場景之多數據源查詢及數據下載問題
前言:本文將介紹常用後台功能中的數據獲取以及下載的一些注意事項和實現。
承接上文數據分頁查詢
當通過分頁查詢到數據之後,接著還會遇到其他需求:
- 繼續其他數據源查詢:分頁查詢到的數據並非全部需要的數據,這個時候主要欄位查出來了,需要去其他表或者其他服務調用再去獲取資訊。
- 數據獲取整合之後進行下載
一、繼續查詢
1、需求
比如根據資料庫查詢出來商品的id,商品名等主要資訊。但是要去查詢商品的購買量以及原始售價,這些與商品基本資訊不太相關的數據資訊,通常考慮到業務數據量,系統中已經進行了分庫或者分表,甚至一些成交數據是維護在數倉等其他業務服務中。
商品id | 商品名 | 商品主圖 | 商品售價 | 商品購買量 | 商品售價 | .....
這個時候如果順序的再去執行第三方服務和去查其他庫,顯然會導致請求的時延很大。既然商品基本資訊已經批量查詢出來了,並且購買量和原始售價分數不同的數據存儲,就可以開執行緒或者協程去一塊查詢其他數據,最後合併匯總。或者本身第一次查詢的數據量,這個時候可以分批量的去查第三方服務數據。
因此分為幾種情況
- (1)同一批數據再去分別查詢不同的數據源
- (2)去查詢相同的數據源,但是原始數據太大,需要分批查詢
- (3)對於從不同數據源二次查詢到的數據,需要作進一步規則計算
下面來看下對於不同的情況的做法以及go語言實現和一些注意事項。
2、實現
2.1 封裝waitgroup和業務對象
首先為了通用性,對sync.WaitGroup做一下簡單封裝,方便協程使用。
type waitGroup struct {
wg *sync.WaitGroup
}
func WaitGroup() *waitGroup {
return &waitGroup{&sync.WaitGroup{}}
}
func (wg *waitGroup) NewGoroutineStart(f func()) {
wg.wg.Add(1)
go func() {
defer func() {
if err := recover(); err != nil {
// 為了保證系統安全通常要做異常捕獲,保證goroutine是有recover
fmt.Println("日誌列印Goroutine處理失敗")
}
wg.wg.Done()
}()
f()
}()
}
func (wg *waitGroup) Wait() {
wg.wg.Wait()
}
這裡通常會對協程調用中可能出現的panic,進行異常捕獲recover,為了保證系統的安全運行。
type Product struct {
ID int
Name string
}
type ProductRes struct {
ID int
Name string
Order int
Price int
}
同時為了更好的展示效果,定義了一個商品類Product,和一個商品ProductRes結果類用於整合數據。
2.2 第一種情況
用分頁查詢出來的數據整批再去其他多個數據源分別讀取數據,比如用商品的id,去獲取商品的成交量order以及商品的售價。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// 商品類定義 與 waitgroup定義省略
func main() {
var data []*Product
// 模擬從分頁查詢出來的商品
for i := 1; i <= 20; i++ {
data = append(data, &Product{
i,
fmt.Sprintf("%d th-Product", i),
})
}
// 用於保存商品id和商品單價以及商品訂單關係
productPriceMp := make(map[int]int, 5)
productOrderMp := make(map[int]int, 5)
wg := WaitGroup()
wg.NewGoroutineStart(func() {
//模擬讀取數據源1數據
fmt.Println("開始讀取數據源1數據")
time.Sleep(time.Duration(rand.Intn(5)) * time.Second)
for i := 0; i < len(data); i++ {
productPriceMp[data[i].ID] = rand.Intn(100)
}
fmt.Println("數據源1數據獲取成功")
})
wg.NewGoroutineStart(func() {
