Spark 3.x Spark Core詳解 & 性能優化
Spark Core
1. 概述
Spark 是一種基於記憶體的快速、通用、可擴展的大數據分析計算引擎
1.1 Hadoop vs Spark
上面流程對應Hadoop的處理流程,下面對應著Spark的處理流程
Hadoop
- Hadoop 是由 java 語言編寫的,在分散式伺服器集群上存儲海量數據並運行分散式 分析應用的開源框架
- 作為 Hadoop 分散式文件系統,HDFS 處於 Hadoop 生態圈的最下層,存儲著所有的 數 據 , 支援著 Hadoop的所有服務 。 它的理論基礎源於Google 的 The GoogleFile System 這篇論文,它是 GFS 的開源實現。
- MapReduce 是一種編程模型,Hadoop 根據 Google 的 MapReduce 論文將其實現, 作為 Hadoop 的分散式計算模型,是 Hadoop 的核心。基於這個框架,分散式並行 程式的編寫變得異常簡單。綜合了 HDFS 的分散式存儲和 MapReduce 的分散式計 算,Hadoop 在處理海量數據時,性能橫向擴展變得非常容易。
- HBase 是對 Google 的 Bigtable 的開源實現,但又和 Bigtable 存在許多不同之處。 HBase 是一個基於 HDFS 的分散式資料庫,擅長實時地隨機讀/寫超大規模數據集。 它也是 Hadoop 非常重要的組件。
Spark
- Spark 是一種由 Scala 語言開發的快速、通用、可擴展的大數據分析引擎
- Spark Core 中提供了 Spark 最基礎與最核心的功能
- Spark SQL 是 Spark 用來操作結構化數據的組件。通過 Spark SQL,用戶可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢數據。
- Spark Streaming 是 Spark 平台上針對實時數據進行流式計算的組件,提供了豐富的處理數據流的 API。
由上面的資訊可以獲知,Spark 出現的時間相對較晚,並且主要功能主要是用於數據計算, 所以其實 Spark 一直被認為是 Hadoop 框架的升級版。
Spark or Hadoop
- Hadoop MapReduce 由於其設計初衷並不是為了滿足循環迭代式數據流處理,因此在多並行運行的數據可復用場景(如:機器學習、圖挖掘演算法、互動式數據挖掘演算法)中存在諸多計算效率等問題。
- 所以 Spark 應運而生,Spark 就是在傳統的 MapReduce 計算框架的基礎上,利用其計算過程的優化,從而大大加快了數據分析、挖掘的運行和讀寫速 度,並將計算單元縮小到更適合併行計算和重複使用的 RDD 計算模型。
- Spark 是一個分散式數據快速分析項目。它的核心技術是彈性分散式數據集(Resilient Distributed Datasets),提供了比 MapReduce 豐富的模型,可以快速在記憶體中對數據集進行多次迭代,來支援複雜的數據挖掘演算法和圖形計算演算法。
- Spark 和Hadoop 的根本差異是多個作業之間的數據通訊問題 : Spark 多個作業之間數據 通訊是基於記憶體,而 Hadoop 是基於磁碟。
1.2 Spark 核心模組

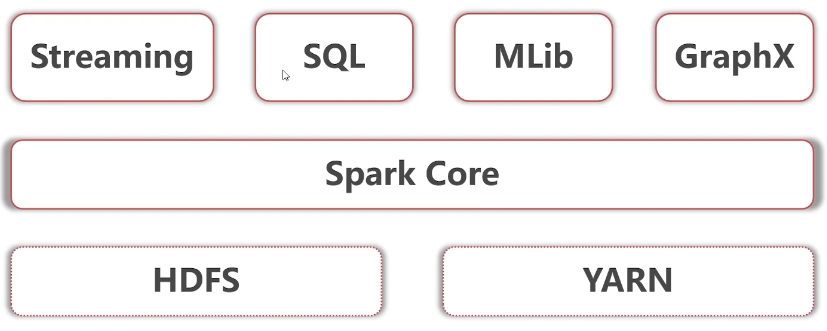
Spark Core
- Spark Core 中提供了 Spark 最基礎與最核心的功能,Spark 其他的功能如:Spark SQL, Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基礎上進行擴展的
Spark SQL
- Spark SQL 是 Spark 用來操作結構化數據的組件。通過 Spark SQL,用戶可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢數據。
Spark Streaming
- Spark Streaming 是 Spark 平台上針對實時數據進行流式計算的組件,提供了豐富的處理數據流的 API。
Spark MLlib
- MLlib 是 Spark 提供的一個機器學習演算法庫。MLlib 不僅提供了模型評估、數據導入等額外的功能,還提供了一些更底層的機器學習原語。
Spark Graphx
- GraphX 是 Spark 面向圖計算提供的框架與演算法庫。
1.3 Spark應用場景
- 低延時的海量數據計算需求
- 低延時SQL交互查詢需求
- 准實時(秒級)海量數據計算需求
2. Spark 運行環境
2.1 Local模式
所謂的 Local 模式,就是不需要其他任何節點資源就可以在本地執行 Spark 程式碼的環境,一般用於教學,調試,演示等
2.1.1 安裝部署
在官網下載安裝包,將 spark-XX-bin-hadoopXX.tgz 文件上傳到 Linux 並解壓縮,放置在指定位置,路徑中不要包含中文或空格。
tar -zxvf spark-XXX-bin-hadoop.XX.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local
2.1.2 啟動Local環境
-
進入解壓縮後的路徑,執行如下指令
bin/spark-shell可以在命令行中,執行scala命令,也可以調用spark
測試
在解壓縮文件夾下的 data 目錄中,添加 word.txt 文件。
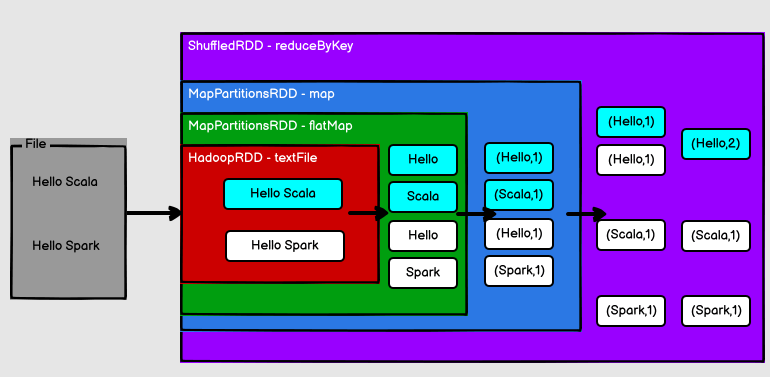
Hello Scala Hello Spark在命令行工具中執行如下程式碼指令
sc.textFile("data/word.txt").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).collect
-
啟動成功後,可以輸入網址進行 Web UI 監控頁面訪問
//虛擬機or本機ip地址:4040 -
退出
按鍵 Ctrl+C 或輸入 Scala 指令
:quit

2.1.3 提交應用
/opt/module/spark-local/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_XXXXXjar \
10
- –class
- 表示要執行程式的主類,此處可以更換為自己寫的應用程式
- –master local[2]
- 部署模式,默認為本地模式,數字表示分配的虛擬 CPU 核數量
- spark-examples_XXX.jar
- 運行的應用類所在的 jar 包(根據實際版本輸入),實際使用時,可以設定自己的 jar 包
- 數字 10 表示程式的入口參數,用於設定當前應用的任務數量
2.2 Standlone模式
local 本地模式畢竟只是用來進行練習演示的,真實工作中還是要將應用提交到對應的 集群中去執行,這裡我們來看看只使用 Spark 自身節點運行的集群模式,也就是我們所謂的 獨立部署(Standalone)模式。Spark 的 Standalone 模式體現了經典的 master-slave 模式。
集群規劃:

2.2.1 安裝部署
注意: 每個節點上配置相同,可配置一台節點,然後上傳到其他節點便可
解壓縮文件
將 spark-XXX.tgz 文件上傳到 Linux 並解壓縮在指定位置
tar -zxvf spark-XXX.tgz -C /opt/module
cd /opt/module
mv spark-XXX spark-standalone
修改配置文件
-
進入解壓縮後路徑的 conf 目錄,修改 workers.template 文件名為 workers
有些老版本是slaves.template
修改 slaves 文件,添加 worker 節點
# 根據自己的主機節點名進行添加 node1 node2 node3 -
修改 spark-env.sh.template 文件名為 spark-env.sh
修改 spark-env.sh 文件,添加 JAVA_HOME 環境變數和集群對應的 master 節點
