零基礎爬取堆糖網圖片(一)
- 2020 年 4 月 6 日
- 筆記
零基礎爬取堆糖網圖片(一)
全文介紹:
首先堆糖網是一個美圖壁紙興趣社區,有大量的美女圖片
今天我們實現搜索關鍵字爬取堆糖網上相關的美圖。
當然我們還可以實現多執行緒爬蟲,加快爬蟲爬取速度

涉及內容:
- 爬蟲基本流程
- requests庫基本使用
- urllib.parse模組
- json包
- jsonpath庫
圖例說明:
- 請求與響應
sequenceDiagram 瀏覽器->>伺服器: 請求 伺服器–>>瀏覽器: 響應
- 爬蟲基本流程
graph TD A[目標網站] –>|分析網站| B(url) B –> C[模擬瀏覽器請求資源] C –>D[解析網頁] D–>E[保存數據]
正文:
1. 分析網站
1.1 目標網址:https://www.duitang.com/
1.2 關鍵字:

值得注意的是url當中是不能有漢字的,所以真正的url是這樣的:
https://www.duitang.com/search/?kw=美女&type=feed
思路:
import urllib.parse label = '美女' label = urllib.parse.quote(label) # 輸出:%E7%BE%8E%E5%A5%B3 1.3 數據源:
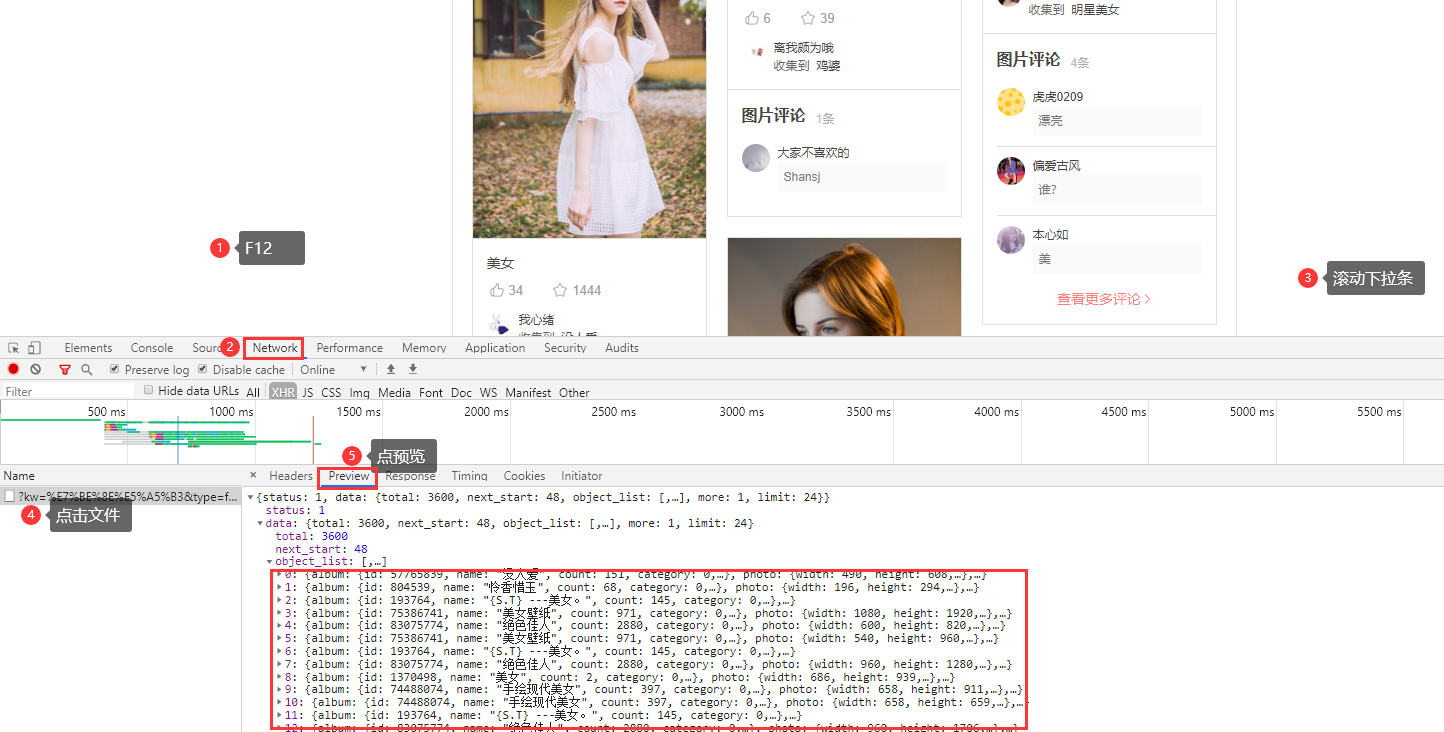
首先,這個網站的數據是瀑布流式的載入方式。
瀑布流舉例說明:你去一個飯店,直接開口要十碗燴面,這個時候老闆開始下面給你吃?。然後你發現當你吃完第一碗面,你就吃不下了。這個時候,剩下的面就算白做了。所以,下次你在去飯店,還是直接開口要十碗面,這時,老闆聰明了,下一碗面,你吃一碗,你還需要,就在去下面。這樣就不會浪費。
針對這種數據載入,需要抓包:
2. 導庫
import urllib.parse import json import requests import jsonpath 3. 模擬瀏覽器請求資源
we_data = requests.get(url).text 4. 解析網頁
