貪心演算法-構造哈夫曼數及生成哈夫曼編碼,編程實現
哈夫曼樹
1.概念:
- 給定n個權值最為n個葉子的節點,構建成一顆二叉樹。如果次樹的帶權路徑長度最小,則稱此二叉樹為最優二叉樹,也叫哈夫曼樹。
- WLP:帶權路徑長度
-
公式:
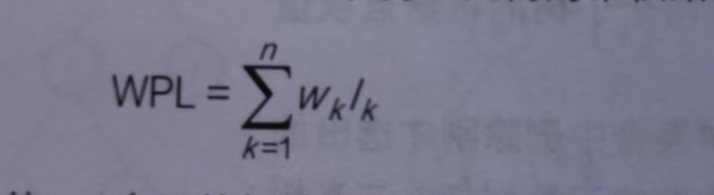
-
Wk:第k個葉子的節點權值
-
Lk:根節點到第k個葉子的節點長度
-
例如下列二叉樹:
- 給定4個葉子節點,權值分別為{2,3,5,8},可以構造出4中形狀不同的二叉樹,但它們的帶權路徑長度可能不同。
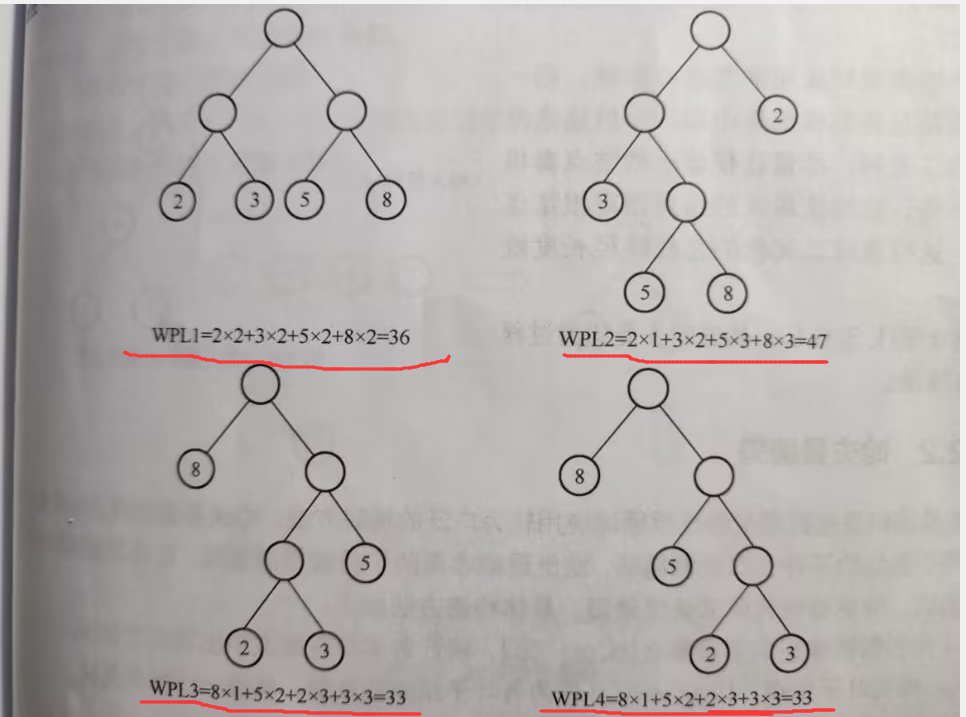
如上圖可看出:1、最後兩個樹的帶權路徑長度相同且也是最小的,所以可看作哈夫曼樹
2、權值最小的節點越靠下,越大越靠近根節點
2.構建哈夫曼樹
(1)、在{2,3,5,8}這幾個節點看作葉子節點(即後面沒有子節點)

(2)、在這幾個節點中選出權值最小和次小的兩個節點。構成一個新二叉樹(最小為左位元組的、次小為右子節點),新二叉樹的權值為這兩個權值之和.