# 根據實際情況進行修改 export JAVA_HOME=/XXX/jdkXXX SPARK_MASTER_HOST=node1 SPARK_MASTER_PORT=7077注意:7077 埠,相當於 hadoop3 內部通訊的 8020 埠,此處的埠需要確認自己的 Hadoop 配置
最後
將配置好的spark,分別上傳到每一個節點上
2.2.2 啟動集群
在任意節點上,執行腳本命令
/opt/module/spark-standlone/sbin/start-all.sh
查看 Master 資源監控 Web UI 介面: //node1:8080
關閉集群
/opt/module/spark-standlone/sbin/stop-all.sh
2.2.3 提交應用
/opt/module/spark-standlone/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077 \
./examples/jars/spark-examples_XXX.jar \
10
- –class 表示要執行程式的主類
- –master spark://linux1:7077 獨立部署模式,連接到 Spark 集群
- spark-examples_XXX.jar 運行類所在的 jar 包
- 數字 10 表示程式的入口參數,用於設定當前應用的任務數量
執行任務時,會產生多個 Java 進程
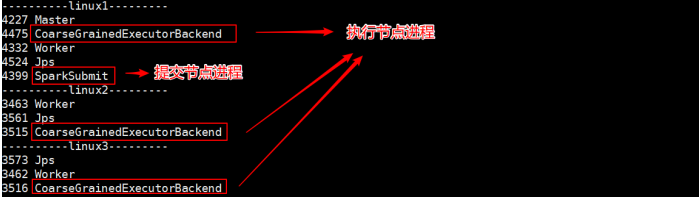
2.2.4 提交參數說明
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]

2.2.5 配置歷史服務
由於 spark-shell 停止掉後,集群監控 node1:4040 頁面就看不到歷史任務的運行情況,所以 開發時都配置歷史伺服器記錄任務運行情況
-
修改 spark-defaults.conf.template 文件名為 spark-defaults.conf
修改 spark-defaults.conf 文件,配置日誌存儲路徑
spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/logs注意:路徑自己設置,需要啟動 hadoop 集群,HDFS 上的 directory 目錄需要提前存在。
-
修改 spark-env.sh 文件, 添加日誌配置
前後路徑保持一致
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://node1:8020/logs -Dspark.history.retainedApplications=30"參數 1 含義:WEB UI 訪問的埠號為 18080
參數 2 含義:指定歷史伺服器日誌存儲路徑
參數 3 含義:指定保存 Application 歷史記錄的個數,如果超過這個值,舊的應用程式 資訊將被刪除,這個是記憶體中的應用數,而不是頁面上顯示的應用數。
注意:每一個節點上配置保持一致
重新啟動集群和歷史服務
/opt/module/spark-standlone/sbin/start-all.sh
/opt/module/spark-standlone/sbin/start-history-server.sh
重新執行任務
/opt/module/spark-standlone/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077 \
./examples/jars/spark-examples_XXX.jar \
10
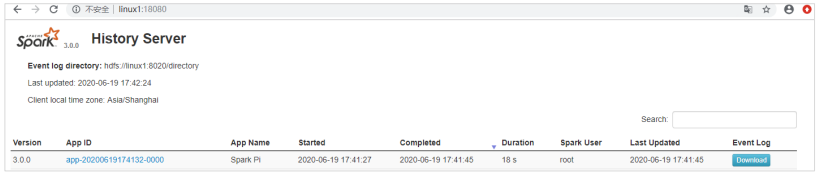
查看歷史服務://node1:18080
2.3 YARN模式
獨立部署(Standalone)模式由 Spark 自身提供計算資源,無需其他框架提供資源。這種方式降低了和其他第三方資源框架的耦合性,獨立性非常強。但是,Spark 主要是計算框架,而不是資源調度框架,所以本身提供的資源調度並不是它的強項,所以還是和其他專業的資源調度框架集成會更靠譜一些。
2.3.1 安裝部署
注意: 每個節點上配置相同,可配置一台節點,然後上傳到其他節點便可
解壓縮文件
將 spark-XXX.tgz 文件上傳到 Linux 並解壓縮在指定位置
tar -zxvf spark-XXX.tgz -C /opt/module
cd /opt/module
mv spark-XXX spark-yarn
修改配置文件
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR\HADOOP_CONF_DIR 配置
export JAVA_HOME=/XXX/jdk1XX
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
2.3.2 啟動集群
啟動HDFS和YARN集群
2.3.3 提交應用
/opt/module/spark-yarn/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_XXX.jar \
10
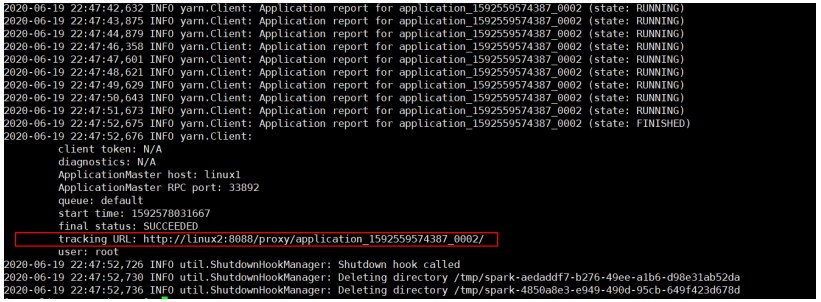
查看顯示的鏈接頁面,點擊 History,查看歷史頁面
2.2.4 配置歷史服務
-
修改 spark-defaults.conf.template 文件名為 spark-defaults.conf
修改 spark-default.conf 文件,配置日誌存儲路徑
spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/logs注意:需要啟動 hadoop 集群,HDFS 上的目錄需要提前存在
-
修改 spark-env.sh 文件, 添加日誌配置
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://node1:8020/logs -Dspark.history.retainedApplications=30"參數 1 含義:WEB UI 訪問的埠號為 18080
參數 2 含義:指定歷史伺服器日誌存儲路徑
參數 3 含義:指定保存 Application 歷史記錄的個數,如果超過這個值,舊的應用程式 資訊將被刪除,這個是記憶體中的應用數,而不是頁面上顯示的應用數。
-
修改 spark-defaults.conf
spark.yarn.historyServer.address=node1:18080 spark.history.ui.port=18080注意:每一個節點上配置保持一致
-
啟動歷史服務
sbin/start-history-server.sh -
重新提交應用
/opt/module/spark-yarn/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ ./examples/jars/spark-examples_XXX.jar \ 10
3. Spark 運行架構
3.1 運行架構
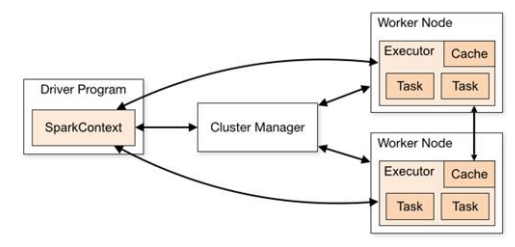
Spark 框架的核心是一個計算引擎,整體來說,它採用了標準 master-slave 的結構。
如下圖所示,它展示了一個 Spark 執行時的基本結構。圖形中的 Driver 表示 master,負責管理整個集群中的作業任務調度。圖形中的 Executor 則是 slave,負責實際執行任務。
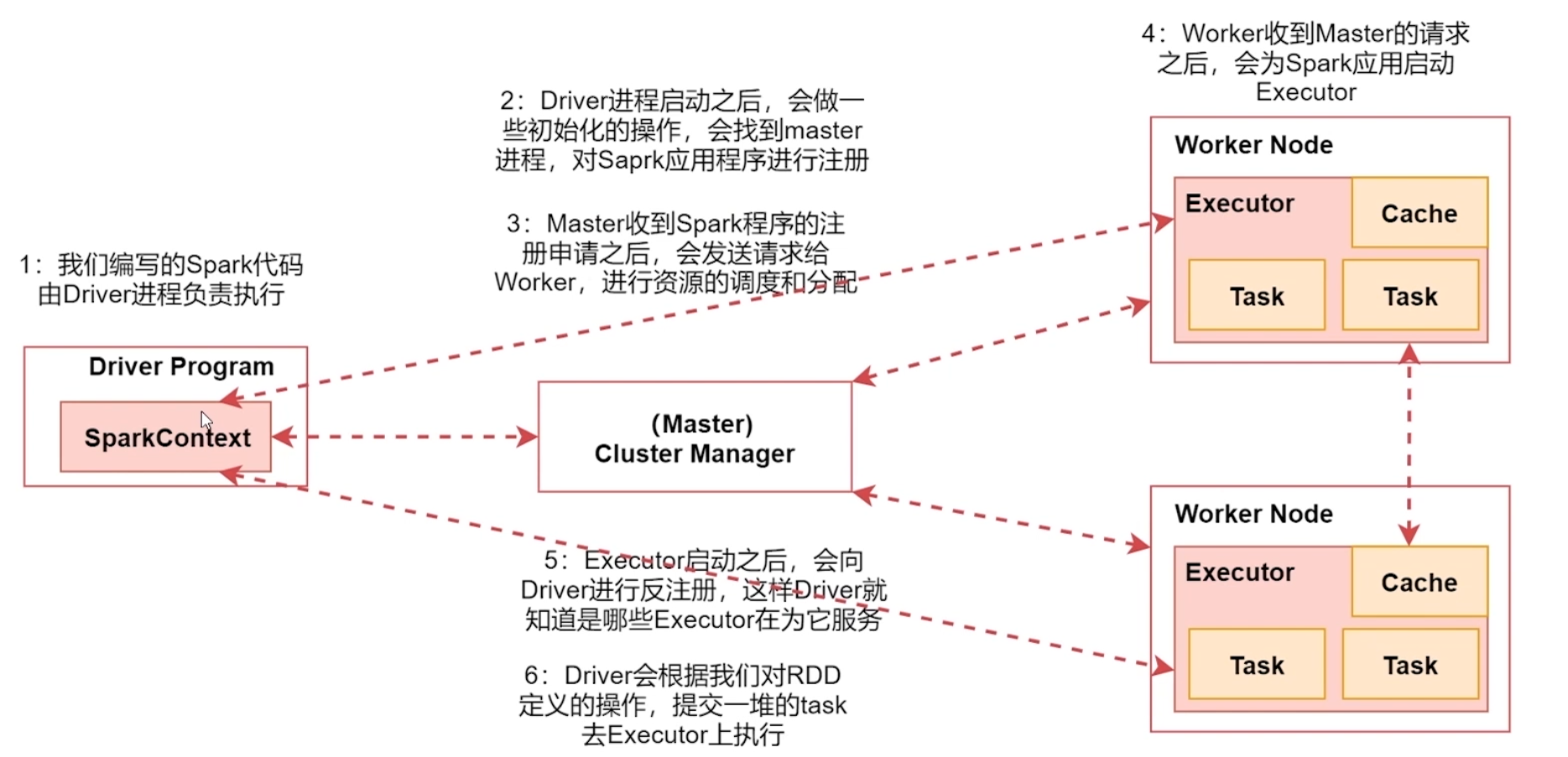
3.2 核心組件
3.2.1 Driver & Executor
計算組件
Driver
Spark 驅動器節點,用於執行 Spark 任務中的 main 方法,負責實際程式碼的執行工作。
Driver 在 Spark 作業執行時主要負責:
- 將用戶程式轉化為作業(job)
- 在 Executor 之間調度任務(task)
