GID:曠視提出全方位的檢測模型知識蒸餾 | CVPR 2021
論文提出的GID框架能夠自動選擇可辨別目標用於知識蒸餾,而且綜合了feature-based、relation-based和response-based知識,全方位蒸餾,適用於不同的檢測框架中。從實驗結果來看,效果十分不錯,值得一看
來源:曉飛的演算法工程筆記 公眾號
論文: General Instance Distillation for Object Detection

Introduction
在目標檢測應用場景中,模型的輕量化和準確率是同樣重要的,往往需要在速度和準確率之間權衡。知識蒸餾(Knowledge Distillation)是解決上述問題的一個有效方法,將大模型學習到的特徵提取規則(知識)轉移到小模型中,提升小模型的準確率,再將小模型用於實際場景中,達到模型壓縮的目的。
目前的知識蒸餾方法大都針對分類任務,目標檢測由於正負樣本極度不平衡,直接將現有的方法應用到檢測中一般都收益甚微。而目前提出的針對目標檢測任務的知識蒸餾方法大都對知識進行了特定的約束,比如控制蒸餾的正負樣本比例或只蒸餾GT相關的區域。此外,這些方法大都不能同時應用於多種目標檢測框架中。為此,論文希望找到通用的知識蒸餾方法,不僅能應用於各種檢測框架,還能轉移儘可能多的知識,同時不用關心正負樣本。
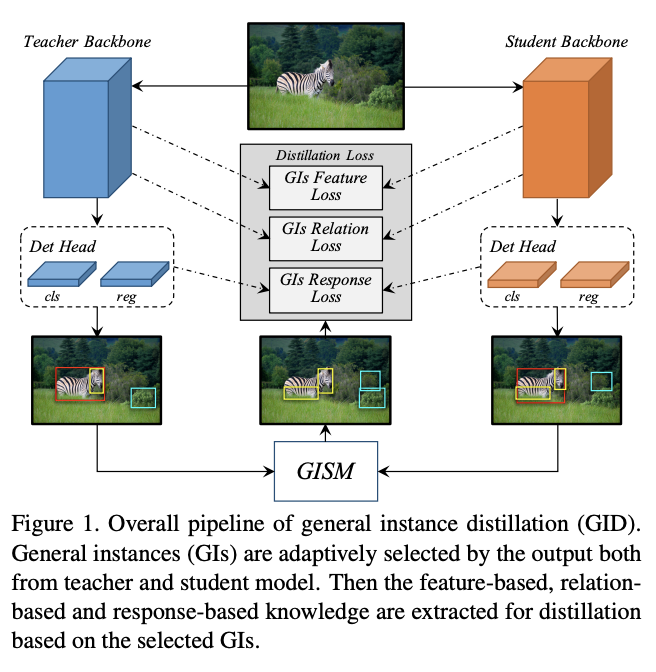
為了達到上述目的,論文結合response-based知識、feature-based知識和relation-based知識,提出了基於可辨別目標的蒸餾方法GID(general instances Distillation),主要優點有以下:
- 可以對單圖中的多個實例間的關係進行建模並用於蒸餾中。儘管已經有研究表明實例間的關係資訊在檢測中的重要性,但還沒有研究將其應用的知識蒸餾中。
