精準用戶畫像!商城用戶分群2.0!⛵
- 2022 年 11 月 20 日
- 筆記
- 業務數據分析, 數據分析, 數據分析 ⛵ 面試寶典&實戰項目, 數據可視化, 數據挖掘, 機器學習, 機器學習實戰通關指南 ⛵ 全場景覆蓋AI解決方案, 特徵工程, 聚類

💡 作者:韓信子@ShowMeAI
📘 數據分析實戰系列://www.showmeai.tech/tutorials/40
📘 機器學習實戰系列://www.showmeai.tech/tutorials/41
📘 本文地址://www.showmeai.tech/article-detail/334
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容

很多公司的技術人員在做用戶畫像的工作,細分客戶/客戶分群是一個很有意義的工作,可以確保企業構建更個性化的消費者針對策略,同時優化產品和服務。
在機器學習的角度看,客戶分群通常會採用無監督學習的演算法完成。應用這些方法,我們會先收集整理客戶的基本資訊,例如地區、性別、年齡、偏好等,再對其進行分群。

在之前的文章 📘基於機器學習的用戶價值數據挖掘與客戶分群中,ShowMeAI 已經做了一些用戶分群實操介紹,本篇內容中,ShowMeAI 將更深入地介紹聚類分群的方法,使用更豐富的建模方式,並剖析模型評估的方法模式。

💡 數據載入 & 基本處理
我們先使用 pandas 載入 🏆Mall_Customers數據,並做了一些最基本的數據清洗,把欄位名稱更改為清晰可理解的字元串格式。
🏆 實戰數據集下載(百度網盤):公眾號『ShowMeAI研究中心』回復『實戰』,或者點擊 這裡 獲取本文 [27]基於多種聚類演算法的商城用戶分群!繪製精準用戶畫像 『Mall_Customers數據集』
⭐ ShowMeAI官方GitHub://github.com/ShowMeAI-Hub
df= pd.read csv( "Mall Customers.csv")