- 跟蹤 Executor 的執行情況
- 通過 UI 展示查詢運行情況
實際上,我們無法準確地描述 Driver 的定義,因為在整個的編程過程中沒有看到任何有關Driver 的字眼。所以簡單理解,所謂的 Driver 就是驅使整個應用運行起來的程式,也稱之為Driver 類。
Executor
Spark Executor 是集群中工作節點(Worker)中的一個 JVM 進程,負責在 Spark 作業中運行具體任務(Task),任務彼此之間相互獨立。Spark 應用啟動時,Executor 節點被同時啟動,並且始終伴隨著整個 Spark 應用的生命周期而存在。如果有 Executor 節點發生了故障或崩潰,Spark 應用也可以繼續執行,會將出錯節點上的任務調度到其他 Executor 節點上繼續運行。
Executor 有兩個核心功能:
- 負責運行組成 Spark 應用的任務,並將結果返回給驅動器進程
- 它們通過自身的塊管理器(Block Manager)為用戶程式中要求快取的 RDD 提供記憶體式存儲。RDD 是直接快取在 Executor 進程內的,因此任務可以在運行時充分利用快取 數據加速運算。
3.2.2 Master & Worker
資源管理組件
Spark 集群的獨立部署環境中,不需要依賴其他的資源調度框架,自身就實現了資源調度的功能,所以環境中還有其他兩個核心組件:Master 和 Worker,這裡的 Master 是一個進 程,主要負責資源的調度和分配,並進行集群的監控等職責,類似於 Yarn 環境中的 RM, 而 Worker 呢,也是進程,一個 Worker 運行在集群中的一台伺服器上,由 Master 分配資源對 數據進行並行的處理和計算,類似於 Yarn 環境中 NM。
3.2.3 ApplicationMaster
Hadoop 用戶向 YARN 集群提交應用程式時,提交程式中應該包含 ApplicationMaster,用於向資源調度器申請執行任務的資源容器 Container,運行用戶自己的程式任務 job,監控整個任務的執行,跟蹤整個任務的狀態,處理任務失敗等異常情況。
說的簡單點就是,ResourceManager(資源)和 Driver(計算)之間的解耦合靠的就是 ApplicationMaster。
3.3 核心概念
3.3.1 Executor 與 Core
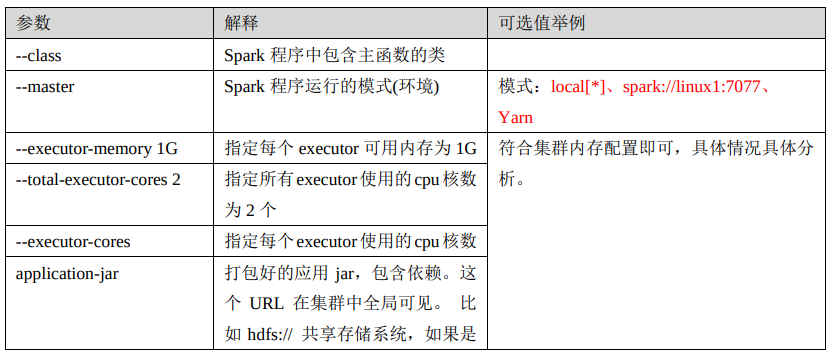
Spark Executor 是集群中運行在工作節點(Worker)中的一個 JVM 進程,是整個集群中的專門用於計算的節點。在提交應用中,可以提供參數指定計算節點的個數,以及對應的資源。這裡的資源一般指的是工作節點 Executor 的記憶體大小和使用的虛擬 CPU 核(Core)數 量。
應用程式相關啟動參數如下:

3.3.2 並行度(Parallelism)
在分散式計算框架中一般都是多個任務同時執行,由於任務分布在不同的計算節點進行計算,所以能夠真正地實現多任務並行執行,記住,這裡是並行,而不是並發。這裡我們將整個集群並行執行任務的數量稱之為並行度。
那麼一個作業到底並行度是多少呢?這個取決於框架的默認配置。應用程式也可以在運行過程中動態修改。
3.3.3 有向無環圖(DAG)
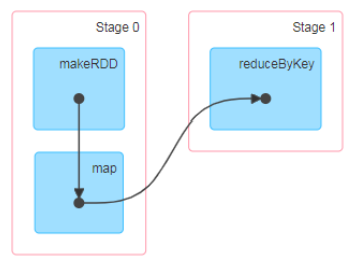
資源之間的依賴關係,不能成環,會形成死鎖
大數據計算引擎框架我們根據使用方式的不同一般會分為四類:
- 其中第一類就是 Hadoop 所承載的 MapReduce,它將計算分為兩個階段,分別為 Map 階段 和 Reduce 階段
- 對於上層應用來說,就不得不想方設法去拆分演算法,甚至於不得不在上層應用實現多個 Job 的串聯,以完成一個完整的演算法,例如迭代計算。 由於這樣的弊端,催生了支援 DAG 框 架的產生。
- 因此,支援 DAG 的框架被劃分為第二代計算引擎。如 Tez 以及更上層的 Oozie。
- 接下來就是以 Spark 為代表的第三代的計算引擎。第三代計算引擎的特點主要是 Job 內部的 DAG 支援(不跨越 Job),以及實時計算。
這裡所謂的有向無環圖,並不是真正意義的圖形,而是由 Spark 程式直接映射成的數據流的高級抽象模型。簡單理解就是將整個程式計算的執行過程用圖形表示出來,這樣更直觀,更便於理解,可以用於表示程式的拓撲結構。
DAG(Directed Acyclic Graph)有向無環圖是由點和線組成的拓撲圖形,該圖形具有方向,不會閉環。
3.4 提交流程
基於Yarn環境
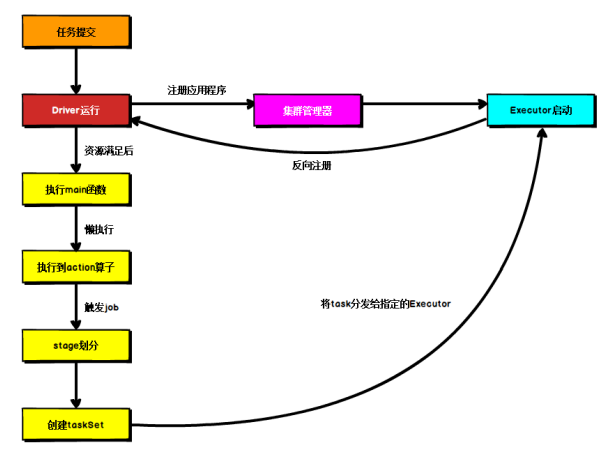
Spark 應用程式提交到 Yarn 環境中執行的時候,一般會有兩種部署執行的方式:Client 和 Cluster。
兩種模式主要區別在於:Driver 程式的運行節點位置
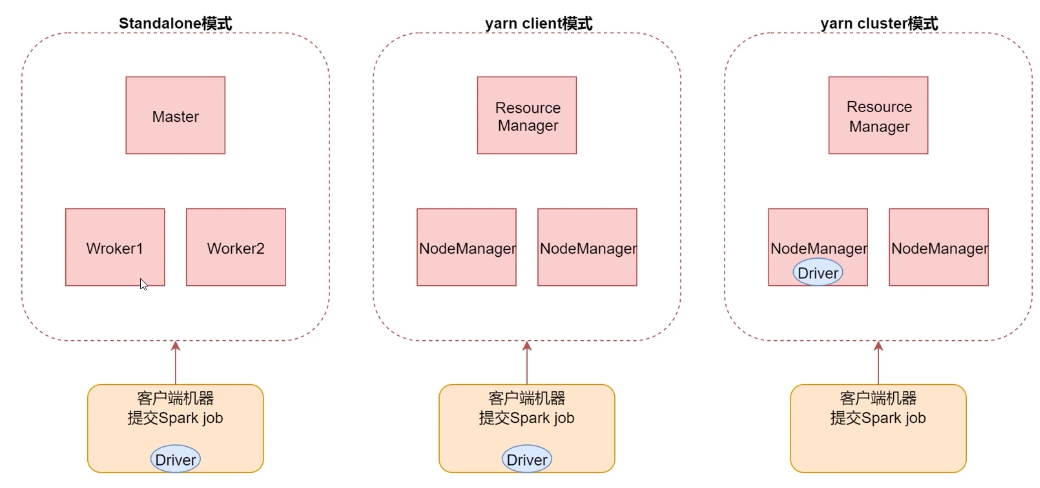
3.4.1 Yarn Client 模式
Client 模式將用於監控和調度的 Driver 模組在客戶端執行,而不是在 Yarn 中,所以一般用於測試
- Driver 在任務提交的本地機器上運行
- Driver 啟動後會和 ResourceManager 通訊申請啟動 ApplicationMaster
- ResourceManager 分配 container,在合適的 NodeManager 上啟動 ApplicationMaster,負責向 ResourceManager 申請 Executor 記憶體
- ResourceManager 接到 ApplicationMaster 的資源申請後會分配 container,然後 ApplicationMaster 在資源分配指定的 NodeManager 上啟動 Executor 進程
- Executor 進程啟動後會向 Driver 反向註冊,Executor 全部註冊完成後 Driver 開始執行 main 函數
- 之後執行到 Action 運算元時,觸發一個 Job,並根據寬依賴開始劃分 stage,每個 stage 生成對應的 TaskSet,之後將 task 分發到各個 Executor 上執行。
3.4.2 Yarn Cluster 模式
Cluster 模式將用於監控和調度的 Driver 模組啟動在 Yarn 集群資源中執行。一般應用於實際生產環境
- 在 YARN Cluster 模式下,任務提交後會和 ResourceManager 通訊申請啟動 ApplicationMaster
- 隨後 ResourceManager 分配 container,在合適的 NodeManager 上啟動 ApplicationMaster,此時的 ApplicationMaster 就是 Driver
- Driver 啟動後向 ResourceManager 申請 Executor 記憶體,ResourceManager 接到 ApplicationMaster 的資源申請後會分配 container,然後在合適的 NodeManager 上啟動 Executor 進程
- Executor 進程啟動後會向 Driver 反向註冊,Executor 全部註冊完成後 Driver 開始執行 main 函數
- 之後執行到 Action 運算元時,觸發一個 Job,並根據寬依賴開始劃分 stage,每個 stage 生成對應的 TaskSet,之後將 task 分發到各個 Executor 上執行。
4. Spark 核心編程
Spark 計算框架為了能夠進行高並發和高吞吐的數據處理,封裝了三大數據結構,用於處理不同的應用場景。
三大數據結構分別是:
- RDD : 彈性分散式數據集
- 累加器:分散式共享只寫變數
- 廣播變數:分散式共享只讀變數
4.1 RDD
4.1.1 什麼是 RDD
RDD(Resilient Distributed Dataset)叫做彈性分散式數據集,是 Spark 中最基本的數據處理模型。程式碼中是一個抽象類,它代表一個彈性的、不可變、可分區、裡面的元素可並行計算的集合。