- 避免手動設置正負樣本比例或只選擇GT相關區域進行蒸餾。雖然GT相關區域包含最多資訊,但背景也可能包含對student的泛化能力學習有幫助的資訊。論文通過實驗發現自動選擇的可辨別實例(discriminative instance)對遷移學習有明顯的提升作用,這些顯著實例也稱為通用實例(General Instance, GIs),因為不需要關心其正負。
- 對不同檢測框架通用,GIs是根據student和teacher的輸出進行選擇的,與網路的內部結構無關。
總結起來,論文的主要貢獻如下:
- 定義通用實例(GIs)作為蒸餾目標,能夠高效地提升檢測模型的蒸餾效果。
- 基於GI,首次將relation-based知識引入到知識蒸餾中,並與response-based知識和feature-based知識合作,使得student能超越teacher。
- 在MSCOCO和PASCAL VOC數據集上驗證不同檢測框架下的有效性,均達到SOTA。
General Instance Distillation
有研究提出GT附近的特徵區域包含有助於知識蒸餾訓練的豐富資訊,而論文發現不僅GT附近的區域,即使屬於背景的區域,只要是可辨別區域(discriminative patch)都對知識蒸餾有幫助。基於上面的發現,論文設計了通用實例選擇模組(general instance selection module, GISM),用於從teacher和student的輸出中選擇關鍵實例進行蒸餾。其次,為了更好地利用teacher的資訊,論文綜合使用了feature-based、relation-based和response-based知識用於蒸餾。
General Instance Selection Module
在檢測模型中,預測結果能夠指出資訊最豐富的區域,而teacher和student的豐富區域的差異恰恰就是性能的差異。為了量化每個結果的差異,選擇可辨別實例用於蒸餾,論文提出了兩個指標:GI score和GI box,在每次迭代中動態計算。為了減少計算消耗,通過計算分類分數的L1 score作為GI score,而GI box則直接選擇分類分數更高的box。
