如何設計一個分散式 ID 發號器?

大家好,我是樹哥。
在複雜的分散式系統中,往往需要對大量的數據和消息進行唯一標識,例如:分庫分表的 ID 主鍵、分散式追蹤的請求 ID 等等。於是,設計「分散式 ID 發號器」就成為了一個非常常見的系統設計問題。今天我將帶大家一起學習一下,如何設計一個分散式 ID 發號器。
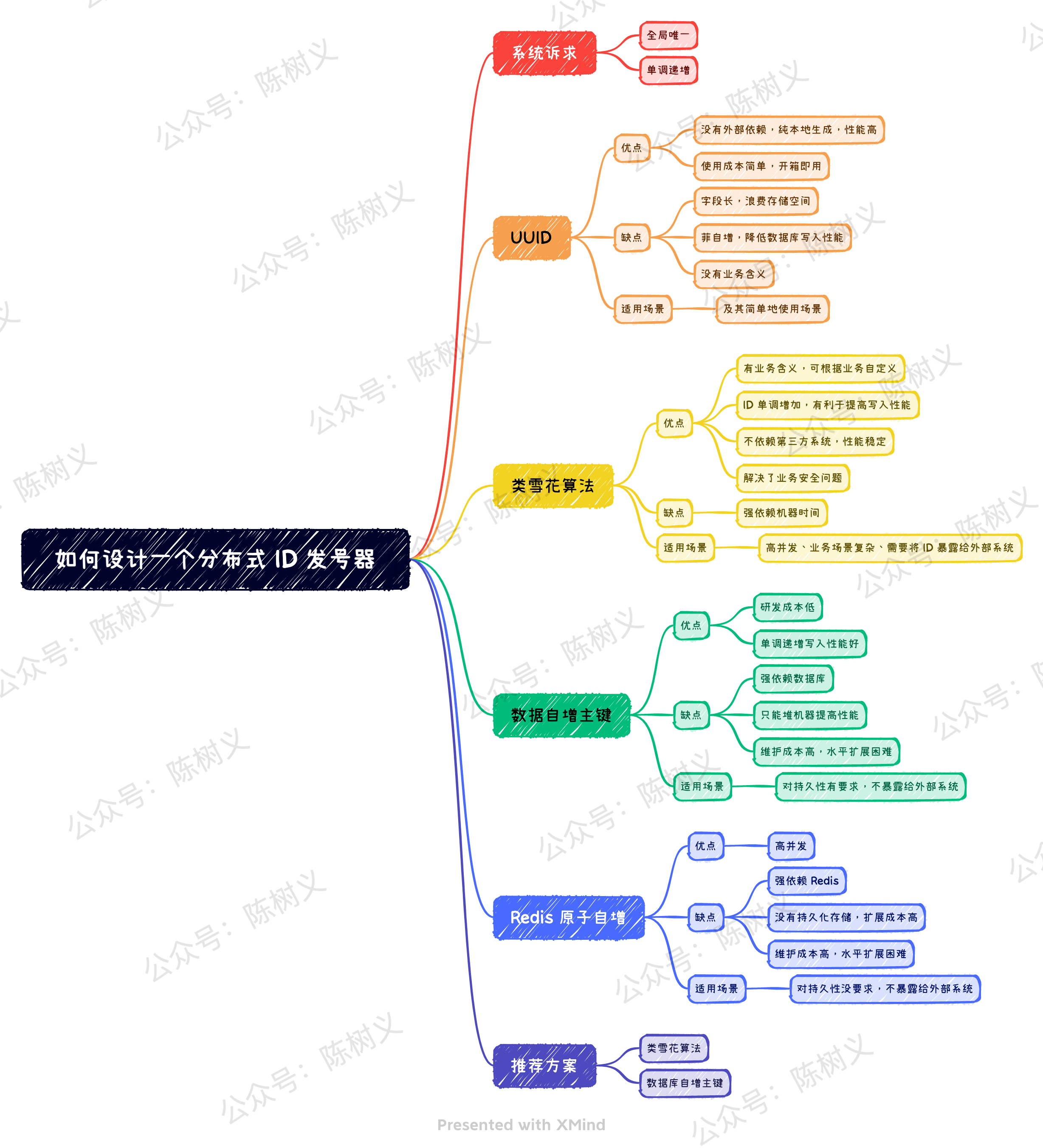
系統訴求
對於業務系統而言,對於全局唯一 ID 一般有如下幾個需求:
- 全局唯一。 生成的 ID 不能重複,這是最基本的要求,否則在分庫分表的場景下就會造成主鍵衝突。
- 單調遞增。 保證下一個 ID 大於上一個 ID,這樣可以保證寫入資料庫的時候是順序寫入,提高寫入性能。
對於上面兩個需求來說,第一點是所有系統都要求的。而第二點則並不是所有系統都需要,例如分散式追蹤的請求 ID 就可以不需要單調遞增。而那些需要存到資料庫里作為 ID 逐漸的場景,可能就需要保證全局唯一 ID 是單調遞增的。
此外,我們可能還需要考慮安全方面的問題。如果一個全局唯一 ID 是順序遞增的,那麼有可能會造成業務資訊的泄露。例如訂單 ID 每次遞增 1,那麼競爭對手直接通過訂單 ID 就可以知道我們每天的訂單數,這對於業務來說是不可接受的。
對於上述的訴求,現在市面上有非常多的唯一 ID 解決方案,其中最為常見的方案有如下 4 種:
- UUID
- 類雪花演算法
- 資料庫自增主鍵
- Redis 原子自增
UUID
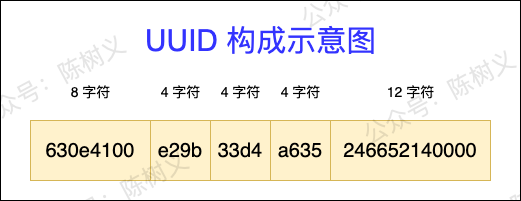
UUID 全稱叫 Universally Unique Identifier,即全局唯一標識符,它是 Java 中自帶的 API。 一個標準的 UUID 包含 32 個 16 進位的數字,以中橫線作為分隔符分為 5 段,每段的長度分別為 8 字元、4 字元、4 字元、4 字元、12 字元,大小為 36 個字元,如下圖所示。一個簡單的 UUID 示例:630e4100-e29b-33d4-a635-246652140000。
對於 UUID 這種唯一 ID 解決方案,優點是沒有外部依賴,純本地生成,因此其性能非常高。但缺點也是非常明顯的:
- 欄位非常長,浪費存儲空間。 UUID 一般長度為 36 個字元串,如果作為資料庫主鍵存儲,極大地增加索引的存儲空間。
- 非自增,降低資料庫寫入性能。 UUID 不是自增的,如果作為資料庫主鍵,那麼無法實現順序寫,從而會降低資料庫寫入性能。
- 沒有業務含義。 UUID 是沒有業務含義的,我們無法從 UUID 中獲取到任何含義。