-
彈性
-
存儲的彈性:記憶體與磁碟的自動切換
-
容錯的彈性:數據丟失可以自動恢復
-
計算的彈性:計算出錯重試機制
-
分片的彈性:可根據需要重新分片
-
-
分散式:數據存儲在大數據集群不同節點上
-
數據集:RDD 封裝了計算邏輯,並不保存數據
-
數據抽象:RDD 是一個抽象類,需要子類具體實現
-
不可變:RDD 封裝了計算邏輯,是不可以改變的,想要改變,只能產生新的 RDD,在新的 RDD 裡面封裝計算邏輯
-
可分區、並行計算
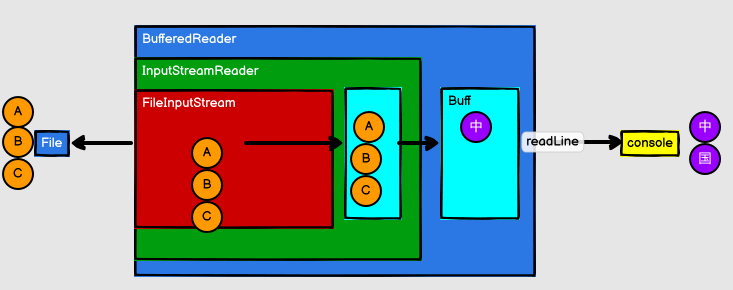
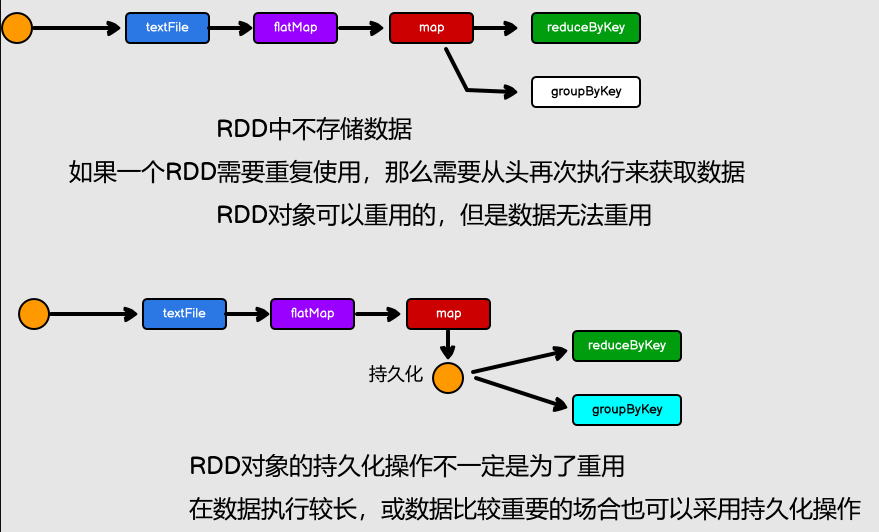
RDD vs IO
RDD的數據處理方式類似於IO流,也有裝飾者設計模式
RDD的數據只有在調用collect方法時,才會真正執行業務邏輯操作。之前的封裝全部都是功能上的擴展
RDD是不保存數據的,但是IO可以臨時保存一部分數據
4.1.2 核心屬性
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
分區列表
-
RDD 數據結構中存在分區列表,用於執行任務時並行計算,是實現分散式計算的重要屬性
protected def getPartitions: Array[Partition]
分區計算函數
-
Spark 在計算時,是使用分區函數對每一個分區進行計算
@DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
RDD 之間的依賴關係
-
RDD 是計算模型的封裝,當需求中需要將多個計算模型進行組合時,就需要將多個 RDD 建立依賴關係
protected def getDependencies: Seq[Dependency[_]] = deps
分區器(可選)
-
當數據為 KV 類型數據時,可以通過設定分區器自定義數據的分區
@transient val partitioner: Option[Partitioner] = None
首選位置(可選)
-
計算數據時,可以根據計算節點的狀態選擇不同的節點位置進行計算
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
4.1.3 執行原理
-
數據處理過程中需要計算資源(記憶體 & CPU)和計算模型(邏輯)。執行時,需要將計算資源和計算模型進行協調和整合
-
Spark 框架在執行時,先申請資源,然後將應用程式的數據處理邏輯分解成一個一個的計算任務。然後將任務發到已經分配資源的計算節點上, 按照指定的計算模型進行數據計算。最後得到計算結果
RDD 是 Spark 框架中用於數據處理的核心模型,接下來我們看看,在 Yarn 環境中,RDD的工作原理
-
啟動 Yarn 集群環境
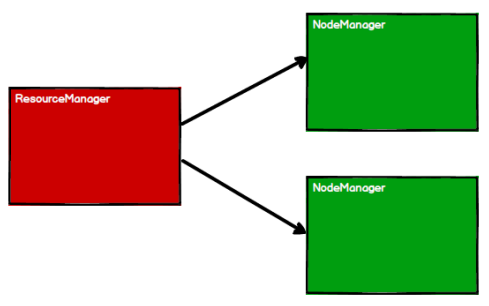
-
Spark 通過申請資源創建調度節點和計算節點
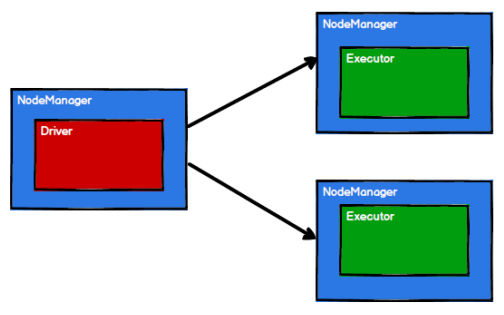
-
Spark 框架根據需求將計算邏輯根據分區劃分成不同的任務
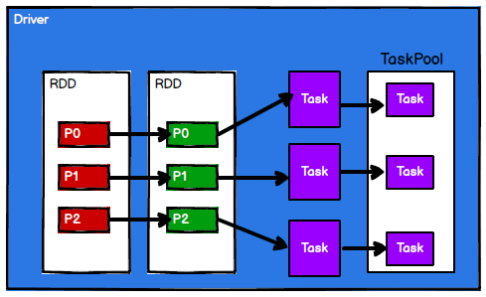
-
調度節點將任務根據計算節點狀態發送到對應的計算節點進行計算
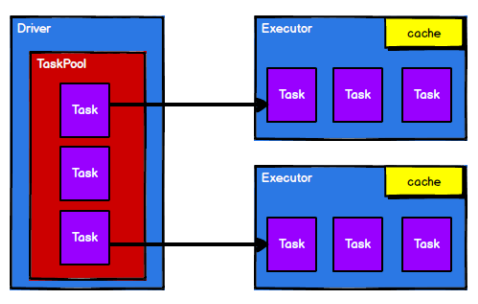




從以上流程可以看出 RDD 在整個流程中主要用於將邏輯進行封裝,並生成 Task 發送給 Executor 節點執行計算
4.1.4 RDD 創建
在 Spark 中創建 RDD 的創建方式可以分為四種
-
從集合(記憶體)中創建 RDD
從集合中創建 RDD,Spark 主要提供了兩個方法:parallelize 和 makeRDD
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") val sparkContext = new SparkContext(sparkConf) val rdd1 = sparkContext.parallelize(List(1,2,3,4)) val rdd2 = sparkContext.makeRDD( List(1,2,3,4)) rdd1.collect().foreach(println) rdd2.collect().foreach(println) sparkContext.stop()從底層程式碼實現來講,makeRDD 方法其實就是 parallelize 方法
def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { parallelize(seq, numSlices) } // makeRDD方法可以傳遞第二個參數,這個參數表示分區的數量 // 第二個參數可以不傳遞的,那麼makeRDD方法會使用默認值 : defaultParallelism(默認並行度) // scheduler.conf.getInt("spark.default.parallelism", totalCores) // spark在默認情況下,從配置對象中獲取配置參數:spark.default.parallelism // 如果獲取不到,那麼使用totalCores屬性,這個屬性取值為當前運行環境的最大可用核數 // val rdd = sc.makeRDD(List(1,2,3,4),2) -
從外部存儲(文件)創建 RDD
由外部存儲系統的數據集創建 RDD 包括:本地的文件系統,所有 Hadoop 支援的數據集, 比如 HDFS、HBase 等
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") val sparkContext = new SparkContext(sparkConf) val fileRDD: RDD[String] = sparkContext.textFile("input") fileRDD.collect().foreach(println) sparkContext.stop() -
從其他 RDD 創建
主要是通過一個 RDD 運算完後,再產生新的 RDD
-
直接創建 RDD(new)
使用 new 的方式直接構造 RDD,一般由 Spark 框架自身使用
4.1.5 RDD並行度與分區
默認情況下,Spark 可以將一個作業切分多個任務後,發送給 Executor 節點並行計算,而能夠並行計算的任務數量我們稱之為並行度。這個數量可以在構建 RDD 時指定。記住,這裡的並行執行的任務數量,並不是指的切分任務的數量,不要混淆了
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4), 4)
val fileRDD: RDD[String] = sparkContext.textFile( "input", 2)
fileRDD.collect().foreach(println)
sparkContext.stop()
讀取記憶體數據時,數據可以按照並行度的設定進行數據的分區操作,數據分區規則的 Spark 核心源碼如下
// Sequences need to be sliced at the same set of index positions for operations
// like RDD.zip() to behave as expected
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
讀取文件數據時,數據是按照 Hadoop 文件讀取的規則進行切片分區,而切片規則和數據讀取的規則有些差異,具體 Spark 核心源碼如下
public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException {
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
...
