文本智慧較對大賽(百度&飛槳&蜜度)經驗分享(17/685)
- 2022 年 10 月 19 日
- 筆記
- Deep Learning, Python, 深度學習, 自然語言處理
引言
我之前參加了一個中文文本智慧校對大賽,拿了17名,雖然沒什麼獎金但好歹也是自己solo拿的第一個比較好的名次吧,期間也學到了一些BERT應用的新視角和新的預訓練方法,感覺還挺有趣的,所以在這裡記錄一下這期間學到的知識,分享一下自己的比賽過程,方案在此處://github.com/qftie/MiduCTC-competition 。這個賽題任務大概就是,選擇網路文本作為輸入,從中檢測並糾正錯誤,實現中文文本校對系統。即給定一段文本,校對系統從中檢測出錯誤字詞、錯誤類型,並進行糾正。
任務定義
系統/模型的輸入為原始序列\(X=(x1,x2,..,xn)\),輸出為糾錯後的序列 \(Y=(y1,y2,..,ym)\)X可能已經是完全正確的序列,所以X可能與Y相同。系統/模型需要支援多種粒度的序列,包括:字詞、短語、句子、短文。
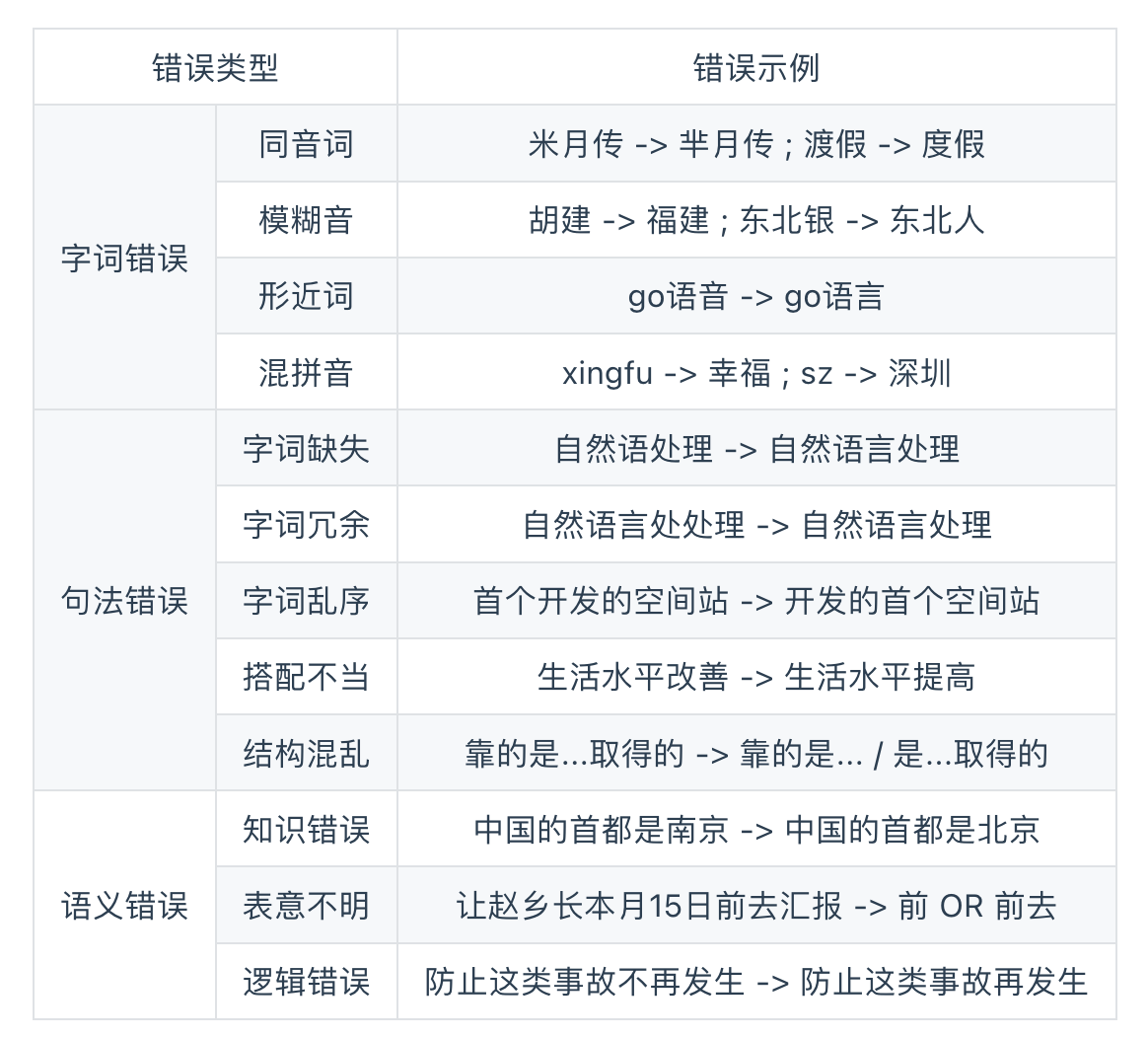
中文錯誤類型
一般包含三種,從字詞到語義錯誤,難度依次遞增
Soft-Masked BERT (ACL2020,字節跳動)
論文:Spelling Error Correction with Soft-Masked BERT
注意該模型只能處理輸入序列和輸出序列等長度的糾錯場景!

