【NLP】一文完全搞懂序列標註演算法
- 2020 年 3 月 13 日
- 筆記
序列標註模型用到了長短期記憶網路(LSTM),條件隨機場(CRF),Highway網路,本文循序漸進的介紹了序列標註演算法,Be patience ! 跟著小編的文章完全搞懂序列標註演算法吧。
1.目標
序列標註模型的目標是用實體或詞性標記句子的每個單詞,如下圖:

其中PER標記的是人名,LOC標記的是位置,ORG標記的是組織。
演算法原理來自論文Empower Sequence Labeling with Task-Aware Neural Language Model,論文所述的序列標註模型演算法比大部分演算法都要高級,文章將要介紹很多常用的理論,不僅僅應用在序列標註領域,該模型的一個特點是並行訓練了語言模型,增強了序列標註的任務。
為了更好的理解序列標註模型,首先介紹幾個概念:
2.需要理解的幾個概念
- 序列標註:標註句子中每個單詞的實體或詞性
- 語言模型:語言模型是預測單詞或字元序列中的下一個單詞或字元,神經語言模型在文本生成、機器翻譯、影像理解、光學字元識別等各種NLP任務中取得了令人印象深刻的結果。
- 字元RNN:對文本中的單個字元進行RNN轉換,在序列標註任務中,字元可以為單詞的實體或屬性提供重要線索,如形容詞通常以」-y」或」-ul」結尾,位置通常以」-land」或」burg」結尾,因此編碼句子中的字元資訊是很有必要的。
- 多任務學習(Multi-Task Learning):模型訓練過程中包含了語言模型,語言模型為序列標註模型提供了額外的有用資訊,即改善了序列標註模型。
- 條件隨機場(Conditional Random Fields):離散分類器根據某個單詞預測其標註,條件隨機場是根據該單詞附近的單詞標註來預測其標註,這是符合理論的,因為單詞的標註不僅僅取決於當前的單詞,還取決於該單詞相鄰的單詞屬性。
- 維特比解碼(Viterbi Decoding):我們使用了CRF輸出每個單詞的標記轉移矩陣,然後通過維特比解碼輸出最優的標記序列。
- Highway Networks(Highway網路):全連接層在任何神經網路結構中轉換或提取不同位置特徵的主要成分,如影像分類中,全連接層輸出用於分類影像的特徵,語言模型中,全連接層輸出每一個類的概率。
3.演算法模型框架
演算法模型框架即LM-LSTM-CRF,LM-LSTM-CRF包含了三個模型:語言模型(LM),長短期記憶網路(LSTM),條件隨機場(CRF)。語言模型的訓練並行在長短期記憶網路和條件隨機場組成的序列標記模型,組成多任務訓練模型。
模型框架如下圖:

上圖右邊的紅色方框所展示的是序列標註模型的框架流程,下圖細化了該模型流程,讓大家有個宏觀的理解:


下面一一介紹該模型框架的結構部分:
3.1 多任務學習(Multi -Task Learning)
由上表可知,在訓練序列標註模型的同時也並行了語言模型訓練,這樣做的好處是使訓練過程中獲得了更多的資訊,提高了序列標註模型的性能。
多任務學習的損失函數是各個任務損失函數的權值相加,如下式:

本文設置

等於1。
梯度下降法更新模型參數:

其中

為學習率。
3.2 字元LSTM
前向字元LSTM和後向字元LSTM都用於語言模型的單詞預測,也用於序列標註模型的輸入。
假設句子是dunston checks in <end>,前向字元LSTM的結構如下圖:

後向字元LSTM結構圖:

3.3 單詞雙向LSTM和條件隨機場
單詞雙向LSTM和條件隨機場用來預測序列標註模型每個單詞的觀測分數矩陣和轉移分數矩陣之和。如下圖:

若句子長度為L,單詞標註種類數為m,那麼每個單詞標註轉移分數矩陣的大小為(L,m,m),觀測分數矩陣的大小為(L,m)。
條件隨機場輸出這兩者之和的總分數,矩陣大小為(L,m,m),位置(k,i,j)的值等於
第k個單詞第j個標記的觀測分數與第k個單詞前一個單詞標註為i,後一個單詞標註為j的觀測分數之和。
比如句子dunston checks in <end>,如果標註種類數為5,總分數矩陣會是這樣:

細心的讀者可能發現,條件隨機場不輸出符號<start>的總分數,因為每個句子都是以<start>開頭,計算<start>的觀測分數和轉移分數沒有任何意義。
從上圖也得到了兩個小細節:
- 給定前一個單詞的標註為<start>,某個標註的轉移分數表示該標註成為句子中第一個標註的可能性,比如句子通常以冠詞(a,an,the)或名詞,代詞開頭。
- 給定後一個單詞的標註為<end>,某個標註的轉移分數表示該標註成為句子中最後一個標註的可能性。
我們現在知道了模型輸出的矩陣總分數,如何計算當前模型的損失函數?
4.維特比損失(Viterbi loss)
若僅僅只有標註觀測分數,那麼小編推薦使用交叉熵損失函數去計算,若包含了轉移矩陣分數,則用維特比損失演算法。
還是用之前的總分數為例,如下圖:
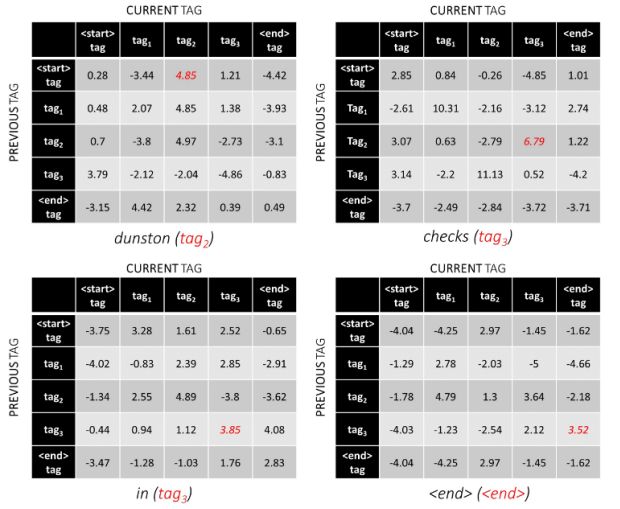
定義序列標註t的得分等於每個標註得分的總和,有:

若句子的真實標註為:tag2,tag3,tag3,<end>,則該序列標註的得分等於:4.85 + 6.79 + 3.85 +3.52 = 19.01。
因此,維特比損失定義為:

其中

表示真實的標註序列,T表示所有可能的標註序列。
簡化上式得:

若經過多次迭代的回饋訓練,得到單詞最終的預測總分數,如何預測句子中最優的標註序列?
5.維特比解碼(Viterbi Decoding
不管是什麼句子,有兩個標註我們是確定的:<start>和<end>標記,維特比預測最優標註序列的思想是:通過<start>去逐步累加每個單詞的總分數,當更新到<end>標註時,由於<end>標註是確定的,然後通過<end>標註的總分數反向預測每個單詞的最優序列。
通過一個來闡述這一思想,還是用之前每個單詞的總分數為例:
第一個單詞為dunston,前一個標註肯定為<start>,於是第一個單詞的累加分數為:

第二個單詞為checks,則第二個單詞的累加分數為:

存儲該單詞所屬每個標註的最大分數和前一個標註:

第三個單詞為in,則第三個單詞的累加分數為:

存儲該單詞所屬每個標註的最大分數和前一個標註:

第四個單詞為<end>符號,則第四個單詞的累加分數為:

存儲該單詞所屬每個標註的最大分數和前一個標註:

因為第四個單詞為標註肯定為<end>,因此選擇該標註最大分數時的前一個標註,由上圖可知為tag3,然後重複該步驟,如下圖:

由上圖可知,最優標註序列為:<start>,<tag2>,<tag2>,<tag3>。
5.Highway Networks
語言模型和序列標註模型都用到了highway網路,該網路與偏差網路有點相似,偏差網路(residual networks)的輸出等於將輸入添加到轉換後的輸出,為數據流的轉換創建路徑。
偏差網路結構圖:

若轉換層個數等於1,轉換函數為f(x),則有:

Highway網路與偏差網路有點相似,它使用sigmoid-activated門來確定輸入和轉換後輸出的係數,因此Highway網路的輸出為:

模型有三個地方要用到Highway網路:
- Highway網路將前向字元LSTN的輸出預測為下一個單詞的分數
- Highway網路將後向字元LSTN的輸出預測為下一個單詞的分數
- 前向字元LSTM和後向字元LSTM的輸出拼接起來,然後用Highway網路轉換,並與單詞的嵌入向量作為單詞雙向LSTM的輸入。
結合字元前向LSTM,字元後向LSTM,雙向單詞LSTM以及條件隨機場的介紹,序列標註演算法模型結構圖如下:

6.其他的序列標註模型簡述

圖(a)與本文介紹的模型很相似,但是該模型是單任務學習,即不包含語言模型。
圖(b)是單任務學習,且沒有利用句子的字元資訊,該模型在工業界十分普及且性能較好。
圖(c)是單任務學習,使用了線性層或Highway層代替條件隨機場,即直接預測每個單詞所屬標記的分數,性能相比之前的模型較差。
參考
https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Sequence-Labeling