}
protected long computeSplitSize(long goalSize, long minSize,long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
4.2 RDD 轉換運算元
RDD 根據數據處理方式的不同將運算元整體上分為 Value 類型、雙 Value 類型和 Key-Value 類型
| Value | DESC |
|---|---|
| map | 將處理的數據逐條進行映射轉換,這裡的轉換可以是類型的轉換,也可以是值的轉換 |
| mapPartitions | 將待處理的數據以分區為單位發送到計算節點進行處理,這裡的處理是指可以進行任意的處理,哪怕是過濾數據 |
| mapPartitionsWithIndex | 將待處理的數據以分區為單位發送到計算節點進行處理,這裡的處理是指可以進行任意的處 理,哪怕是過濾數據,在處理時同時可以獲取當前分區索引 |
| flatMap | 將處理的數據進行扁平化後再進行映射處理,所以運算元也稱之為扁平映射 |
| glom | 將同一個分區的數據直接轉換為相同類型的記憶體數組進行處理,分區不變 |
| groupBy | 將數據根據指定的規則進行分組, 分區默認不變,但是數據會被打亂重新組合,我們將這樣的操作稱之為 shuffle。極限情況下,數據可能被分在同一個分區中 一個組的數據在一個分區中,但是並不是說一個分區中只有一個組 |
| filter | 將數據根據指定的規則進行篩選過濾,符合規則的數據保留,不符合規則的數據丟棄。 當數據進行篩選過濾後,分區不變,但是分區內的數據可能不均衡,生產環境下,可能會出現數據傾斜。 |
| sample | 根據指定的規則從數據集中抽取數據 |
| distinct | 將數據集中重複的數據去重 |
| coalesce | 根據數據量縮減分區,用於大數據集過濾後,提高小數據集的執行效率。當 spark 程式中,存在過多的小任務的時候,可以通過 coalesce 方法,收縮合併分區,減少分區的個數,減小任務調度成本 |
| repartition | 該操作內部其實執行的是 coalesce 操作,參數 shuffle 的默認值為 true。無論是將分區數多的 RDD 轉換為分區數少的 RDD,還是將分區數少的 RDD 轉換為分區數多的 RDD,repartition 操作都可以完成,因為無論如何都會經 shuffle 過程 |
| sortBy | 該操作用於排序數據。在排序之前,可以將數據通過 f 函數進行處理,之後按照 f 函數處理的結果進行排序,默認為升序排列。排序後新產生的 RDD 的分區數與原 RDD 的分區數一致。中間存在 shuffle 的過程 |
| 雙Value | DESC |
| intersection | 對源 RDD 和參數 RDD 求交集後返回一個新的 RDD |
| union | 對源 RDD 和參數 RDD 求並集後返回一個新的 RDD |
| subtract | 以一個 RDD 元素為主,去除兩個 RDD 中重復元素,將其他元素保留下來 |
| zip | 將兩個 RDD 中的元素,以鍵值對的形式進行合併 |
| Key – Value | DESC |
| partitionBy | 將數據按照指定 Partitioner 重新進行分區。Spark 默認的分區器是 HashPartitioner |
| reduceByKey | 可以將數據按照相同的 Key 對 Value 進行聚合 |
| groupByKey | 將數據源的數據根據 key 對 value 進行分組 |
| aggregateByKey | 將數據根據不同的規則進行分區內計算和分區間計算 |
| foldByKey | 當分區內計算規則和分區間計算規則相同時,aggregateByKey 就可以簡化為 foldByKey |
| combineByKey | 最通用的對 key-value 型 rdd 進行聚集操作的聚集函數(aggregation function),combineByKey()允許用戶返回值的類型與輸入不一致 |
| sortByKey | 在一個(K,V)的 RDD 上調用,K 必須實現 Ordered 介面(特質),返回一個按照 key 進行排序 的 |
| join | 在類型為(K,V)和(K,W)的 RDD 上調用,返回一個相同 key 對應的所有元素連接在一起的 (K,(V,W))的 RDD |
| leftOuterJoin | 類似於 SQL 語句的左外連接 |
| cogroup | (join & group)在類型為(K,V)和(K,W)的 RDD 上調用,返回一個(K,(Iterable,Iterable))類型的 RDD |
4.2.1 value
map
-
函數簽名
def map[U: ClassTag](f: T => U): RDD[U] -
函數說明
將處理的數據逐條進行映射轉換,這裡的轉換可以是類型的轉換,也可以是值的轉換
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD1: RDD[Int] = dataRDD.map( num => { num * 2 } ) val dataRDD2: RDD[String] = dataRDD1.map( num => { "" + num} )
mapPartitions
-
函數簽名
def mapPartitions[U: ClassTag]( f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U] -
函數說明
將待處理的數據以分區為單位發送到計算節點進行處理,這裡的處理是指可以進行任意的處理,哪怕是過濾數據
val dataRDD1: RDD[Int] = dataRDD.mapPartitions( datas => { datas.filter(_==2) } ) // mapPartitions : 可以以分區為單位進行數據轉換操作 // 但是會將整個分區的數據載入到記憶體進行引用 // 如果處理完的數據是不會被釋放掉,存在對象的引用。 // 在記憶體較小,數據量較大的場合下,容易出現記憶體溢出。
map 和 mapPartitions 的區別?
- Map 運算元是分區內一個數據一個數據的執行,類似於串列操作。而 mapPartitions 運算元是以分區為單位進行批處理操作
- Map 運算元主要目的將數據源中的數據進行轉換和改變。但是不會減少或增多數據。
- MapPartitions 運算元需要傳遞一個迭代器,返回一個迭代器,沒有要求的元素的個數保持不變,所以可以增加或減少數據
- Map 運算元因為類似於串列操作,所以性能比較低,而是 mapPartitions 運算元類似於批處理,所以性能較高。但是 mapPartitions 運算元會長時間佔用記憶體,那麼這樣會導致記憶體可能不夠用,出現記憶體溢出的錯誤。所以在記憶體有限的情況下,不推薦使用。
mapPartitionsWithIndex
-
函數簽名
def mapPartitionsWithIndex[U: ClassTag]( f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false): RDD[U] -
函數說明
將待處理的數據以分區為單位發送到計算節點進行處理,這裡的處理是指可以進行任意的處理,哪怕是過濾數據,在處理時同時可以獲取當前分區索引
val dataRDD1 = dataRDD.mapPartitionsWithIndex( (index, datas) => { datas.map(index, _) } )
flatMap
-
函數簽名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] -
函數說明
將處理的數據進行扁平化後再進行映射處理,所以運算元也稱之為扁平映射
val dataRDD = sparkContext.makeRDD(List(List(1,2),List(3,4)),1) val dataRDD1 = dataRDD.flatMap(list => list)
glom
-
函數簽名
def glom(): RDD[Array[T]] -
函數說明
將同一個分區的數據直接轉換為相同類型的記憶體數組進行處理,分區不變
val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1) val dataRDD1:RDD[Array[Int]] = dataRDD.glom()
groupBy
-
函數簽名
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] -
函數說明
將數據根據指定的規則進行分組, 分區默認不變,但是數據會被打亂重新組合,我們將這樣的操作稱之為 shuffle。極限情況下,數據可能被分在同一個分區中
一個組的數據在一個分區中,但是並不是說一個分區中只有一個組
val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1) val dataRDD1 = dataRDD.groupBy(_%2)
filter
-
函數簽名
def filter(f: T => Boolean): RDD[T] -
函數說明
將數據根據指定的規則進行篩選過濾,符合規則的數據保留,不符合規則的數據丟棄。 當數據進行篩選過濾後,分區不變,但是分區內的數據可能不均衡,生產環境下,可能會出現數據傾斜
val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1) val dataRDD1 = dataRDD.filter(_%2 == 0)
sample
-
函數簽名
def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T] -
函數說明
根據指定的規則從數據集中抽取數據
val dataRDD = sparkContext.makeRDD(List( 1,2,3,4 ),1) // 抽取數據不放回(伯努利演算法) // 伯努利演算法:又叫 0、1 分布。例如扔硬幣,要麼正面,要麼反面。 // 具體實現:根據種子和隨機演算法算出一個數和第二個參數設置幾率比較,小於第二個參數要,大於不要 // 第一個參數:抽取的數據是否放回,false:不放回 // 第二個參數:抽取的幾率,範圍在[0,1]之間,0:全不取;1:全取; // 第三個參數:隨機數種子,如果不傳遞第三個參數,那麼使用的是當前系統時間 val dataRDD1 = dataRDD.sample(false, 0.5) // 抽取數據放回(泊松演算法) // 第一個參數:抽取的數據是否放回,true:放回;false:不放回 // 第二個參數:重複數據的幾率,範圍大於等於 0.表示每一個元素被期望抽取到的次數 // 第三個參數:隨機數種子,如果不傳遞第三個參數,那麼使用的是當前系統時間 val dataRDD2 = dataRDD.sample(true, 2)
distinct
-
函數簽名
