RNN學習筆記(一):長短時記憶網路(LSTM)
- 2020 年 3 月 9 日
- 筆記
一、前言
在影像處理領域,卷積神經網路(Convolution Nerual Network,CNN)憑藉其強大的性能取得了廣泛的應用。作為一種前饋網路,CNN中各輸入之間是相互獨立的,每層神經元的訊號只能向下一層傳播,同一卷積層對不同通道資訊的提取是獨立的。因此,CNN擅長於提取影像中包含的空間特徵,但卻不能夠有效處理時間序列數據(語音、文本等)。
時序數據往往包含以下特性:
- 輸入的序列數據長度是不固定(如機器翻譯,句子長度不固定)
- 不同時刻的數據存在相互影響(如前一時刻的事實會影響後續時刻的推斷)

拿到一個小球,我們並不知道它下一步會往哪一個方向運動,到當我們獲取了小球前幾個時刻的位置,我們就能推斷出小球下一步的運動方向。前一時刻的資訊影響了後續時刻的推測,不同時刻下小球的位置資訊就是時間序列數據的一種。
二、循環神經網路
與前饋網路不同,循環神經網路(Recurrent Nerual Network,RNN)在隱藏層中帶有自回饋的神經元對前面的資訊進行記憶並應用於當前輸出的計算中,即神經元在接收當前數據輸入的同時,也接收了上一個隱藏層的輸出結果,一直循環直到所有數據全部輸入。RNN能夠利用歷史資訊來輔助當前的決策,它也可以根據任務的不同,靈活地改變輸出的個數。
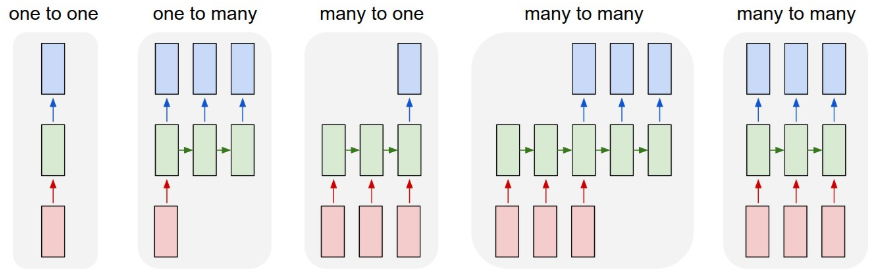
- one to one:一個輸入對應一個輸出;
- one to many:一個輸入對應許多輸出,比如影像理解,輸入一張影像,讓機器試著描述影像內容;
- many to one:語句情感分析,輸入句子,對語句中所包含的情感進行分類;
- many to many:機器翻譯。
在RNN中,隱藏層狀態(Hidden State)通俗的理解就是隱藏層神經元將輸入計算後的輸出值,這一輸出值不僅是當前時刻神經元的輸出,也是後一時刻神經元的輸入。