模型簡介:整個模型包括檢錯網路和改錯網路:
- 檢錯網路是一個簡單的Bi-GRU+MLP的網路,輸出每個token是錯字的概率
- 改錯網路是BERT模型,創新點在於,BERT的輸入是原始Token的embbeding和 [MASK]的embbeding的加權平均值,權重就是檢錯網路的概率,這也就是所謂的Soft-MASK,即 \(ei=pi∗e_{mask}+(1−p_i)∗e_i\) 。極端情況下,如果檢錯網路輸出的錯誤概率是1,那麼BERT的輸入就是MASK的embedding,如果輸出的錯誤概率是0,那麼BERT的輸入就是原始Token的embedding。
在訓練方式上採用Multi-Task Learning的方式進行,\(L=λ·L_c+(1−λ)·L_d\),這裡λ取值為0.8最佳,即更側重於改錯網路(Lc means correction)的學習。
模型結果:

該結果是句子級別的評價結果,Soft-MASK BERT在兩個數據集上均達到了新的SOTA,相比僅使用BERT在F1上有2-3%的提升。
該模型處理錯誤的情況,主要有以下缺點,模型沒有推理能力不能處理邏輯錯誤(語義錯誤),模型缺乏世界知識不能處理知識錯誤(地名等)
用MLM-phonetics糾錯
2021ACL中文文本糾錯論文:Correcting Chinese Spelling Errors with Phonetic Pre-training 論文筆記 – 知乎 (zhihu.com)
論文地址: paper
作者在論文中對比了MLM-base和MLM-phonetics的差異:
- MLM-base 遮蓋了15%的詞進行預測, MLM-phonetics 遮蓋了20%的詞進行預測。
- MLM-base 的遮蓋策略基於以下3種:[MASK]標記替換(和BERT一致)、隨機字元替換(Random Hanzi)、原詞不變(Same)。且3種遮蓋策略佔比分別為: 80% 、10%、10%。MLM-phonetics的Mask策略基於以下3種:[MASK]標記替換(和BERT一致)、字音混淆詞替換(Confused-Hanzi)、混淆字元的拼音替換(Noisy-pinyin)。且這3種遮蓋策略分別佔比為: 40%、30%、30%。
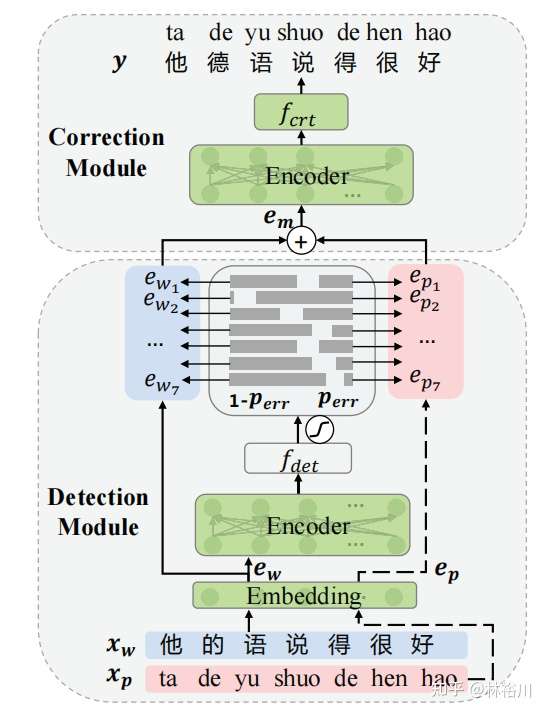
