JAVA SE 基礎總結
§ 基礎知識
一、程式組織與運行原理
1.1 程式組織
一個 JAVA 程式文件中主要由如下幾部分構成:
-
package 聲明
-
public 類:public 類與類文件名相同,因為其是作為該類文件唯一對外介面,所以需要唯一代表該類文件。
-
main 方法
一個帶有包結構的 .java 文件以如下結構組織
package .... // 具有包結構時才需要聲明,且聲明必須放在第一行
import .... // 當使用了其他包的類時需要聲明
public class NameOfClass{
public static void main(String[] args){
// 主方法體
}
}
在 JAVA 中,萬物皆對象,所以每個 *.java 文件都是由一個類構成,我喜歡將其稱為 類文件 ,一個類文件作為一個 編譯單元 / 編輯單元 存在。
一個 *.java 有如下幾個限制:
-
一個
*.java文件只允許有一個 public class:這是為了給類裝載器提供方便。同時,從設計思想的角度來說,一個文件實現一組相關的功能,並封裝同時對外暴露一個介面即可,也 -
一個
*.java文件允許有許多個 class:實現一個功能可能不僅靠一個類就能完成,所以允許在一個類文件中定義其它的類。在編譯時,每個單獨的類都會生成一個單獨的*.class文件;出於工程管理和設計思維:
通常不會這麼做,一般一個類文件都只應該包含一個對外介面,如果需要定義和使用其他的類,通常都會在 public class 中使用內部類,內部類在編譯時不會生成一個單獨的
*.class文件,而是如下存在( Ttt 時 Demo01 的內部類 )。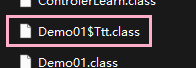
為每個
.java文件中只配備一個同名的頂級 public class 更加方便工程管理,因為這樣直接從文件名就能直接知道這個文件能做什麼。而不會因為在其中定義了其他類而導致文件混亂。需要實現其他功能的內部類應當定義在該 public class 中,輔助該public class 完成功能構建,而不是單獨獨立於 public class。單獨獨立於 public class 的類能被其他
*.java文件訪問,這樣破壞了封裝。 -
一個
*.java文件可以不必須包含 public class; -
main 方法必須由 public static 修飾,但其並不一定存在於 public class 中(不過通常不推薦這麼做)。且
*.java文件並不一定需要包含 main 方法,只是其如果不包含則無法執行罷了。

(以上僅限於本人對該部分的思考和理解,並不一定完全正確,歡迎大家討論。)
1.2 包結構
個人理解,包應當作為一系列相關功能的類文件(*.java)的集合,這些類共同構成一個相對較大的問題的解決方案。例如 java.utils.* 就是對一組編程過程中常常需要的功能分成各個類進行實現,並進行了打包。
包也是作為庫的單元,一個庫由一系列功能相關的 *.java 文件組成,編譯後生成一組對應同名的 *.class 文件,由 JAVA 提供的 jar 工具打包,封裝並壓縮到 *.jar 文件中。JAVA 解釋器負責對這些文件的尋找、裝載和解釋。[1]
1.2.1 使用規範
-
在文件開頭聲明文件屬於的包
-
包名使用域名倒置(因為域名是唯一的),保證了唯一性
1.2.2 關於 classpath 和 jar[2]
什麼是 classpath ?
classpath 是 JVM 用到的一個環境變數,用於指示 JVM 如何搜索 class
JVM 真正執行的是 .class 文件中的位元組碼。所以,JVM 需要在執行的時候知道上哪去搜索程式碼所需要的對應類,即上哪去找 *.class 文件。
通常情況下,JVM 搜索 abc.xyz.Hello 這個類會以如下路徑搜索類:
-
<當前目錄>\abc\xyz\Hello.class (默認)
-
C:\Work\project1\bin\abc\xyz\Hello.class
-
C:\shared\abc\xyz\Hello.class
一旦搜索到,就停止繼續向下搜索。
當然,也可以在啟動 JVM 時設置 classpath ,如:
java Hello -cp .;path\to\Class;...
