Involution:空間不共享?可完全替代卷積的高性能運算元 | CVPR 2021
其實這篇文章很早就寫好了,但作者其它論文涉及到洗稿問題,所以先放著了。目前看這篇文章沒被舉報有洗稿的嫌疑,所以就發出來了
.
來源:曉飛的演算法工程筆記 公眾號
論文: Involution: Inverting the Inherence of Convolution for Visual Recognition

Introduction
論文認為卷積操作有三個問題:
- 空間不變(spatial-agnostic)的計算方式雖然節省參數以及帶來平移不變性,卻也剝奪了卷積從不同位置發掘不同特徵的能力。
- 常用的卷積核大小為$3\times 3$,過小的感受野會約束與長距離特徵的互動,限制特徵提取能力。
- 卷積核的冗餘性已經被廣泛地發現。
為了解決上述的問題,論文提出了與卷積有相反屬性的操作involution,核參數在空間上面特異,而在通道上面共享,主要有以下兩個優點:
- 通道共享減少了大量參數,使得involution可以使用更大的核,從而能夠捕捉長距離特徵。
- 由於involution是空間特異的,相同的網路不同的輸入會產生不同大小的特徵圖,對應的核大小也不一樣,所以involution根據輸入特徵動態生成核參數,能夠自適應地提取更多的視覺資訊,達到類似attention的效果。
Design of Involution
一組involution核可表示為\mathcal{H}\in \mathbb{R}^{H\times W\times K\times K\times G},這裡的分組與卷積相反,增加分組是為了增加核的複雜性。對於像素X_{i,j}\in \mathbb{R}^C,其involution核為\mathcal{H}_{i,j,\cdot,\cdot,g}\in \mathbb{R}^{K\times K},g=1,2,\cdots,G為involtion核的分組,組內核共享。involution的特徵圖輸出通過對輸入特徵進行Multiply-Add操作得到:
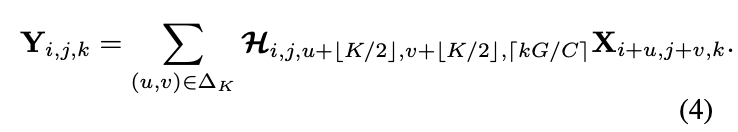
k為通道編號,involution核的大小取決於輸入特徵圖的大小,通過核生成函數\phi動態生成:
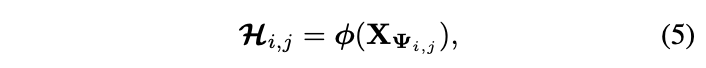
\Psi_{i,j}為\mathcal{H}_{i,j}對應的輸入像素合集。
Implementation Details
為了簡潔,論文直接從單個像素X_{i,j}生成對應的involution核\mathcal{H}_{i,j},更複雜的結構也許能帶來更好的性能,但不是當前主要的工作。定義核生成函數\phi:\mathbb{R}^C\mapsto\mathbb{R}^{K\times K\times G},\Psi_{i,j}=\{(i,j)\}:
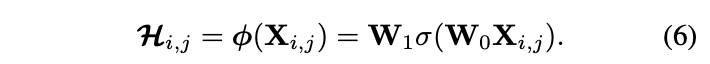