端到端文本糾錯包括Detection Module和Correction Module2個部分,具體如下圖所示,但官方沒有發布預訓練模型,paddle中提供了使用ernie1.0為backbone的模型:
GECToR
GECToR — Grammatical Error Correction: Tag, Not Rewrite | Papers With Code
Seq2Edit模型簡介:本文屬於seq2edit模型,Seq2Edit模型只有Encoder,將GEC任務看作是一個序列標註任務,在每個Time-Step預測生成一個編輯動作。通過使用預測得到的編輯動作對源文本進行轉化,我們便可以得到目標文本。屬於一種序列標註模型,通過預先定義一些編輯動作,採用神經網路為句子的token打上編輯標籤,從而進行語法糾錯。
目前較為常用的Seq2Edit模型有PIE、GECToR等。以2019年Awasthi等人的並行迭代編輯(Parallel Iterative Edit, PIE)模型為例,它們使用的編輯動作有:複製、刪除、增加、替換、變形等。其中,由於增加操作和替換操作需要在候選集中指定單詞,所以實際上包含多種編輯操作。總體而言,Seq2Edit模型的編輯空間遠遠小於Seq2Seq模型的辭彙空間,所以解碼空間小了很多。此外,非自回歸模型能夠並行解碼,速度優勢巨大,比如GECToR 5次迭代比NMT beam-size為1還快接近一倍,並且是當前的sota。
Token級別的變換
原理
比較兩個錯誤和正確句子的diff可以找到一系列編輯操作,從而把語法錯誤的句子變成語法正確的句子。為了給序列打標籤,可以把編輯映射到某個token上認為是對這個token的操作。如果同一個token需要進行多個編輯操作,則需要採用迭代的方法給序列打標籤。

比如上圖的例子,紅色的句子是語法錯誤的句子:」A ten years old boy go school」。
- 先經過一次序列打標籤,找到了需要對ten和go進行操作,也就是把ten和years合併成ten-years,把go變成goes。注意:這裡的用連字元」-「把兩個詞合併的操作定義在前面的Token上。
- 接著再進行一次序列打標籤,發現需要對ten-years和goes進行操作,把ten-years變成ten-year然後與old合併,在goes後面增加to。
- 最後一次序列打標籤在school後面增加句號」.」。
變換
上述的編輯操作被定義為對某個Token的變換(Transform),如果詞典是5000的話,則總共包含4971個基本變換(Basic Transform)和29個g-變換。