什麼是 jar ?
jar 包就是對一組 .class 文件按照 package 的目錄層級進行打包,封裝壓縮。
在使用時可以直接導入 jar 包,直接使用其中的 .class ,運行在 JVM 上
1.3 從 .java 到 運行[3]
該部分主要從 文章[3:1] 進行參考,這篇文章寫的非常清晰,值得一讀。本人是個初學者,為了筆記,大致記錄一下文章的關鍵部分。
從 .java 到運行中間經歷如下三個階段:
-
編譯:主要將
.java變為.class,使得 JVM 可以載入。 -
載入:JVM 將需要運行的類裝載進入記憶體,並分配空間和初始化
-
解釋:將位元組碼文件解釋為指令碼,使其調用硬體指令進行執行
3.1 編譯階段[3:2]
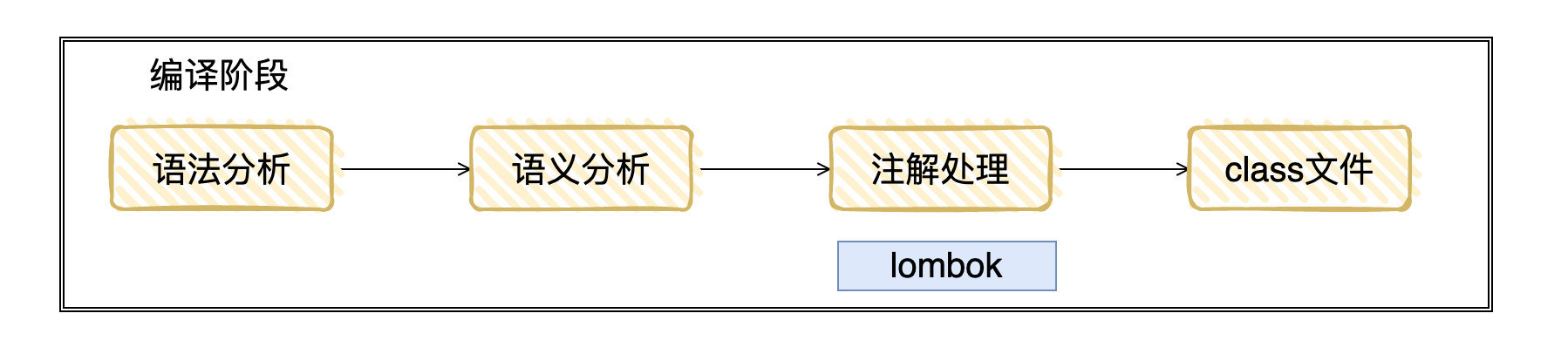
.java 文件通過編譯階段,變為 .class 文件的位元組碼,位元組碼能在 JVM 中運行,而 JVM 是我們能夠跨平台運行的保證。
3.2 載入階段[3:3]
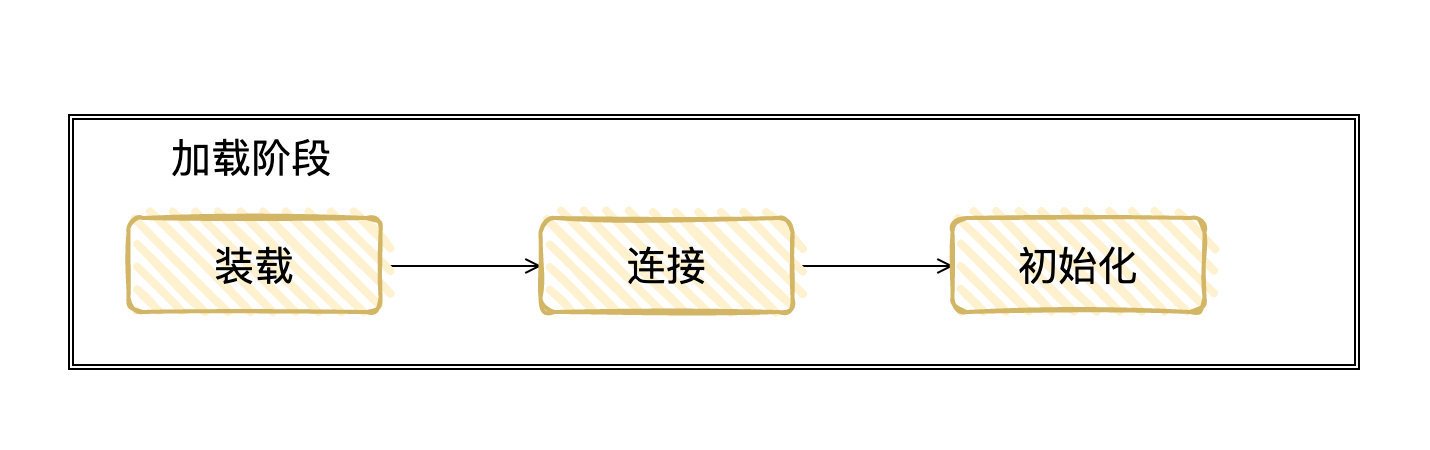
首先是裝載:
java 是懶裝載機制,並不會一次性將所有的類都裝在進 JVM 中,而是在該類被用到時才會被裝載。
裝載階段可以總結為:查找並載入類的二進位數據,在JVM「堆」中創建一個java.lang.Class 類的對象,並將類相關的資訊存儲在 JVM「方法區」中
然後是連接:
對 class 的資訊進行驗證,並且為 類變數 分配記憶體空間並對其賦默認值
最後是初始化:
為類的靜態變數賦予正確的初始值。
3.3 解釋階段[3:4]
解釋階段分為兩種:直接解釋 和 編譯解釋
JVM 會對「熱點程式碼」做編譯,非熱點程式碼做解釋。
熱點程式碼:被頻繁執行的程式碼塊
二、數據結構
2.1 基礎數據結構
在 JAVA 中,數據被分為兩種類型:
-
基本數據類型:整型(byte,short,int, long)、浮點型(float,double)、布爾值(true,false);
-
引用類型:類、介面、數組。
引用類型指的是其在棧記憶體空間存放的並不是其數據,而是指向堆的地址。
2.1.1 類型轉換
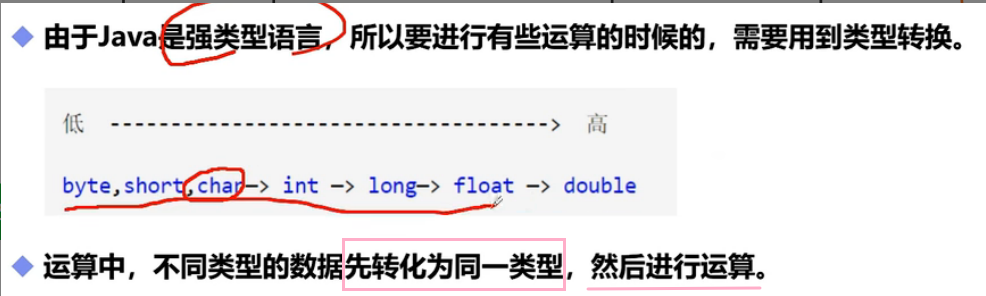
-
從 低 —–> 高 自動轉換;
-
從 高 —–> 低 需要手動強制轉換(強制轉換就是
(目標類型) 變數)。
看待類型轉換其實可以從思考記憶體的角度來理解:
-
小記憶體到大記憶體,系統發現現有空間不夠,重新為其開闢一個新的空間,並回收之前的空間即可,所以可以做到自動轉換。