df.rename (columns={"CustomerID": "id", "Age": "age", "Annual Income (k$)": "annual_income", "Spending Score (1-100)": "spending_score"}, inplace=True)
df.drop(columns=["id"], inplace=True)
💡 探索性數據分析

本文數據操作處理與分析涉及的工具和技能,歡迎大家查閱 ShowMeAI 對應的教程和工具速查表,快學快用。
下面我們對數據做一些探索性數據分析,首先我們的特徵欄位可以分為數值型和類別型兩種類型。後面我們單獨對兩類特徵欄位進行分析。
numcol = ["age", "annual_income", "spending_score"]
objcol = ['Gender']
💦 單變數分析
① 類別型特徵
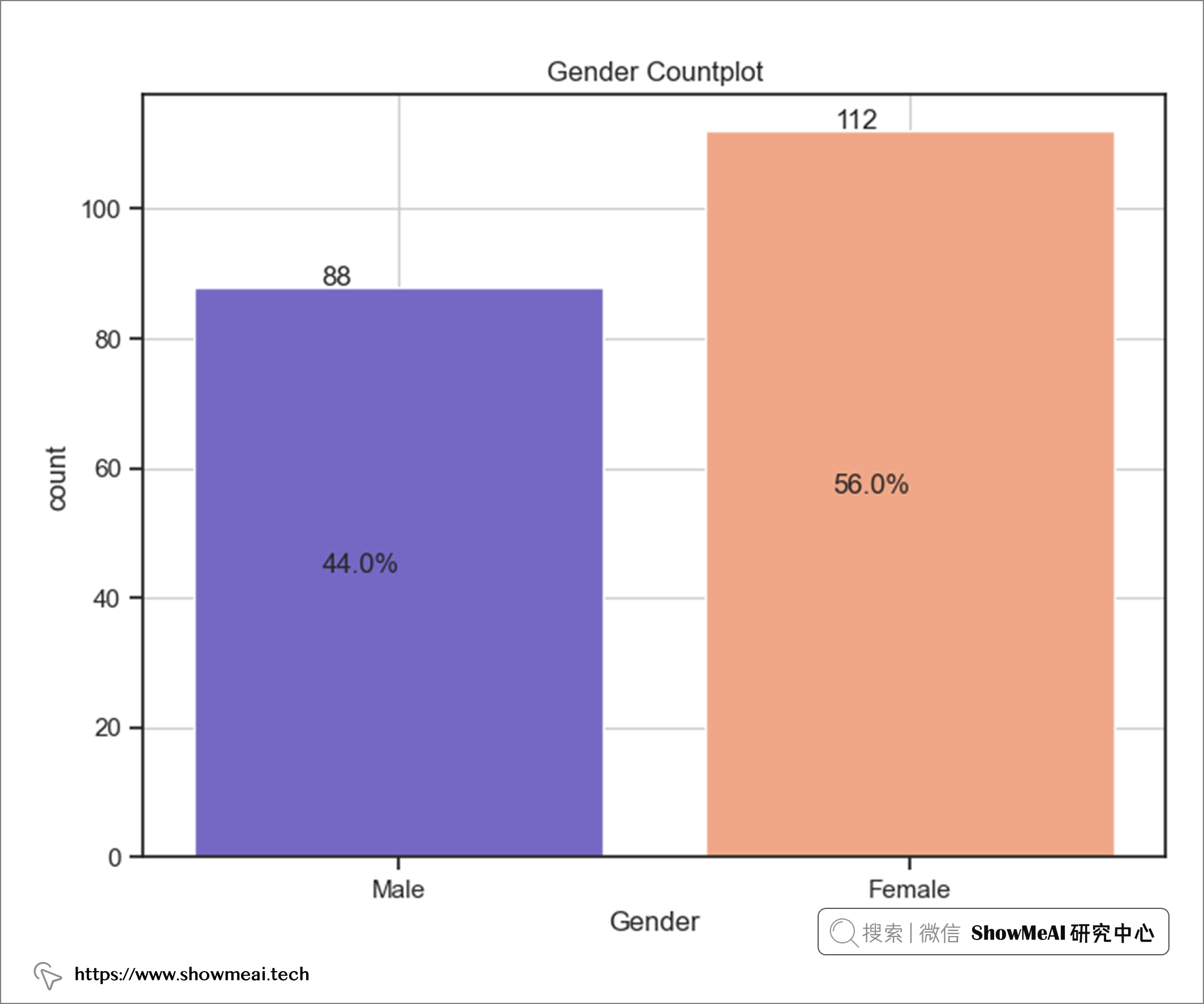
我們對性別(女性和男性)做計數統計和繪圖,程式碼如下:
sns.set_style("ticks")
my_pal = {"Male": "slateblue", "Female": "lightsalmon"}
ax = sns.countplot(data=df, x="Gender", palette=-my_pal)
ax.grid(True, axis='both' )
for p in ax.patches:
ax.annotate( '{:.Of}'. format(p.get _height()), (p.get _x()+0.25, p.get_height()+0.3))
percentage = "{:.If}%'. format(100 * p.get height )/lendf[ "Gender" ]))
ax.annotate(percentage, (p.get x()+0.25, p.get height ( )/2))
olt.title( "Gender Countolot")
② 數值特徵
後續的用戶分群會使用到聚類演算法,為了確保聚類演算法可以正常工作,我們會查看連續值數據分布並檢查異常值。如果不加這個步驟,嚴重傾斜的數據和異常值可能會導致很多問題。
