Redis高可用之主從複製原理演進分析
- 2022 年 10 月 12 日
- 筆記
- [02]redis-memcached, Redis, 原理
Redis高可用之主從複製原理演進分析
在很久之前寫過一篇 Redis 主從複製原理的簡略分析,基本是一個筆記類文章。
一、什麼是主從複製
1.1 什麼是主從複製
主從複製,從名字可以看出,至少需要 2 台 Redis 伺服器,一台叫主 Redis 伺服器,一台叫從 Redis 伺服器,也可以把他們叫做主節點(主 Redis 伺服器)從節點(從 Redis 伺服器)。然後把主 Redis 伺服器上的數據複製到從 Redis 伺服器上,這就是主從複製。後續也會源源不斷的把數據從主節點複製到從節點。
1.2 怎麼設置主從複製
怎麼設置主 Redis 伺服器,怎麼設置從 Redis 伺服器?
比如有 2 台 Redis 伺服器,ip 分別為:192.168.1.100 和 192.168.1.101。
- 第一種方法
設置方法:在 Redis 的配置文件 redis.conf 中配置:replicaof masterip masterport
比如將 192.168.1.100 這台伺服器設置為主(master)伺服器,那麼就在伺服器 192.168.1.101 的配置文件里設置如下:
replicaof 192.168.1.100 6379
然後重啟伺服器,這樣主伺服器就是 192.168.1.100,從伺服器就是 192.168.1.101。
- 第二種方法
還可以用 redis-cli 客戶端連接到 192.168.1.101,然後執行命令 replicaof 192.168.1.100 6379。
這種方式如果從 Redis 重啟後,主從關係就消失了。
- 第三種方法
在 redis-server 啟動參數中增加 --replicaof 192.168.1.100 6379 參數
說明:Redis 5.0 後,replicaof 命令已經替換了 slaveof 命令,但是為了兼容 slaveof 還是可以用。
一台主伺服器也可以有多台從伺服器,從伺服器也可以有從伺服器。
二、為什麼要主從複製
主從複製後就有多份數據,相當於有多個副本,既是備份也是容災。
為什麼要有主從複製功能?
其實問的就是 Redis 主從複製有什麼作用,帶來了啥好處。
- 負載均衡
數據量大的時候,為了減輕伺服器壓力,會用讀寫分離模式來分攤流量,主伺服器負責寫,從伺服器負責讀。當然主伺服器也可以讀。
- 故障恢復
主伺服器出現問題時候,從伺服器還可以繼續提供服務。並且也可以把從伺服器提升為主伺服器,這就是 Redis 的哨兵模式。
高可用的數據冗餘方式。
- 數據冗餘
多了一份數據,故障了,就可以快速恢複數據。
三、怎麼進行主從複製
主從數據同步就是把主伺服器生成的 RDB 數據文件複製到從伺服器上,然後解析 RDB 文件,在從伺服器上生成對應的數據。或同步相關的命令。
3.1 主從複製同步的演進
在 Redis2.8 之前,都是全量數據複製。也就是說,斷線重連後,也是重新全量複製數據。這種方式把很多原來同步過了的數據又重新同步一次,這種方式的數據同步效率太低。
在 Redis2.8 之後,增加了部分重同步模式,也就是增加增量數據同步,只同步需要同步的數據。這就改進了之前的數據同步模式。
什麼時候進行全量數據同步?第一次數據同步時候就進行全量數據同步。有時主從數據不一致時也需要全量同步。
什麼時候進行增量數據同步?比如斷線重連後,就進行增量數據同步。
3.2 Redis2.8之前複製
Redis2.8 之前主從同步有 2 個部分:全量同步,命令傳播。
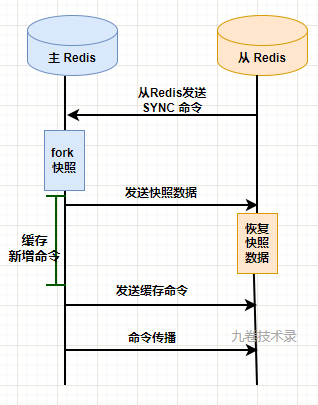
全量同步:主從節點建立連接,主節點回復後,從節點向主節點發送 SYNC 命令,把從節點伺服器狀態更新到當前主節點伺服器狀態。主節點創建全量數據的 RDB 快照文件,然後發送給從節點,從節點載入 RDB 文件恢復對應的數據。主節點再繼續發送複製過程中積壓在緩衝區內的新增命令到從節點,使從節點的數據到達和主節點數據一致。
命令傳播:主節點和從節點保持連接,主節點將繼續向從節點發送命令流,保證主節點上的數據集發生了變更同樣在從數據集上也發生變更。
流程圖:
3.3 Redis2.8之後複製
以 redis6.0 版本來介紹。