W_0\in\mathbb{R}^{\frac{C}{r}\times C}和W_1\in\mathbb{R}^{(K\times K\times G)\times\frac{C}{r}}為線性變換,共同構成一個bottleneck結構,r為壓縮因子,\sigma為BN+非線性激活。

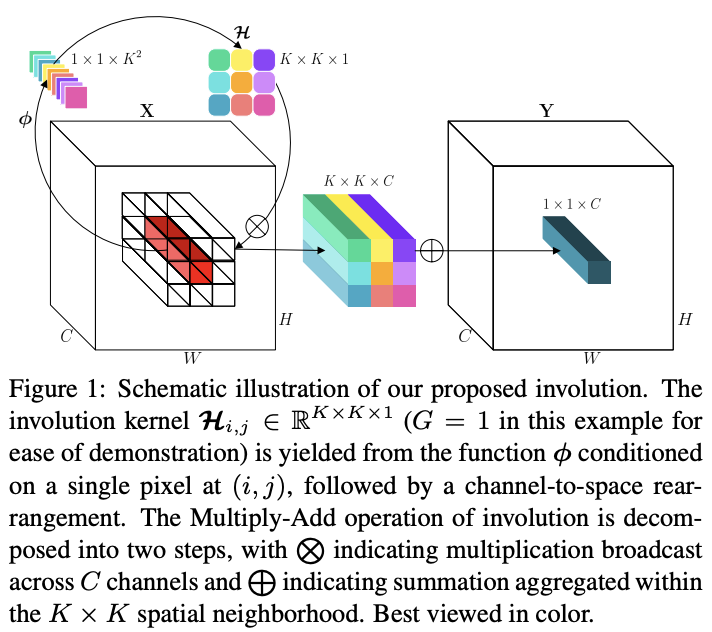
公式4和公式6可表示為演算法1和圖1,在每個位置(i,j)通過核生成函數生成對應的involution核,再對該位置進行計算得到輸出。
在構建完整的網路時,以ResNet作為基礎,將stem(開頭)的bottleneck中的$3\times 3卷積替換成$3\times 3或$7\times 7的involution,將trunk(後續)的bottleneck中的$3\times 3卷積替換成$7\times 7的involution,$1\times 1卷積保留用作通道融合與擴展。
Involution的優勢在於通道資訊在核生成時利用了起來,並且後續使用較大的感受野獲得更大的空間資訊。另外在使用時,前後的$1\times 1$卷積也增加了通道交互,從而提升了整體的性能。
In Context of Prior Literature
下面分別對involution進行兩方面的探討,分別是參數量下降的來源以及性能提升的來源。
Convolution and Variants
Involution的思想十分簡潔,從卷積的通道特異、空間共享轉換成通道共享、空間特異,我們從參數量和計算量兩塊來進行分析(不考慮bias和involution的G):
- 參數量方面,卷積和involution分別為C\times K\times K\times C和H\times W\times K\times K\times C,由於網路後續的特徵圖較小特點,involution能夠節省大量的參數。
- 計算量方面,不考慮核生成部分,卷積和involtion分別為H\times W \times C\times K\times K\times C和H\times W\times K\times K\times C,由於involution在輸出單像素結果時不需要像卷積那樣綜合多通道輸入,計算量減少了一個量級。
因為標準卷積實際上會融合多個輸入通道進行輸出,而且通道不共享,導致參數量和計算量都很高。而分組卷積減少了標準卷積中輸出通道與輸入通道之間的大量關聯,和invlotion在參數量和計算量上有十分相似的地方:
- 參數量方面,分組卷積和involution分別為\frac{C}{G}\times K\times K\times C和H\times W\times K\times K\times G,而G=C的分組卷積和G=1的involution的參數量分別為K\times K\times C和H\times W\times K\times K,兩者十分接近。