因此,對於 UUID 而言,其比較適用於非資料庫 ID 存儲的情況,例如生成一個本地的分散式追蹤請求 ID。
類雪花演算法
雪花演算法(SnowFlake)是 Twitter 開源的分散式 ID 生成演算法,其思路是用 64 位來表示一個 ID,並將 64 位分割成 4 個部分,如下圖所示。
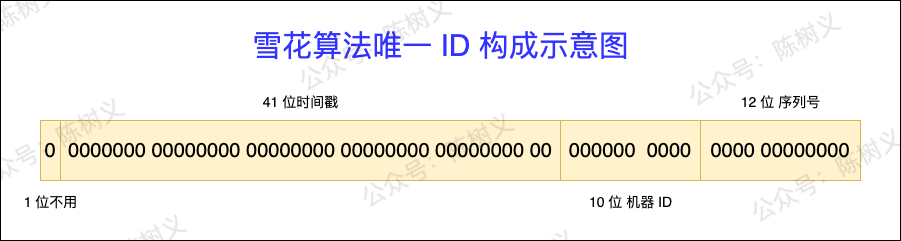
- 第一個部分:1 位。 固定為 0,表示為正整數。二進位中最高位是符號位,1 表示負數,0 表示正數。ID 都是正整數,所以固定為 0。
- 第二個部分:41 位。 表示時間戳,精確到毫秒,可以使用 69 年。時間戳帶有自增屬性。
- 第三個部分:10 位。 表示 10 位的機器標識,最多支援 1024 個節點。此部分也可拆分成 5 位 datacenterId 和 5 位 workerId,datacenterId 表示機房 ID,workerId 表示機器 ID。
- 第四部分:12 位。 表示序列化,即一些列的自增 ID,可以支援同一節點同一毫秒生成最多 4095 個 ID 序號。
雪花演算法的優點是:
- 有業務含義,並且可自定義。 雪花演算法的 ID 每一位都有特殊的含義,我們從 ID 的不同位數就可以推斷出對應的含義。此外,我們還可根據自身需要,自行增刪每個部分的位數,從而實現自定義的雪花演算法。
- ID 單調增加,有利於提高寫入性能。 雪花演算法的 ID 最後部分是遞增的序列號,因此其生成的 ID 是遞增的,將其作為資料庫主鍵 ID 時可以實現順序寫入,從而提高寫入性能。
- 不依賴第三方系統。 雪花演算法的生成方式,不依賴第三方系統或中間件,因此其穩定性較高。
- 解決了安全問題。 雪花演算法生成的 ID 是單調遞增的,但其遞增步長又不是確定的,因此無法從 ID 的差值推斷出生成的數量,從而可以保護業務隱私。
雪花演算法幾乎可以是非常完美了,但它有一個致命的缺點 —— 強依賴機器時間。 如果機器上的系統時間回撥,即時間較正常的時間慢,那麼就可能會出現發號重複的情況。對於這種情況,我們可以在本地維護一個文件,寫入上次的時間戳,隨後與當前時間戳比較。如果當前時間戳小於上次時間戳,說明系統時間出了問題,應該及時處理。
整體而言,雪花演算法不僅長度更短,而且還具有業務含義,在資料庫存儲的場景下還能提高寫入性能,因此雪花演算法生成分散式唯一 ID 受到了大家的歡迎。 現在許多中國大廠的開源發號器的實現,都是在雪花演算法的基礎上做改進,例如:百度開源的 UidGenerator、美團開源的 Leaf 等等。這些類雪花演算法的核心都是將 64 位進行更合理的劃分,從而使得其更適合自身場景。
