GNN手繪草圖識別新架構:Multi-Graph Transformer 網路
- 2020 年 2 月 21 日
- 筆記
來源:公眾號 我愛電腦視覺 授權轉
本文介紹一篇比較小眾但非常有意思的手繪草圖識別的新文章《Multi-Graph Transformer for Free-Hand Sketch Recognition》,其實質是提出了一種新穎的 Transformer 網路。

該文作者資訊:

作者均來自南洋理工大學。
Ⅰ 研究動機
通常,Transformer 的輸入是序列化輸入形式,若給定一個句子作為輸入,Transformer 允許句子 中的全部詞之間建立相互關聯的 attention 關係。所以,本質上講,Transformer 把輸入的每個句子看作一個全連接的圖(fully-connected graph),Transformer 也算是一種特殊的圖神經網路 (GNN)。然而, 如何能為 Transformer 注入先驗知識去引導它更精細化地學習圖上的結構模式,是一個值得思考的問 題。該文提出以手繪草圖作為一種 GNN 的實驗床,探索新穎的 Transformer 網路。
手繪草圖(free-hand sketch)是一種特殊數據,本質上是一種動態的序列化的數據形式。因為,手繪的過程本身就是一個「連點成線」的過程(如下圖 1(b)所示)。
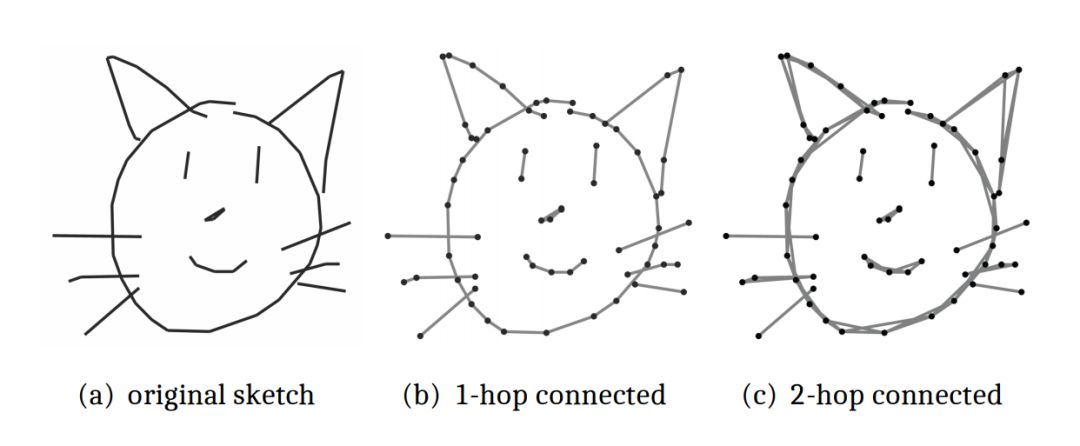
圖 1: 手繪草圖的離散化理解示意圖
已有的手繪草圖研究工作均在歐氏空間中對手繪草圖進行建模,手繪草圖被理解為靜態圖片輸入 到 CNN 中,或者被理解為筆畫的關鍵點的坐標序列輸入到 RNN 中。
然而,在實時性要求較高的人機交互場景中,存儲和傳輸圖片會引起較大的開銷,存儲和傳輸筆畫的關鍵點的坐標是更好的選擇。文本的主要動機就是將手繪草圖表示為稀疏圖,將筆畫的關鍵點理解為結點(node),且在幾何空間中使用 Transformer 對其進行建模,從更具普適性的角度去理解並表示手繪草圖。
通過實驗,該文發現且證實了,原版的 Transformer(Vanilla Transformer)並不能對手繪草圖進行合理地表示。所以,該文提出了一種新穎的圖神經網路,即 Multi-Graph Transformer(MGT)網路結構,將每一張手繪草圖表示為多個圖結構(multiple graph structure),並且這些圖結構中融入了手繪草圖的領域知識(domain knowledge)(如上圖 1(b)和 1(c)所示)。
該文所提出的 Multi-Graph Transformer 網路也可以用於其他結構化且序列化的數據建模當中。
Ⅱ Multi-Graph Transformer (MGT)
該文所提出的網路結構可分為三個部分:
(1)網路的輸入層;
(2)網路的主幹,即多層的Multi-Graph Transformer 結構;
(3)網路的輸出層,即分類器。
2.1 Multi-Modal Input Layer
該文採用 Google QuickDraw 數據,對每一張手繪草圖都取前 100 個筆畫關鍵點,對多於 100 個關鍵點或者少於 100 個關鍵點的手繪草圖進行截斷(truncation)或者補零(padding)操作。每個結點被表示為 4 維的向量,前兩位是該結點在畫布上的橫縱坐標,第三位是用於描述畫筆狀態的標誌位,第四位是位置編碼。橫縱坐標通過線性層進行升維,標誌位和位置編碼通過 embedding layer 進行升維, 它們升維之後拼接(concatenate)起來構成 MGT 的輸入。