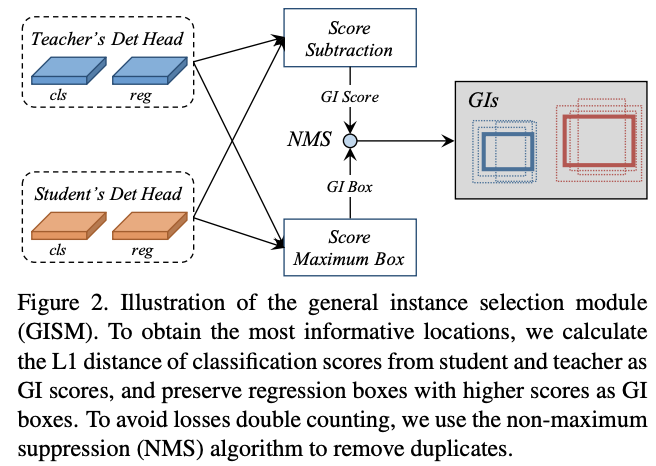
整個GI的選擇過程如圖2所示,對於實例r,其score和box的選擇定義為:
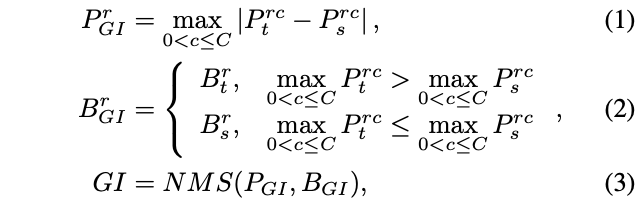
P_{GI}和B_{GI}分別為GI score和GI box。對於one-stage檢測器,P_t和P_s為teacher和student的分類分數,而對於two-stage檢測器則為RPN的objectness分數,B_t和B_s同理。R為預測框數目,C為類別數。由於論文將teacher和student的detection head設置成完全一樣的,所以預測框也是可以根據位置一一對應的。
需要注意的是,高GI score的實例可能重合度比較高,導致蒸餾損失翻倍。為解決這一問題,使用NMS來去重,遞歸選擇重複實例中GI score最高的實例。在實際使用中,NMS的IoU為0.3,最終每張圖片只選擇top-K個實例。
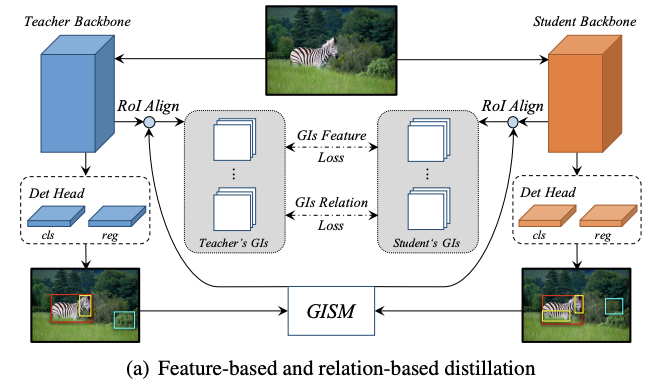
Feature-based Distillation
FPN接面合了主幹網路的不同層特徵,能夠顯著提升檢測模型對多尺度目標的魯棒性。於是,論文打算將FPN加入到蒸餾中,根據GI box的尺寸選擇對應的FPN層特徵。
由於每個FPN層的目標特徵大小不同,直接進行pixel-wise蒸餾會導致模型更傾向於大目標。於是論文轉而採用ROIAlign將不同大小的特徵輸出為相同大小再進行蒸餾,如圖a所示。feature-based蒸餾損失計算如下:
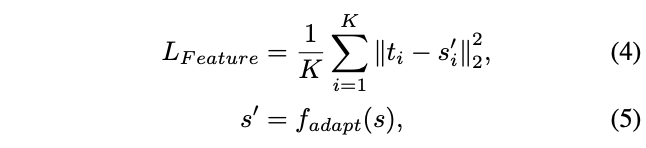
