論文解讀(SEP)《Structural Entropy Guided Graph Hierarchical Pooling》
論文資訊
論文標題:Structural Entropy Guided Graph Hierarchical Pooling
論文作者:Junran Wu, Xueyuan Chen, Ke Xu, Shangzhe Li
論文來源:2022,ICLR
論文地址:download
論文程式碼:download
1 Introduction
之前池化的方法大多是 固定比例的池化 或者 基於逐步池化設計的。本文針對上述問題,設計了 SEP 模型,具體來說,在不分配特定於層的壓縮配額的情況下,設計了一種全局優化演算法來一次生成針對池化的簇分配矩陣。
然後,本文舉例說明了以往的方法在重建環圖和網格合成圖中的局部結構損傷。除 SEP 外,還進一步設計了兩個分類模型,SEP-G 和 SEP-N,分別用於圖分類和節點分類。結果表明,SEP 在圖分類基準上優於最先進的圖池方法,並在節點分類上獲得了更好的性能。
池化有兩種代表性的工作:
-
- 基於節點丟棄的池化策略:TopKPool、SAGPool、ASAP
-
- 基於節點聚類的層次池化:DiffPool
本文貢獻:
-
- 我們在以往的分層池工作中發現了阻礙 GNN 發展的兩個關鍵問題,包括由於固定的壓縮配額和逐步池設計而造成的局部結構損傷和次優問題。
- 通過引入結構資訊理論,我們提出了一種新的分層池化方法,稱為SEP,以解決所揭示的問題。
- 我們在圖重建、圖分類和節點分類任務上廣泛地驗證了SEP,與SOTA分層池化方法相比,它們的性能更好。
2 Proposed Method
整體框架圖示:
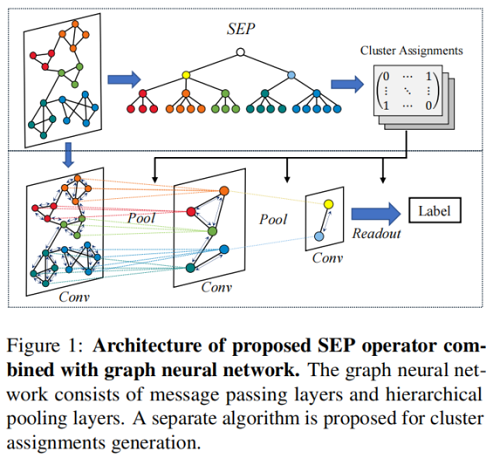
2.1 Preliminaries
$H_{i+1}=\operatorname{Re} L U\left(\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} H_{i} W_{i}\right) $
$\mathbf{A}_{i+1}=\mathbf{S}_{i} \mathbf{A}_{i} \mathbf{S}_{i}^{\top} ; \quad \mathbf{P}_{i+1}=\mathbf{S}_{i} H_{i}$
-
- $\mathbf{A}_{i} \in \mathbb{R}^{n_{i} \times n_{i}}$ 代表第 $i$ 層的鄰接矩陣;
- $H_{i} \in \mathbb{R}^{n_{i} \times h}$ 代表第 $i$ 層由 GNN 導出的特徵矩陣;
- $\mathbf{P}_{i+1}$ 接收節點隱藏特徵 $H_{i}$ 併合並這些特徵,以改進新圖中 $n_{i+1}$ 簇的初始表示;
2.2 Cluster Assignments via Structural Entropy Minimization
結構熵用來解碼圖的層次結構,通過結構熵最小化,可以將圖的層次結構解碼為相應的編碼樹,使雜訊或隨機變化產生的干擾最小化。本文認為一種有效的結構熵最小化演算法可以揭示層次池化層之間的聯繫,並消除圖中的雜訊結構。
編碼樹 $T$ 上 $G$ 的結構熵的形式化方程可以寫為:
${\large \mathcal{H}^{T}(G)=-\sum\limits _{v_{t} \in T} \frac{g_{v_{t}}}{\operatorname{vol}(\mathcal{V})} \log \frac{\operatorname{vol}\left(v_{t}\right)}{\operatorname{vol}\left(v_{t}^{+}\right)}} \quad\quad\quad(3)$
其中,
-
- $v_{t}$ 是編碼樹 $T$ 的一個非根節點,同時可以被認為是一個根據編碼樹 $T$ 劃分的節點子集 $\subset \mathcal{V}$;
- $v_{t}^{+}$ 是 $v_{t}$ 的父節點;
- $g_{v_{t}}$ 是指在 $v_{t}$ 的葉節點劃分中具有端點的邊數;
- $\operatorname{vol}(\mathcal{V})$ 代表 $\mathcal{V}$ 中的葉子節點度的和;
- $\operatorname{vol}\left(v_{t}\right)$ 代表 $v_{t}$ 節點度;
編碼樹是圖的一種自然的層次劃分,為了使結構熵最小化 $\mathcal{H}(G)=\min _{\forall T}\left\{\mathcal{H}^{T}(G)\right\}$,本文建立了不同層之間的連接。此外,圖中的局部結構將被保留,因為不需要分配圖層中特定的節點壓縮配額。
首選具有一定高度的自然編碼樹,因為大多數任務只需要幾次固定時間的圖粗化。在此背景下,提出了 $G$ 的 $k$ 維結構熵來解碼具有固定高度 $k$ 的最優編碼樹:
$\mathcal{H}^{(k)}(G)= \underset{\forall T: \operatorname{Height}(T)=k}{\text{min}} \left\{\mathcal{H}^{T}(G)\right\} \quad\quad\quad(4)$
本文在 $k$ 維結構熵的指導下,研究了對具有一定高度 $k$ 的編碼樹進行解密的求解方法。首先,我們定義了三個函數。
Definition 3.1. Let T be any coding tree for graph $G= (\mathcal{V}, \mathcal{E})$, $v_{r}$ is the root node of $T$ and $\mathcal{V}$ are the leaf nodes of $T$ . Given any two nodes $\left(v_{i}, v_{j}\right)$ in $T$ , in which $v_{i} \in v_{r}$.children and $v_{j} \in v_{r}$.children.
