文字识别‘5000次/天免费’,一般是足够的。




python实现基于百度OCR的pdf文本识别
from pdf2image import convert_from_path
from aip import AipOcr
import os
APP_ID = '***'
API_KEY = '***'
SECRET_KEY = '***'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def baidu_ocr(fname):
f = open('result.txt', 'w', encoding='utf-8')
dirname = fname.rsplit('.', 1)[0]
if not os.path.exists(dirname):
os.mkdir(dirname)
images = convert_from_path(fname, fmt='png', output_folder=dirname)
for img in images:
with open(img.filename, 'rb') as fimg:
img = fimg.read() # 根据'PIL.PngImagePlugin.PngImageFile'对象的filename属性读取图片为二进制
msg = client.basicGeneral(img)
for i in msg.get('words_result'):
f.write('{}\n'.format(i.get('words')))
f.write('\f\n')
f.close()
baidu_ocr('1.pdf')

