自己動手實現深度學習框架-4 使用交叉熵損失函數支援分類任務
程式碼倉庫: //github.com/brandonlyg/cute-dl
目標
- 增加交叉熵損失函數,使框架能夠支援分類任務的模型。
- 構建一個MLP模型, 在mnist數據集上執行分類任務準確率達到91%。
實現交叉熵損失函數
數學原理
分解交叉熵損失函數
交叉熵損失函數把模型的輸出值當成一個離散隨機變數的分布列。 設模型的輸出為: \(\hat{Y} = f(X)\), 其中\(f(X)\)表示模型。\(\hat{Y}\)是一個m X n矩陣, 如下所示:
\hat{y}_{11} & \hat{y}_{12} & … & \hat{y}_{1n} \\
\hat{y}_{21} & \hat{y}_{22} & … & \hat{y}_{2n} \\
… & … & … & … \\
\hat{y}_{m1} & \hat{y}_{m2} & … & \hat{y}_{mn}
\end{bmatrix}
\]
把這個矩陣的第i行記為\(\hat{y}_i\), 它是一個\(\\R^{1Xn}\)向量, 它的第j個元素記為\(\hat{y}_{ij}\)。
交叉熵損失函數要求\(\hat{y}_i\)具有如下性質:
0<=\hat{y}_{ij}<=1 & & (1)\\
\sum_{j=1}^{n} \hat{y}_{ij} = 1, & n=2,3,… & (2)
\end{matrix}
\]
特別地,當n=1時, 只需要滿足第一條性質即可。我們先考慮n > 1的情況, 這種情況下n=2等價於n=1,在工程上n=1可以看成是對n=2的優化。
模型有時候並不會保證輸出值有這些性質, 這時損失函數要把\(\hat{y}_i\)轉換成一個分布列:\(\hat{p}_i\), 轉換函數的定義如下:
S_i = \sum_{j=1}^{n} e^{\hat{y}_{ij}}\\
\hat{p}_{ij} = \frac{e^{\hat{y}_{ij}}}{S_i}
\end{matrix}
\]
這裡的\(\hat{p}_i\)是可以滿足要求的。函數\(e^{\hat{y}_{ij}}\)是單調增函數,對於任意兩個不同的\(\hat{y}_{ia} < \hat{y}_{ib}\), 都有:\(e^{\hat{y}_{ia}}\) < \(e^{\hat{y}_{ib}}\), 從而得到:\(\hat{p}_{ia} < \hat{p}_{ib}\). 因此這個函數把模型的輸出值變成了概率值,且概率的大小關係和輸出值的大小關係一致。
設數據\(x_i\)的類別標籤為\(y_i\)∈\(\\R^{1Xn}\). 如果\(x_i\)的真實類別為t, \(y_i\)滿足:
y_{ij} = 1 & {如果j=t} \\
y_{ij} = 0 & {如果j≠t}
\end{matrix}
\]
\(y_i\)使用的是one-hot編碼。交叉熵損失函數的定義為:
\]
對於任意的\(y_{ij}\), 損失函數中任意一項具有如下的性質:
-y_{ij}ln(\hat{p}_{ij}) ∈ [0, ∞), & 如果: y_{ij} = 1\\
-y_{ij}ln(\hat{p}_{ij})=0, & 如果: y_{ij} = 0