//模擬讀取數據源2數據
fmt.Println("開始讀取數據源2數據")
time.Sleep(time.Duration(rand.Intn(5)) * time.Second)
for i := 0; i < len(data); i++ {
productOrderMp[data[i].ID] = rand.Intn(100)
}
fmt.Println("數據源2數據獲取成功")
})
// 阻塞等待
wg.Wait()
fmt.Println("數據同步讀取完成,開始合併")
var res []*ProductRes
for _, product := range data {
res = append(res, &ProductRes{
product.ID,
product.Name,
productOrderMp[product.ID],
productPriceMp[product.ID],
})
}
// 展示商品數據
for _, productRes := range res {
fmt.Println(productRes)
}
}
說明:
- 這裡首先模擬生成20條分頁查詢得到的商品記錄,存放在data切片中
- 定義兩個map分別保存商品與訂單,商品與售價之間的關係,每個map設置為10,是一個預估容量,一般為了防止map在實際增加數據的時候容量上成倍擴增,可以根據情況初始化一個比較小的值。
- 然後用封裝好得waitgroup開啟兩個協程去不同的數據源獲取數據,這裡我們用sleep以及rand來模擬
- 最後將整合好的結果放在res切片中,一般到這裡在框架中的servers層,邏輯就處理完了,將res就可作為返回結果
來看下實際的運行結果

可以看到同時從兩個數據源獲取數據,並且整合成功,列印出來。
2.2 第二種情況
以上是所有分頁查詢得到的數據去不同數據源二次獲取數據,下面這種情況更加常見,對於第一次分頁查詢的數據很多,要分批再去做其他數據源查詢。因此就涉及到多個協程之間去讀取統一切片,也就是並發數據讀取問題。首先來看個錯誤demo。
func main() {
var data []*Product
for i := 1; i <= 1000; i++ {
data = append(data, &Product{
i,
fmt.Sprintf("%d th-Product", i),
})
}
wg := WaitGroup()
var newData []*Product
var startInd, endInd = 0, 0
for i := 0; i < len(data); i += 100 {
if i+100 < len(data) {
startInd, endInd = i, i+100
} else {
startInd, endInd = i, len(data)
}
newData = data[startInd:endInd]
wg.NewGoroutineStart(func() {
fmt.Println("開始分批去其他數據源獲取")
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
fmt.Println(newData[0])
})
}
// 阻塞等待
wg.Wait()
}
說明:
- 用data切片模擬第一次查詢出來的很多數據記錄
- 為了分批傳入go程,預先定義了一個newData切片,
- 用封裝好得waitgroup開啟go程,每100條記錄,新開一個go程用time和rand模擬新數據源獲取
- fmt.PrintLn(newData[0])來作為日誌,列印goroutine處理的數據
來猜一下日誌會輸出什麼
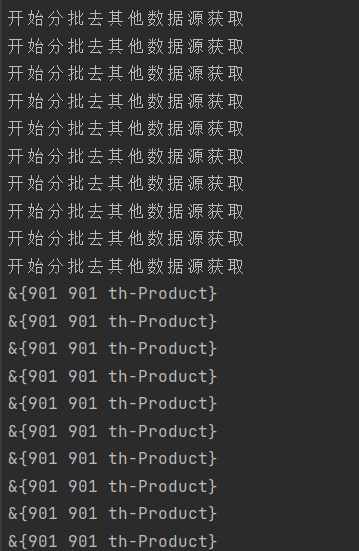
問題:從日誌列印可以看出,雖然開啟了10個go程,並且按照邏輯應該是每個go分別用的是從1-100,101-200…..分批次的數據,而實際是所有的go程式用的都是同一批數據也就是最後一批從901下標開始的數據。也就是說出現了多個執行單元使用的都是同一批數據。
原因就在於:newData作為一個切片是引用類型,而由於newData但是預先定義在for循環之外的,所有的goroutine用的同一個newData指針,也因此都是同一批數據。
鑒於上述原因,可以在每次循環內部重新定義一個新的newData作為協程的傳入,這樣就不會有數據衝突的問題發生。作如下修改
wg := WaitGroup()