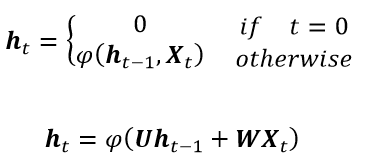
其中,ht 為t時刻的隱藏層狀態,Xt 為時間序列數據,φ為激活函數(如雙曲正切函數、sigmoid函數等),U和W分別為在前一個時刻隱藏層和在當前時刻輸入的係數矩陣。
整個RNN的計算圖如下圖所示:
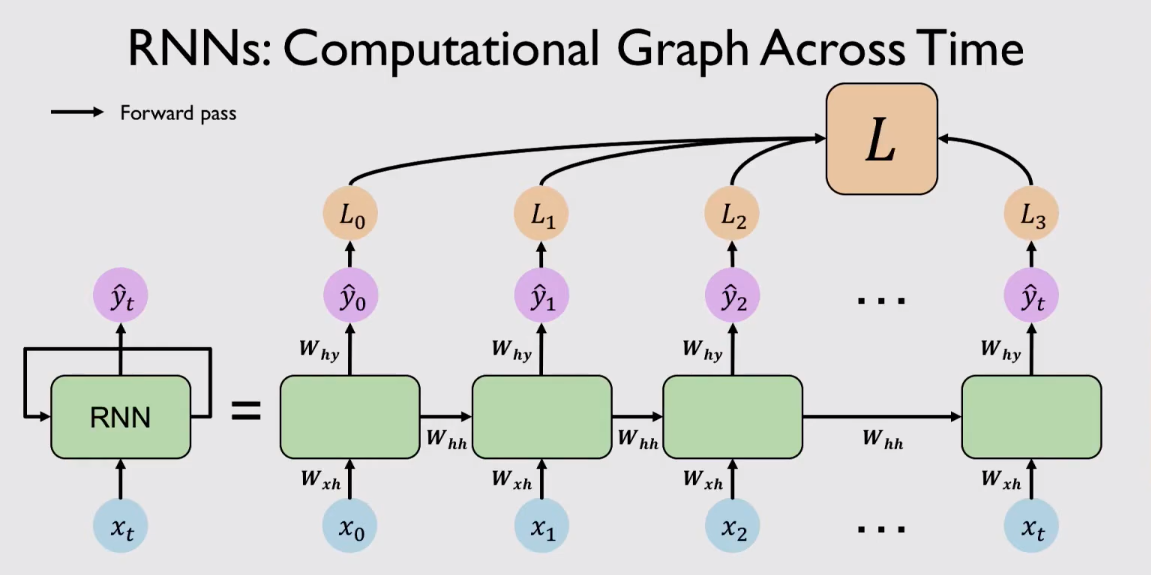
參數共享和循環回饋的設計機制,使得 RNN 模型理論上能夠處理任意長度的時間序列,因此RNN非常適用於時間序列數據的分析應用中。理論上,RNN可以無限拓展他的隱藏層,去學習更長序列數據。但是過多的層數不僅會使模型訓練速度變慢,而且也會帶來“梯度消失”或“梯度爆炸”的問題,造成 RNN 無法獲取長時間依賴資訊,從而喪失了利用長距離歷史資訊的能力。
三、長期依賴(Long-Term Dependencies)的問題
對於間隔較長的時間序列數據,在實際應用中RNN往往在學習長距離歷史資訊表現欠佳。
以下面這個例子來說,“The clouds are in the ”最後我們要模型去輸出這個詞,歷史資訊告訴模型前面出現了“clouds”,那麼模型就可以根據歷史資訊來推斷出要輸出“sky”。因為這裡的相關資訊和預測詞的位置之間只有非常小的間隔,如下圖所示:

但是在現實應用不僅僅有這種簡單的預測任務,還存在大量複雜的時間序列數據,這些數據需要模型去記憶更早的歷史資訊去完成推斷。比如“I grew up in France,…and I speak fluent ”,要去推測這個詞,模型需要記憶“France”這一歷史資訊,但它與輸出位置間隔太遠,由於“梯度消失”的問題,這麼遠的歷史資訊很難被有效傳遞。
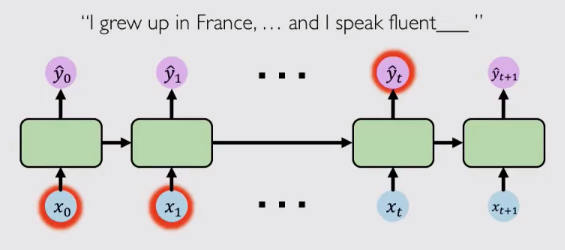