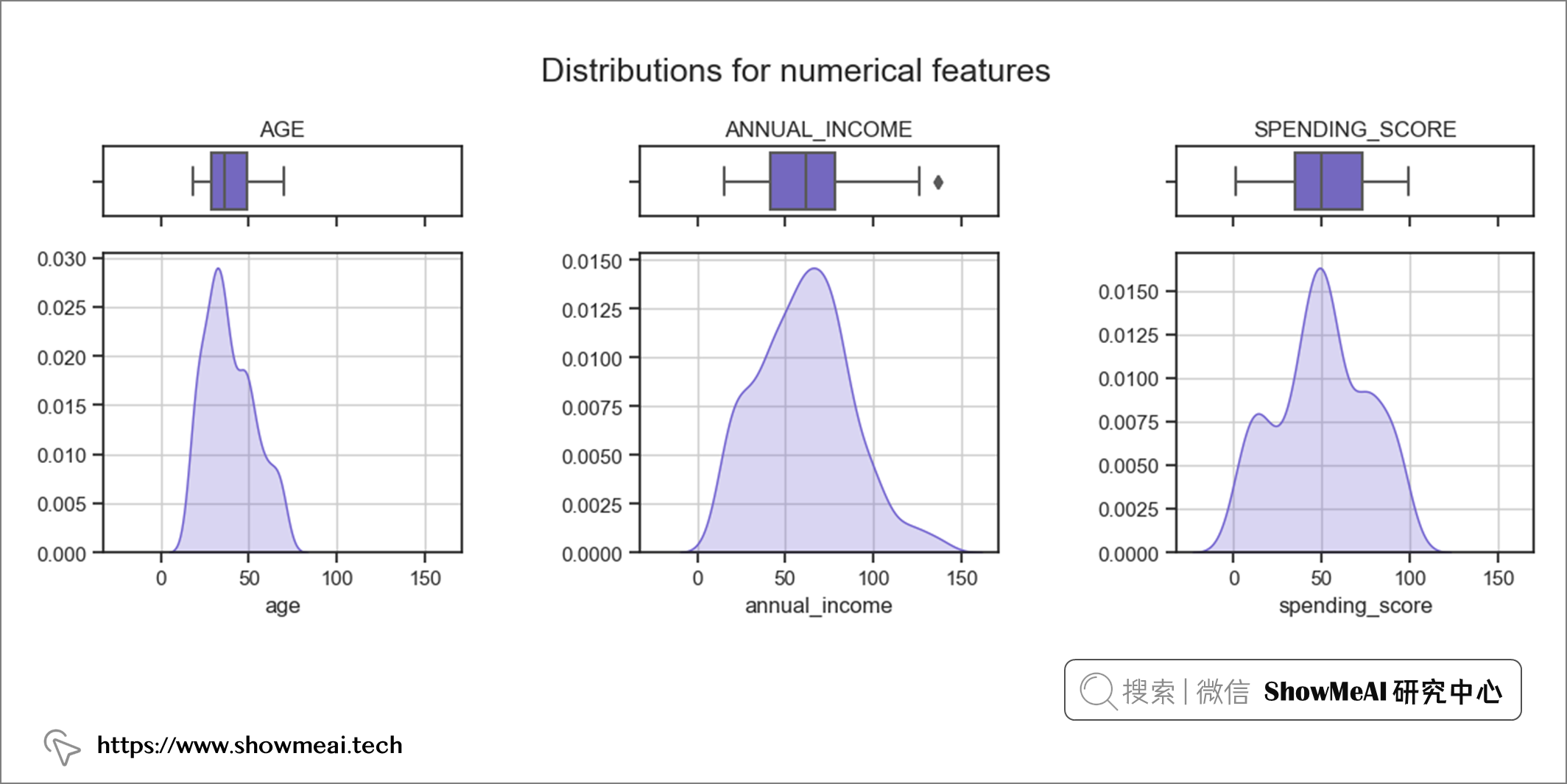
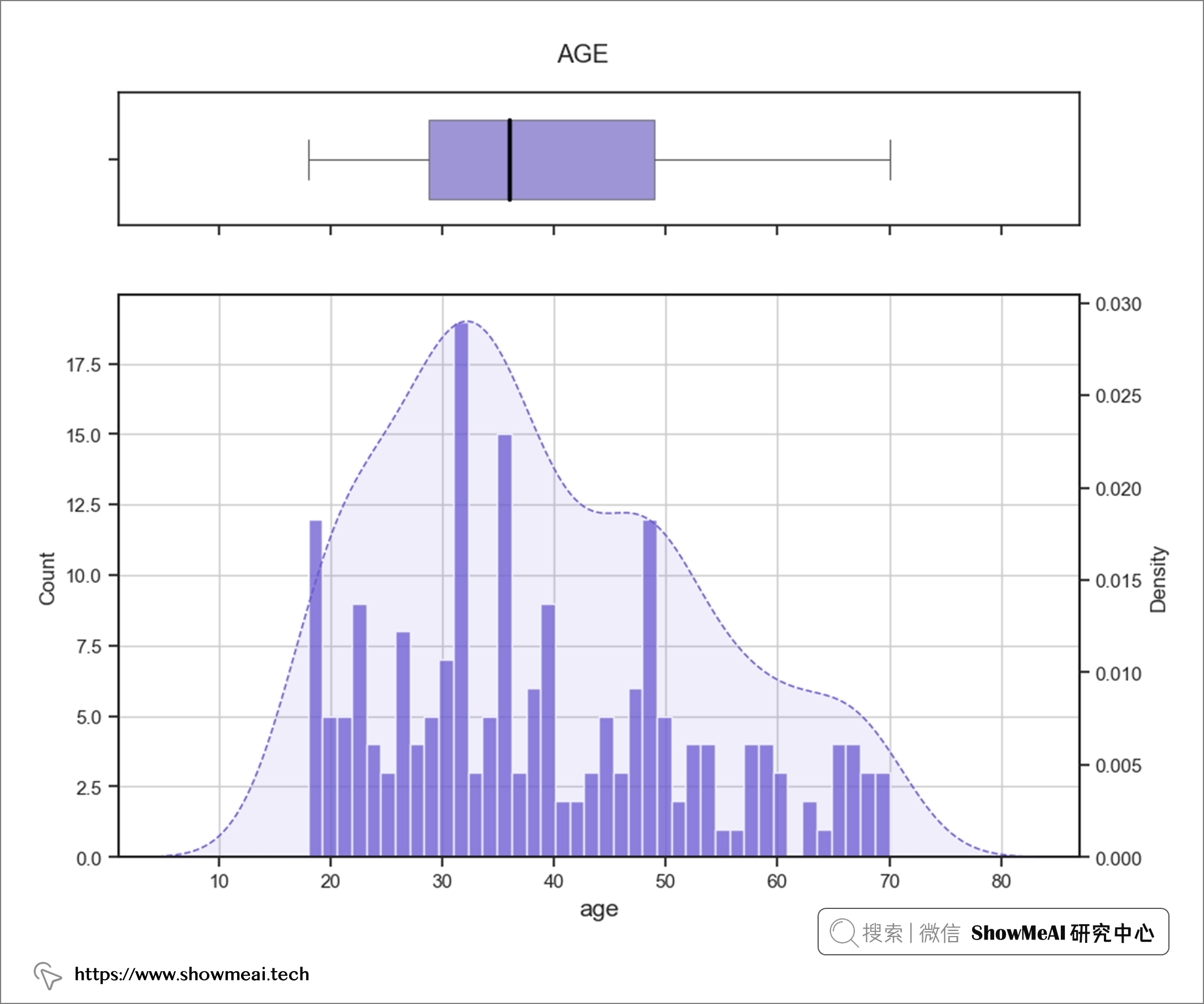
如上圖所示,除了annual_income特徵有一個異常值之外,大多數數值特徵已經很規整了。
sns.set_style("ticks", {'axes.grid' : False})
for idx, col in enumerate (numcol):
plt.figure()
f, ax = plt.subplots(nrows=2, sharex=True, gridspec_kw={"height_ratios": (0.2,0.85)}, figsize=(10,8));
plt.suptitle(f"{col.upper()}",y=0.93);
sns.boxplot(data=df,x=col,ax=ax[0],color="slateblue",boxprops=dict(alpha=.7),
linewidth=0.8, width=0.6, fliersize=10,
flierprops={ "marker" :"O", "markerfacecolor": "slateblue"},
medianprops={ "color": "black", "linewidth":2.5})
sns.histplot(data=df, ×=col, ax=ax[1],multiple="layer", fill=True, color= "slateblue", bins=40)
ax2 =ax[1].twinx()
sns.kdeplot(data=df, x=col, ax=ax2,
multiple="layer",
fill=True,
color="slateblue",
bw_adjust=0.9,
alpha=0.1,
linestyles="--")
ax[1].grid(False)
ax[0].set(xlabel="");
