HashSet 添加/遍曆元素源碼分析
HashSet 類圖
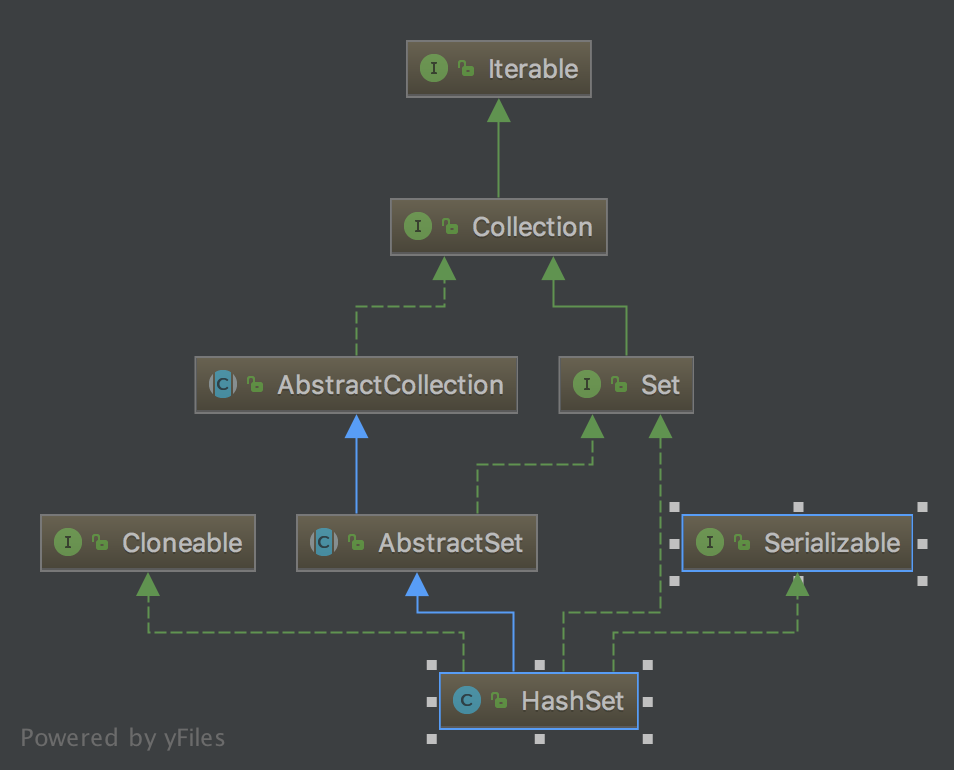
HashSet 簡單說明
HashSet實現了Set介面
HashSet底層實際上是由HashMap實現的
public HashSet() {
map = new HashMap<>();
}
- 可以存放
null,但是只能有一個null
HashSet不保證元素是有序的(即不保證存放元素的順序和取出元素的順序一致),取決於hash後,再確定索引的結果
- 不能有重複的元素
HashSet 底層機制說明
HashSet底層是HashMap,HashMap底層是 數組 + 鏈表 + 紅黑樹
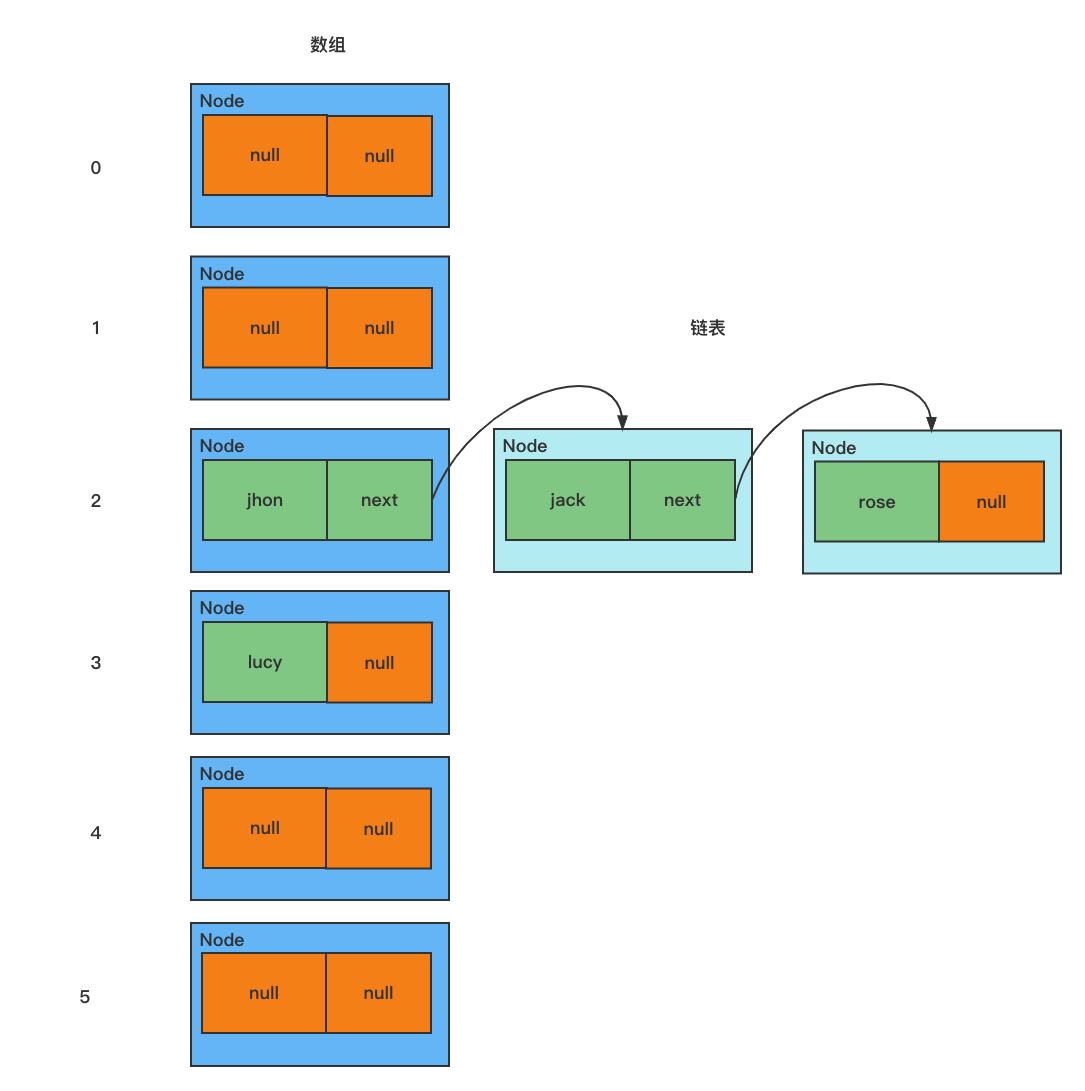
模擬數組+鏈表的結構
/**
* 模擬 HashSet 數組+鏈表的結構
*/
public class HashSetStructureMain {
public static void main(String[] args) {
// 模擬一個 HashSet(HashMap) 的底層結構
// 1. 創建一個數組,數組的類型為 Node[]
// 2. 有些地方直接把 Node[] 數組稱為 表
Node[] table = new Node[16];
System.out.println(table);
// 3. 創建節點
Node john = new Node("john", null);
table[2] = jhon; // 把節點 john 放在數組索引為 2 的位置
Node jack = new Node("jack", null);
jhon.next = jack; // 將 jack 掛載到 jhon 的後面
Node rose = new Node("rose", null);
jack.next = rose; // 將 rose 掛載到 jack 的後面
Node lucy = new Node("lucy", null);
table[3] = lucy; // 將 lucy 放在數組索引為 3 的位置
System.out.println(table);
}
}
// 節點類 存儲數據,可以指向下一個節點,從而形成鏈表
class Node{
Object item; // 存放數據
Node next; // 指向下一個節點
public Node(Object item, Node next){
this.item = item;
this.next = next;
}
}
HashSet 添加元素底層機制
HashSet 添加元素的底層實現
HashSet底層是HashMap
- 當添加一個元素時,會先得到 待添加元素的
hash值,然後將其轉換成一個 索引值
- 查詢存儲數據表(Node 數組)
table,看當前 待添加元素 所對應的 索引值 的位置是否已經存放了 其它元素
- 如果當前 索引值 所對應的的位置不存在 其它元素,就將當前 待添加元素 放到這個 索引值 所對應的的位置
- 如果當前 索引值 所對應的位置存在 其它元素,就調用
待添加元素.equals(已存在元素)比較,結果為true,則放棄添加;結果為false,則將 待添加元素 放到 已存在元素 的後面(已存在元素.next = 待添加元素)
HashSet 擴容機制
HashSet的底層是HashMap,第一次添加元素時,table數組擴容到cap = 16,threshold(臨界值) = cap * loadFactor(載入因子 0.75) = 12
- 如果
table數組使用到了臨界值 12,就會擴容到cap * 2 = 32,新的臨界值就是32 * 0.75 = 24,以此類推
- 在 Java8 中,如果一條鏈表上的元素個數 到達
TREEIFY_THRESHOLD(默認是 8),並且table的大小 >=MIN_TREEIFY_CAPACITY(默認是 64),就會進行 樹化(紅黑樹)
- 判斷是否擴容是根據
++size > threshold,即是否擴容,是根據HashMap所存的元素個數(size)是否超過臨界值,而不是根據table.length()是否超過臨界值
HashSet 添加元素源碼
/**
* HashSet 源碼分析
*/
public class HashSetSourceMain {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set = " + hashSet);