因此,隨著間隔的增大,傳統RNN在面對這樣時間序列數據的建模效果往往差強人意。目前,存在一定方法能夠緩解“梯度消失”來解決長期依賴問題,如
- 用RELU函數替換sigmoid函數作為激活函數
- 權重初始化(權重係數矩陣初始化為單位矩陣,偏置係數矩陣初始化為0)
- 使用帶有門控(gate)的更複雜循環單元去記錄長期歷史資訊(如LSTM,GRU等)
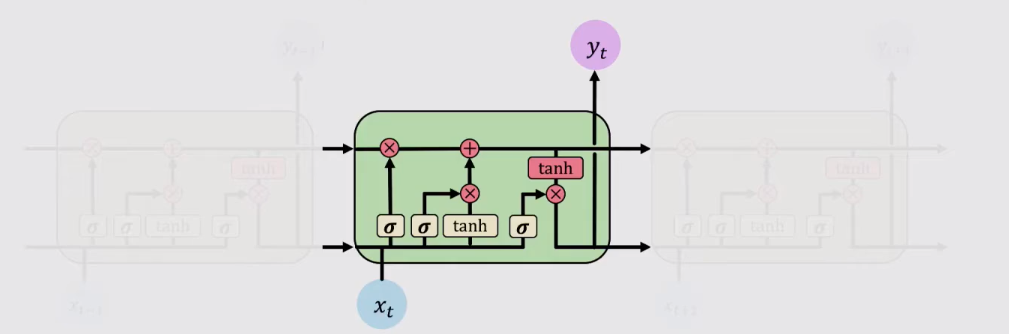
四、長短時記憶網路(Long Short-Term Memory Network)
LSTM就是為了解決間隔較遠的歷史資訊無法有效傳遞這一問題,它是利用門控單元(Gated Cell)來控制長期歷史資訊的傳遞過程。
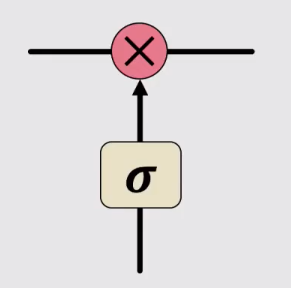
門控(Gate)這一概念是指控制循環單元內資訊的增加或刪除的一種結構,它選擇性地讓資訊通過,例如下圖,一個簡單的sigmoid函數加哈達瑪積即可實現這樣一個控制資訊傳遞的過程,sigmoid輸出為0表示完全捨棄,輸出為1表示完全通過。
LSTM就是靠著sigmoid函數來控制資訊的傳遞過程,LSTM循環單元中一般包含三個門控單元,即遺忘門、輸入門和輸出門。
不同於傳統RNN,LSTM在每個循環單元中添加了單元狀態(Cell State)來選擇性地記憶過去傳遞的資訊。一個循環單元不僅要接收上一次時間步驟傳遞出的Hidden State,也要接收傳遞出的Cell State。通俗的理解,Hidden State是到目前為止我們所看到的總體資訊,而Cell State是歷史資訊的選擇性記憶。
LSTM的工作方式可以抽象地分為以下四步:
- 遺忘(Forget)
- 存儲(Store)
- 更新(Update)
- 輸出(Output)
1、遺忘(Forget)
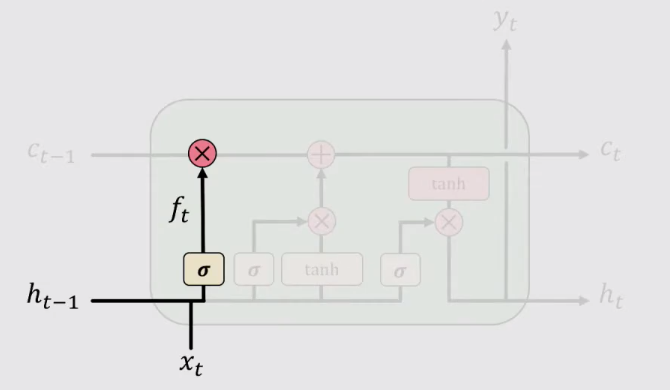