ax[1].set _xlabel(col, fontsize=14)
ax[1].grid(True)
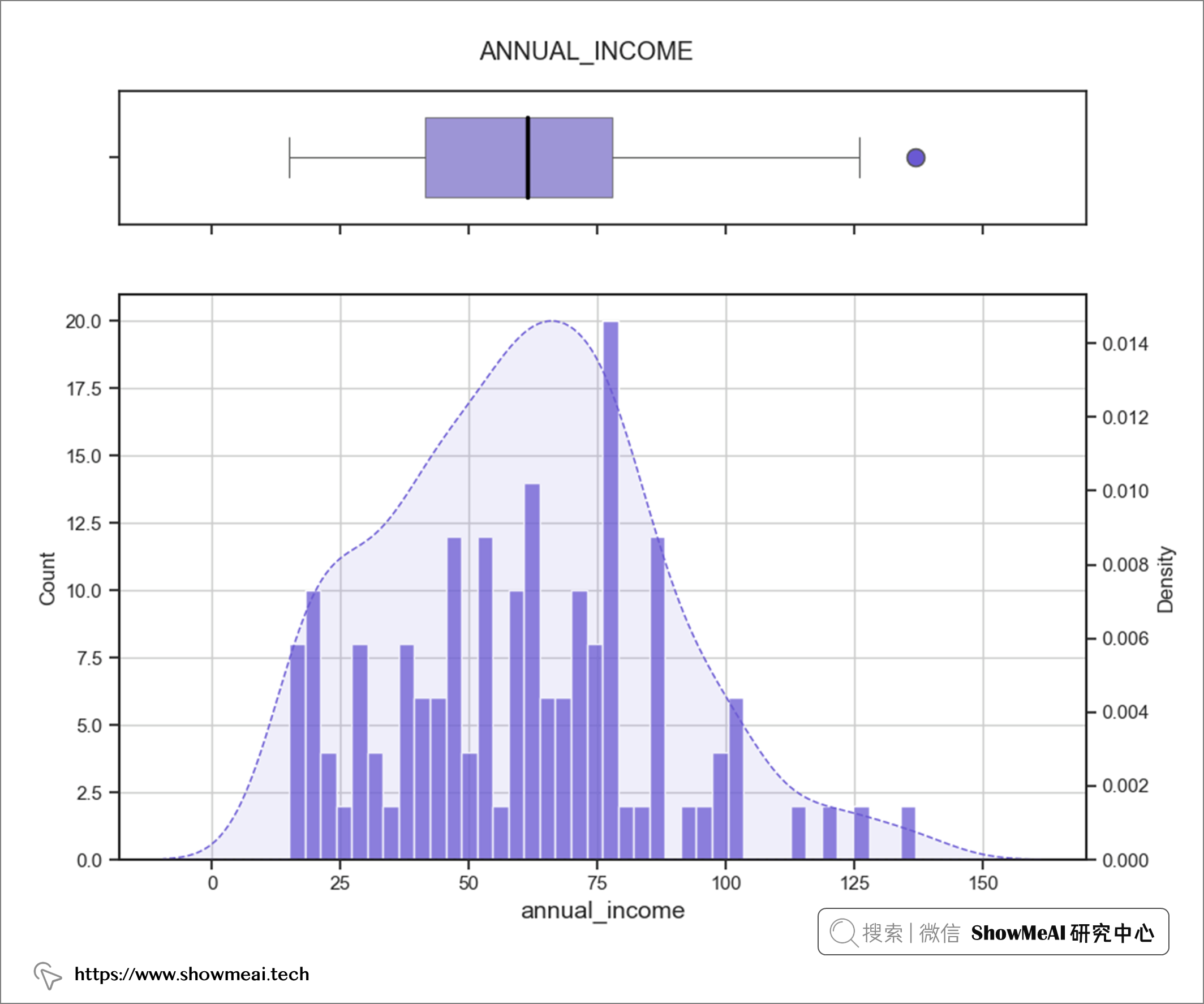
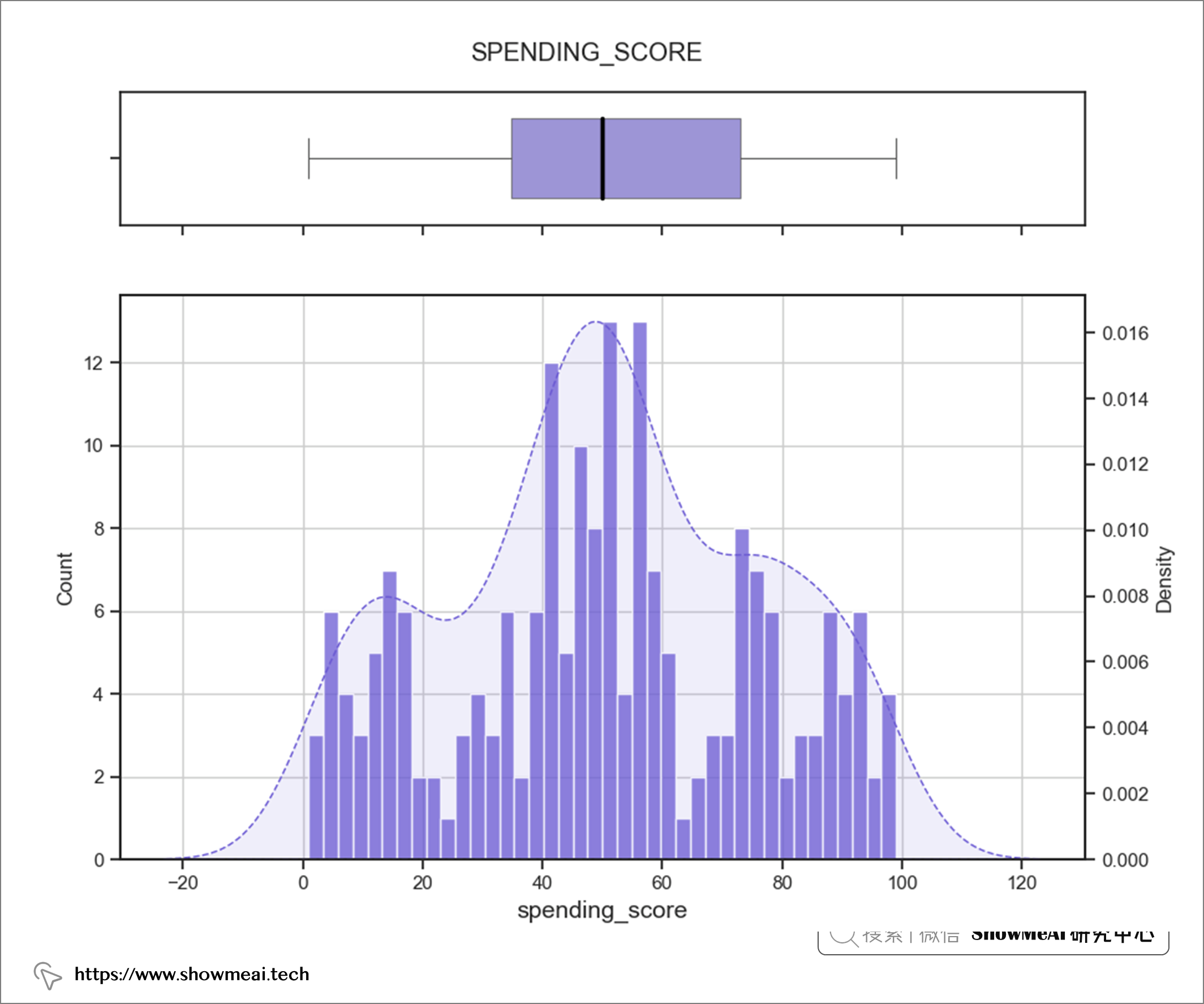
💦 雙變數分析
我們再對兩兩的特徵做聯合分析,程式碼和繪製結果如下:
sns.set_style("ticks", {'axes.grid' : False})
def pairplot_hue(df, hue, **kwargs):
g = sns.pairplot(df, hue=hue, **kwargs)
g.fig.subplots_adjust(top=0.9)
g.fig.suptitle(hue)
return g
pairplot_hue(df[numcol+objcol], hue='Gender')
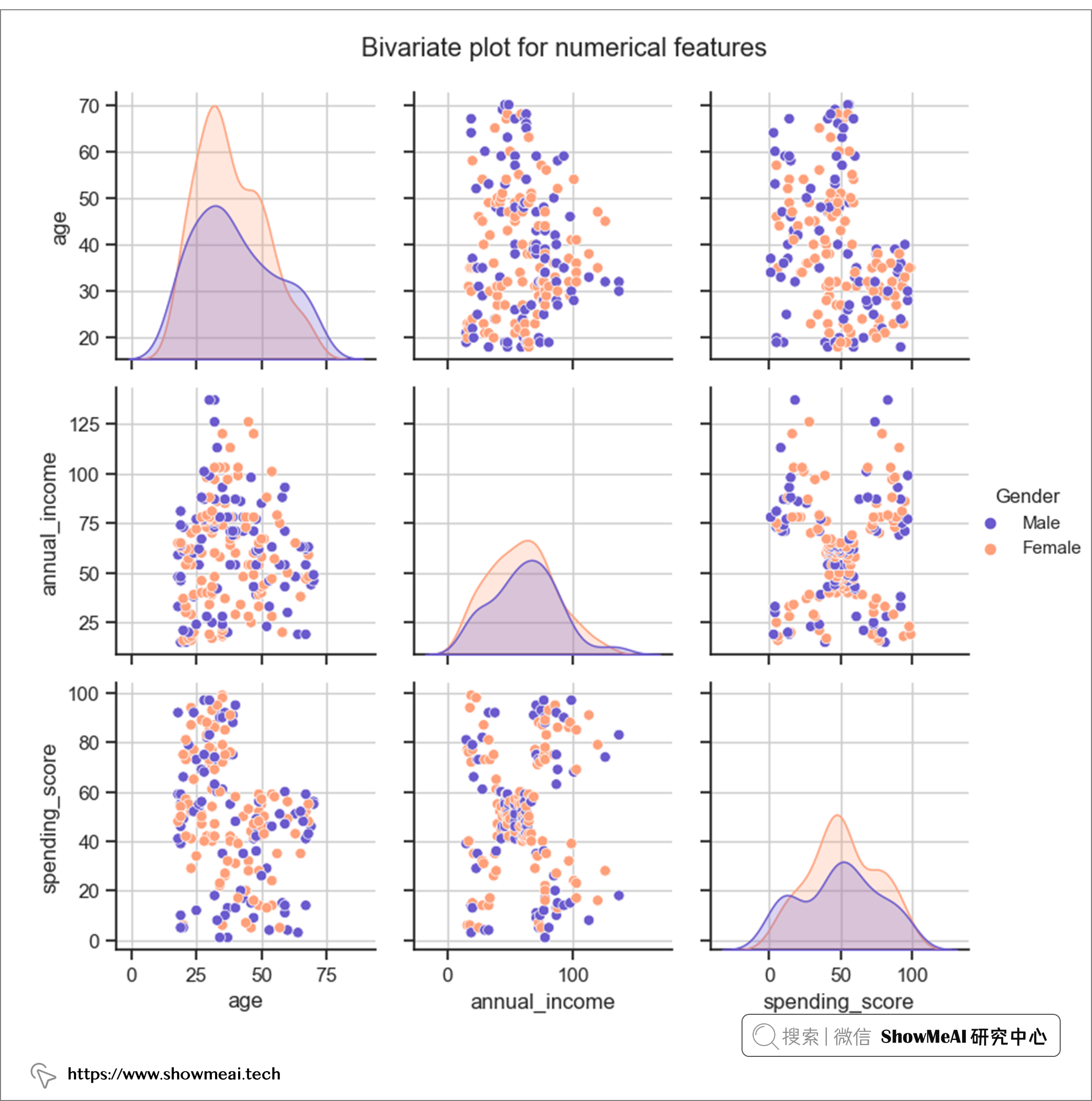
💡 建模
💦 數據縮放
為了保證後續聚類演算法的性能效果,數值特徵在送入模型之前需要做縮放處理。我們直接使用 sklearn 中的 MinMaxScaler 縮放方法來完成這項工作,將數值型欄位數據範圍轉換為 [0,1]。
scaler = MinMaxScaler()
df_scaled = df.copy()
for col in numcol:
df scaled[col] = pd.DataFrame(scaler.fit_transform(df_scaled[col].values.reshape(-1,1) ))
💦 模型選擇
本篇內容涉及的聚類無監督學習演算法,歡迎大家查看ShowMeAI的教程文章:
① K-Means 聚類
K-Means 演算法是一種無監督學習演算法,它通過迭代和聚合來根據數據分布確定數據屬於哪個簇。
 |
② 層次聚類(BIRCH) 演算法
BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)翻譯為中文就是『利用層次方法的平衡迭代規約和聚類』,全稱非常複雜。簡單來說,BIRCH 演算法利用了一個樹結構來幫助我們快速的聚類,這個特殊的樹結構,就是我們後面要詳細介紹的聚類特徵樹(CF-tree)。簡單地說演算法可以分為兩步:
-
1)掃描資料庫,建立一棵存放於記憶體的 CF-Tree,它可以被看作數據的多層壓縮,試圖保留數據的內在聚類結構;
-
2)採用某個選定的聚類演算法,如 K-Means 或者凝聚演算法,對 CF 樹的葉節點進行聚類,把稀疏的簇當作離群點刪除,而把更稠密的簇合併為更大的簇。
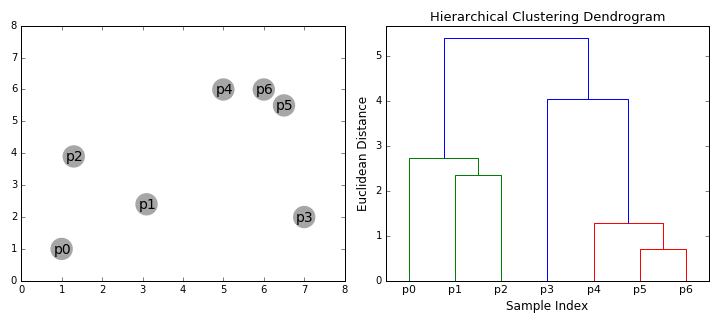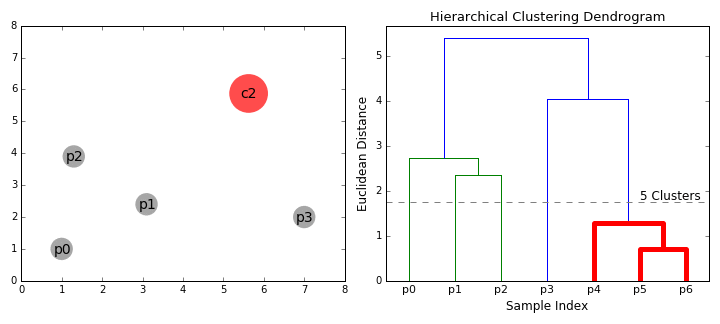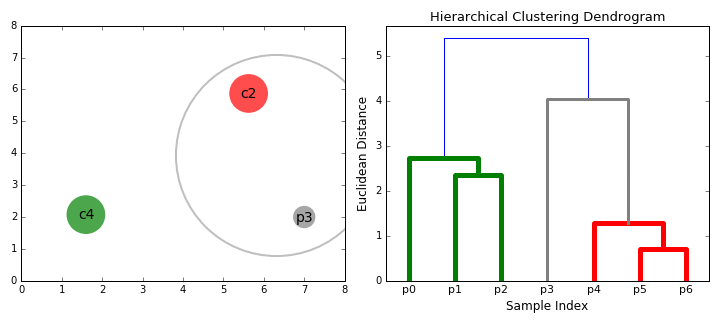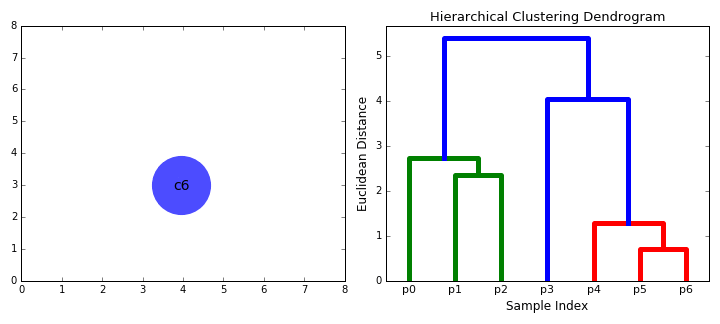 |
💦 模型評估
① 聚類演算法評估
雖然說聚類是一個無監督學習演算法,但我們也有一些方法可以對其最終聚類效果進行評估,對我們的建模和聚合有一些指導作用。
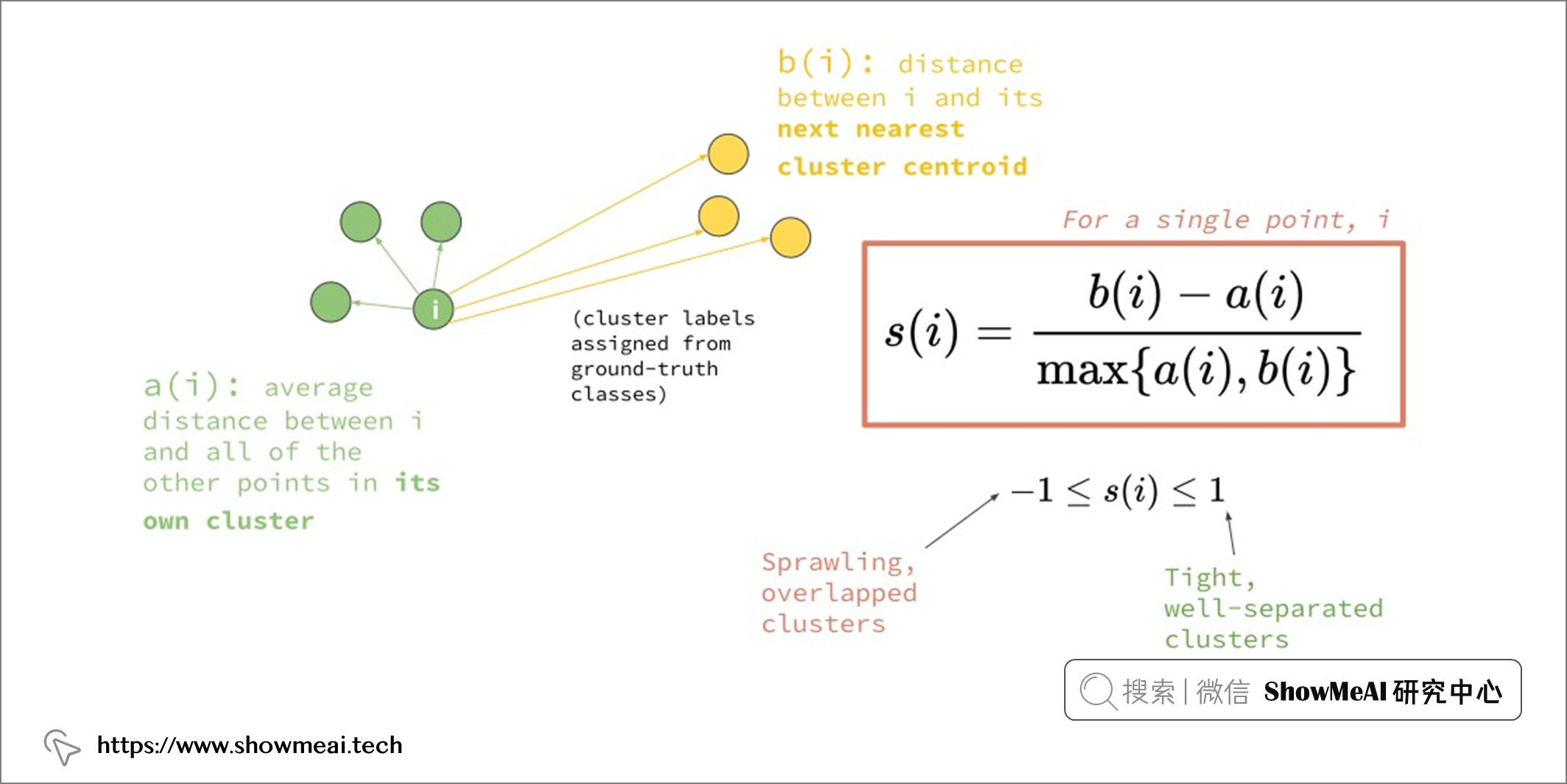
◉ 輪廓分數(Silhouette score)
輪廓分數( Silhouette score)是一種常用的聚類評估方式。對於單個樣本,設 a 是與它同類別中其他樣本的平均距離,b 是與它距離最近不同類別中樣本的平均距離,輪廓係數為:

對於一個數據集,它的輪廓係數是所有樣本輪廓係數的平均值。輪廓係數取值範圍是 [-1,1],同類別樣本越距離相近且不同類別樣本距離越遠,分數越高。
◉ 卡林斯基哈拉巴斯得分(Calinski Harabasz score)
卡林斯基哈拉巴斯得分(Calinski Harabasz score)也稱為方差比標準,由所有簇的簇間離散度(Between Group Sum of Squares, BGSS)之和與簇內離散度(Within Group Sum of Squares, WGSS)之和的比值計算得出。較高的 Calinski Harabasz 分數意味著更好的聚類(每個聚類中更密集)。以下給出計算過程:
第一步:計算簇間離散度(Between Group Sum of Squares, BGSS)

第二部:計算簇內離散度(Within Group Sum of Squares, WGSS)

第三步:計算卡林斯基哈拉巴斯得分(Calinski Harabasz score)

◉ 戴維斯布爾丹得分(Davies Bouldin score)
戴維斯布爾丹得分(Davies Bouldin score)表示每個集群與與其最相似的集群或每個集群的內部模式的平均相似度。最低可能或最接近零表示更好的聚類。
② 應用 K-Means 聚類
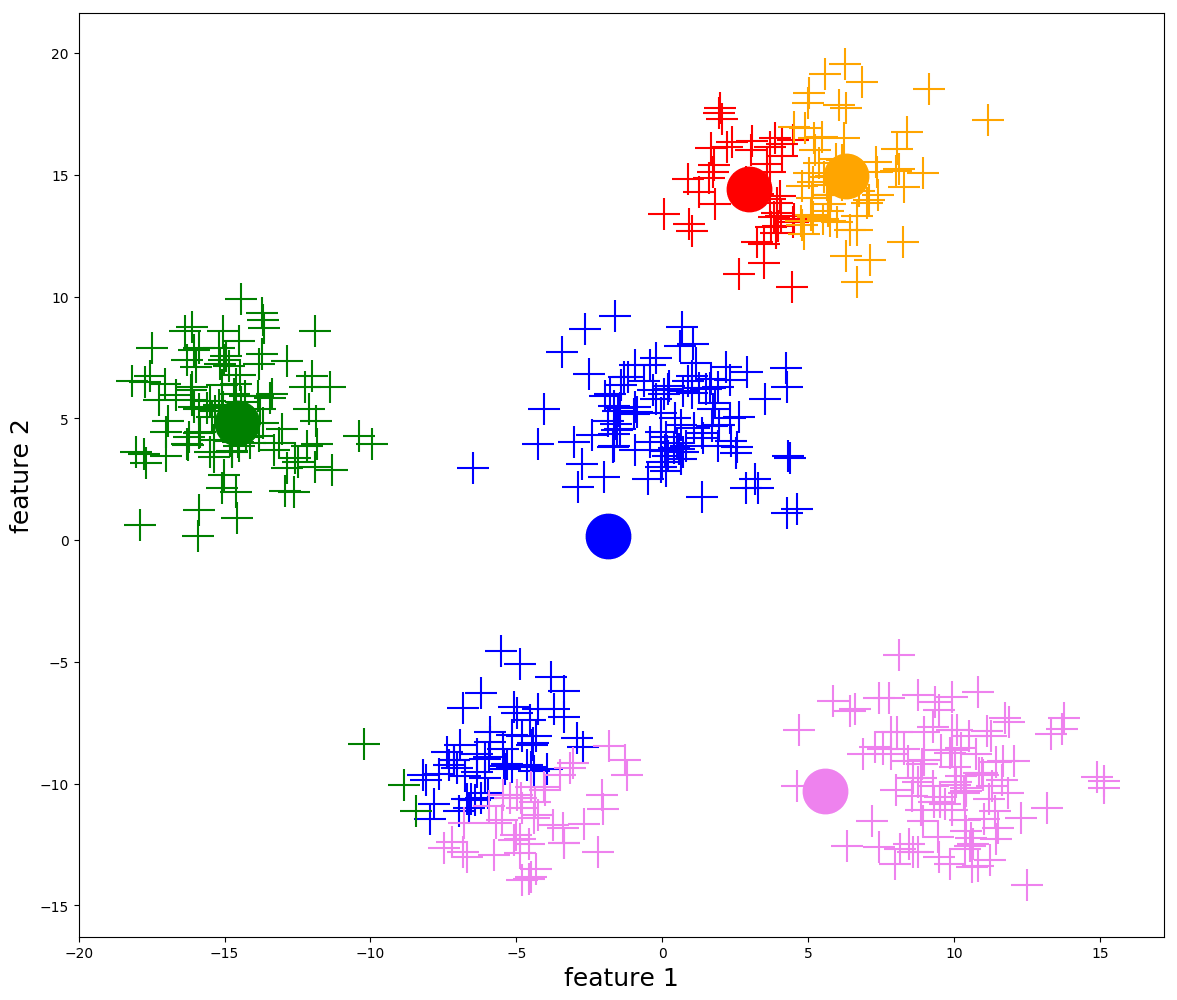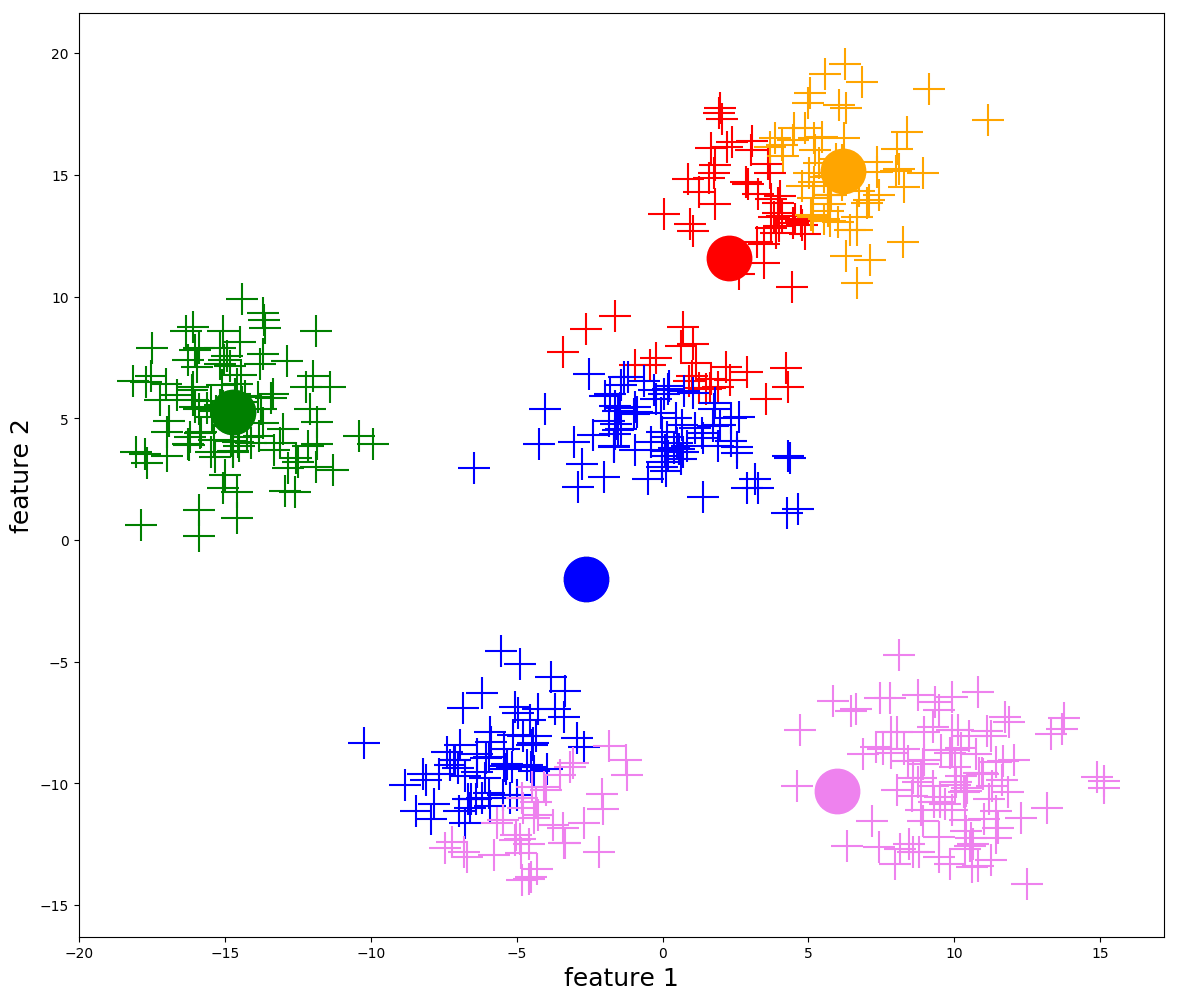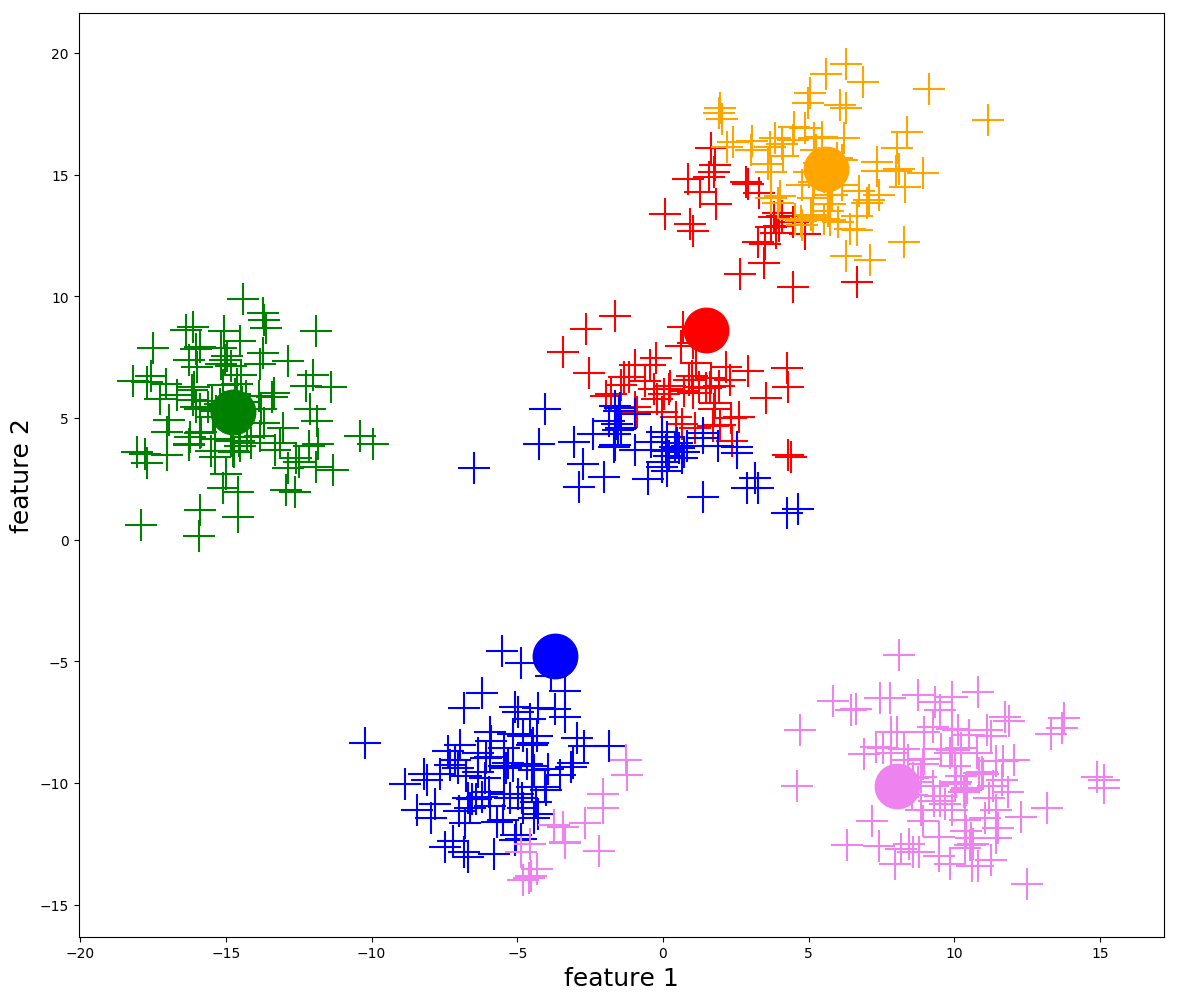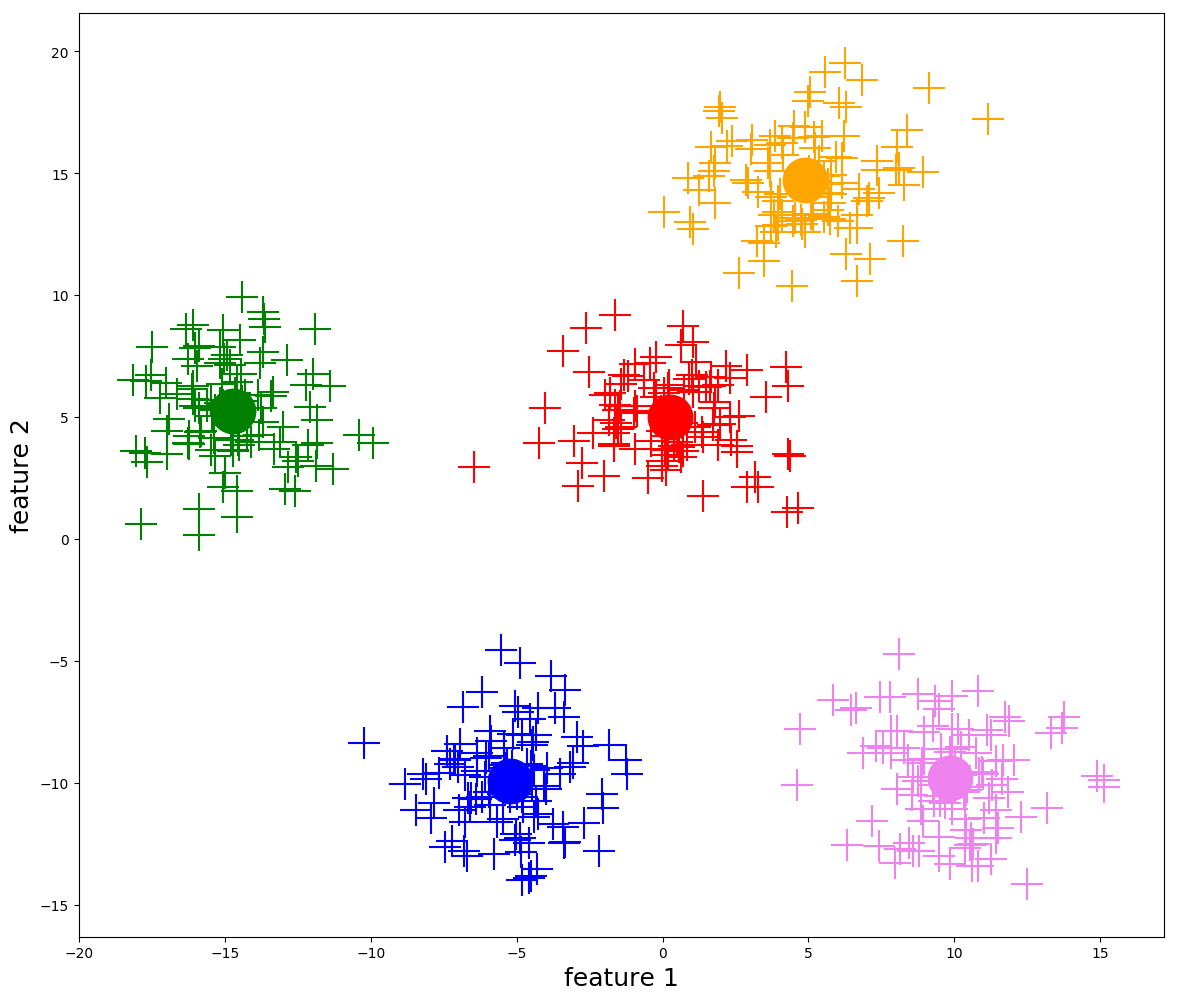
我們先應用 K-Means 聚類對數據進行建模,聚合得到不同的用戶簇,程式碼如下:
k_range = range(2,10)
for x in k range:
model = KMeans(n_clusters=x, random_state=42)
X = df_scaled[[ "annual_ income", "spending_score"]]
model.fit(x)
評估 K-Means 演算法的一種非常有效的方法是肘點法,它會可視化具有不同數量的簇的平方距離之和(失真分數)的加速變化(遞減收益)的過程。
我們結合上述提到的3個得分,以及肘點法進行計算和繪圖如下:
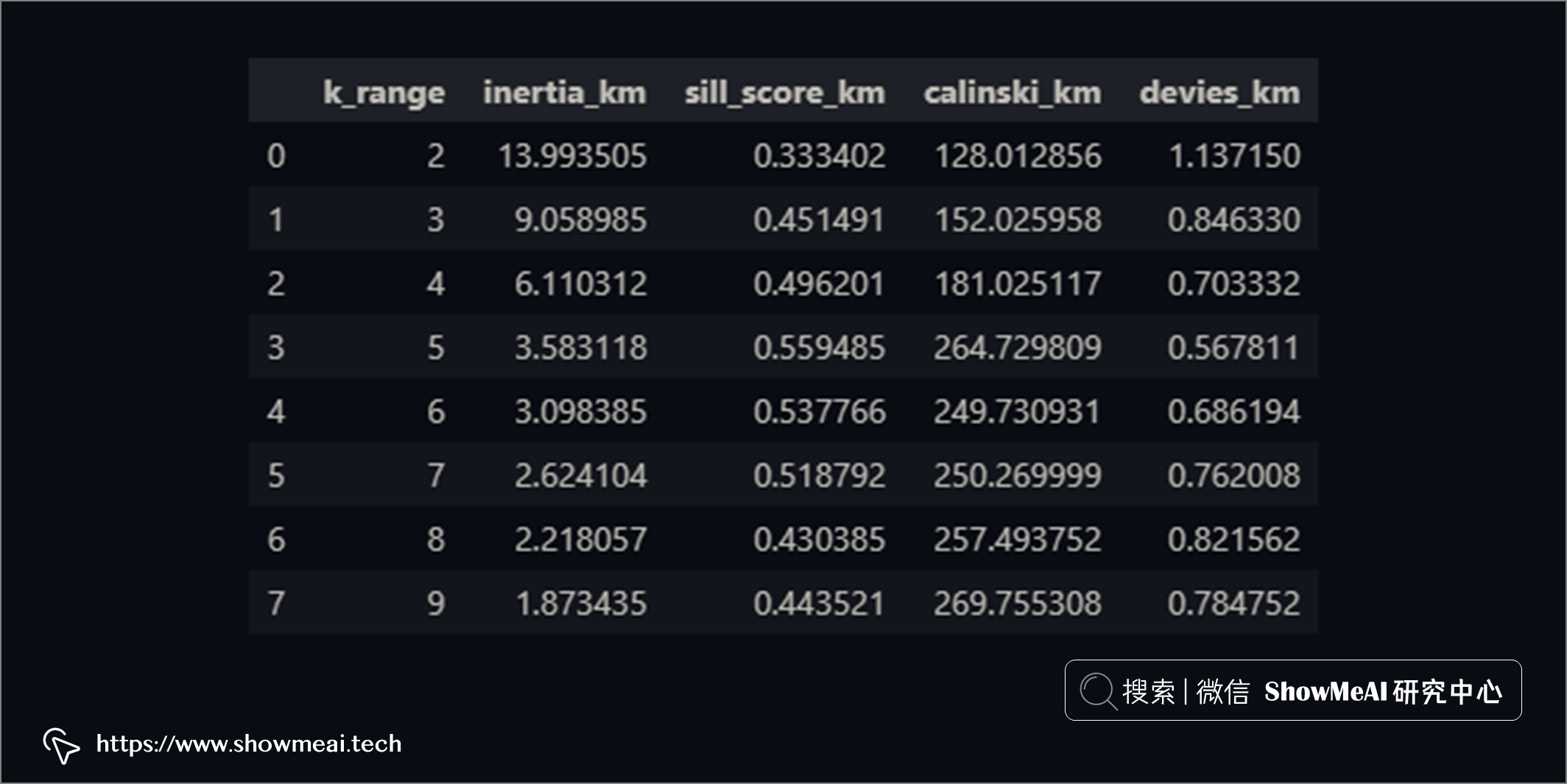
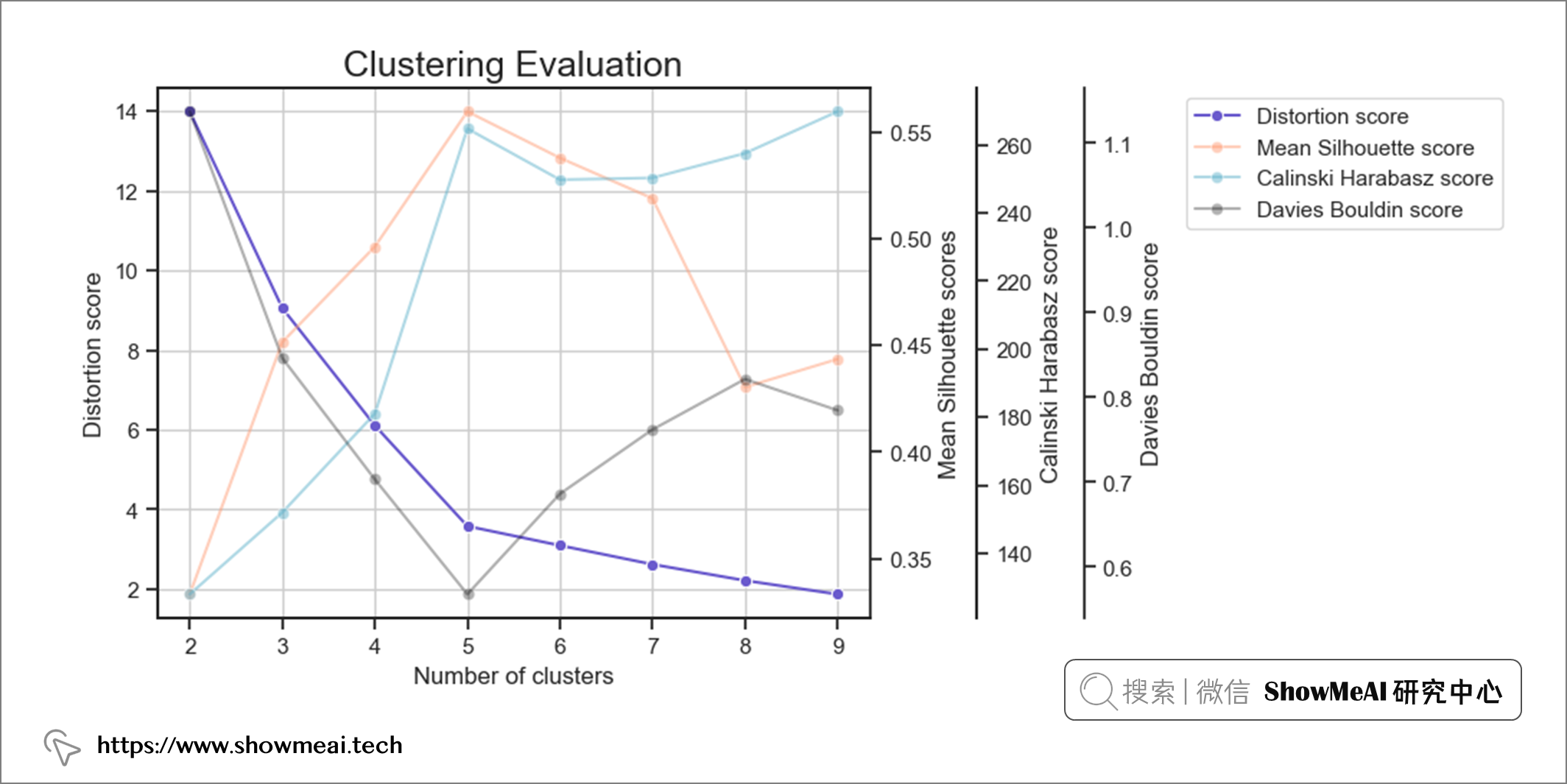
如上圖所示,簇數 = 5 是適用於該數據集的適當簇數,因為它有著這些特性:
- 開始遞減收益(肘法)
- 最高平均輪廓分數
- 相對較高的 Calinski Harabarsz 評分(局部最大值)
- Davies Bouldin 最低分數