// 源碼分析
// 1. 執行 HashSet()
/**
* public HashSet() { // HashSet 底層是 HashMap
* map = new HashMap<>();
* }
*/
// 2. 執行 add()
/**
* public boolean add(E e) { // e == "java"
* // HashSet 的 add() 方法其實是調用 HashMap 的 put()方法
* return map.put(e, PRESENT)==null; // (static) PRESENT = new Object(); 用於佔位
* }
*/
// 3. 執行 put()
// hash(key) 得到 key(待存元素) 對應的hash值,並不等於 hashcode()
// 演算法是 h = key.hashCode()) ^ (h >>> 16
/**
* public V put(K key, V value) {
* return putVal(hash(key), key, value, false, true);
* }
*/
// 4. 執行 putVal()
// 定義的輔助變數:Node<K,V>[] tab; Node<K,V> p; int n, i;
// table 是 HashMap 的一個屬性,初始化為 null;transient Node<K,V>[] table;
// resize() 方法,為 table 數組指定容量
// p = tab[i = (n - 1) & hash] 計算 key的hash值所對應的 table 中的索引位置,將索引位置對應的 Node 賦給 p
/**
* final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
* boolean evict) {
* Node<K,V>[] tab; Node<K,V> p; int n, i; // 輔助變數
* // table 就是 HashMap 的一個屬性,類型是 Node[]
* // if 語句表示如果當前 table 是 null,或者 table.length == 0
* // 就是 table 第一次擴容,容量為 16
* if ((tab = table) == null || (n = tab.length) == 0)
* n = (tab = resize()).length;
* // 1. 根據 key,得到 hash 去計算key應該存放到 table 的哪個索引位置
* // 2. 並且把這個位置的索引值賦給 i;索引值對應的元素,賦給 p
* // 3. 判斷 p 是否為 null
* // 3.1 如果 p 為 null,表示還沒有存放過元素,就創建一個Node(key="java",value=PRESENT),並把這個元素放到 i 的索引位置
* // tab[i] = newNode(hash, key, value, null);
* if ((p = tab[i = (n - 1) & hash]) == null)
* tab[i] = newNode(hash, key, value, null);
* else {
* Node<K,V> e; K k; // 輔助變數
* // 如果當前索引位置對應的鏈表的第一個元素和待添加的元素的 hash值一樣
* // 並且滿足下面兩個條件之一:
* // 1. 待添加的 key 與 p 所指向的 Node 節點的key 是同一個對象
* // 2. 待添加的 key.equals(p 指向的 Node 節點的 key) == true
* // 就認為當前待添加的元素是重複元素,添加失敗
* if (p.hash == hash &&
* ((k = p.key) == key || (key != null && key.equals(k))))
* e = p;
* // 判斷 當前 p 是不是一顆紅黑樹
* // 如果是一顆紅黑樹,就調用 putTreeVal,來進行添加
* else if (p instanceof TreeNode)
* e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
* else {
* // 如果 當前索引位置已經形成一個 鏈表,就使用 for 循環比較
* // 將待添加元素依次和鏈表上的每個元素進行比較