基本變換
基本變化包括兩類:與Token無關的和與Token相關的變換。與Token無關的包括\(KEEP(不做修改)、\)DELETE(刪除當前token)。與token相關的有1167個\(APPEND_t1變換,也就是在當前Token後面可以插1167個常見詞t1(5000個詞並不是所以的詞都可以被插入,因為有些詞很少會遺漏);另外還有3802個\)REPLACE_t2,也就是把當前Token替換成t2。
g-變換
前面的替換隻是把當前詞換成另一個詞,但是英語有很多時態和單複數的變化,如果把不同的形態的詞都當成一個新的詞,則詞的數量會暴增,而且也不利於模型學習到這是一種時態的變化。所以這裡定義了g-變換,也就是對當前Token進行特殊的變換。完整的g-變換包括:
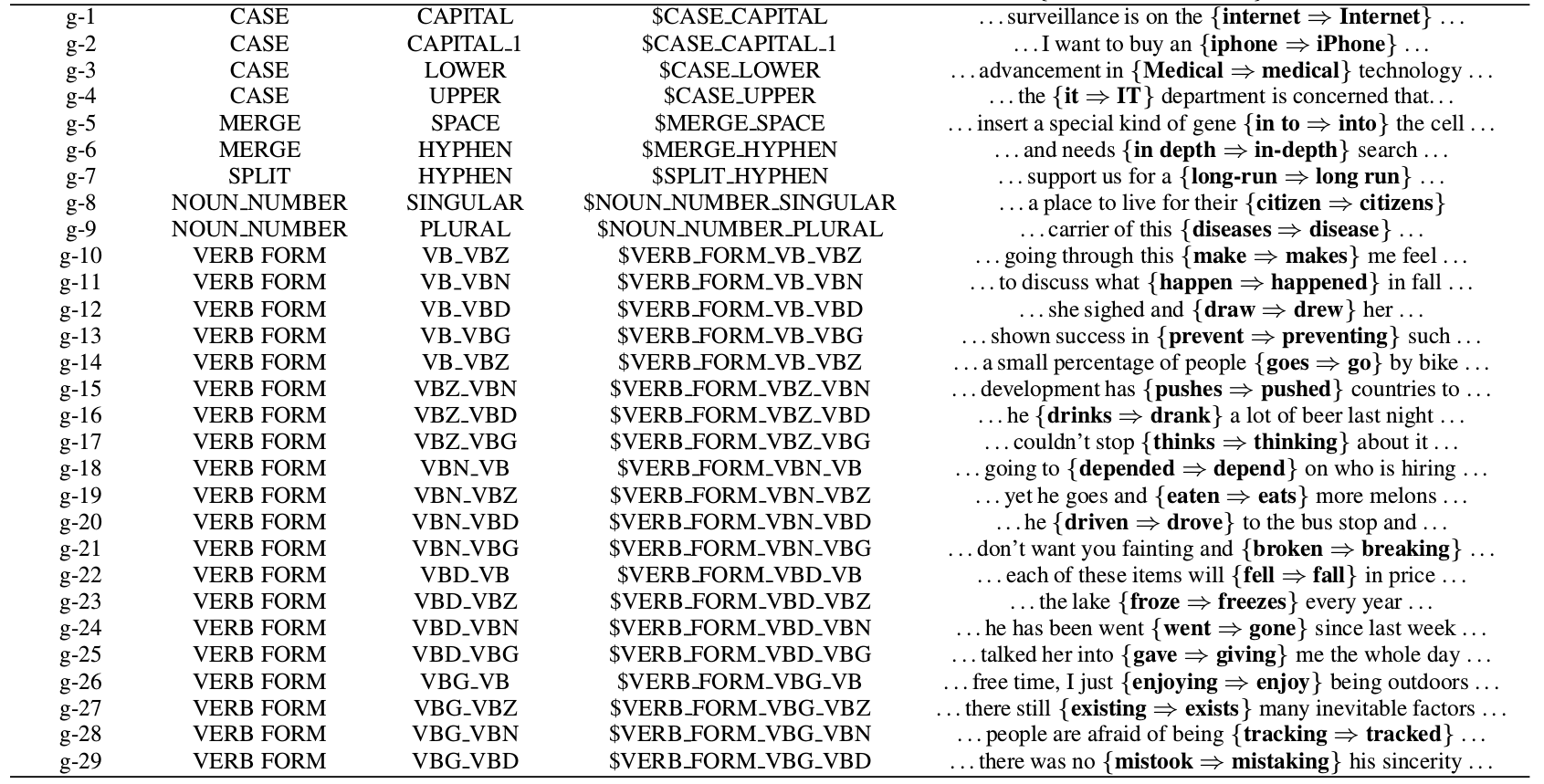
- CASE類的變化包括字母大小寫的糾錯,比如$CASE_CAPITAL_1就是把第2(下標0開始)個字母變成對象,因此它會把iphone糾正為iPhone。
- MERGE把當前Token和下一個合併,包括MERGESPACE和MERGESPACE和MERGE_HYPHEN,分別是用空格和連字元」-「合併兩個Token。
- SPLIT $SPLIT-HYPHEN把包含連字元的當前Token分開成兩個
- NOUN_NUMBER把單數變成複數或者複數變成單數。
- VERB_FORM動詞的時態變化,這是最複雜的,我們只看一個例子。比如VERB_FORM_VB_VBZ可以把go糾正成goes。時態變換使用了word forms提供的詞典
預處理獲得訓練數據
我們的訓練數據只是錯誤-正確的句對,沒有我們要的VERB_FORM_VB_VBZ標籤,因此需要有一個預處理的過程把句對變成Token上的變換標籤。
1 token映射
把源句子(語法錯誤句子)的每一個Token映射為目標句子(語法正確句子)的零個(刪除)、一個或者多個Token。比如」A ten years old boy go school」->」A ten-year-old boy goes to school.」會得到如下的映射:
A → A
ten → ten, -
years → year, -
old → old
boy → boy
go → goes, to
school → school, .