-
而大記憶體到小記憶體,如果不手動進行強制轉換,系統在存數據的時候會發現現有記憶體空間夠用,發現不了什麼異常,就不管。但這樣會造成數據溢出,超過對於類型存的數據時,就會發生移位,這樣在記憶體中就超過了其類型可訪問範圍,那麼在取數時,按照對應類型的地址訪問範圍就會取得一個錯誤的數據。
2.2 數組
2.2.1 使用
數組的使用分為:聲明、創建、賦值。
聲明:dataType[] arrayName,這一步只是將 arrayName 這個變數壓入棧,但其並沒有具體的數值記憶體空間;
創建:new dataType[arraySize] ,這一步才真正開闢了一個對應類型的數據空間;
賦值:賦值就是將聲明的變數與創建的對象連接起來,使得聲明的變數指向所創建的對象。其形式有:
-
按元素賦值:
array[i] = value -
直接:
dataType[] araryName = new dataType[]{.....} -
或者:
dataType[] arrayName = {dataType1, dataType2, ......}
其實第二種和第三種在解釋成位元組碼後的形式是一樣的(通過看 .class 文件的反編譯知道的)。
2.2.2 多維數組
dataType[][] arrayName = new dataType[][]{ {}, {}, {} }
多維數組中除了最內層存的是實際的數據,外層全部存的是指向其下一層的地址。
三、流程式控制制
3.1 控制語句
主要控制語句就是:順序、循環、分支選擇
值得一提的就是 JAVA 對數組對象提供 for each 循環
3.2 邏輯封裝(方法)
方法就是為了解決一個小問題的有關控制語句和變數的集合。並沒有什麼很多值得說的,以下主要說一說方法中比較特別的幾個知識點:
3.2.1 重載
重載簡單來說就是相同方法名,不同參數列表的一系列方法。在執行的時候,會根據傳入的參數進行自動匹配對應的方法。
不同參數列表可以分為以下幾種:
-
參數類型不同
-
參數個數不同
-
不同參數類型的排列順序不同
以上三種不同單獨或者混合存在都能構成重載的條件。
3.2.2 可變長參數
在編寫程式時,我們有時候無法預知當前方法的參數個數,那麼可以使用可變長參數,在參數類型後加 ... :
void methodName(dataType... para)
在方法體中,para 以數組的形式被訪問。
限制:
-
一個方法至多只能有一個可變長參數;
-
如果存在可變長參數,那麼可變長參數只能放在參數列表的末尾位置。
3.2.3 命令行傳參