* // 1. 比較過程中如果出現待添加元素和鏈表中的元素有相同的,比較結束,出現重複元素,添加失敗
* // 2. 如果比較到鏈表最後一個元素,鏈表中都沒出現與待添加元素相同的,就把當前待添加元素放到該鏈表最後的位置
* // 注意:在把待添加元素添加到鏈表後,立即判斷 該鏈表是否已經到達 8 個節點
* // 如果到達,就調用 treeifyBin() 對當前這個鏈表進行數化(轉成紅黑樹)
* // 注意:在轉成紅黑樹前,還要進行判斷
* // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
* // resize();
* // 如果上麵條件成立,先對 table 進行擴容
* // 如果上麵條件不成立,才轉成紅黑樹
* for (int binCount = 0; ; ++binCount) {
* if ((e = p.next) == null) {
* p.next = newNode(hash, key, value, null);
* if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
* treeifyBin(tab, hash);
* break;
* }
* if (e.hash == hash &&
* ((k = e.key) == key || (key != null && key.equals(k))))
* break;
* p = e;
* }
* }
* // e 不為 null ,說明添加失敗
* if (e != null) { // existing mapping for key
* V oldValue = e.value;
* if (!onlyIfAbsent || oldValue == null)
* e.value = value;
* afterNodeAccess(e);
* return oldValue;
* }
* }
* ++modCount;
* // 擴容:說明判斷 table 是否擴容不是看 table 的length
* // 而是看 整個 HashMap 的 size(即已存元素個數)
* if (++size > threshold)
* resize();
* afterNodeInsertion(evict);
* return null;
* }
*/
}
}
HashSet 遍曆元素底層機制
HashSet 遍曆元素底層機制
-
HashSet的底層是HashMap,HashSet的迭代器也是藉由HashMap來實現的 -
HashSet.iterator()實際上是去調用HashMap的KeySet().iterator()
public Iterator<E> iterator() {
return map.keySet().iterator();
}
KeySet()方法返回一個KeySet對象,而KeySet是HashMap的一個內部類
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
KeySet().iterator()方法返回一個KeyIterator對象,KeyIterator是HashMap的一個內部類
public final Iterator<K> iterator() { return new KeyIterator(); }
KeyIterator繼承了HashIterator(HashMap的內部類) 類,並實現了Iterator介面,即KeyIterator、HashIterator才是真正實現 迭代器 的類
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
-
當執行完
Iterator iterator = HashSet.iterator;之後,此時的iterator對象中已經存儲了一個元素節點-
怎麼做到的?
-
回到第 4 步,
KeySet().iterator()方法返回一個KeyIterator對象 -
new KeyIterator()調用KeyIterator的無參構造器 -
在這之前,會先調用其父類
HashIterator的無參構造器 -
因此,分析
HashIterator的無參構造器就知道發生了什麼/** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */ -
next、current、index都是HashIterator的屬性 -
Node<K,V>[] t = table;先把Node數組talbe賦給t -