- 計算量方面,不考慮核生成部分,分組卷積和involution分別為\frac{C}{G}\times H\times W \times K\times K\times C和H\times W\times K\times K\times C,而G=C的分組卷積和G=1的involtion分別為H\times W\times K\times K\times C和H\times W\times K\times K\times C,兩者完全一致。
G=C的分組卷積即depthwise卷積,G=1的involution和depthwise卷積兩者在結構上也可以認為是完全對立的,一個則通道共享、空間獨立,另一個通道獨立、空間共享,而在depthwise卷積上加上空間特異的屬性即G=C的involution。但在之前很多的研究中,depthwise卷積一般都只用於輕量化網路的搭建,會犧牲部分準確率,而involution卻能在減少部分參數量的同時提升準確率。我覺得除了空間特異帶來大量參數之外,主要得益於兩個部分設計:1)核大小增加到$7\times 7$。 2) 根據輸入特徵動態生成核參數。如果將depthwise卷積按類似的設置替換卷積核,不知道能否達到類似的結果。
Attention Mechanism
self-attention起源於nlp任務,目前在視覺上的應用十分火熱,有不錯的性能表現。將輸入向量線性轉化成查詢項Q、關鍵詞項K以及值項V後,先用QK^{T}計算出相似性,再對值項加權後輸出,大致的公式為:
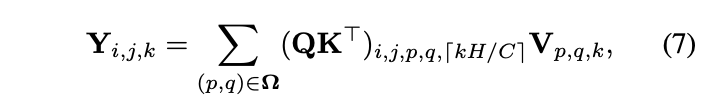
如果將involution的核生成函數\mathcal{H}看成是QK^{T}的話,則可認為involution在某種意義上等同於self-attention,position encoding的資訊也可認為是隱藏在了核生成函數裡面,與生成的位置相關。文章花了很多篇幅去說明involution是self-attention的高層定義,有興趣的可以去看看。不過我們只要理解,involution在特徵圖的不同位置動態生成了不同的核參數,功能上類似於self-attention中的attention即可,這也是involution能夠提升準確率的關鍵。
Experiment
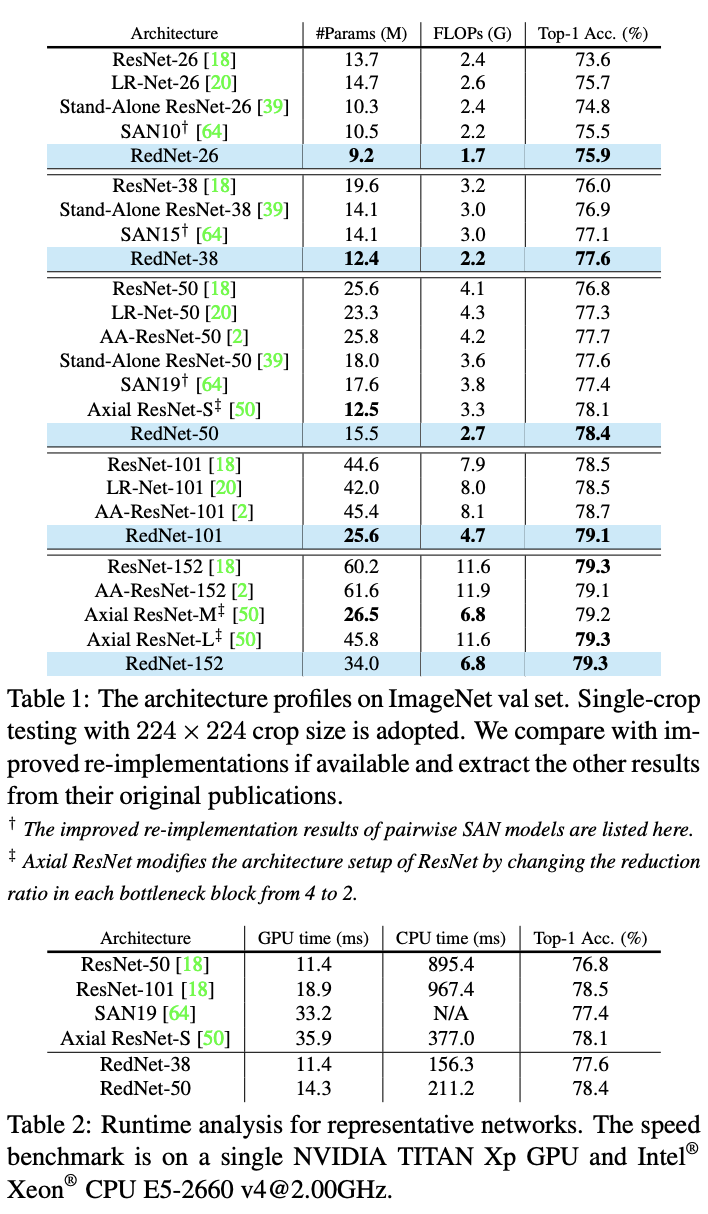
從實驗結果來看,由involution搭建的ReaNet能夠在準確率提升的情況下減少大量的參數,從實際速度來看,GPU速度與ResNet差不多,CPU速度則提升很大。
Conclusion
論文創新地提出了與卷積特性完全相反的基礎運算元Involution,該運算元在通道上共享,而在空間上特異,不僅能夠大幅減少參數量,還集成了attention的特性,在速度和準確率上都有很不錯的表現。
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的演算法工程筆記】