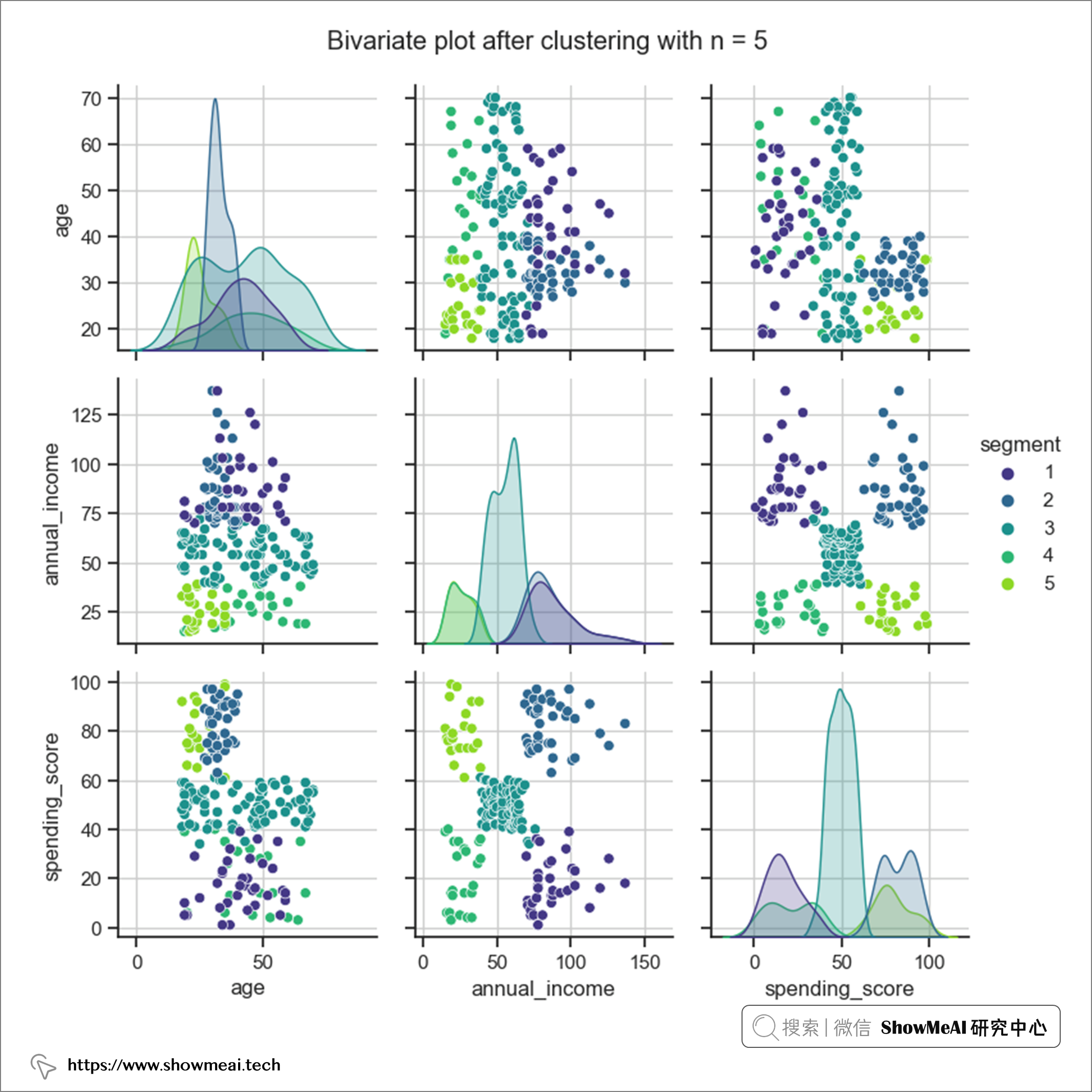
我們以5為聚類個數,對數據重新聚類,並分發聚類 id,然後再對數據進行分布分析繪圖,不同的用戶簇的數據分布如下(我們可以比較清晰看到不同用戶群的分布差異)。
③ 應用 BIRCH 聚類
我們再使用 BIRCH 進行聚類,程式碼如下:
n = range(2,10)
for x in n:
model = Birch(n_clusters=x, threshold=0.17)
X = df_scaledI[ "annual income", "spending_score"]]
model.fit(X)
與 K-Means 聚類不同,BIRCH 聚類沒有失真分數。其他3 個評分指標(Silhouette、CH、DBI)仍然相同。
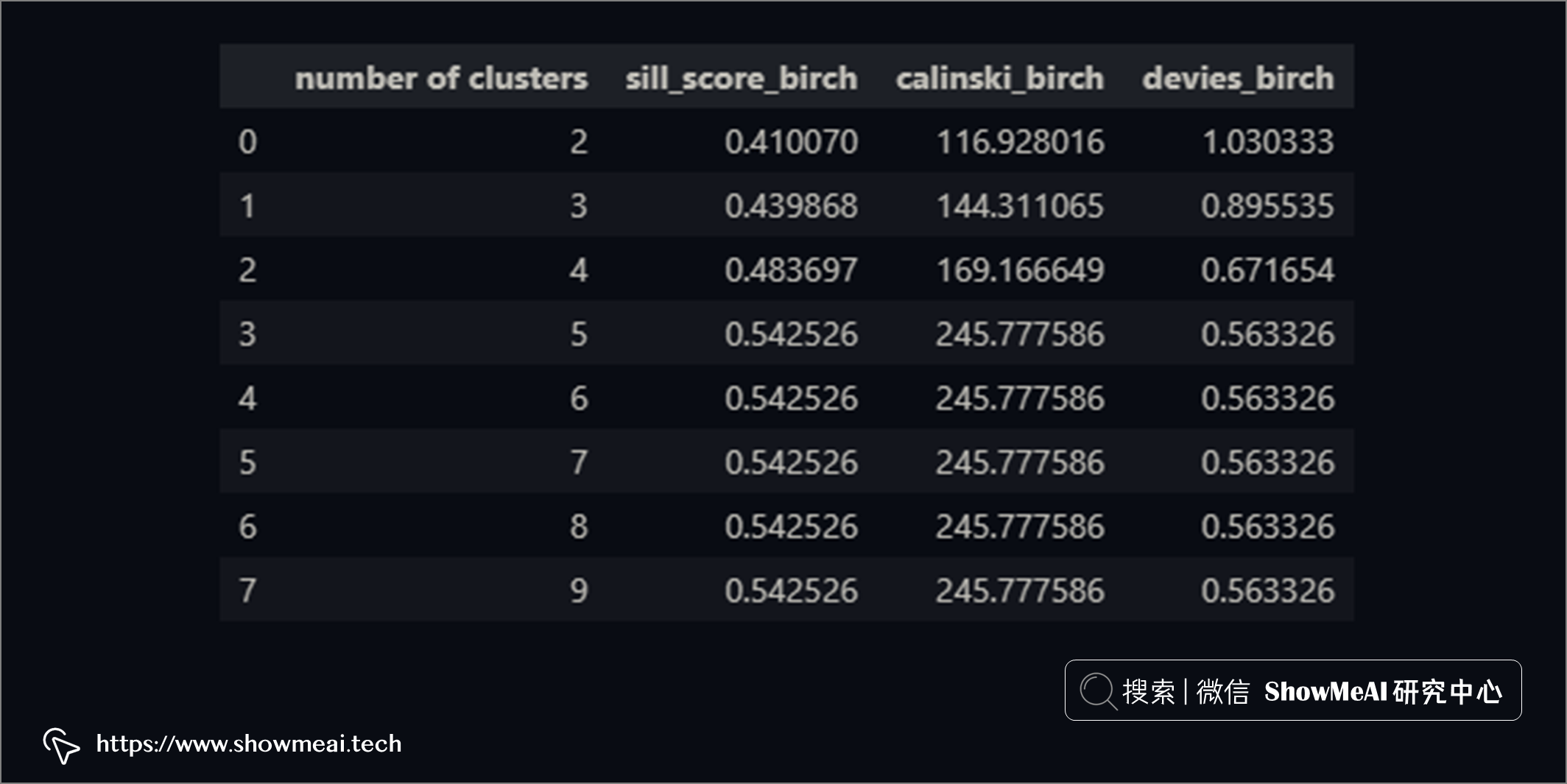
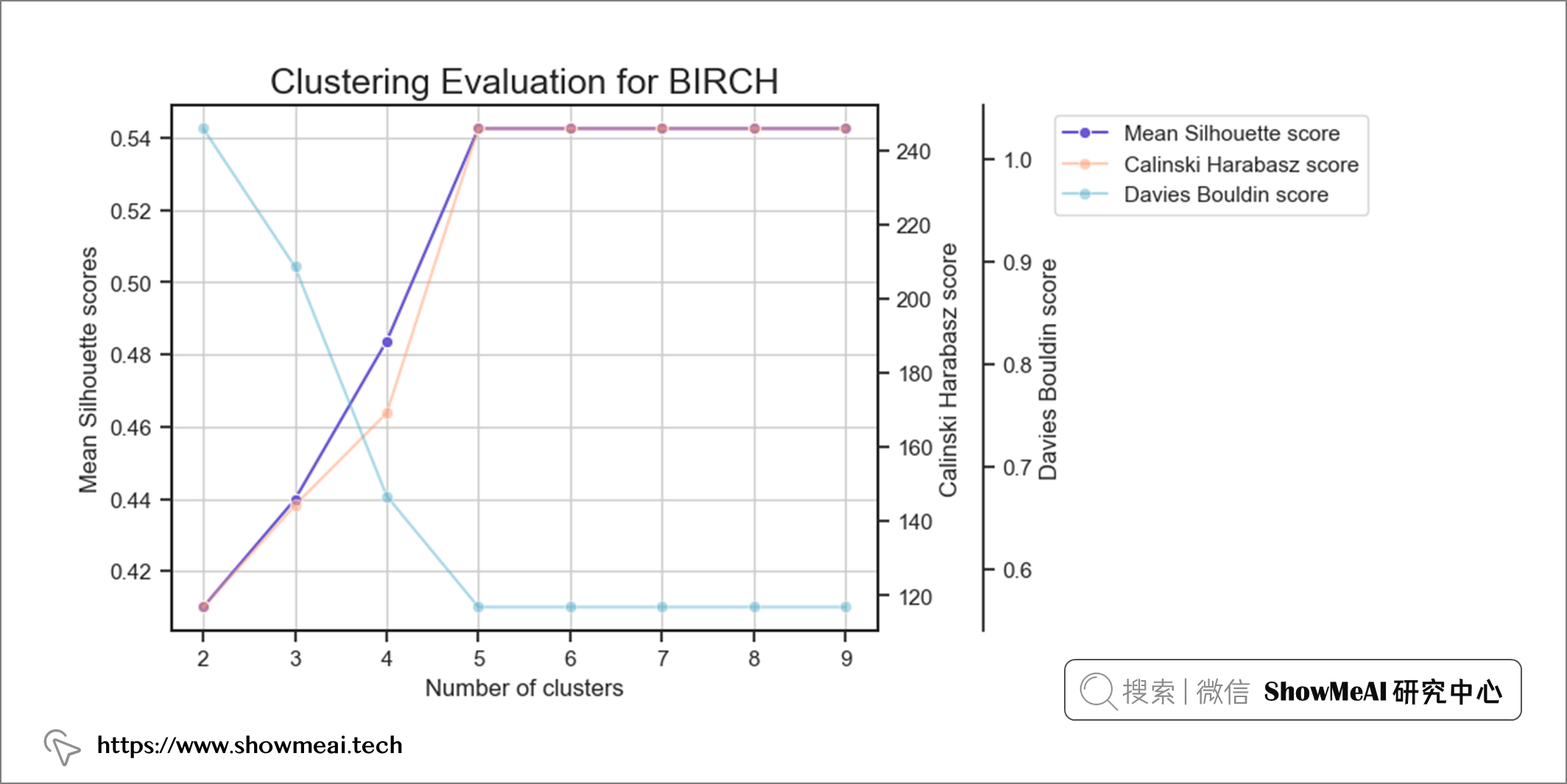
BIRCH 的計算也給出了簇數等於5這樣的一個結論。我們同樣對數據進行分布分析繪圖,不同的用戶簇的數據分布如下(依舊可以比較清晰看到不同用戶群的分布差異)。
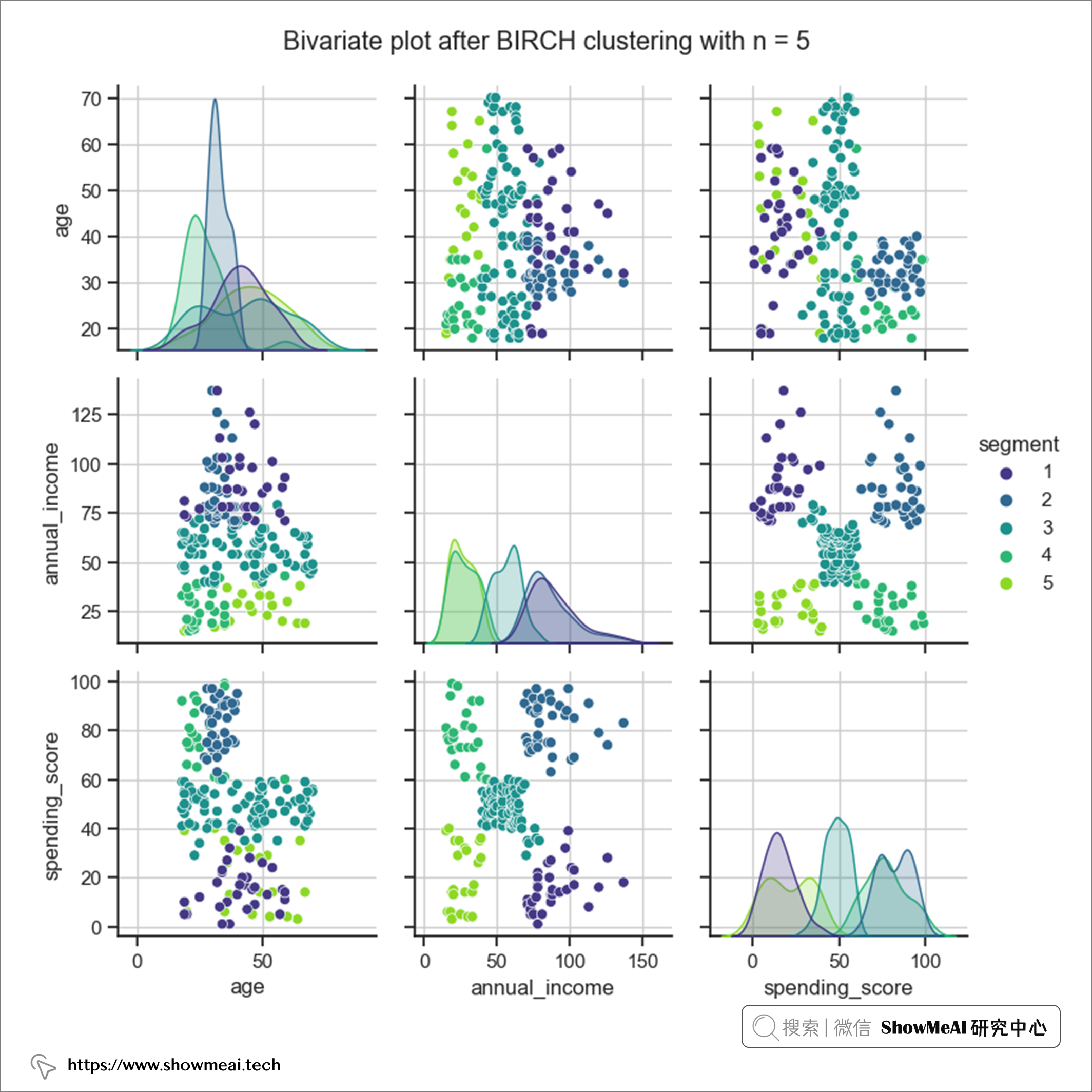
兩種演算法都得出相似的結果(不完全相同)。
④ 建模結果解釋
我們來對聚類後的結果做一些解釋分析,如下:
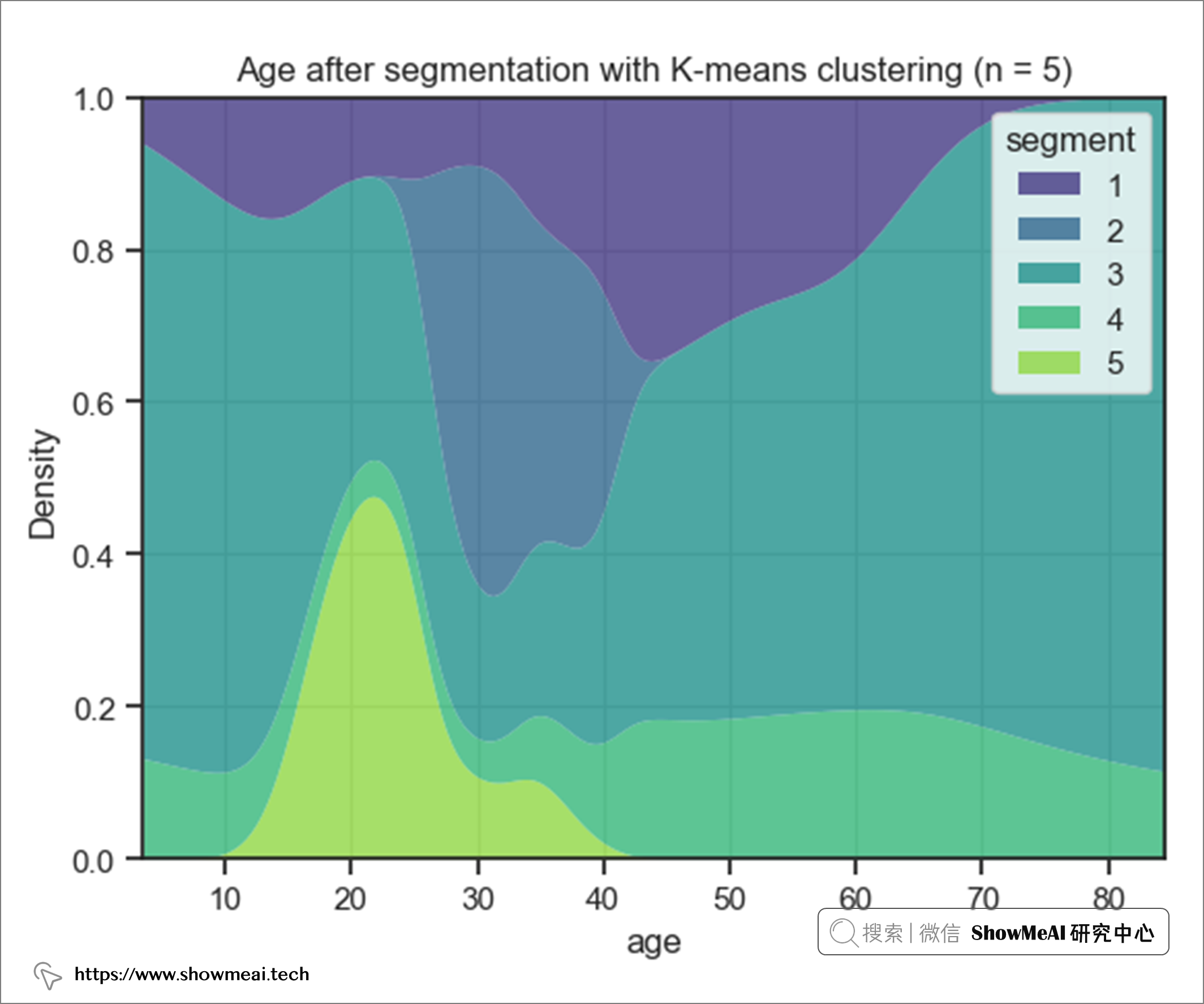
如上圖所示,從年齡的角度來看,不同的用戶簇有各自的一些分布特點:
- 第 2 個用戶簇 => 年齡在 27 到 40 歲之間 ,平均值為 33 歲。
- 第 5 個用戶簇 => 年齡在 18 到 35 歲之間 ,平均為 25 歲。

從收入維度來看:
- 用戶群4和5的年收入大致相等,大約為 26,000 美元。 → 低收入群體
- 用戶群1和2的年收入大致相等,這意味著大約 87,000 美元。 → 高收入群體
- 用戶群3是獨立組,平均年收入為 55,000 美元。 → 中等收入群體
綜合年齡和年收入得出以下結果。