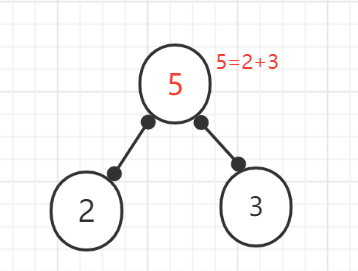
(3)、刪除已經使用過的節點。將新創建的節點加入到還沒被使用過的節點集合中,找出最小和次小的節點權值。又構成一顆新的二叉樹。

(4)、重複(2)的操作
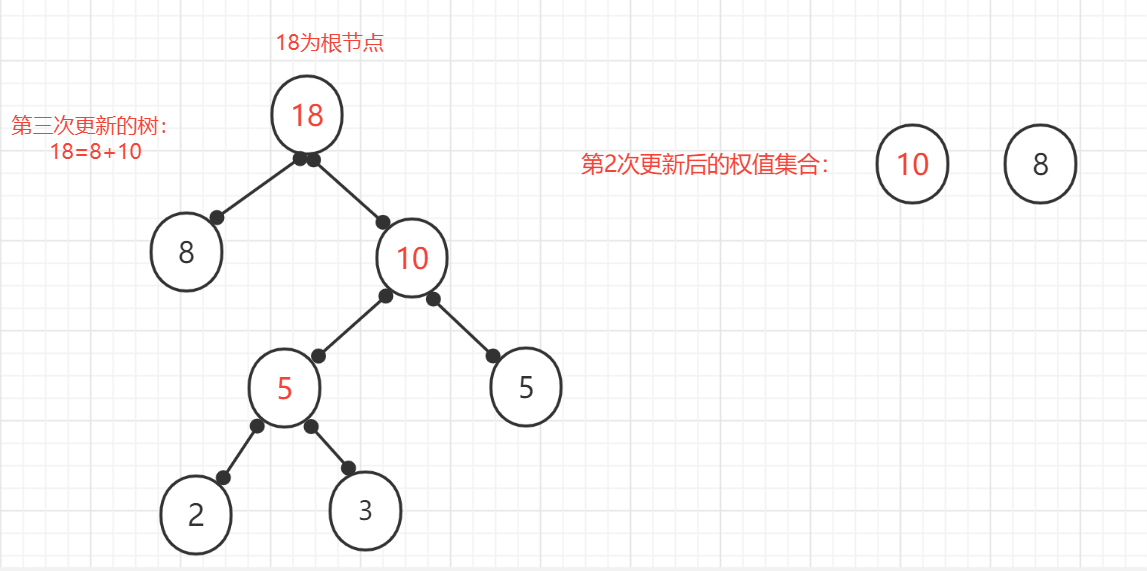
(5)、重複上面操作:刪除已使用的節點,將新的節點加入未使用節點的集合中,發現只有一個節點,其權值為18.則此哈夫曼樹創建完成,根節點權值為18.
程式碼如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 構造哈夫曼樹
*/
public class test1 {
public static void main(String[] args) {
int[] arr={2,3,5,8};
//調用自定義的哈夫曼樹方法,生成哈夫曼樹
hafmantree(arr);
}
/**
* ,構造哈夫曼數方法
*
* @param arry
*/
public static void hafmantree(int[] arry) {
//創建集合用於存放節點值
List<Node> nlis = new ArrayList<Node>();
//遍歷集合
for (int value : arry) {
//將每個數組元素看作Node節點對象,並存入list集合內
nlis.add(new Node(value));
}
/*
由於集合中存入的是一個個的Node對象,而Node對象已經被我們聲明成了按照從小到大的可排序對象。
所以這裡我們為可以通過Collections工具類中的sort方法進行排序
*/
//循環條件:只有一個節點,即最終根節點
while (nlis.size() > 1) {
Collections.sort(nlis);
//查看集合中還未被使用的節點
System.out.println(nlis);
//到了這裡說明集合中的所有節點(權值)都是按照從小到大的順序
//獲取最小的節點值(二叉樹左節點):子節點
Node lileft = nlis.get(0);
//獲取第2小的節點值(二叉樹右節點):子節點
Node lireght = nlis.get(1);
/*創建新的Node節點對象(二叉樹):
此節點對象是最小的兩個節點之和所生成的最新的節點。三個節點可以看成一個二叉樹,即:
根節點(insternode對象)、左子節點(lileft.value)、右子節點(lireght.value)
*/
Node insternode = new Node(lileft.value + lireght.value);
//此二叉樹的左節點
insternode.left = lileft;
//此二叉樹的右節點
insternode.right = lireght;
//刪除已經被處理過的節點
nlis.remove(lileft);
nlis.remove(lireght);
//將最新的節點加入到list集合中
nlis.add(insternode);
//重新對最新的list數組進行排序
Collections.sort(nlis);
}
//查看最終根節點
System.out.println(nlis);
}
}
/**
* ,構造哈夫曼數節點類,
* 此類也可以看成一個二叉樹:根節點(Node對象)、左節子點(left)、右位元組點(right)
* 實現Comparable介面:說明此類是可通過Collections工具類排序的,
*/
class Node implements Comparable<Node> {
int value; //每個節點的值(權值)
Node left; //每個二叉樹的左指向節點
Node right; //每個二叉樹的右指向節點
//構造方法,這裡只需要初始化value實例變數,用於對象的賦值,而 left 與 right 本身就是此對象,可直接用於value賦值
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
//支援從小到大排序
@Override
public int compareTo(Node o) {
return this.value - o.value;
}
}
結果:
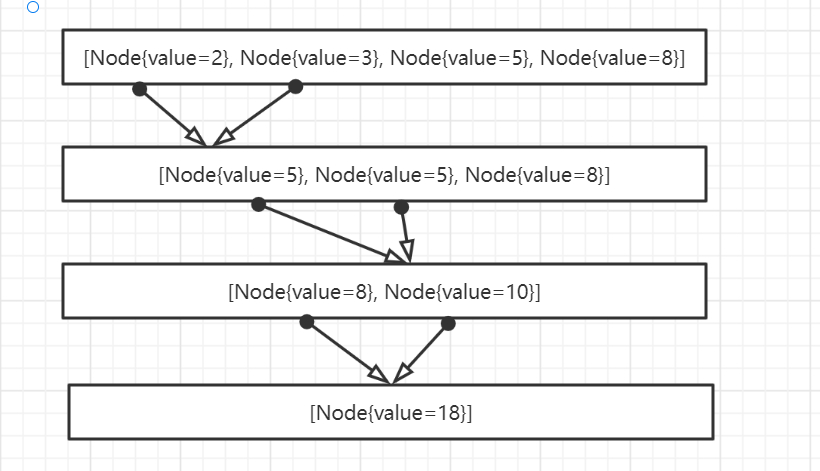