\end{matrix}
\]
可看出\(y_{ij}=0\)的項對損失函數的值不會產生影響,所以在計算時可以把這樣的項從損失函數中忽略掉。其它\(y_{ij}=1\)的項當\(\hat{p}_{ij}=y_{ij}=1\)時損失函數達到最小值0。
梯度推導
根據鏈式法則, 損失函數的梯度為:
\]
其中:
\]
\]
把(2), (3)代入(1)中得到:
= \frac{1}{m}(y_{ij}\hat{p}_{ij} -y_{ij})
\]
由於當\(y_{ij}=0\)時, 梯度值為0, 所以這種情況可以忽略, 最終得到的梯度為:
\]
如果模型的輸出值是一個隨機變數的分布列, 損失函數就可以省略掉把\(\hat{y}_{ij}\)轉換成\(\hat{p}_{ij}\)的步驟, 這個時候\(\hat{y}_{ij} = \hat{p}_{ij}\), 最終的梯度變成:
\]
交叉熵損失函數的特殊情況: 只有兩個類別
現在來討論當n=1的情況, 這個時候\(\hat{y}_i\) ∈ \(\\R^{1 X 1}\),可以當成標量看待。
如果模型輸出的不是分布列, 損失函數可以分解為:
\hat{p}_{i} = \frac{1}{1+e^{-\hat{y}_{i}}} \\
\\
J_i = \frac{1}{m}[-y_iln(\hat{p}_{i}) – (1-y_i)ln(1-\hat{p}_{i})]
\end{matrix}
\]
損失函數關於輸出值的梯度為:
\]
\]
\]
把(1),(2)代入(3)中得到:
\]
如果模型輸出值時一個隨機變數的分布列, 則有:
\]
實現程式碼
這個兩種交叉熵損失函數的實現程式碼在cutedl/losses.py中。一般的交叉熵損失函數類名為CategoricalCrossentropy, 其主要實現程式碼如下:
'''
輸入形狀為(m, n)
'''
def __call__(self, y_true, y_pred):
m = y_true.shape[0]
#pdb.set_trace()
if not self.__form_logists:
#計算誤差
loss = (-y_true*np.log(y_pred)).sum(axis=0)/m
#計算梯度
self.__grad = -y_true/(m*y_pred)
return loss.sum()
m = y_true.shape[0]
#轉換成概率分布
y_prob = dlmath.prob_distribution(y_pred)
#pdb.set_trace()
#計算誤差
loss = (-y_true*np.log(y_prob)).sum(axis=0)/m
#計算梯度
self.__grad = (y_prob - y_true)/m
return loss.sum()
其中prob_distribution函數把模型輸出轉換成分布列, 實現方法如下:
def prob_distribution(x):
expval = np.exp(x)
sum = expval.sum(axis=1).reshape(-1,1) + 1e-8
prob_d = expval/sum
return prob_d
二元分類交叉熵損失函數類名為BinaryCrossentropy, 其主要實現程式碼如下:
'''
輸入形狀為(m, 1)
'''
def __call__(self, y_true, y_pred):
#pdb.set_trace()
m = y_true.shape[0]
if not self.__form_logists:
#計算誤差
loss = (-y_true*np.log(y_pred)-(1-y_true)*np.log(1-y_pred))/m
#計算梯度
self.__grad = (y_pred - y_true)/(m*y_pred*(1-y_pred))
return loss.sum()
#轉換成概率
y_prob = dlmath.sigmoid(y_pred)
#計算誤差
loss = (-y_true*np.log(y_prob) - (1-y_true)*np.log(1-y_prob))/m
#計算梯度
self.__grad = (y_prob - y_true)/m
return loss.sum()
在MNIST數據集上驗證
現在使用MNIST分類任務驗證交叉熵損失函數。程式碼位於examples/mlp/mnist-recognize.py文件中. 運行這個程式碼前先把原始的MNIST數據集下載到examples/datasets/下並解壓. 數據集下載鏈接為://pan.baidu.com/s/1CmYYLyLJ87M8wH2iQWrrFA,密碼: 1rgr
訓練模型的程式碼如下:
'''
訓練模型
'''
def fit():
inshape = ds_train.data.shape[1]
model = Model([
nn.Dense(10, inshape=inshape, activation='relu')
])
model.assemble()
sess = Session(model,
loss=losses.CategoricalCrossentropy(),
optimizer=optimizers.Fixed(0.001)
)
stop_fit = session.condition_callback(lambda :sess.stop_fit(), 'val_loss', 10)
#pdb.set_trace()
history = sess.fit(ds_train, 20000, val_epochs=5, val_data=ds_test,
listeners=[
stop_fit,
session.FitListener('val_end', callback=accuracy)
]
)
fit_report(history, report_path+"0.png")
擬合報告:
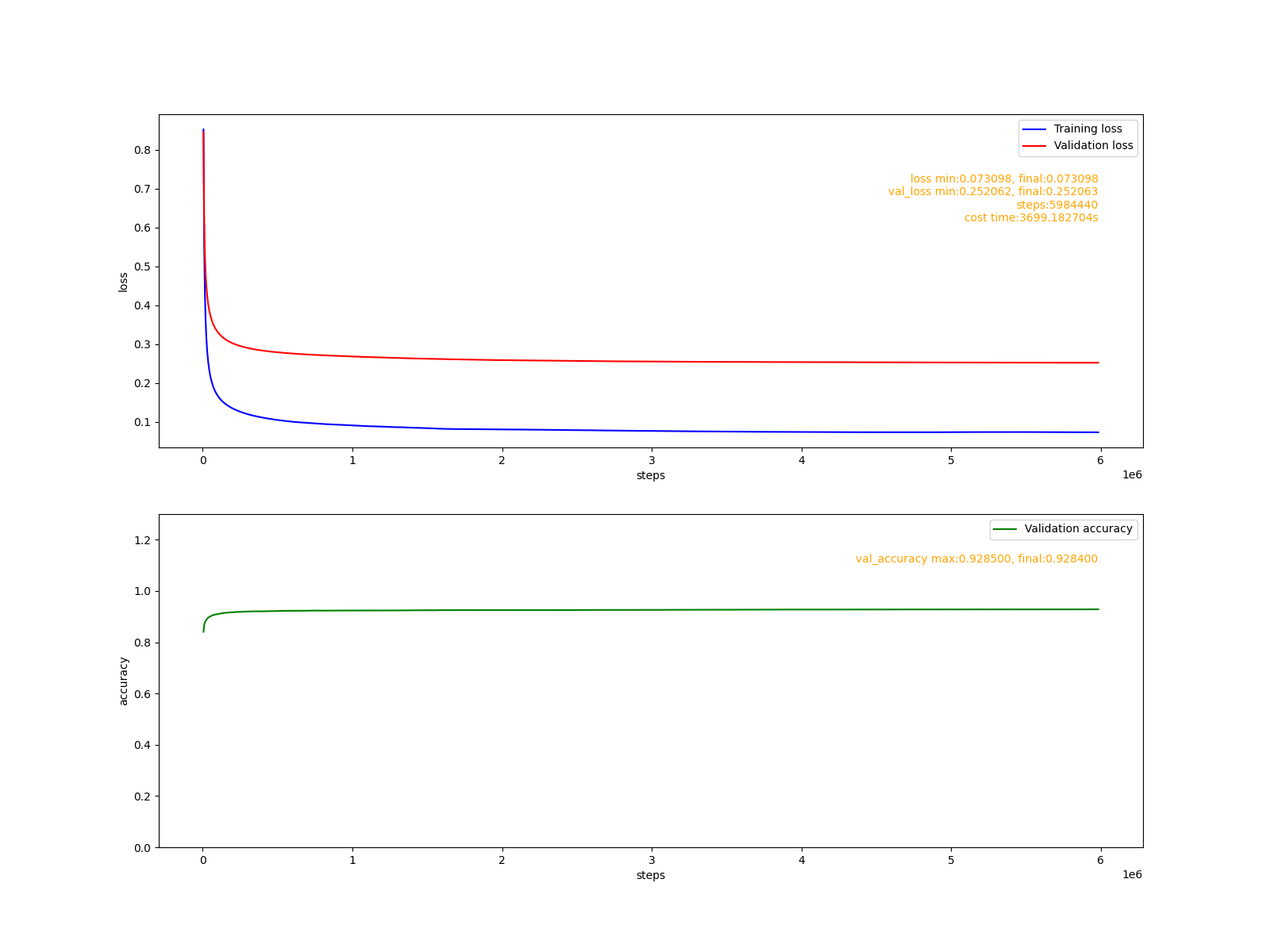
可以看出,通過一個小時(3699s), 將近600萬步的訓練,模型準確率達到了92%。同樣的模型在tensorflow(CPU版)中經過十幾分鐘的訓練即可達到91%。這說明, cute-dl框架在任務性能上是沒問題的,但訓練模型的速度欠佳。
總結
這個階段框架實現了對分類任務的支援, 在MNIST數據集上驗證模型性能達到預期。模型訓練的速度並不令人滿意。
下個階段,將會給模型添加學習率優化器, 在不損失泛化能力的同時加快模型訓練速度。