在我們使用 public static void main(String[] args){} 時,可以看到 main 方法是存在參數列表的,該參數由程式執行的時候傳入:
java someClass args1 args2 ....
參數以字元串的形式被傳入。
四、記憶體
JAVA 中的記憶體可以看成如下結構:
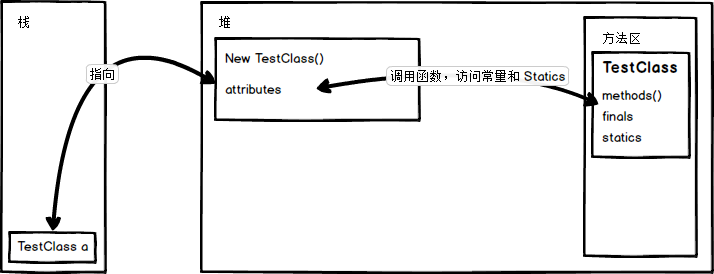
以 TestClass a = new TestClass() 在記憶體中的具體過程舉例:
最開始在需要用到這個類的時候,JVM 就將對應的類載入進了方法區。
第一步:TestClass a 生成了一個變數 a ,能指向具有 TestClass 類結構的對象(這裡用 TestClass 類結構的說法是為後面多態埋個坑);
第二步:在堆中開闢一個 TestClass 類大小的空間用於存放新實例化的對象,空間中需要存放屬於該對象的屬性(attributes)、以及類載入進方法區的地址,和對應方法的句柄,以便在調用時可以訪問到;
常量和 statics 是可以被對象共享的,且只載入一次,所以應該跟著類走,放在類所在的空間。
第三步:變數 a 指向開闢出來的這個空間的地址,即在變數 a 中存放堆中這個新 new 出來的對象的地址。
1. 堆
-
堆中存放 new 出來的對象和數組;
-
可以被所有執行緒所共享,不會存放別的對象引用;
2. 棧
-
存放基本變數類型(會包含基本變數類型的具體數值)
-
存放引用對象的變數(存放這個引用在堆中的具體地址)
3. 方法區
-
可以被所有執行緒所共享
-
包含了所有 class 和 靜態變數
§ 基礎抽象:面向對象
一、 封裝、繼承、多態
1. 封裝與訪問限制
1.1 封裝
思想:封裝就是將需要保護起來的變數和方法保護起來,不讓外界訪問,隱藏功能的實現細節,只暴露對應功能的介面,告訴使用者,你直接用我給你的這個方法即可,只要按照我的規矩用,你就能得到期望的結果。
具體做法:屬性私有,不需要暴露的方法私有。即使用 private 關鍵字控制訪問許可權。
1.2 訪問限制
public(任意):任意位置都可以訪問;
protected(父子):只有本身和具有繼承關係的類內部可以訪問,不同包的子類可以繼承父類中 protected 修飾的變數和方法;
default(同包):只有在同一個包中的才具有訪問資格,出了包,就算具有繼承關係的子類,也不能訪問,因為只有在同一個包中的子類才能繼承 default 修飾的變數;
private(本類):只能被在該類的內部被訪問到,出了{}就不能被訪問。
2. 繼承
JAVA 不支援多繼承!!!