def distinct()(implicit ord: Ordering[T] = null): RDD[T] def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] -
函數說明
將數據集中重複的數據去重
val dataRDD = sparkContext.makeRDD(List(1,2,3,4,1,2),1) val dataRDD1 = dataRDD.distinct() val dataRDD2 = dataRDD.distinct(2)
coalesce
-
函數簽名
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null) :RDD[T] -
函數說明
根據數據量縮減分區,用於大數據集過濾後,提高小數據集的執行效率
當 spark 程式中,存在過多的小任務的時候,可以通過 coalesce 方法,收縮合併分區,減少分區的個數,減小任務調度成本
val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),6) val dataRDD1 = dataRDD.coalesce(2) // coalesce方法默認情況下不會將分區的數據打亂重新組合 // 這種情況下的縮減分區可能會導致數據不均衡,出現數據傾斜 // 如果想要讓數據均衡,可以進行shuffle處理
repartition
-
函數簽名
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] -
函數說明
該操作內部其實執行的是 coalesce 操作,參數 shuffle 的默認值為 true。無論是將分區數多的 RDD 轉換為分區數少的 RDD,還是將分區數少的 RDD 轉換為分區數多的 RDD,repartition 操作都可以完成,因為無論如何都會經 shuffle 過程
val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),2) val dataRDD1 = dataRDD.repartition(4)
兩者區別
coalesce運算元可以擴大分區的,但是如果不進行shuffle操作,是沒有意義,不起作用。
所以如果想要實現擴大分區的效果,需要使用shuffle操作
spark提供了一個簡化的操作
- 縮減分區:coalesce,如果想要數據均衡,可以採用shuffle
- 擴大分區:repartition, 底層程式碼調用的就是coalesce,而且肯定採用shuffle
sortBy
-
函數簽名
def sortBy[K]( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] -
函數說明
該操作用於排序數據。在排序之前,可以將數據通過 f 函數進行處理,之後按照 f 函數處理的結果進行排序,默認為升序排列。排序後新產生的 RDD 的分區數與原 RDD 的分區數一致。中間存在 shuffle 的過程
val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),2) val dataRDD1 = dataRDD.sortBy(num=>num, false, 4) // sortBy方法可以根據指定的規則對數據源中的數據進行排序,默認為升序,第二個參數可以改變排序的方式 // sortBy默認情況下,不會改變分區。但是中間存在shuffle操作
4.2.2 double value
交集,並集和差集要求兩個數據源數據類型保持一致
intersection
對源 RDD 和參數 RDD 求交集後返回一個新的 RDD
def intersection(other: RDD[T]): RDD[T]
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.intersection(dataRDD2)
union
對源 RDD 和參數 RDD 求並集後返回一個新的 RDD
def subtract(other: RDD[T]): RDD[T]
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.union(dataRDD2)
subtract
以一個 RDD 元素為主,去除兩個 RDD 中重複元素,將其他元素保留下來。求差集
def subtract(other: RDD[T]): RDD[T]
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.subtract(dataRDD2)
zip
將兩個 RDD 中的元素,以鍵值對的形式進行合併。
-
數據類型可以不一致
-
兩個數據源要求分區數量要保持一致
-
兩個數據源要求分區中數據數量保持一致
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.zip(dataRDD2)
4.2.3 key-value
partitionBy
-
函數簽名
def partitionBy(partitioner: Partitioner): RDD[(K, V)] -
函數說明 將數據按照指定 Partitioner 重新進行分區。Spark 默認的分區器是 HashPartitioner
import org.apache.spark.HashPartitioner val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3) // RDD => PairRDDFunctions // 隱式轉換(二次編譯) // 重分區的分區器與當前RDD的分區器一樣,則不會再次分區 val rdd2: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2))
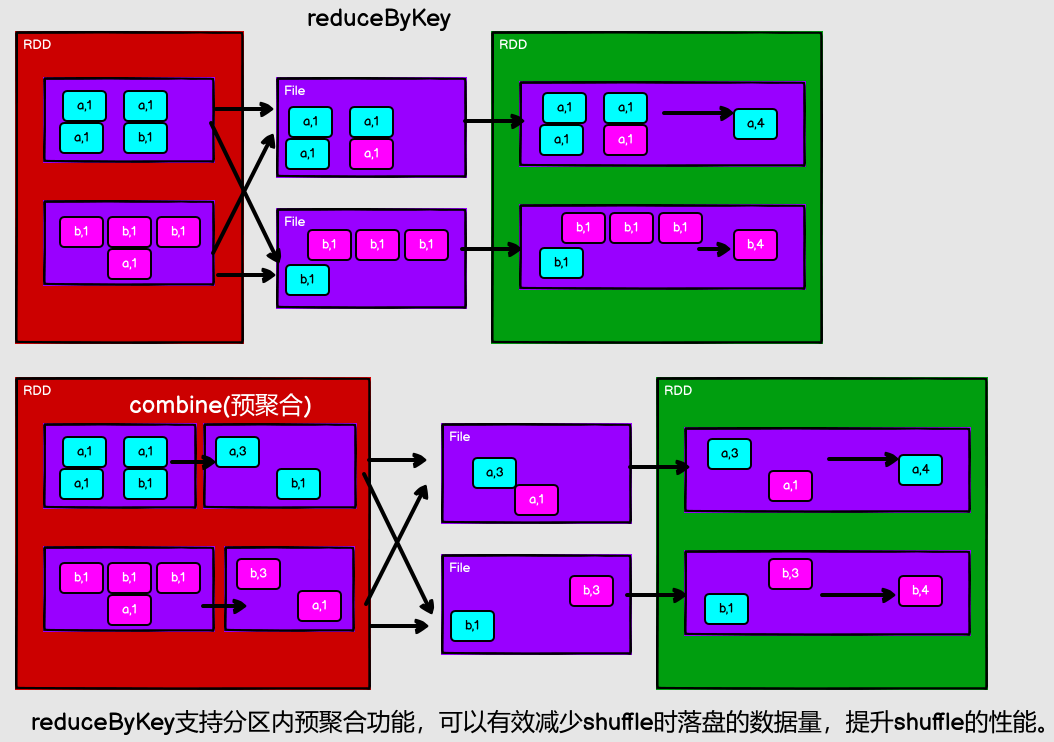
reduceByKey
-
函數簽名
def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] -
函數說明
可以將數據按照相同的 Key 對 Value 進行聚合
// reduceByKey : 相同的key的數據進行value數據的聚合操作 // scala語言中一般的聚合操作都是兩兩聚合,spark基於scala開發的,所以它的聚合也是兩兩聚合 // 【1,2,3】 // 【3,3】 // 【6】 // reduceByKey中如果key的數據只有一個,是不會參與運算的。 val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.reduceByKey(_+_) val dataRDD3 = dataRDD1.reduceByKey(_+_, 2)
groupByKey
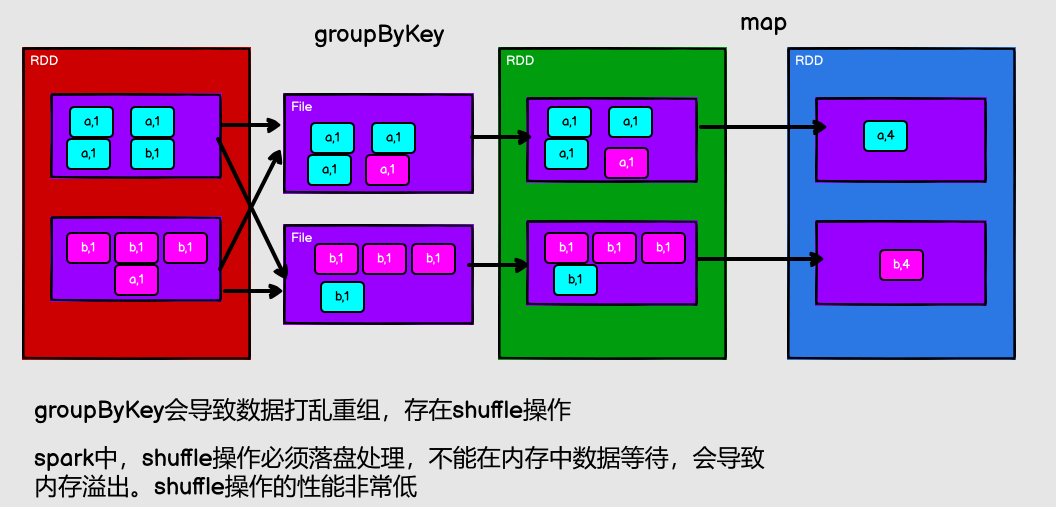
spark中,shuffle操作必須落盤處理,不能在記憶體中數據等待,會導致記憶體溢出
-
函數簽名
def groupByKey(): RDD[(K, Iterable[V])] def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] -
函數說明
將數據源的數據根據 key 對 value 進行分組
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.groupByKey() val dataRDD3 = dataRDD1.groupByKey(2) val dataRDD4 = dataRDD1.groupByKey(new HashPartitioner(2))
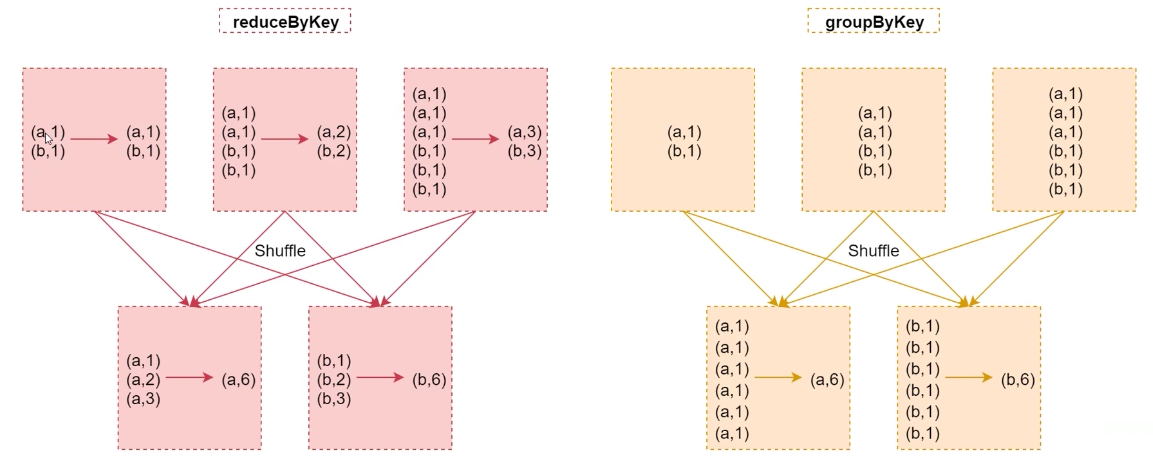
兩者區別
-
從 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前對分區內相同 key 的數據進行預聚合(combine)功能,這樣會減少落盤的數據量,而 groupByKey 只是進行分組,不存在數據量減少的問題,reduceByKey 性能比較高。
-
從功能的角度:reduceByKey 其實包含分組和聚合的功能。GroupByKey 只能分組,不能聚合,所以在分組聚合的場合下,推薦使用 reduceByKey,如果僅僅是分組而不需要聚合。那麼還是只能使用 groupByKey
aggregateByKey
-
函數簽名
def aggregateByKey[U: ClassTag](zeroValue: U) (seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)] -
函數說明
將數據根據不同的規則進行分區內計算和分區間計算
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.aggregateByKey(0)(_+_,_+_) // TODO : 取出每個分區內相同 key 的最大值然後分區間相加 // aggregateByKey 運算元是函數柯里化,存在兩個參數列表 // 1. 第一個參數列表中的參數表示初始值 // 2. 第二個參數列表中含有兩個參數 // 2.1 第一個參數表示分區內的計算規則 // 2.2 第二個參數表示分區間的計算規則
foldByKey
-
函數簽名
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] -
函數說明
當分區內計算規則和分區間計算規則相同時,aggregateByKey 就可以簡化為 foldByKey
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.foldByKey(0)(_+_)
combineByKey
-
函數簽名
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)] -
函數說明
最通用的對 key-value 型 rdd 進行聚集操作的聚集函數(aggregation function)。類似於 aggregate(),combineByKey()允許用戶返回值的類型與輸入不一致
val list: List[(String, Int)] = List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)) val input: RDD[(String, Int)] = sc.makeRDD(list, 2) val combineRdd: RDD[(String, (Int, Int))] = input.combineByKey( (_, 1), (acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), (acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) )
reduceByKey、foldByKey、aggregateByKey、combineByKey 的區別?