Define a function $\operatorname{MERGE}_{T}\left(v_{i}, v_{j}\right)$ for $T$ to insert a new node $v_{\varepsilon}$ between $v_{r}$ and $\left(v_{i}, v_{j}\right)$ :
$\begin{array}{l}v_{\varepsilon} \cdot \text { children } \leftarrow v_{i} \quad\quad\quad(5) \\v_{\varepsilon} \cdot \text { children } \leftarrow v_{j} \quad\quad\quad(6) \\v_{r}. \text { children } \leftarrow v_{\varepsilon} \quad\quad\quad(7) \end{array}$
Definition 3.2. Following the setting in Definition 3.1, given any two nodes $\left(v_{i}, v_{j}\right)$ , in which $v_{i} \in v_{j} .children$.
Define a function $\operatorname{REMOVE}_{T}\left(v_{i}\right)$ for $T$ to remove $v_{i}$ from $T$ and merge $v_{i} .children$ to $v_{j} .chileren$:
$v_{j} \text {.children } \leftarrow v_{i} \text {.children } \quad\quad\quad(8)$
Definition 3.3. Following the setting in Definition 3.1, given any two nodes $\left(v_{i}, v_{j}\right)$ , in which $v_{i} \in v_{j} .children$ and $\mid Heigth \left(v_{j}\right)-H e i g h t\left(v_{i}\right) \mid>1$ .
Define a function $\operatorname{FILL}\left(v_{i}, v_{j}\right)$ for $T$ to insert a new node $v_{\varepsilon}$ between $v_{i}$ and $v_{j}$ :
$\begin{array}{l}v_{\varepsilon} \text {.children } \leftarrow v_{i} ; \quad\quad\quad(9) \\v_{j} \text {.children } \leftarrow v_{\varepsilon} ;\quad\quad\quad(10) \end{array}$
使用上述 3 個 Definition 構造一個 高度為 $k$ 的編碼樹:

Stage 1: Bottom to top construction —— 從上到下 構造一棵二進位編碼樹,將根的兩個節點和並乘一個新的劃分,最大限度的減少結構熵;
Stage 2: Compress $T$ to the certain height $k$ —— 為滿足固定數量的圖粗化,需要通過刪除節點來壓縮之前的全高二進位編碼樹。每次從 $T$ 中選擇一個內部節點,這使得 $T$ 在去除該節點後的結構熵變化最小。
Stage 3: Fill T to avoid cross-layer links —— 在第二階段結束時,已經在結構熵的指導下得到了一個一定高度為 $k$ 的編碼樹。但是,由於跨層鏈接,節點在下一層中沒有直接後繼,這將導致在基於這種編碼樹實現分層池時節點丟失。因此,我們需要執行第三個階段,以確保層間資訊傳輸的完整性,也不需要干擾 $G$ 在編碼樹 $T$ 上的結構熵。
最終,$G$ 的編碼樹 $T$ 被獲得,其中 $T=\left(\mathcal{V}^{T}, \mathcal{E}^{T}\right)$,$\mathcal{V}^{T}=\left(\mathcal{V}_{0}^{T}, \ldots, \mathcal{V}_{k}^{T}\right)$ 和$\mathcal{V}_{0}^{T}=\mathcal{V}$。此外,從 $\mathcal{E}^{T}$ 中也可以得到簇分配矩陣,即 $\mathbb{S}=\left(\mathbf{S}_{1}, \ldots, \mathbf{S}_{k}\right)$。
Proposition 3.4. Let T be a coding tree after the second stage of Algorithm 1, and given two adjacent nodes $\left(v_{i}, v_{j}\right) in T$ , in which $v_{i} \in v_{j} .children$ and $\mid H e i g \operatorname{th}\left(v_{j}\right)- \operatorname{Height}\left(v_{i}\right) \mid>1$ . Then, $\mathcal{H}^{T}(G)=\mathcal{H}^{T_{F IL L\left(v_{i}, v_{j}\right)}} \;\;(G)$.