current = next = null;current、next都置為null -
index = 0;index置為0 -
do {} while (index < t.length && (next = t[index++]) == null);這個do-while會在table中遍歷Node結點 -
一旦
(next = t[index++]) == null不成立 時,就說明找到了一個table中的Node結點 -
將這個節點賦給
next,並退出當前do-while循環 -
此時
Iterator iterator = HashSet.iterator;就執行完了 -
當前
iterator的運行類型其實是HashIterator,而HashIterator的next中存儲著從table中遍歷出來的一個Node結點
-
-
執行
iterator.hasNext-
此時的
next存儲著一個Node,所以並不為null,返回truepublic final boolean hasNext() { return next != null; }
-
-
執行
iterator.next()Node<K,V> e = next;把當前存儲著Node結點的next賦值給了e(next = (current = e).next) == null判斷當前結點的下一個結點是否為null- (a). 如果當前結點的下一個結點為
null,就執行do {} while (index < t.length && (next = t[index++]) == null);,在table數組中遍歷,尋找table數組中的下一個Node並賦值給next - (b). 如果當前結點的下一個結點不為
null,就將當前結點的下一個結點賦值給next,並且此刻不會去table數組中遍歷下一個Node結點
- (a). 如果當前結點的下一個結點為
- 將找到的結點
e返回 - 之後每次執行
iterator.next()都像 (a)、(b) 那樣去判斷遍歷,直到遍歷完成
HashSet 遍曆元素源碼
/**
* HashSet 源碼分析
*/
public class HashSetSourceMain {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set = " + hashSet);
// HashSet 迭代器實現原理
// HashSet 底層是 HashMap,HashMap 底層是 數組 + 鏈表 + 紅黑樹
// HashSet 本身沒有實現迭代器,而是藉由 HashMap 來實現的
// 1. hashSet.iterator() 實際上是去調用 HashMap 的 keySet().iterator()
/**
* public Iterator<E> iterator() {
* return map.keySet().iterator();
* }
*/
// 2. KeySet() 方法返回一個 KeySet 對象,而 KeySet 是 HashMap 的一個內部類
/**
* public Set<K> keySet() {
* Set<K> ks = keySet;
* if (ks == null) {
* ks = new KeySet();
* keySet = ks;
* }
* return ks;
* }
*/
// 3. KeySet().iterator() 方法返回一個 KeyIterator 對象,KeyIterator 是 HashMap的一個內部類
/**
* public final Iterator<K> iterator() { return new KeyIterator(); }
*/
// 4. KeyIterator 繼承了 HashIterator(HashMap的內部類) 類,並實現了 Iterator 介面
// 即 KeyIterator、HashIterator 才是真正實現 迭代器的類
/**
* final class KeyIterator extends HashIterator
* implements Iterator<K> {
* public final K next() { return nextNode().key; }
* }
*/
// 5. 當執行完 Iterator iterator = hashSet.iterator(); 後
// 此時的 iterator 對象中已經存儲了一個元素節點
// 怎麼做到的?