-
reduceByKey: 相同 key 的第一個數據不進行任何計算,分區內和分區間計算規則相同
-
FoldByKey: 相同 key 的第一個數據和初始值進行分區內計算,分區內和分區間計算規則相 同
-
AggregateByKey: 相同 key 的第一個數據和初始值進行分區內計算,分區內和分區間計算規則可以不相同
-
CombineByKey: 當計算時,發現數據結構不滿足要求時,可以讓第一個數據轉換結構。分區內和分區間計算規則不相同
// reduceByKey:
combineByKeyWithClassTag[V](
(v: V) => v, // 第一個值不會參與計算
func, // 分區內計算規則
func, // 分區間計算規則
)
// aggregateByKey :
combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v), // 初始值和第一個key的value值進行的分區內數據操作
cleanedSeqOp, // 分區內計算規則
combOp, // 分區間計算規則
)
// foldByKey:
combineByKeyWithClassTag[V](
(v: V) => cleanedFunc(createZero(), v), // 初始值和第一個key的value值進行的分區內數據操作
cleanedFunc, // 分區內計算規則
cleanedFunc, // 分區間計算規則
)
// combineByKey :
combineByKeyWithClassTag(
createCombiner, // 相同key的第一條數據進行的處理函數
mergeValue, // 表示分區內數據的處理函數
mergeCombiners, // 表示分區間數據的處理函數
)
sortByKey
-
函數簽名
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) : RDD[(K, V)] -
函數說明
在一個(K,V)的 RDD 上調用,K 必須實現 Ordered 介面(特質),返回一個按照 key 進行排序的
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(true) val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(false)
join
-
函數簽名
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] -
函數說明
在類型為(K,V)和(K,W)的 RDD 上調用,返回一個相同 key 對應的所有元素連接在一起的 (K,(V,W))的 RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c"))) val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (3, 6))) rdd.join(rdd1).collect().foreach(println)
leftOuterJoin
-
函數簽名
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))] -
函數說明
類似於 SQL 語句的左外連接
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val rdd: RDD[(String, (Int, Option[Int]))] = dataRDD1.leftOuterJoin(dataRDD2)
cogroup
-
函數簽名
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))] -
函數說明
在類型為(K,V)和(K,W)的 RDD 上調用,返回一個(K,(Iterable,Iterable))類型的 RDD
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("a",2),("c",3))) val dataRDD2 = sparkContext.makeRDD(List(("a",1),("c",2),("c",3))) val value: RDD[(String, (Iterable[Int], Iterable[Int]))] = dataRDD1.cogroup(dataRDD2)
4.3 RDD 行動運算元
4.3.1 reduce
-
函數簽名
def reduce(f: (T, T) => T): T -
函數說明
聚集 RDD 中的所有元素,先聚合分區內數據,再聚合分區間數據
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 聚合數據 val reduceResult: Int = rdd.reduce(_+_)
4.3.2 collect
-
函數簽名
def collect(): Array[T] -
函數說明
在驅動程式中,以數組 Array 的形式返回數據集的所有元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 收集數據到 Driver rdd.collect().foreach(println)
4.3.3 count
-
函數簽名
def count(): Long -
函數說明
返回 RDD 中元素的個數
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 返回 RDD 中元素的個數 val countResult: Long = rdd.count()
4.3.4 first
-
函數簽名
def first(): T -
函數說明
返回 RDD 中的第一個元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 返回 RDD 中元素的個數 val firstResult: Int = rdd.first() println(firstResult)
4.3.5 take
-
函數簽名
def take(num: Int): Array[T] -
函數說明
返回一個由 RDD 的前 n 個元素組成的數組
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 返回 RDD 中元素的個數 val takeResult: Array[Int] = rdd.take(2) println(takeResult.mkString(","))
4.3.6 takeOrdered
-
函數簽名
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] -
函數說明
返回該 RDD 排序後的前 n 個元素組成的數組
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4)) // 返回 RDD 中元素的個數 val result: Array[Int] = rdd.takeOrdered(2)
4.3.7 aggregate
-
函數簽名
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U -
函數說明
分區的數據通過初始值和分區內的數據進行聚合,然後再和初始值進行分區間的數據聚合
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8) // 將該 RDD 所有元素相加得到結果 //val result: Int = rdd.aggregate(0)(_ + _, _ + _) val result: Int = rdd.aggregate(10)(_ + _, _ + _)
4.3.8 fold
-
函數簽名
def fold(zeroValue: T)(op: (T, T) => T): T -
函數說明
摺疊操作,aggregate 的簡化版操作
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val foldResult: Int = rdd.fold(0)(_+_)
4.3.9 countByKey
-
函數簽名
def countByKey(): Map[K, Long] -
函數說明
摺疊操作,aggregate 的簡化版操作
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c"))) // 統計每種 key 的個數 val result: collection.Map[Int, Long] = rdd.countByKey()