3.構建哈夫曼編碼
-
這裡是對一段字元串進行哈夫曼編碼,所以需要先處理字元串
-
在哈夫曼樹的基礎上,規定了路徑編碼。
-
遍歷已經創建好了的哈夫曼樹,從它的根節點遍歷次樹到葉子節點,左子路徑編碼:0 、右子路徑編碼:1
import java.util.*;
/**
* 構造哈夫曼數+生成哈夫曼編碼,編程實現。
*/
public class test1 {
public static void main(String[] args) {
//需要轉換為哈夫曼編碼的字元串
String valus="asdsgddbhj ,sjsh";
//將字元串存以node對象存入list集合中
List<Node> list = ListAndNode(valus);
//生成哈夫曼樹
Node node = HFMTree(list);
//得到哈夫曼編碼
HFMTable(node,"",andindex);
System.out.println(yezijied); //{32=1010, 97=1011, 98=1100, 115=01, 100=111, 103=1101, 104=001, 106=100, 44=000}
}
/*
第四步:
創建哈夫曼編碼表:將葉子節點以0、1表示。0===》向左子節點走。1===》向右子節點走
yezijied:存放葉子節點對應的哈夫曼編碼。此集合作業與全局
andindex:拼接編碼。(拼接對應的0或1,形參最終的哈夫曼編碼)
*/
static Map<Byte,String> yezijied=new HashMap<>();
static StringBuilder andindex=new StringBuilder();
/**
*
* @param node:節點
* @param index:路徑表示:左路徑為0.右路勁為1
* @param sub:拼接路徑,使其成為對應葉子節點的哈夫曼碼
*/
public static void HFMTable(Node node,String index,StringBuilder sub){
//
StringBuilder gitindex=new StringBuilder(sub);
//拼接路徑
gitindex.append(index);
//如果節點為空就不需要處理
if (node!=null) {
//如果當前節點不是葉子節點
if (node.value == null) {
//如果節點不為空就遞歸其左邊節點。並設置向左為0
HFMTable(node.left, "0", gitindex);
//如果節點不為空就遞歸其右邊節點。並設置向右為1
HFMTable(node.right, "1", gitindex);
} else {
//為葉子節點就將其存入map集合中
yezijied.put(node.value, gitindex.toString());
}
}
}
/*
第三步:
@param nodes:已經存入list集合中的Node節點
創建字元串的哈夫曼樹結構
*/
public static Node HFMTree(List<Node> nodes){
//循環條件:節點數必須大於1.如果等於1就是一個節點(根節點),沒有分支
while (nodes.size()>1){
//排序list集合,根據權值(節點個數)從小到大排序
Collections.sort(nodes);
/*
創建一個二叉樹:
feiyezijied:根節點
nodeleft:左子節點
noderight:右子節點
*/
//得到權值最小的兩個節點.這兩個節點分別可看作左右兩個子節點
Node nodeleft = nodes.get(0);
Node noderight = nodes.get(1);
//創建新的Node對象:這可以想像為兩個葉子節點生成的根節點,
// 由於哈夫曼數的原理,需要編碼的值是葉子節點,而葉子節點上的父節點只是通過葉子節點虛擬創建的節點,
// 是為了形成一整顆完整的樹。所以它是沒有字元串原始值,,其可用兩個位元組的權值之和標記
Node feiyezijied=new Node(null,nodeleft.quanzhi+noderight.quanzhi);
//Node對象的左位元組點
feiyezijied.left=nodeleft;