資料庫自增主鍵
說起唯一 ID,我們自然會想起資料庫的自增主鍵,因為它就是唯一的。
對於並發量低的情況下,我們可以直接部署 1 台機器,每次獲取 ID 的時候就往資料庫表插入一條數據,隨後返回主鍵 ID。這種方式的好處是非常簡單,實現成本低。此外,生成的唯一 ID 也是單調自增的,可以滿足資料庫寫入性能的要求。
但其缺點也非常明顯,即其強依賴資料庫。當資料庫異常的時候,會造成整個系統不可用。即使做了高可用切換,主從切換時數據同步不一致時,仍然可能造成重複發號。另外,由於是單機部署,因此其性能瓶頸限制在單台 MySQL 機器的讀寫性能上,註定無法承擔起高並發的業務場景。
對於上面說到的性能問題,我們可以通過集群部署來解決。而集群部署之後的 ID 衝突問題,我們可以通過設置遞增步長來解決。例如如果我們有 3 台機器,那麼我們就設置遞增步長為 3,每台機器的 ID 生成策略為:
- 第 1 台機器,從 0 開始遞增,步長為 3,生成的 ID 分別是:0、3、6、9 等等。
- 第 2 台機器,從 1 開始遞增,步長為 3,生成的 ID 分別是:1、4、7、10 等等。
- 第 3 台機器,從 2 開始遞增,步長為 3,生成的 ID 分別是:2、5、8、11 等等。
這種方式解決了集群部署以及 ID 衝突的問題,可以在一定程度上提升並發訪問的容量。但其缺點也比較明顯:
- 只能依賴堆機器提高性能。 當請求再次增多時,我們只能無限堆機器,這貌似是一種物理防禦一樣。
- 水平擴展困難。 當我們需要增加一台機器時,其處理過程非常麻煩。首先,我們需要先把新增的伺服器部署好,設置新的步長,起始值要設置一個不可能達到的值。當把新增的伺服器部署好之後,再一台台處理舊的伺服器,這個過程真的非常痛苦,可以說是人肉運維了。
Redis 原子自增
由於 Redis 是記憶體資料庫,其強大的性能非常適合用來實現高並發的分散式 ID 生成。基於 Redis 實現自增 ID,其主要還是利用了 Redis 中的 INCR 命令。該命令可以將某個數自增一併返回結果,並且這個操作是原子操作。
通過 Redis 實現分散式 ID 功能,其模式與通過資料庫自增 ID 類似,只是存儲介質從硬碟變成了記憶體。當單台 Redis 無法支撐並發請求的時候,Redis 同樣可以通過集群部署和設置步長的方式去解決。但資料庫自增主鍵有的問題,Redis 自增 ID 的方式也同樣會有,即只能堆機器,同時水平擴展困難。此外,比起資料庫存儲的持久化,Redis 是基於記憶體的存儲,需要考慮持久化的問題,這同樣是一個頭疼的問題。
總結
看了這麼多個分散式 ID 的解決方案,那麼我們到底應該選哪個呢?