因為是json文件,所以直接用jsonpath工具提取數據
# 類型轉換 html = json.loads(we_data) photo = jsonpath.jsonpath(html,"$..path") print(photo) 得到圖片的鏈接
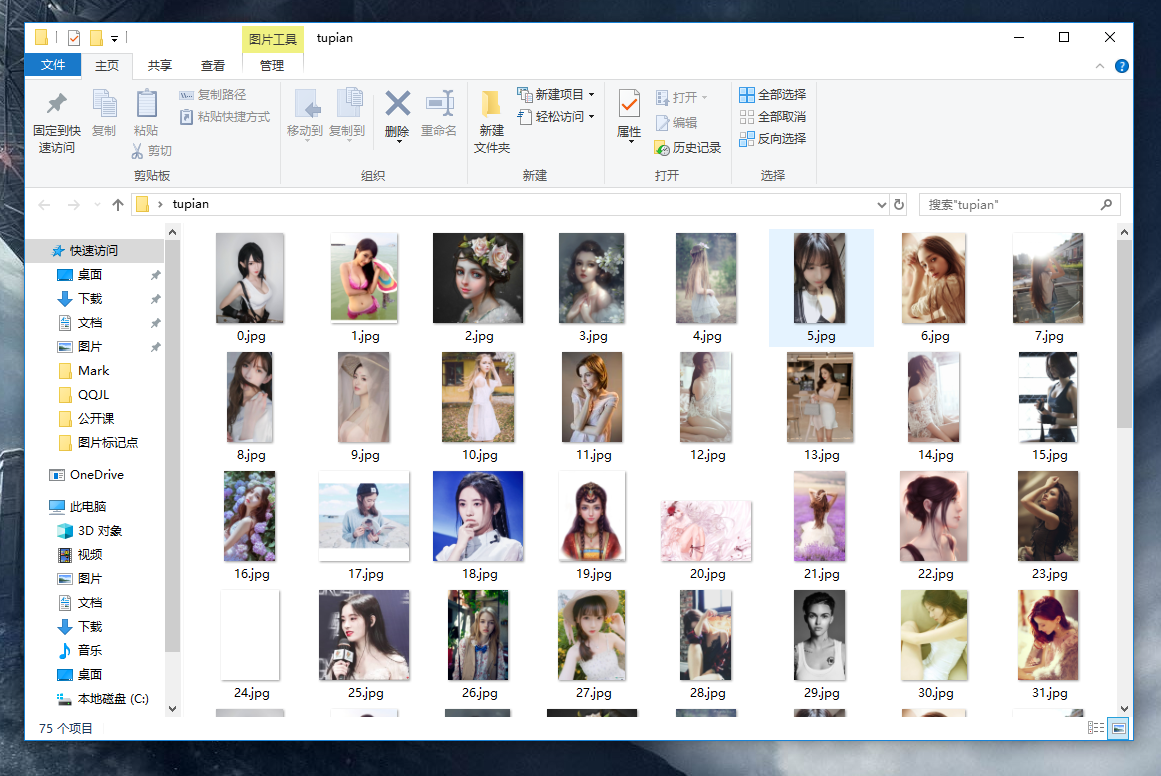
5. 保存數據
num = 0 for i in photo: a = requests.get(i) with open(r'tupian{}.jpg'.format(num),'wb') as f: # content 二進位流 f.write(a.content) num += 1 效果:


完整程式碼:
所以,以此為動力,又實現了翻頁,下面是簡單的全部程式碼(程式碼為了零基礎小白看懂,大神勿噴)
import urllib.parse import json import requests import jsonpath url = 'https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}' label = '美女' # 關鍵字 label = urllib.parse.quote(label) num = 0 # 翻頁 24的間隔 for index in range(0,2400,24): u = url.format(label,index) we_data = requests.get(u).text html = json.loads(we_data) photo = jsonpath.jsonpath(html,"$..path") # 遍歷每頁的圖片鏈接 for i in photo: a = requests.get(i) # wb 二進位寫入 with open(r'tupian{}.jpg'.format(num),'wb') as f: # content 二進位流 f.write(a.content) num +=1 PS:
問題可以評論區提出