Proof:
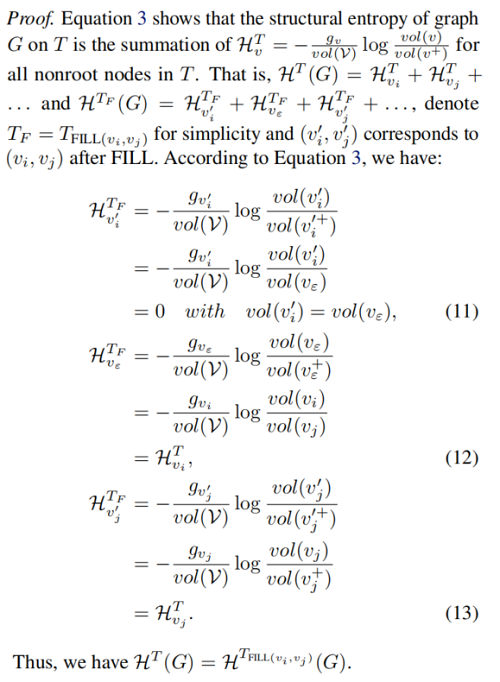
2.3 Graph Neural Network for Graph Classification
圖分類框架如下:
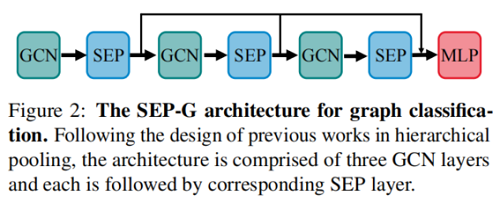
圖表示如下:
$h_{G}=\operatorname{Concat}\left(\operatorname{Readout}\left(S E P_{i}\left(G C N_{i}\left(H_{i}, \mathbf{A}_{i}\right), \mathbf{S}_{i}\right)\right)\right.\quad\quad \mid \forall i \in\{1,2,3\})\quad\quad\quad(14)$
Proposition 3.5. Given a permutation matrix $\mathcal{P} \in \{0,1\}^{n \times n}$ , then $\operatorname{SEP}(A, H)=\operatorname{SEP}\left(\mathcal{P} A \mathcal{P}^{\top}, \mathcal{P} H\right)$ (i.e., SEP is permutation invariant).
2.4 Graph Neural Network for Node Classification
節點分類框架如下:
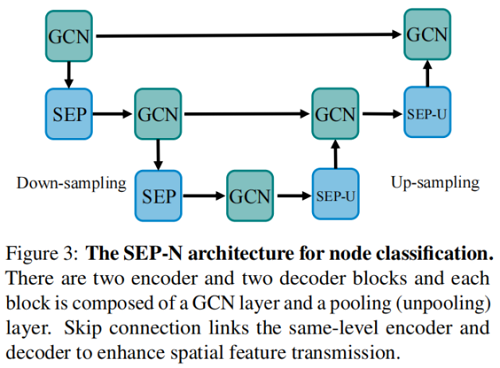
除了將圖轉換為高級表示的功能外,我們還可以採用相同的矩陣 $S_i$ 來展開壓縮圖表示 $H_i$,並將 $A_i$ 結構到原始空間:
$\mathbf{A}_{i+1}=\mathbf{S}_{i}^{\top} \mathbf{A}_{i} \mathbf{S}_{i} ; \quad \mathbf{P}_{i+1}=\mathbf{S}_{i}^{\top} H_{i}\quad\quad\quad(15)$