Redis2.8 之後全量複製與上面(Redis2.8之前)複製步驟差不多,SYNC 命令變成了 PSYNC 命令,之後增加了部分重同步。部分重同步改進了之前的每次需要全量同步問題。
增加了部分重同步,這個要怎麼做才能兼容之前的全量同步呢?怎麼知道從庫複製到哪兒了?第一個從庫肯定要記錄下從庫複製到哪兒了,下次斷線重連時就可以告訴主庫該從哪個地方開始複製了。主庫也要記錄自己的一些複製資訊。Redis 用了幾個概念就把這些問題給解決了,Replication ID,offset,replication_backlog。
- Replication ID:複製 ID。這是一個較大的隨機字元串,標記一個給定的數據集。每個主節點都會用這個 Repli ID 來標識內部數據集,從節點 ID。當從節點加入時,這個 repli id 就初始化了。
- offset:複製偏移量。每個主節點都有這個 offset 偏移量,主節點將自己產生的數據發送給從節點時,發送多少位元組數據,自身 offset 就會增加多少。從節點也有自己 offset,從節點寫入數據時,offset 也會增加。斷線重連時,就可以知道從哪裡開始同步了。offset 需配合下面的複製積壓緩衝區工作。
- replication_backlog:複製積壓緩衝區。它是在主節點上的一個環形緩衝區,用來存儲主節點向從節點傳遞的命令。它是大小固定,存儲的命令有限,所有超出了就會刪除。從節點進行增量同步時,主節點會根據 offset 從 replication_backlog 中拷貝從節點缺失的數據到從節點。
Replication ID, offset,這一對來標識數據集版本。
Redis2.8之後就是用上面這幾個概念實現部分數據重同步的。從節點發送主節點的 replid 和從節點的一個 offset,主節點拿到這個replid 和自己的 replid 比較,如果是一樣,並且這個 offset 也在 backlog 中能找到,那就可以可以進行部分重同步。
全量複製步驟
- 主從節點先建立連接
建立連接後,從節點使用命令 PSYNC <replid> <offset> 向主節點發起同步請求。如果主從節點是第一次複製,那麼命令為 PSYNC ? -1,replid 為 ?,因為是第一次複製不知道主庫的 replid。offset 為 -1,表示第一次複製。
主節點收到 PSYNC 命令後,會用 FULLRESYNC 命令響應,帶上主節點的 replid 和 offset 返回給從庫,從庫會記錄下這兩個參數。便於以後判斷是否需要部分重同步。
- 同步數據
主節點執行 bgsave 命令生成 RDB 文件,生成完後把文件發送給從節點,從節點載入 RDB 文件。這個過程中,主節點不會阻塞,依然會接收客戶端的命令請求,當然,這些請求不會寫在之前的 RDB 文件里,為了保持主從數據一致,這些命令會存儲在 replication buffer 中,記錄 RDB 文件後的所有寫操作。
- 同步緩衝的命令數據
協商就是根據先前定義好步驟來發送相關命令,為同步做準備工作。有點協議的意思。步驟如下:
當主庫把 RDB 文件傳送給從節點完成後,就會把 replication buffer 中的寫命令操作發送給從節點,從節點執行這些操作命令,主從節點同步完成。
- 命令傳播
之後會繼續向從節點發送主節點的操作命令,從節點執行這些命令,保持主從數據的一致。
上面是一個主體的同步步驟,更加詳細的步驟要分析源碼了。
發送步驟與 Redis2.8 之前全量同步沒有多大區別。
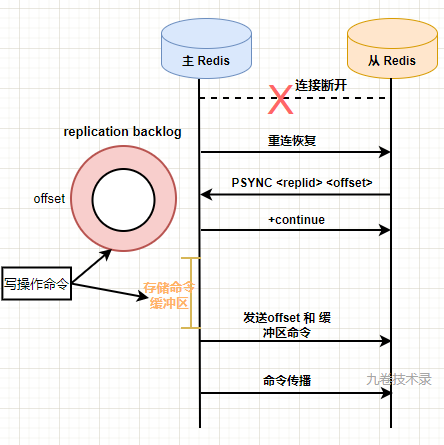
部分數據同步
部分數據同步,解決的是主從節點在同步命令時候,網路斷了在連上時,Redis2.8 之前會在全量同步數據,顯然開銷太大,不合理。能不能只把斷線後的數據同步一份,而不是全量同步?
網路斷線後,就有部分命令數據沒有同步到從節點上去,那我們能不能保存這部分命令數據?重連後,將斷開期間的這部分命令重新同步給從節點,這樣就不需要全量同步。
Redis2.8 之後引入了 replication_backlog 複製積壓緩衝區,前面有講到這個概念。命令一方面會傳輸給從節點,另外還會記錄在這個複製積壓緩衝區里。Redis 使用一個環形緩衝區的結構保存最近的一些命令。在緩衝區中,對位元組進行編號,這個編號在 Redis 中叫複製偏移量。

是否部分同步條件?