var startInd, endInd = 0, 0
for i := 0; i < len(data); i += 100 {
if i+100 < len(data) {
startInd, endInd = i, i+100
} else {
startInd, endInd = i, len(data)
}
// 新定義newData作為部分數據切片,傳入goroutine
newData := data[startInd:endInd]
wg.NewGoroutineStart(func() {
fmt.Println("開始分批去其他數據源獲取")
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
fmt.Println(newData[0])
})
}
以上是基於已經封裝好的waitgroup的使用,因為封裝的時候是無參數的,如果使用go func的方式開啟,也可傳入參數避免以上問題。
接下來再來看一個demo,會有類似的問題。
for i := 0; i <= 9; i++ {
go func() {
time.Sleep(3 * time.Second)
fmt.Println("i =", i)
}()
}
time.Sleep(5 * time.Second)
說明:
- 連續開啟10個協程執行不同的任務,fmt.Println模擬日誌,列印處理的數據
- 用time.sleep阻塞等待所有的協程執行完畢
來看下結果
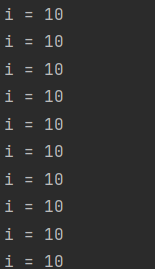
結果列印所有的i值都為10
原因是:同上面的多協程讀取統一數據類似的,協程內讀取到的是變數的指針,也就是統一值,而最後i的值變為10for循環才會結束,因此所有的協程內部日誌列印的也都是10。
2.3 二次查詢數據重新計算
2.2中實現了大數據量中不同批次的數據二次查詢,如果有一個全局指標,比如商品的總成交量,而每個商品的成交量是開啟多個goroutine二次查詢的,二次查詢之後還要做規則計算。也就是涉及到並發數據寫入的問題。
func main() {
var data []*Product
for i := 1; i <= 1000; i++ {
data = append(data, &Product{
i,
fmt.Sprintf("%d th-Product", i),
})
}
wg := WaitGroup()
dataLock := sync.Mutex{}
var totalOrder int
var startInd, endInd = 0, 0
for i := 0; i < len(data); i += 100 {
if i+100 < len(data) {
startInd, endInd = i, i+100
} else {
startInd, endInd = i, len(data)
}
newData := data[startInd:endInd]
wg.NewGoroutineStart(func() {
fmt.Println("開始分批去其他數據源獲取")
time.Sleep(time.Second * time.Duration(rand.Intn(3)))
var newDataOrder []int
for _, pro := range newData {
newDataOrder = append(newDataOrder, rand.Intn(10)*(pro.ID+1))
}
dataLock.Lock()
defer dataLock.Unlock()
for _, order := range newDataOrder {
totalOrder += order
}
})
}
// 阻塞等待
wg.Wait()
fmt.Println("總成交量:", totalOrder)
}
說明:
- 用data切片模擬第一次查詢出來的很多數據記錄,總共1000條
- 為了分批傳入go程,為了避免goroutine讀取數據問題,每個for循環開啟goroutine之前預先定義一個新的newData切片
- 用封裝好得waitgroup開啟go程,為了保證數據同步的問題,預先互斥鎖mutex
- 用time和rand模擬從其他數據源獲取訂單數據
- rand.Intn(10)*(pro.ID+1)表示用商品id+1乘以一個隨機數模擬商品對應的訂單量