這是一種對齊演算法,但是不能直接用基於連續塊(Span)的對齊,因為這可能會把源句子的多個Token映射為目標句子的一個Token。我們要求每個Token有且僅有一個標籤,所以這裡使用了修改過的編輯距離的對齊演算法。這個問題的形式化描述為:假設源句子為\(x_1,…,x_N\),目標句子為\(y_1,…,y_M\),對於源句子的每一個Token \(x_i(1≤i≤N)\),我們需要找到與之對齊的子序列\(y_{j_1},…,y_{j_2}\),其中\(1≤j_1≤j_2≤M\),使得修改後的編輯距離最小。這裡的編輯距離的cost函數經過了修改,使得g-變換的代價為零。
2 找出token變換
通過前面的對齊,我們可以找到每個Token的變換,因為是一對多的,所以可能一個Token會有多個變換。比如上面的例子,會得到如下的變換:
[A → A] : $KEEP
[ten → ten, -]: $KEEP, $MERGE_HYPHEN
[years → year, -]: $NOUN_NUMBER_SINGULAR, $MERGE_HYPHEN
[old → old]: $KEEP
[boy → boy]: $KEEP
[go → goes, to]: $VERB_FORM_VB_VBZ, $APPEND_to
[school → school, .]: $KEEP, $APPEND_{.}
3 保留一個變換
只保留一個變換,因為一個Token只能有一個Tag。但是有讀者可能會問,這樣豈不是糾錯沒完全糾對?是的,所以這種演算法需要多次的迭代糾錯。最後的一個問題就是,多個變換保留哪個呢?論文說優先保留KEEP之外的,因為這個Tag太多了,訓練數據足夠。如果去掉KEEP還有多個,則保留第一個。所以最終得到的標籤為:
[A → A] : $KEEP
[ten → ten, -]: $MERGE_HYPHEN
[years → year, -]: $NOUN_NUMBER_SINGULAR
[old → old]: $KEEP
[boy → boy]: $KEEP
[go → goes, to]: $VERB_FORM_VB_VBZ
[school → school, .]: $APPEND_{.}
模型結構
類似BERT的Transformer模型,加兩個全連接層和一個softmax。根據不同的Pretraining模型選擇不同的subword切分演算法:RoBERTa使用BPE;BERT使用WordPiece;XLNet使用SentencePiece。因為我們需要在Token上而不是在subword進行Tag,因此我們只把每個Token的第一個subword的輸出傳給全連接層。
迭代糾錯
前面介紹過,有的時候需要對一個Token進行多次糾錯。比如前面的go先要變成goes,然後在後面增加to。因此我們的糾錯演算法需要進行多次,理論上會一直迭代直到沒有發現新的錯誤。但是最後設置一個上限,因此論文做了如下統計:
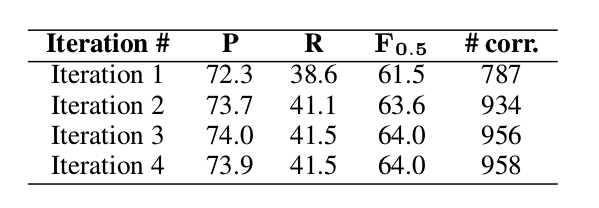
基本上兩次迭代就能達到比較好的效果,如果不在意糾錯速度,可以到三次或者四次。
實驗
3-stage training
本文中,訓練分為三個階段:在合成數據上的Pretraining;在錯誤-正確的句對上的fine-tuning;在同時包含錯誤-正確和正確-正確句對數據上的fine-tuning。