K為GISM選擇的GI數目,t_i和s_i為ROIAlign處理後的FPN特徵,f_{adapt}用於將s_i縮放到t_i的相同大小。
Relation-based Distillation
物體間的關係資訊是分類任務進行蒸餾的關鍵,但還沒在檢測任務蒸餾中進行嘗試。同一場景中的物體,不管是前景還是背景,都是高度相關的,這對student網路的收斂有很大幫助。
為了挖掘GIs中的關係知識,使用歐式距離來度量實例間的距離,然後用L1距離來傳遞知識。如圖a所示。relation蒸餾損失計算如下:
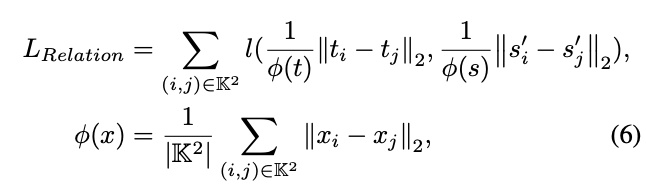
\mathbb{K}^2=\{(i,j)|i\ne j, 1\le i,j\le K\},\phi為歸一化因子,l為smooth L1損失。
Response-based Distillation
知識蒸餾的關鍵主要是來自teacher的response-based知識的約束,這裡的response-based知識指的是模型的最終輸出。但因為檢測輸出往往存在正負樣本不平衡或過多負樣本的情況,如果直接將detection head的所有輸出進行蒸餾,這種情況帶來的雜訊反而會損害student的性能。
有研究提出只蒸餾detection head的正樣本,但這種方法忽略了可辨別的負樣本的作用。為此,論文設計了distillation mask,將分類分支和回歸分支的輸出與GIs掛鉤,比只選擇正樣本要高效。
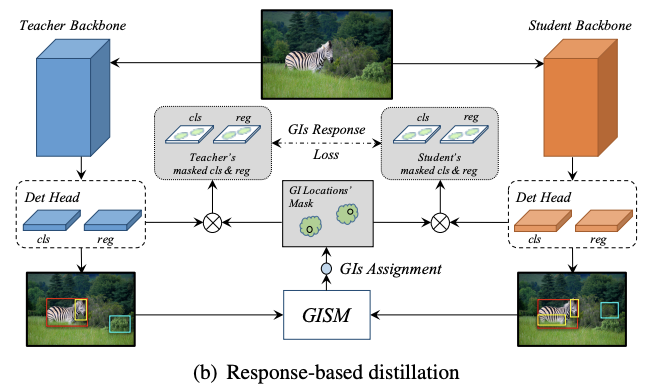
不同檢測模型的輸出是不同的,論文定義了一個通用的方法來進行detection head的蒸餾,如圖b所示。首先,基於GIs的distillation mask計算為:
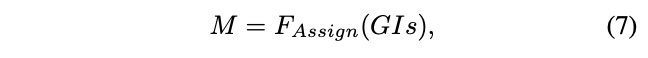