- 從節點 replid 和 主節點的 replid 相同
- 複製偏移量 offset 在複製積壓緩衝區的 backlog_off 和 offset 範圍之間。
如果滿足上面的 2 個條件,就進行部分數據重同步。
四、Redis4.0的同源增量同步
先看兩個問題
1.從節點重啟後丟失了原主節點的節點編號和複製偏移量,這導致重啟後需要全量複製,這個很好辦,把這些資訊保存下來
2.主從切換後,主節點資訊變化了,導致從節點需要全量數據同步,這個也好辦,只要能確認新主節點數據是從原主節點複製過來就可以了
Redis4.0 後,對 PSYNC 進行了改進,提出了同源增量複製解決方案,來解決上面提到的兩個全量複製問題。
第1個:從節點重啟後,需要跟主節點全量數據同步,為什麼?本質原因,是從節點丟失了主節點的編號資訊和偏移量資訊。Redis4.0後,就把主節點的編號資訊寫入到 RDB 中持久化保存。
第2個:主從切換後,從節點需要和主節點全量同步,為什麼?原因就是新的主節點不認識原來主節點的編號資訊。切換後怎麼才能識別到呢?Redis4.0 後,主從切換後,新的主節點會將先前的主節點資訊記錄下來,這樣新主節點就知道自己原先數據是從哪箇舊主節點同步來的,大家都是從同一個地方出來的,應該接受部分數據同步策略。
五、Redis6.0無盤同步複製
什麼叫無盤?
原先的同步複製是通過 fork 一個子進程生成 RDB 快照文件,RDB 存儲在磁碟上,然後傳輸 RDB 文件,從節點伺服器在恢復 RDB 文件數據。
無盤,就是說不生成 RDB 文件,不通過 RDB 來傳輸數據。而是直接通過網路來傳輸數據。
怎麼做到無盤呢?
Redis6.0 後,它也是先 fork 一個子進程,這個子進程 dump 數據,它通過管道回寫給主節點,主節點在將數據發送給從節點,這樣的過程就是無盤傳輸。
六、Redis7.0共享複製緩衝區
6.1 多從庫時主庫佔用記憶體過多問題
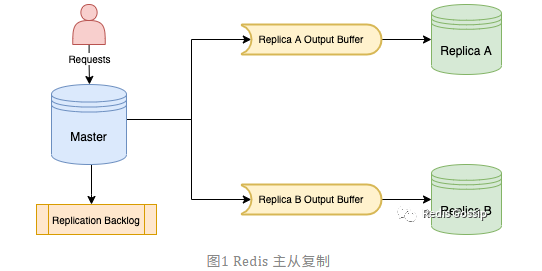
(from: //mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT)
如圖所示,對於 Redis 主庫,當用戶的寫請求到達時,主庫會將變更命令分別寫入所有從庫的緩衝區(OutputBuffer),以及複製積壓緩衝區(ReplicationBacklog)。全量同步也會執行該邏輯。所以在全量同步階段經常會觸發 client-output-buffer-limit,主庫斷開與從庫的連接,導致主從同步失敗,甚至出現循環持續失敗的情況。
所有從庫的連接在主庫上是獨立的,也就是說每個從庫 OutputBuffer 佔用的記憶體空間也是獨立的,那麼主從複製消耗的記憶體就是所有從庫緩衝區記憶體大小之和。如果我們設定從庫的 client-output-buffer-limit 為 1GB,如果有三個從庫,則在主庫上可能會消耗 3GB 的記憶體用於主從複製。另外,真實環境中從庫的數量不是確定的,這也導致 Redis 實例的記憶體消耗不可控。
from: //mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT
6.2 OutputBuffer 拷貝和釋放的堵塞問題
- ReplicationBacklog 的限制
- OutputBuffer 拷貝和釋放的堵塞問題
具體內容請看這裡://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg
6.3 解決方案:共享複製緩衝區
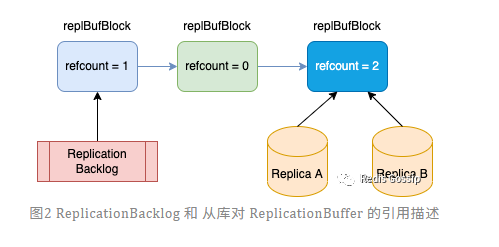
具體方案請看這裡://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT
七、參考
- //redis.io/docs/manual/replication/ redis 複製功能
- //mp.weixin.qq.com/s/a4JTKKTCEyz1W0FIF5fVZA Redis 主從複製的演進歷程與百度實踐 – 百度
- //mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg Redis 7.0 共享複製緩衝區的設計與實現-ShooterIT
- 《Redis設計與實現》