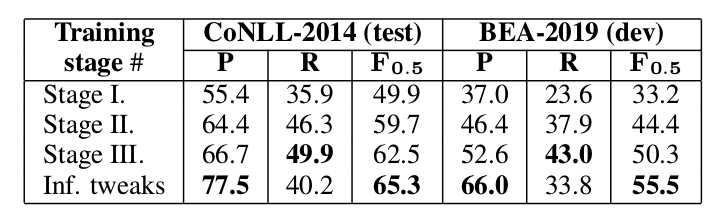
有第三步讓模型看懂一些沒有語法錯誤的句子是很重要的,實驗也說明第三步使得結果好了很多;最後一行表示加上一些推理的trick,具體如下
推理的trick
- 給$KEEP增加一個bias
- 因為大部分的句子錯誤較少,而訓練時錯誤的卻居多,所以要給它加一個bias
- 增加最小的錯誤概率閾值
- 因為模型會盡量糾錯,即使概率很少。這裡增加一個句子基本的概率值,如果小於它則不糾錯。
這兩個值是使用驗證集找到的。從上圖的結果可以看出,使用了推理trick後效果提升不少。
預訓練模型
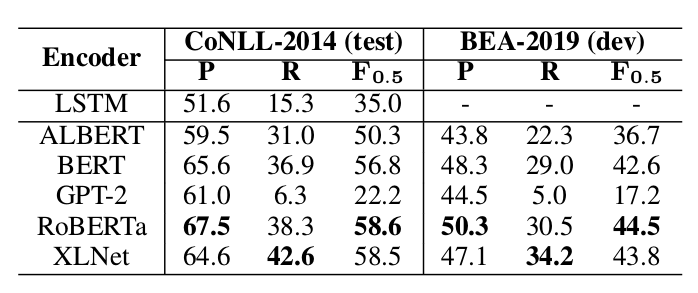
RoBERTa和XLNet比較好,GPT-2和ALBERT較差,文章認為因為是生成模型
性能提升技術
重排序 TODO
與其它集成在模型內部的性能提升手段不同,重排序(Reranking)更像是模型預測完成之後的一個獨立的階段,所以它被稱為一種後處理方法(post-training)。它的目的主要是為了解決:模型預測得分最高的結果,往往並不是最好的結果。
它的主要做法是:將GEC模型輸出的N個最好的結果作為候選集,使用一些在GEC模型中無法被很好地覆蓋但卻又較為重要的特徵,對這N個最好結果進行重新排序,選取得分最高的結果作為最終的預測結果。
通過使用重排序方法,我們可以引入豐富的語言學知識,考慮更多全局的特徵,還能集成多個GEC模型的輸出一起重排序。
常用的重排序特徵有:1)語言模型得分;2)編輯距離特徵;3)句法特徵。
模型集成 TODO
模型集成(Model Ensemble)也是當下最為常用的性能提升手段之一,它的做法主要有:1)在Beam-Search解碼階段,將多個模型的輸出取平均;2)在輸出預測結果階段,採用多模型投票的方式確定編輯操作等。
迭代糾正
同人類一樣,機器對一個句子進行語法糾錯往往也無法一次就找到所有的錯誤,所以,迭代糾正(Iterative Correction)的思想應運而生。這一方法的主要思想是:對一個含有語病的句子進行多輪糾錯,直到評判句子正確程度的某種指標達到指定的閾值。比較典型的一個例子是微軟亞洲研究院在2018年提出的Fluency Boosting模型。
修改損失函數
一種更直接的性能提升方式,是修改模型的損失函數。
例如:GEC任務中,輸出結果的大多數Token與輸入文本是相同的,並不重要,而那些產生了差異的Token理應受到更多的關注,所以我們應該提升這些產生差異的Token在損失函數中所佔的權重,才能讓模型更好地捕捉資訊。
數據增強
人工生成的平行語料主要有兩種使用方式:1)直接與真實數據集相合併,一起進行訓練;2)先使用人工平行語料對模型進行預訓練,再將預訓練的模型使用真實數據集進行微調。由於人工數據的分布往往與真實數據不一致,所以將人工數據用於預訓練階段能夠收穫更好的性能,當下絕大多數基於神經網路的GEC模型都採用這一方式。
噪音生成
噪音生成的思想來自於預訓練階段常用的降噪自編碼器(DAE)。例如:猿輔導研究院的Wei Zhao等人提出採用隨機製造錯誤數據的方法來構建偽數據,具體流程如下:按照10%的概率隨機刪除一個詞;按照10%的比例隨機增加一個詞;按照10%的比例隨機替換一個詞;對所有的詞語序號增加一個正態分布,然後對增加正態分布後的詞語序號進行重新排序後得到的句子作為錯誤語句。