函數F是標籤指定演算法,輸入為GI box,當匹配時,輸出1,否則輸出0。函數F對不同的模型的定義是不同的,對於RetinaNet,使用anchor和GIs間的IoU決定是否匹配,而對於FCOS則所有中心點在GIs外的輸出都是0。
然後,response-based損失計算如下:
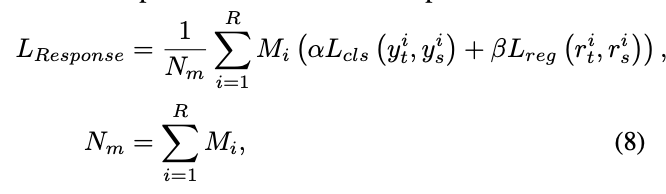
R為所有與選擇的GIs匹配的輸出,teacher和student對應的輸出其中一個匹配即可。y_t和y_s為分類分支輸出,r_t和r_s為回歸分支輸出,L_{cls}和L_{reg}為分類損失函數和回歸損失函數。需要注意的是,為了簡便,對於two-stage檢測器只蒸餾RPN輸出。
Overall loss function
模型的訓練是端到端的,student的整體損失函數為:
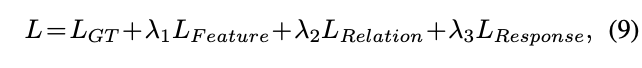
L_{GT}為模型原本的損失函數,\lambda為調節超參數。
Experiment
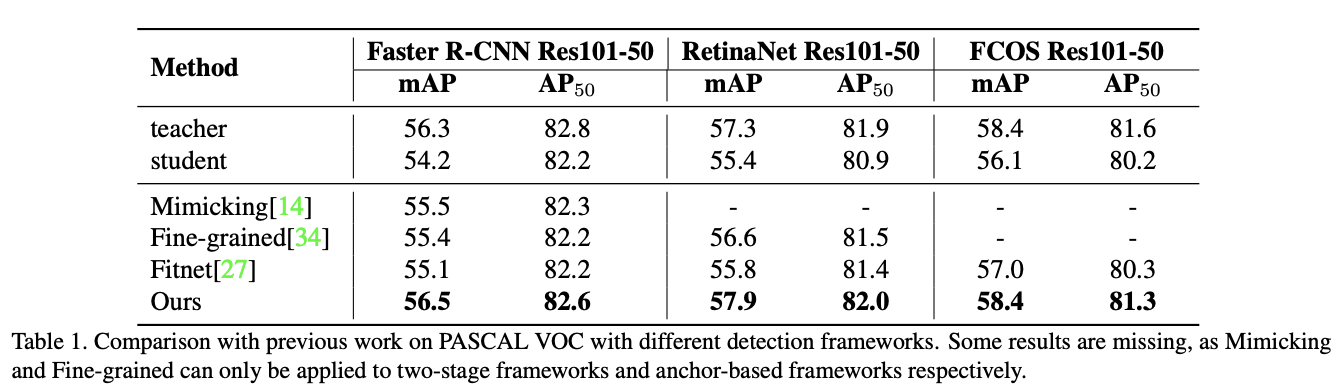
在VOC上對比蒸餾效果。
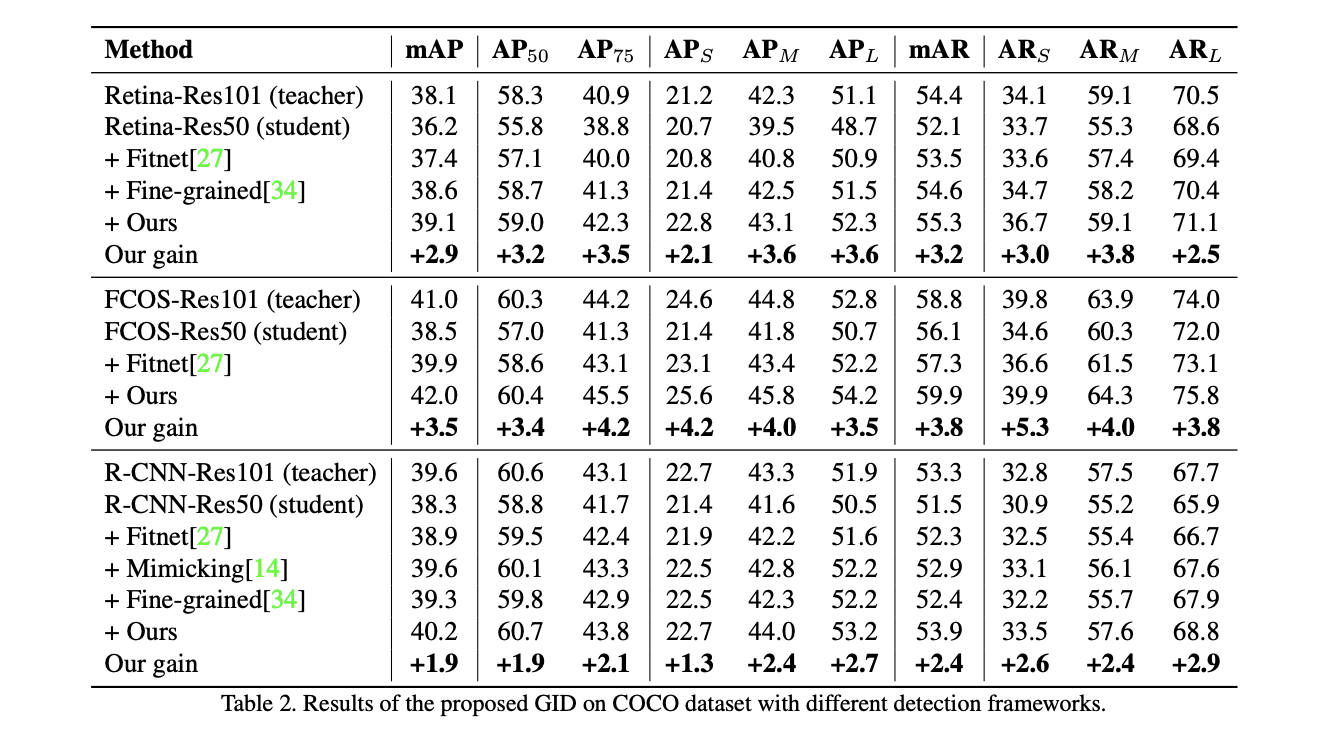
在COCO上對比蒸餾效果。
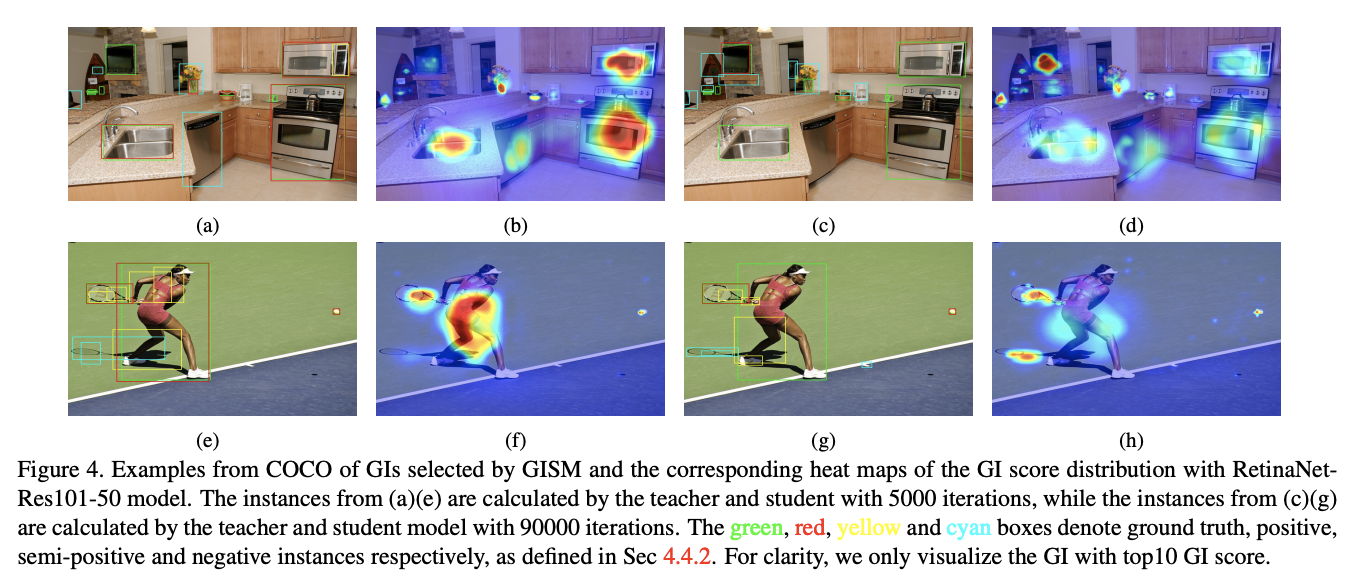
選擇的GI box可視化,前面為5000迭的選擇,後面為90000迭的選擇。綠色代表GT,紅色為正樣本,黃色為中間(非正非負)樣本,青色為負樣本。
Conclusion
論文提出的GID框架能夠自動選擇可辨別目標用於知識蒸餾,而且綜合了feature-based、relation-based和response-based知識,全方位蒸餾,適用於不同的檢測框架中。從實驗結果來看,效果十分不錯,值得一看。
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的演算法工程筆記】