繼承的記憶體本質是子類指向父類(最頂級的 object 類省略了):
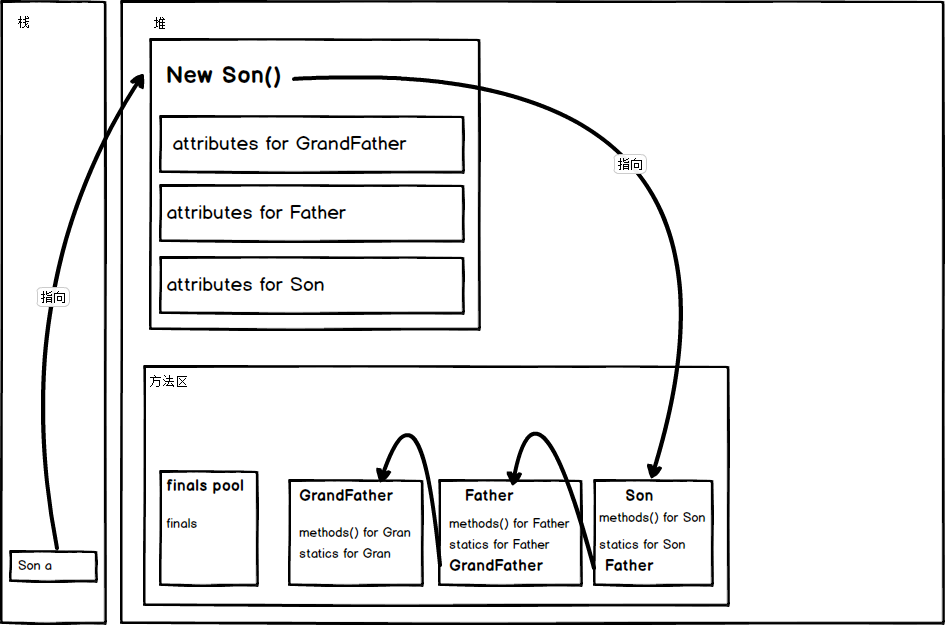
2.1 子類實例化過程
-
最開始,在類載入階段:JVM 會從最頂層的類開始逐步將類導入記憶體,JAVA 中所有的類都是
Object的子類,所以在導入時是從Object開始,然後一級一級導入,一直到Son(本例中)。其實從邏輯上也很好理解,子類在放入記憶體的時候是需要指向父類的地址的,如果父類都沒有被放入記憶體中,那豈不是指不到,那麼就會出錯。
-
同樣,在實例化
new Son()時,是首先從基類的Super()出發,一級級完成初始化的。在實例化子類時,會在子類中開闢一個屬於父類成員的空間,父類成員的初始化時靠子類調用父類的構造函數執行的。
有趣的是,父類的私有屬性其實也會在子類對象的空間中被分配空間,否則如果父類構造函數中有私有屬性的初始化,而又沒有對應的私有屬性,那麼豈不是會報錯?