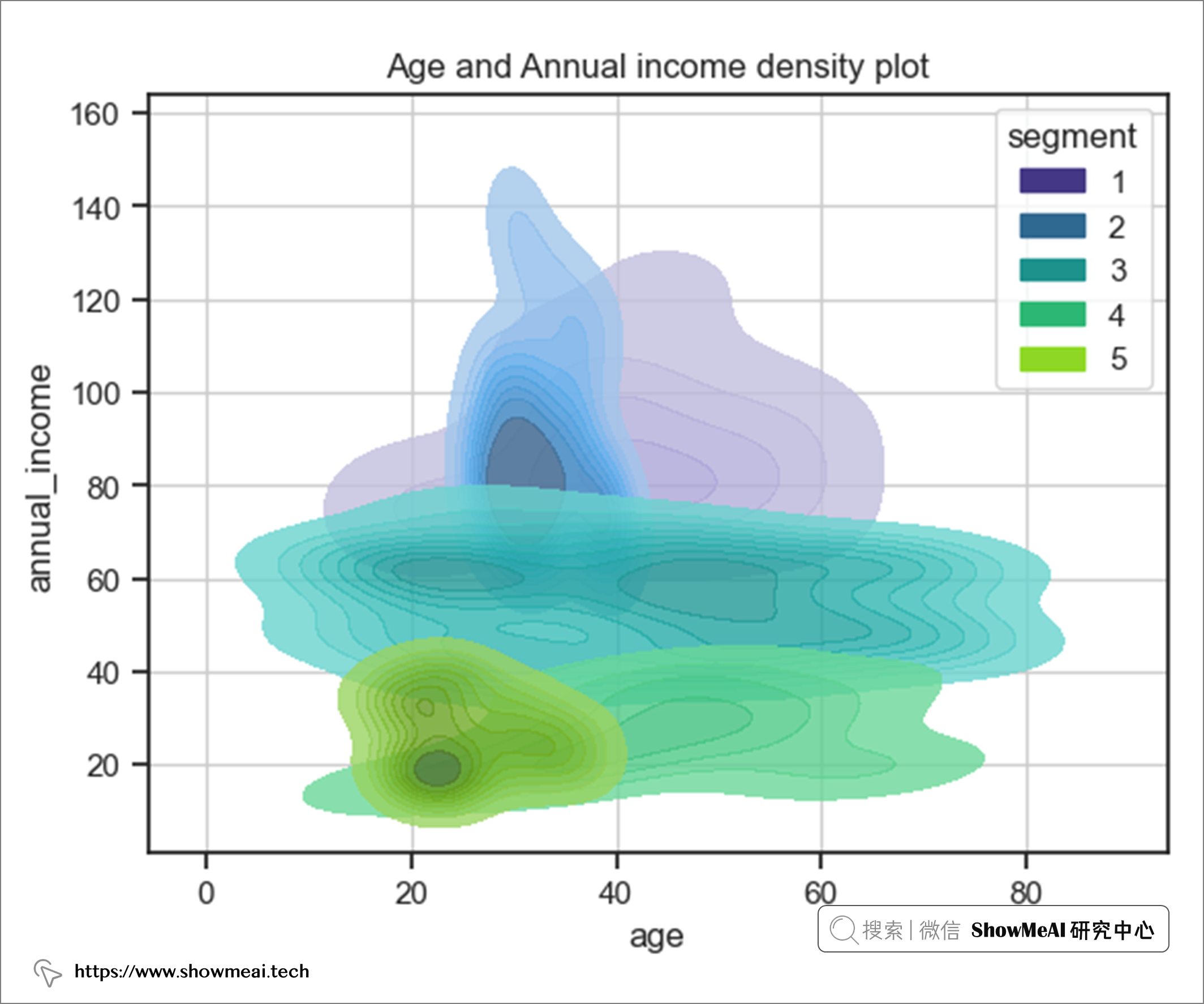
結果表明
- 用戶群2和5的年齡範圍相同,但年收入有顯著差異
- 用戶群4和5的年收入範圍相同,但第 5 段屬於青少年組(20-40 歲)
從花費的角度來看分組的用戶群:
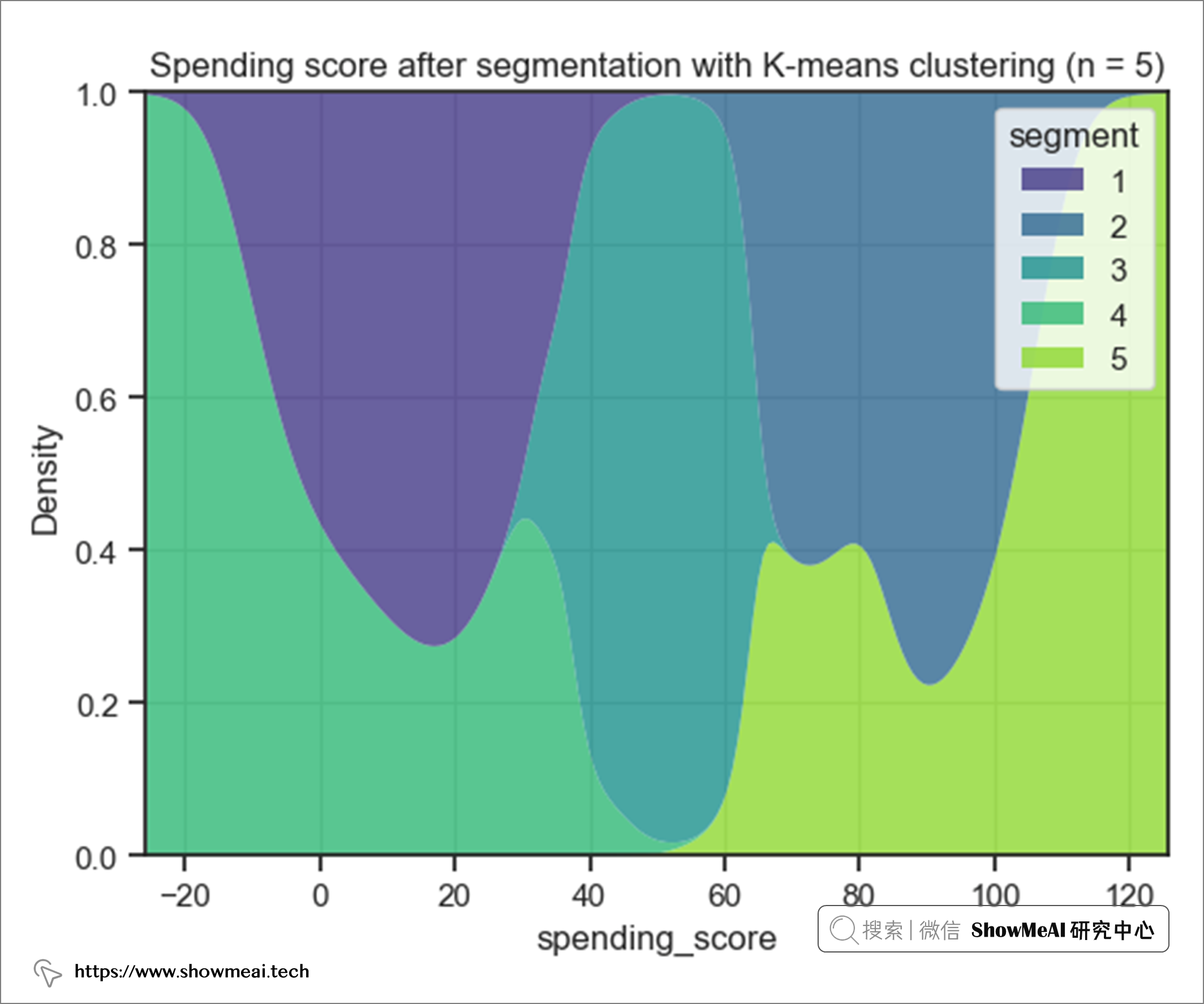
結果表明
- 用戶群5的 支出得分最高。
- 用戶群4的 支出得分最低。
綜合支出分和年收入來看。
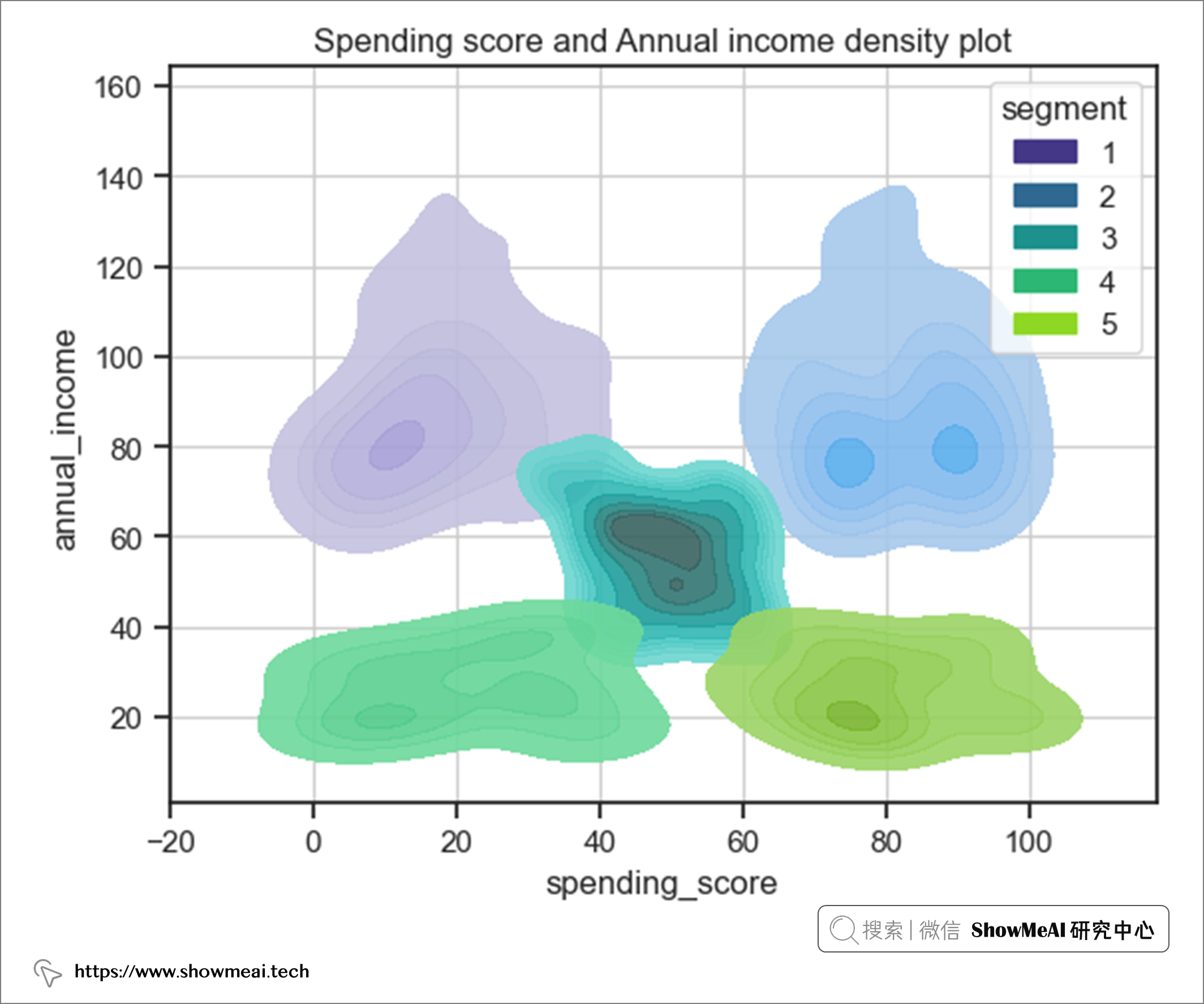
結果表明:
- 用戶群1和2的年收入範圍相同,但支出分範圍完全不同。
- 用戶群4和5的年收入範圍相同,但支出分範圍完全不同。
💡 結論
我們對各個用戶群進行平均匯總,並繪製圖表如下:
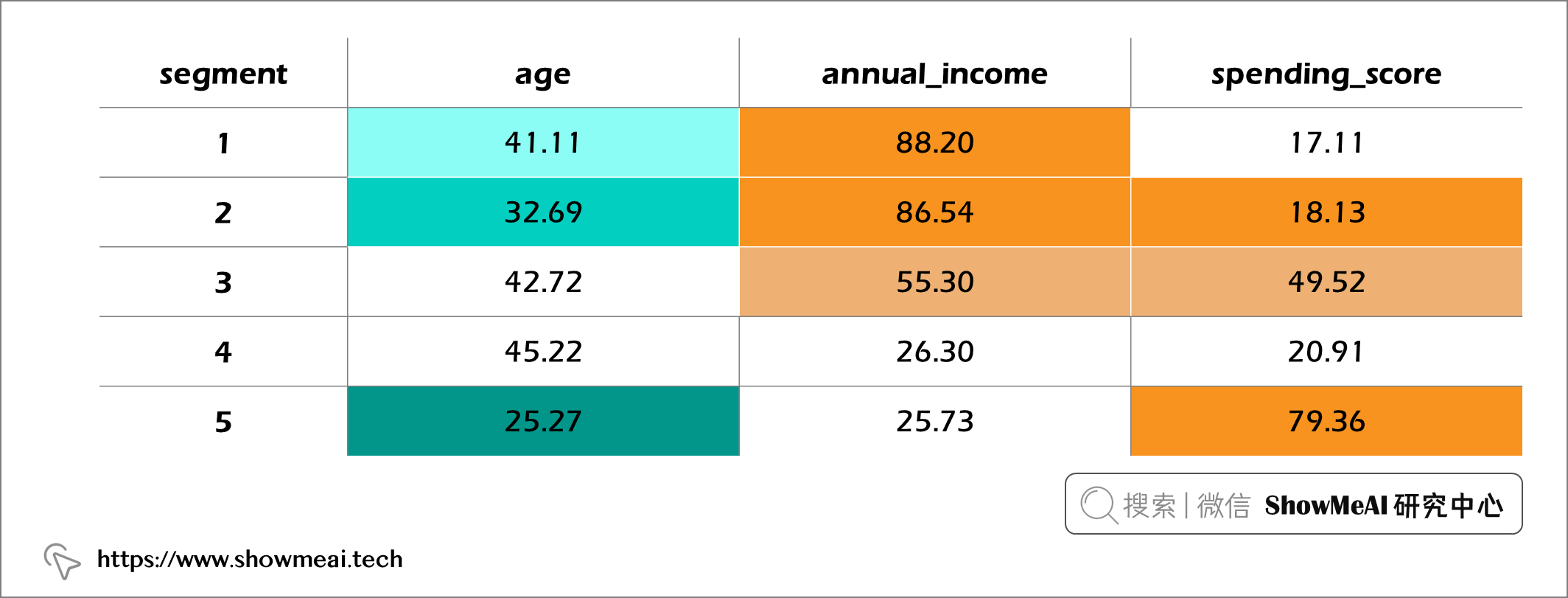
- 用戶群1是最高年收入組,但有最差的支出消費。 → 目前商城的產品並不是這部分客戶的消費首選(非目標客戶)。
- 用戶群2的平均年齡比第 1 段低 10 倍,但在相同年收入範圍內的平均支出分數是 4 倍。
- 用戶群5是最高支出分數但是最低年收入組。 → 客戶購買慾望強,但消費能力有限。
參考資料
- 📘 基於機器學習的用戶價值數據挖掘與客戶分群://showmeai.tech/article-detail/325
- 📘 數據科學工具庫速查表 | Pandas 速查表://www.showmeai.tech/article-detail/101
- 📘 數據科學工具庫速查表 | Matplotlib 速查表://www.showmeai.tech/article-detail/103
- 📘 數據科學工具庫速查表 | Seaborn 速查表://www.showmeai.tech/article-detail/105
- 📘 圖解數據分析:從入門到精通系列教程://www.showmeai.tech/tutorials/33
- 📘 圖解機器學習 | 聚類演算法詳解:ttps://www.showmeai.tech/article-detail/197