當我們在決策的時候,我們應該確定決策的維度。對於這個問題,我們應該關注的維度大致有:研發成本、並發量、性能、運維成本。
首先,對於 UUID 而言,其在各個方面其實都不如雪花演算法,唯一的優點是 JDK 自帶 API。因此,如果你只是極其簡單地使用,那麼就直接使用 UUID 就可以,畢竟雪花演算法還得寫一寫實現程式碼呢。
其次,對於類雪花演算法而言,其毋庸置疑是非常好的一種實現。與 UUID 相比,其不僅有 UUID 本地生成、不依賴第三方系統的優點,還有業務含義、能提高寫入性能、解決了安全問題。但其缺點在於要實現雪花演算法的程式碼,因此其研發成本稍稍比 UUID 高一些。
最後,對於資料庫自增 ID 與 Redis 原子自增這兩種方式。資料庫自增 ID 的方式,其優點同樣在於簡單方便,不需要太高的研發成本。但其缺點是支撐的並發量太低,並且後續運維成本太高。因此,資料庫自增 ID 這種方式,應該適用於小規模的使用場景下。而 Redis 原子自增的方式,其優先在於能支撐高並發的場景。但缺點是需要自行處理持久化問題,運維成本可能比較高。
本人更傾向於資料庫自增方式。這兩種方式都是非常類似的,唯一的區別是存儲介質。Redis 原子自增方式非常快,可能單機可以是資料庫方式的好幾倍。但是如果要考慮持久化的問題,那對於 Redis 來說就太複雜了。
我們把上面這四種實現方式整理一下,可以匯總成下面的對比表格:
| 實現方案 | 優點 | 缺點 | 使用場景 |
|---|---|---|---|
| UUID | 性能高、不依賴第三方、研發成本低 | 欄位長浪費存儲空間、ID 不自增寫入性能差、無業務含義 | 非常簡單的使用場景(用於簡單測試) |
| 類雪花演算法 | 有業務含義、單調遞增寫入性能好、不依賴第三方、業務安全 | 強依賴機器時間 | 高並發、業務場景複雜、需要將 ID 暴露給外部系統 |
| 資料庫自增 ID | 研發成本低、單調遞增寫入性能好 | 依賴資料庫、只能堆機器提高性能、維護成本高 | 對持久性有要求,不暴露給外部系統 |
| Redis 原子自增 | 高並發、單調遞增寫入性能好 | 依賴 Redis、有業務問題、有持久性問題 | 對持久性沒要求,不暴露給外部系統 |
總的來說,如果站在長期使用考慮,那麼運維成本、高並發肯定是需要考慮的。在這個基礎條件下,類雪花演算法與資料庫自增 ID 或許是相對好的選擇。
參考資料
- 分散式系統全局發號器的幾點思考 – 掘金
- VIP!!非常好!Leaf—— 美團點評分散式 ID 生成系統 – 美團技術團隊
- (8 條消息) 六種方式實現全局唯一發號器_北鶴 M 的部落格 – CSDN 部落格_發號器
- VIP!!不錯,擴展視野!10 | 發號器:如何保證分庫分表後ID的全局唯一性?