//Node對象的右位元組點
feiyezijied.right=noderight;
//刪除原集合中的以使用的節點對象.即上面已經每次獲得的集合中兩個最小的節點
nodes.remove(nodeleft);
nodes.remove(noderight);
//將新創建的Node節點加入list集合中
nodes.add(feiyezijied);
//重新對list集合排序
Collections.sort(nodes);
}
//返回最終根節點
return nodes.get(0);
}
/*
第二步:
@param valus:傳入需要編碼的字元串,將其變成節點
將需要編碼的字元串,每個原始值(ASCIIM碼)以節點(Node)對象形式傳入list集合中。
而節點對象Node初始化了value與quanzhi,所以節點對象是包括這兩個值,所以將每個節點對象當作一個map.
設k=value、v=quanzhi
*/
public static List<Node> ListAndNode(String valus){
//將字元對象存入byte數組。
byte[] bytes = valus.getBytes();
//創建List集合
List<Node> nodes=new ArrayList<>();
//創建Map集合
Map<Byte,Integer> node=new HashMap<>();
//遍歷bytes數組,得到每個字元串的原始值
for (byte by:bytes){
//先試著通過傳入的第一個k獲取v
Integer index = node.get(by);
//如果map集合中此原始值對應的個數還沒有
if (index==null){
node.put(by,1);
}else {
node.put(by,index+1);
}
}
//遍歷map集合,並將每次遍歷的元素,以Node對象的形式存入list集合
for (Map.Entry<Byte,Integer> n:node.entrySet()){
nodes.add(new Node(n.getKey(),n.getValue()));
}
//最後返回此list集合
return nodes;
}
}
/*
第一步:
節點類:其本身可可看作一個概念性的二叉樹
Node對象本身可看作是一個二叉樹的根節點
實現Comparable介面:泛型規定此介面作用與此Node節點,說明此類是可排序的,通過' Collections.sort()'
*/
class Node implements Comparable<Node>{
Byte value; //原始值:字元本身的ASCIIM碼。因為一段字元串中有許多相同的字元,但相同字元卻對應這一個ASCIIM碼
int quanzhi; //此字元value在一段字元串中出現的次數
Node left; //Node對象看作是二叉樹的根節點,那麼這就是此二叉樹的左子節點
Node right; //Node對象看作是二叉樹的根節點,那麼這就是此二叉樹的右邊子節點
//構造器初始化 value 、quanzhi。
public Node(Byte value, int quanzhi) {
this.value = value;
this.quanzhi = quanzhi;
}
//重寫toString:因為我們需要拿到這兩個值
@Override
public String toString() {
return "Node{" +
"value=" + value +
", quanzhi=" + quanzhi +
'}';
}
//實現Comparable介面中的方法:手動設置排序規則
@Override
public int compareTo(Node o) {
//設置為通過權值從小到大排序
return this.quanzhi-o.quanzhi;
}
//前序遍歷
public void qxbl(){
//先輸出當前節點,也就是根節點
System.out.println(this);
//如果左子節點不是null節點,就遞歸遍歷輸出左子節點.null表示不是葉子節點
if (this.left!=null){
this.left.qxbl();
}
//同樣遞歸右子節點
if (this.right!=null){
this.right.qxbl();
}
}
}