- 用互斥鎖控制並發流程下數據totalOrder的寫入,並且使用defer保證了每次goroutine釋放鎖
執行結果如下

二、數據下載
雖然從底表分頁查詢,並且多數據源也合併到數據,有時候對於一些後台運營,是希望將這些數據以表格的形式導出。
1、數據導出實現
這裡針對excel表格下載,可以使用開源工具
//github.com/360EntSecGroup-Skylar/excelize
基本的包括
- excel格式定義
- 設置表名
- 設置第一行表頭
- 數據寫入寫入文件
具體的步驟指南,不再做贅述,可以直接github查看。
2、數據下載限制
服務端數據以表格格式返回二進位格式表格數據,如果數據量很大的話,肯定需要做一些限制。
- 根據日期限制最近幾個月生成的記錄,入參的時候做校驗。
- 對於下載數據的記錄條數做限制。
但是兩種限制條件都不夠靈活,根據日期和記錄數做限制無法適用於所有的用戶,對於服務端我們希望的是對下載頻率的限制而不僅僅是對下載數據量的限制。通用的方法可以在後台設置一把鎖,這個鎖是有失效時間,比如3秒,每發送一次下載請求就添加一把鎖,使得規定時間限制之內的請求都無法獲取到鎖,也因此無法下載。
這個鎖可以用redis中的setnx實現,setnx的意思就是指定的 key 不存在時,為 key 設置指定的值。
邏輯可以寫成如下
lock := redis.setnx(key, value)
if !lock {
// 上鎖失敗,流程終止
return
}
// 設置失效時間
redis.expire(key, 3)
// 以下下載流程
download
說明
- 首先用setnx設置一把鎖,key在業務中可以用項目名+用戶id來實現,比如”project-product-download:user_id”,因為對於下載操作來說,肯定是只暴露給已經認證登錄的用戶,value的設置可以不做限制
- 如果lock==1,說明設置成功,否則設置上鎖失敗,退出
- 為了控制下載頻率,用expire對key設置有效時間為3s,3s之內進來的下載請求都會獲取鎖失敗。
以上邏輯可以完成功能,但是在極端情況下確實可能出現問題,就是setnx獲取鎖和expire不是原子性操作,假設有一極端情況,一個請求發進來setnx獲取到鎖,還沒來得及執行expire設置鎖的過期時間,服務就宕機了,那是不是鎖永遠不會到失效時間而永遠存在?用戶也就無法再進行下載,這個問題可以使用set命令解決,我們先來看一下這個命令的語法
SET key value [EX seconds] [PX milliseconds] [NX|XX]
從 Redis 2.6.12 版本開始, SET 命令的行為可以通過一系列參數來修改:
- EX seconds : 將鍵的過期時間設置為 seconds 秒。 執行 SET key value EX seconds 的效果等同於執行 SETEX key seconds value 。
- PX milliseconds : 將鍵的過期時間設置為 milliseconds 毫秒。 執行 SET key value PX milliseconds 的效果等同於執行 PSETEX key milliseconds value 。
- NX : 只在鍵不存在時, 才對鍵進行設置操作。 執行 SET key value NX 的效果等同於執行 SETNX key value 。
- XX : 只在鍵已經存在時, 才對鍵進行設置操作。
那麼在邏輯中,用set代替setnx如下
lock := redis.set(key,value,"NX","EX",3)
if !lock {
// 上鎖失敗,流程終止
return
}
// 以下為下載流程
download
也就是當redis中key不存在的時候,才能設置鎖成功,如果設置成功,則設置失效時間為3s。
問題:有的場景下set可以作為分散式鎖實現,多用戶之間共享資源的問題,那麼這裡怎麼解決鎖被誤刪問題?
答:這裡對於下載請求的時候,首先是只對登錄過的用戶開放,設置鎖的時候是根據用戶的id進行設置的key,不同的用戶設置的也就是不同的key,因此不存在誤刪的問題。
三、總結
- 首先,在上篇文中通用的管理功能分頁查詢中,介紹了sql語句的實現和可能的查詢優化方案。
- 在本文中,對分頁首次查詢獲取到數據之後,接著進行二次查詢的情況進行了介紹,涉及到了對鎖的使用和waitgroup的封裝,並發讀數據和並發寫數據的操作和一些注意事項。
- 接著對於數據整合之後的數據下載需求,限制用戶操作頻率,通過使用redis鎖給出了實現。