// 回到第 3 步,KeySet().iterator() 方法返回一個 KeyIterator 對象
// new KeyIterator() 調用 KeyIterator 的無參構造器
// 在這之前,會先調用 KeyIterator 父類 HashIterator 的無參構造器
// 因此分析 HashIterator 的無參構造器就知道發生了什麼
/**
* Node<K,V> next; // next entry to return
* Node<K,V> current; // current entry
* int expectedModCount; // for fast-fail
* int index; // current slot
* HashIterator() {
* expectedModCount = modCount;
* Node<K,V>[] t = table;
* current = next = null;
* index = 0;
* if (t != null && size > 0) { // advance to first entry
* do {} while (index < t.length && (next = t[index++]) == null);
* }
* }
*/
// 5.0 next, current, index 都是 HashIterator 的屬性
// 5.1 Node<K,V>[] t = table; 先把 Node 數組 table 賦給 t
// 5.2 current = next = null; 把 current 和 next 都置為 null
// 5.3 index = 0; index 置為 0
// 5.4 do {} while (index < t.length && (next = t[index++]) == null);
// 這個 do{} while 循環會在 table 中 遍歷 Node節點
// 一旦 (next = t[index++]) == null 不成立時,就說明找到了一個 table 中的節點
// 將這個節點賦給 next,並退出當前 do while循環
// 此時 Iterator iterator = hashSet.iterator(); 就執行完了
// 當前 iterator 的運行類型其實是 HashIterator,而 HashIterator 的 next 中存儲著從 table 中遍歷出來的一個 Node節點
// 6. 執行 iterator.hasNext()
/**
* public final boolean hasNext() {
* return next != null;
* }
*/
// 6.1 此時的 next 存儲著一個 Node,所以並不為 null,返回 true
// 7. 執行 iterator.next(),其實是去執行 HashIterator 的 nextNode()
/**
* final Node<K,V> nextNode() {
* Node<K,V>[] t;
* Node<K,V> e = next;
* if (modCount != expectedModCount)
* throw new ConcurrentModificationException();
* if (e == null)
* throw new NoSuchElementException();
* if ((next = (current = e).next) == null && (t = table) != null) {
* do {} while (index < t.length && (next = t[index++]) == null);
* }
* return e;
* }
*/
// 7.1 Node<K,V> e = next; 把當前存儲著 Node 節點的 next 賦值給了 e
// 7.2 (next = (current = e).next) == null
// 判斷當前節點的下一個節點是否為 null
// a. 如果當前節點的下一個節點為 null
// 就執行 do {} while (index < t.length && (next = t[index++]) == null);
// 再 table 數組中 遍歷,尋找 table 數組中的下一個 Node 並賦值給 next
// b. 如果當前節點的下一個節點不為 null
// 就將當前節點的下一個節點賦值給 next,並且此刻不會去 table 數組中遍歷下一個 Node 節點
// 7.3 將找到的節點 e 返回
// 7.4 之後每次執行 iterator.next(),都像 a、b 那樣去判斷遍歷,直到遍歷完成
Iterator iterator = hashSet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}