3 Experiments
3.1 Graph Reconstruction
Confifiguration
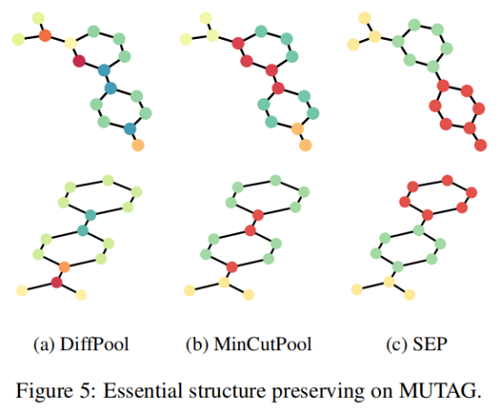
Figure 4 展示了使用原始圖和使用不同池化方法重構的圖:

我們選擇 TopKPool 來表示節點丟棄設計的方法,選擇 MinCutPool 來表示節點聚類設計的方法。我們首先注意到 TopKPool 的重建結果,其中原始圖的基本形狀甚至無法識別。這證實了節點下降方法會導致嚴重的資訊缺失,並意味著節點下降方法在圖分類中的性能較差。另一方面,MinCutPool 確實保留了原始圖形的基本形狀。但是,我們仍然可以看到環的邊緣和網格中心的顯著扭曲,這代表了環和網格的關鍵結構,這驗證了圖中的局部結構會被人為指定的節點壓縮配額破壞的假設。相反地,SEP 幾乎重建了環,並保留了網格中心的基本結構,這表明我們的池化方法獲得了原始圖的關鍵結構資訊。
3.2 Graph Classifification
圖分類結果:
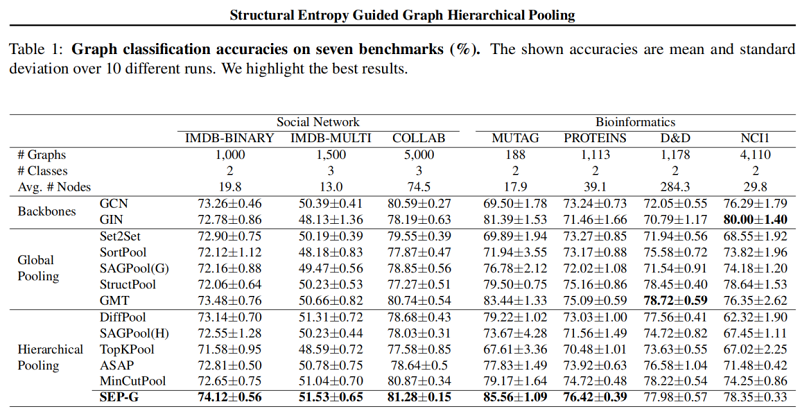
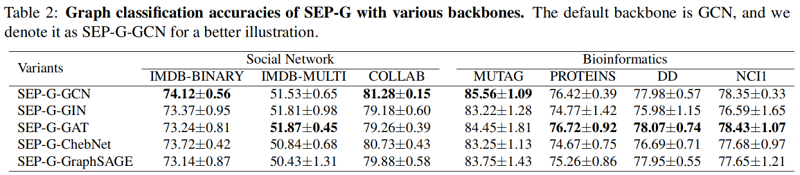
聚類可視化
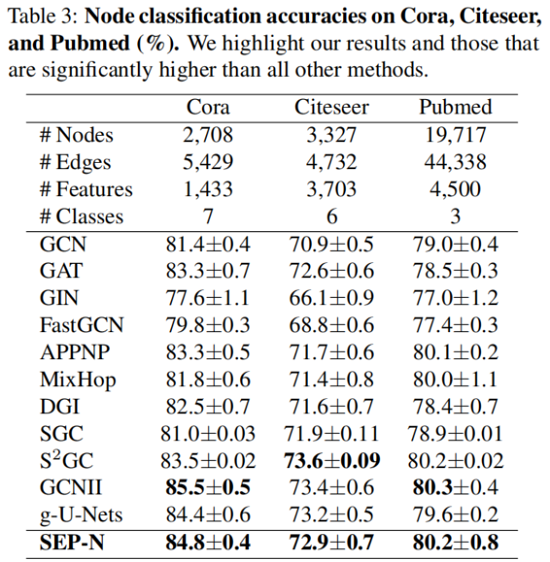
3.3 Node Classification
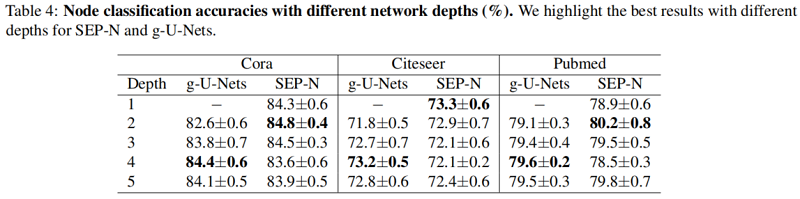
4 Conclusions
在本文中,我們開發了一個優化演算法來解決現有的分層池方法的幾個局限性。特別是,在結構熵最小化的指導下,我們的池化方法SEP不僅可以捕獲池化層之間的連通性,而且還可以解決由於節點壓縮的超參數而導致的局部結構破壞的問題。在提出的SEP基礎上,我們引入了兩種學習模型,SEP-G和SEP-n,分別用於圖分類和節點分類。實驗結果表明,SEP-G在圖分類方面取得了顯著的改進,並且SEP-N在節點分類任務上取得了優於其他gnn的性能。結構熵和節點特徵的結合是未來工作的一個有趣的方向。