噪音生成的具體做法有很多,目前比較好的方法是預先統計真實數據里各類型錯誤的分布及概率,再根據這一分布生成噪音,從而使人造數據儘可能地接近真實數據地情況。
通過將加入噪音的句子糾正回原本的句子,我們可以以一種無監督的方式對模型進行預訓練,這種做法即為降噪自編碼器,能有效提升模型性能。(這種方式有些類似PERT的做法,即打亂正常語序的句子而非【MASK】,讓語言模型學會重新生成正確的句子)
比賽思路分享
模型
以GECToR作為baseline模型,我的方案主要是在賽題的baseline上進行更改,可參考GECToR論文和GECToR源程式碼
backbone則替換為了hfl/chinese-macbert-base
訓練說明
該模型訓練按GECToR的論文所述,嘗試兩個stage和三個stage的訓練方法,由於驗證下來兩個stage顯著優於只用偽數據訓練,而三個stage相對兩個stage提升不大,所以選擇了兩個stage的訓練方式。
Stage1
第一個stage先在100w條樣本的偽數據上進行訓練,將訓練得到的在preliminary_val.json上效果最優的權重作為stage2的預訓練權重。這裡直接將第一個stage訓練得到的權重等文件保存在pretrained_model/ch_macbert_base_epoch5,step1,testf1_39_41%,devf1_67_26%,方便stage2的調用。
Stage2
第二個stage使用pretrained_model/ch_macbert_base_epoch5,step1,testf1_39_41%,devf1_67_26%作為預訓練權重,使用合併的初賽和決賽數據合併的data/final_train_fusion_stage2_3.json數據集,分為十折來進行訓練和驗證,最後選取的是驗證集表現最好的兩組權重平均考慮其預測,生成最後得分Fscore=51.89的提交文件。
調優和trick搜索
trick
在a榜b榜的提交過程中嘗試了不同的trick均未有明顯提升所以最後沒有使用其他trick(嘗試過的trick有迭代糾錯、使用detect輸出判斷整句話是否有錯,如果最大檢錯概率小於一定的閾值則認為該句沒有出錯直接跳過,測試記錄可見提交結果記錄文檔)
backbone
在stage1嘗試過roberta-base、macbert-base、pert-base、macbert-large,調優後發現macbert-base效果較好,個人覺得應該是因為macbert預訓練就是使用了錯字或者span替換等策略和gec中出現最多的錯誤類似,pert則是使用的語序打亂復原的預訓練方式,可能對於亂序的錯誤的錯誤更有效果,也有考慮融合不同模型的優勢,但由於時間問題沒有嘗試,但不清楚為什麼large大模型反而效果更差,也許是因為沒有足夠的計算資源嘗試lr調優
參考:
ERNIE for CSC:【的、地、得】傻傻分不清?救星來了! – 飛槳AI Studio (baidu.com)
(4 封私信 / 8 條消息) 目前NLP中文文本糾錯(錯別字檢索,修改)有什麼研究? – 知乎 (zhihu.com)
文本糾錯的論文看這一篇就夠了 – 知乎 (zhihu.com)
競賽大神易顯維:帶你深度認知校對問題_嗶哩嗶哩_bilibili
語法糾錯進展綜述 | HillZhang的部落格 (gitee.io)
//fancyerii.github.io/2020/06/15/gector/