接收上一時間步驟的Hidden State ht-1 和當前輸入數據Xt,將他們計算後的值通過sigmoid激活函數,計算遺忘門的資訊,來確定需要遺忘的資訊。

2、存儲(Store)
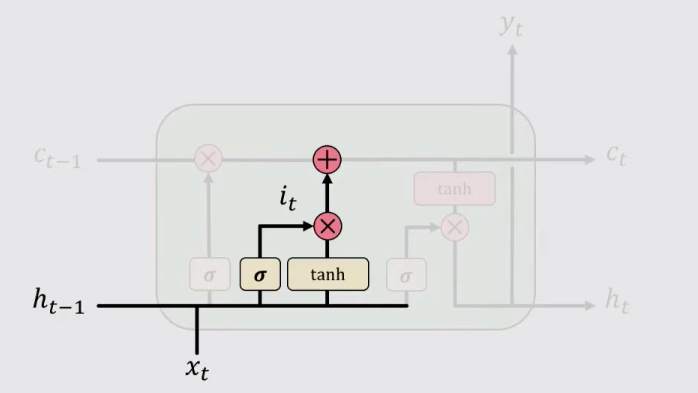
計算輸入門的值 it 並將其與整體資訊 St 計算哈達瑪積。在這一步,之所以要在輸入門的值再與整體資訊 St 計算哈達瑪積的原因是,門控結構(Gate)輸出的介於0-1之間的數字,相當於影像的掩膜(mask),與整體資訊結合在一起才能確定輸入的資訊。


3、更新(Update)
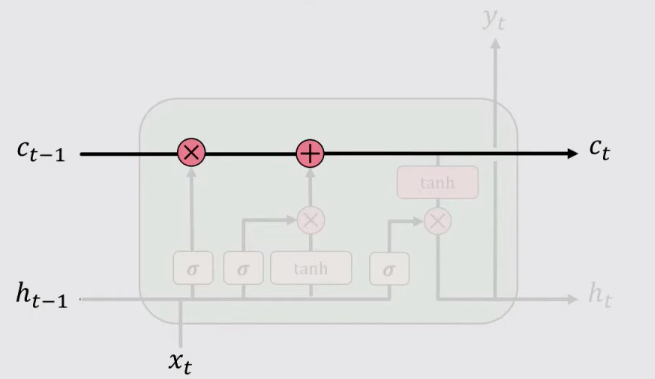
單元狀態(Cell State)表示的是到t時刻,循環單元選擇性記憶的資訊。對它進行更新就需要遺忘 t-1時刻的單元狀態Ct-1,並加上當前時刻輸入資訊,這樣更新Cell State。
![]()
4、輸出(output)
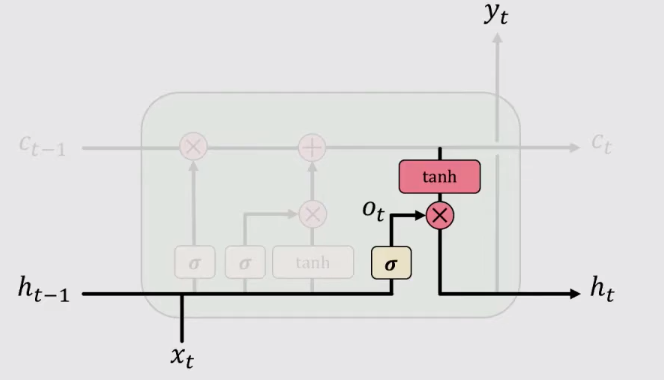
到了輸出這一步,循環單元計算輸出門的值,並將當前時刻下已經選擇性記憶的資訊 Ct 拿出來做“掩膜”,來得到輸出的Hidden State Ht

四、小結
學習LSTM的關鍵在於理解單元狀態(Cell State)的意義。傳統RNN中的Hidden state保留的是到當前時刻為止所積攢的所有資訊,而Cell State保留的是經歷過遺忘和輸入的資訊。LSTM有效地解決了 RNN 模型訓練時出現的梯度“爆炸”和梯度“消失”問題在很多應用中都取得了不錯的效果。
參考資料
https://www.quora.com/How-is-the-hidden-state-h-different-from-the-memory-c-in-an-LSTM-cell
MIT.Introduction to Deep Learning:Deep Sequence Modeling,2020