圖 2: Multi-Graph Transformer 網路結構圖
2.2 Multi-Graph Transformer
如圖 2所示,整體上看,該文所提出的 Multi-Graph Transformer(MGT)是一個 L 層的結構,每層由兩個子層構成,分別是 Multi-Graph Multi-Head Attention(MGMHA)sub-layer 和 position-wise fully connected Feed-Forward (FF)sub-layer。
該文所提出的 MGMHA 子層是一個多路並行結構,每一路都是一個基於圖結構的 Multi-Head Attention 模組。這裡的「圖」結構是由該文基於手繪草圖的領域知識所定義的圖結構,也就是在原文中所定義的多種鄰接矩陣。使用這些鄰接矩陣來描述每張手繪草圖上結點間的連通性。
進而,在 Multi-Head Attention 操作中,使用鄰接矩陣所描述的連通性來控制注意力分數矩陣中的連通性,允許或者屏蔽掉特定結點間的注意力關係。
FF 子層主要進行殘差連接和 BN 等操作,這裡不做贅述。
2.3 Sketch Embedding and Classification Layer
給定一張草圖,經過 MGT 後,其每個結點都會被表示為一個向量,將這些結點的表示向量加起來作為該張草圖的向量表示。加和過程中,不考慮數據預處理過程中 padding 操作所引入的額外結點。網路尾端的分類器由多層感知器來實現,使用 softmax 交叉熵損失函數。
Ⅲ 實驗
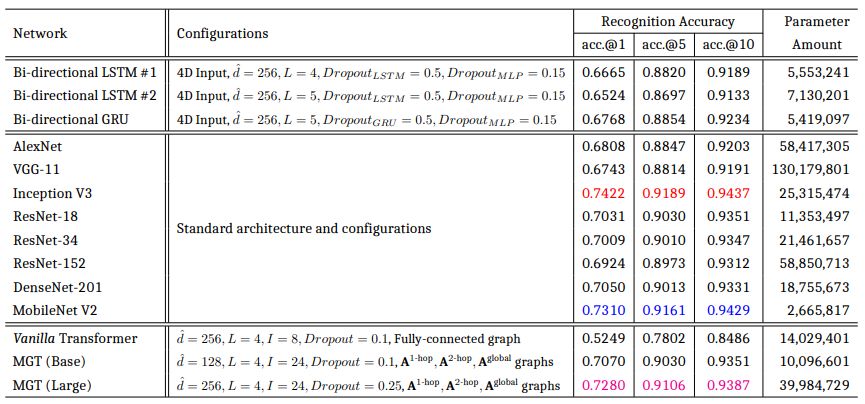
文中提供了 MGT 與眾多經典的 RNN 結構和 CNN 網路的性能比較,同時也提供了詳細的消融實驗結果及可視化結果。儘管數據預處理環節的截斷操作決定了 CNN 是 MGT 的性能上界,但是 MGT 所取得的識別準確率不僅遠高於基於 LSTM 和 GRU 的網路,而且還超越了眾多經典 CNN 網路,僅低於 Incetpion V3 和 MobileNet V2,但差距很微小。
表 1: Test set performance of MGT vs. the state-of-the-art RNN and CNN architectures. The 1 st/2 nd/3 rd best results per column are indicated inred/blue/magenta.
下圖給出了可視化的分析,將一張鬧鐘的草圖輸入到訓練好的 MGT 中,其經過每一層後得到相應的注意力權重(attention heads),這裡選取了其中一些有代表性的 heads。可以看到初始層的 heads 中,結點會更多地關注局部,消息傳遞是沿著筆畫展開的,高層的 heads 中,局部的注意力在逐漸淡 化,模型正在從全局地角度對圖上的關係進行聚合。
同時,基於全局圖結構先驗知識所學到的 attention heads 對跨筆畫的消息傳遞也很重要,例如可以捕獲鬧鐘的 body 和 feet 間的關係。

圖 3: 注意力權重可視化
Ⅳ 結論
該文提出了一種新穎的圖神經網路,即 Multi-Graph Transformer (MGT),同時也為手繪草圖提出了一種新穎的表示方法,即把每一張手繪草圖表示為多張稀疏連接的圖。文本所提出的 MGT 網路的主要特性包括:
(1)可以同時對手繪草圖中的幾何結構資訊和筆畫時序資訊進行建模;
(2)通過預 定義的多種圖結構為 Transformer 結構注入了領域知識;
(3)充分利用了手繪草圖的全局和局部圖結 構,即筆畫內的、筆畫之間的多重圖結構。
希望文本可以幫助手繪草圖領域的學者們從圖的角度對手繪數據在更具普適性的幾何空間中進行建模,同時幫助圖神經網路領域的學者們把手繪數據作為一種新型的實驗數據床。
論文鏈接:
https://arxiv.org/pdf/1912.11258.pdf
程式碼鏈接:
https://github.com/PengBoXiangShang/multigraph_transformer