但是由於訪問限制,子類對象是不能直接訪問到的,需要使用父類的具有操作私有屬性的
public修飾的方法才能訪問。
2.2 子類對象的成員訪問
在 JAVA 中,訪問對象的屬性和方法時,使用的是「搜到即停」的原則。
即在調用一個方法或者訪問一個屬性時,會先從子類開始搜索,如果沒搜索到,則向上尋找父類中對應的方法。一旦找到,就停止搜索
3. 重寫( @override )
重寫的具體表現機制就是在子類中,聲明和定義和父類相同的方法。重寫是多態的基礎。
這個相同的定義如下:
-
名稱相同;
-
參數個數相同;
-
參數類型相同;
-
各個參數類型的排列位置相同;
缺一不可。
4. 多態
多態的具體表現為:父類的引用指向子類對象:
Father f = new Son();
這樣做的好處就是:當 f 指向不同的子類,調用相同名稱的方法時,會執行不同的函數體,得到不同的行為。
從記憶體角度分析多態:
子類在初始化的時候,會將父類的方法申明所使用的偏移量賦值一份。
JVM在執行
.class文件的時候,也就是在記憶體中執行 Java 的程式的時候,會將父類的 Method,放到 Method Table 裡面,子類複寫了父類中的方法後,初始化子類的時候,就會將 Method Table中相應的 Method 進行覆蓋。
另一方面,所有派生類中繼承於基類的方法在方法表中的偏移量跟該方法在基類方法表中的偏移量保持一致這也就是為什麼可以準確的調用Method。[4]
在對象調用方法的時候,是從子類開始一級級向上搜索,當一旦找到對應的量就會直接停止搜索。
那麼如果複寫了父類的程式碼,則會在子類的方法區中相同偏移量的位置開闢一個方法空間,此時按照相同的偏移量去調用方法則會在子類中搜索到對應的方法,然後停止搜索並執行。如果沒找到,才會去尋找父類的方法。
二、 抽象類
抽象類用於抽象一個領域的固有屬性和方法,它存在的意義是定義和被繼承。
具體形式:
public abstract AbstracClass{
// 定義屬性
attributes;
// 定義具體方法
[public/protected/default/private] void/返回類型 method(){}
// 定義抽象方法,只能用 public 修飾,抽象方法必須被繼承然後實現
public abstract void/返回類型 method();
}
在抽象類中:
-
我們可以定義屬性;
-
我們可以具體方法;
-
我們可以定義抽象方法;(抽象方法只能存在於抽象類和介面中)
抽象方法就是沒有方法體的方法,只聲明這個方法,在被繼承的時候會強制需要實現抽象方法。
三、 介面
介面存在的意義就是擴展類的功能,增強類的可擴展性和可維護性。
舉個例子:我們可以定義一個人的基本屬性(年紀,性別,體重等等一系列屬性)和一些基本方法(呼吸,思考等一系列基本行為),但當這個人學了某個領域的專業知識,他就具備了這個領域的專業能力,這個時候他能解決的問題並不是每個人都能解決的,這個時候就可以通過定義介面來擴展這個人的方法庫。例如會計介面中就可以定義一些專業的會計方法,而一個會計類就可以 extends Person implements Accountant
介面的特點:
-
介面中只允許存在抽象方法;
-
介面允許多繼承;
-
介面可以包含變數,成員變數會被隱式地指定為public static final變數(並且只能是public static final變數,用private修飾會報編譯錯誤);[5]
-
介面的實現類必須重寫介面中定義的抽象方法;
具體形式:
// 定義介面
public interface InterfaceName{
// 介面內的方法修飾符為 public abstract
public abstract method1();
}
// 實現介面類
public class ClassName extends FatherClass Implements Interface1, Interface2(){
}
實現類通常會在類名的結尾加上 Impt (非強制),例如:ClassNameImpt
寫在最後:文章中有一些自己的思考,並不保證一定正確,如果有錯誤歡迎在討論區指出,一起學習。同時,也歡迎一起更加深入討論編程中更加本質的東西。
Reference
-
《Java 編程思想(第四版)》 ↩︎