4.3.10 save 相關運算元
-
函數簽名
def saveAsTextFile(path: String): Unit def saveAsObjectFile(path: String): Unit def saveAsSequenceFile( path: String, codec: Option[Class[_ <: CompressionCodec]] = None): Unit -
函數說明
將數據保存到不同格式的文件中
// 保存成 Text 文件 rdd.saveAsTextFile("output") // 序列化成對象保存到文件 rdd.saveAsObjectFile("output1") // 保存成 Sequencefile 文件 rdd.map((_,1)).saveAsSequenceFile("output2")
4.3.11 foreach
-
函數簽名
def foreach(f: T => Unit): Unit = withScope { val cleanF = sc.clean(f) sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF)) } -
函數說明
分散式遍歷 RDD 中的每一個元素,調用指定函數
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 收集後列印 rdd.map(num=>num).collect().foreach(println) println("****************") // 分散式列印 rdd.foreach(println)
4.4 RDD 序列化
4.4.1 閉包檢查
從計算的角度, 運算元以外的程式碼都是在 Driver 端執行, 運算元裡面的程式碼都是在 Executor 端執行。
那麼在 scala 的函數式編程中,就會導致運算元內經常會用到運算元外的數據,這樣就形成了閉包的效果,如果使用的運算元外的數據無法序列化,就意味著無法傳值給 Executor 端執行,就會發生錯誤,所以需要在執行任務計算前,檢測閉包內的對象是否可以進行序列化,這個操作我們稱之為閉包檢測。
Scala2.12 版本後閉包編譯方式發生了改變
從計算的角度, 運算元以外的程式碼都是在 Driver 端執行, 運算元裡面的程式碼都是在 Executor 端執行
object Spark_RDD_Serial {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive"))
val search = new Search("h")
// 會報錯
//search.getMatch1(rdd).collect().foreach(println)
// 不會報錯
search.getMatch2(rdd).collect().foreach(println)
sc.stop()
}
// 查詢對象
// 類的構造參數其實是類的屬性, 構造參數需要進行閉包檢測,其實就等同於類進行閉包檢測
class Search(query:String){
def isMatch(s: String): Boolean = {
s.contains(this.query)
}
// 函數序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 屬性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
val s = query
rdd.filter(x => x.contains(s))
}
}
}
4.5 RDD 依賴關係
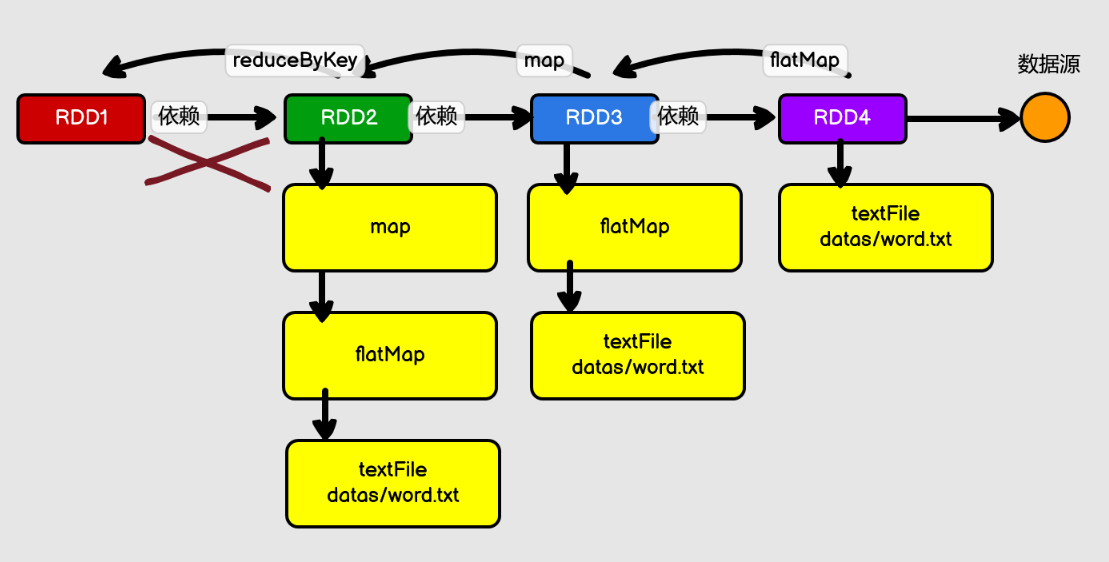
RDD 血緣關係
RDD 只支援粗粒度轉換,即在大量記錄上執行的單個操作。將創建 RDD 的一系列 Lineage (血統)記錄下來,以便恢復丟失的分區。RDD 的 Lineage 會記錄 RDD 的元數據資訊和轉 換行為,當該 RDD 的部分分區數據丟失時,它可以根據這些資訊來重新運算和恢復丟失的 數據分區。
RDD 依賴關係
這裡所謂的依賴關係,其實就是兩個相鄰 RDD 之間的關係
RDD 窄依賴
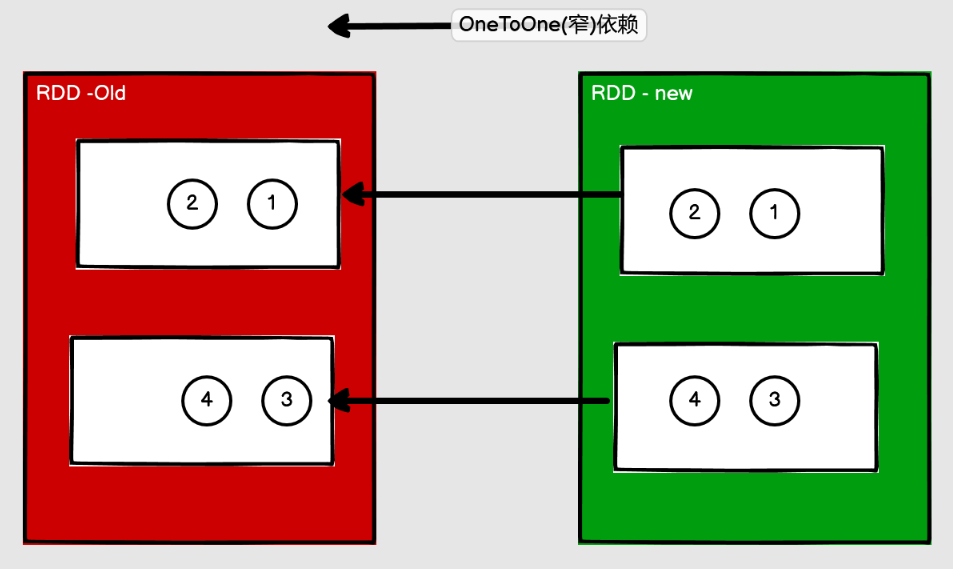
Narrow Dependency
窄依賴表示每一個父(上游)RDD 的 Partition 最多被子(下游)RDD 的一個 Partition 使用
RDD 寬依賴
Shuffle Dependency
寬依賴表示同一個父(上游)RDD 的 Partition 被多個子(下游)RDD 的 Partition 依賴,會引起 Shuffle
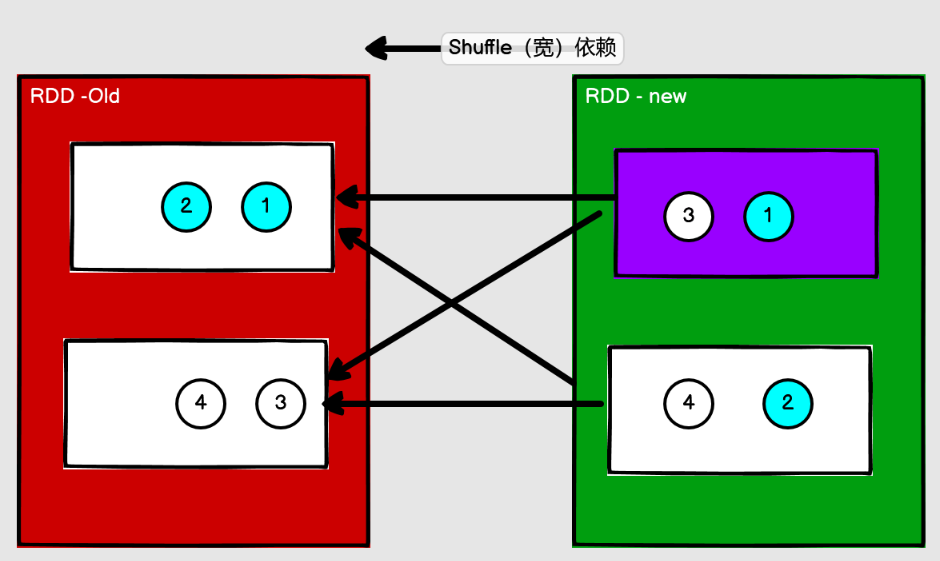
4.5 RDD stage
Spark Job會被劃分為多個Stage,每一個Stage是有一組並行的Task組成的。
劃分依據:是否產生了Shuffle(寬依賴),一個shuffle會產生兩個stage
RDD 階段劃分
DAG(Directed Acyclic Graph)有向無環圖是由點和線組成的拓撲圖形,該圖形具有方向, 不會閉環。例如,DAG 記錄了 RDD 的轉換過程和任務的階段。
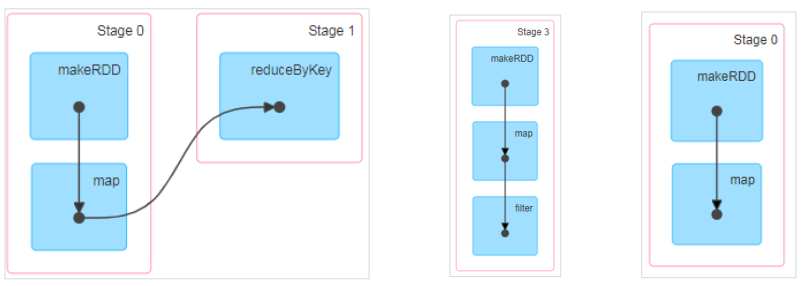
RDD 階段劃分源碼
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage (finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning ("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed (e)
return
}
……
private def createResultStage (
rdd: RDD[_],
func: (TaskContext, Iterator[_] ) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite
): ResultStage = {
val parents = getOrCreateParentStages (rdd, jobId)
val id = nextStageId.getAndIncrement ()
val stage = new ResultStage (id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage (id) = stage
updateJobIdStageIdMaps (jobId, stage)
stage
}
……
private def getOrCreateParentStages (rdd: RDD[_], firstJobId: Int): List[Stage]
= {
getShuffleDependencies (rdd).map {
shuffleDep =>
getOrCreateShuffleMapStage (shuffleDep, firstJobId)
}.toList
}
……
private[scheduler] def getShuffleDependencies ( rdd: RDD[_] ): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push (rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop ()
if (! visited (toVisit) ) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push (dependency.rdd)
}
}
}
parents
}
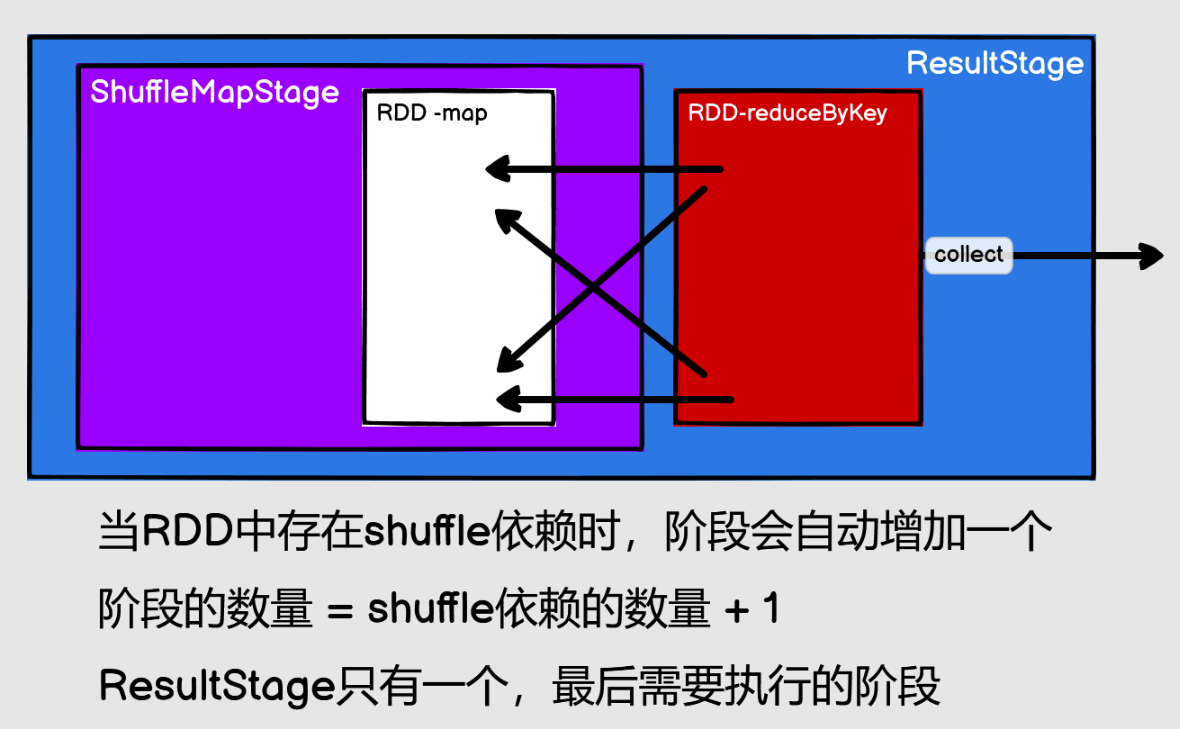
RDD 任務劃分
RDD 任務切分中間分為:Application、Job、Stage 和 Task
- Application:初始化一個 SparkContext 即生成一個 Application
- Job:一個 Action 運算元就會生成一個 Job
- Stage:Stage 等於寬依賴(ShuffleDependency)的個數加 1
- Task:一個 Stage 階段中,最後一個 RDD 的分區個數就是 Task 的個數
注意:Application->Job->Stage->Task 每一層都是 1 對 n 的關係。
RDD 任務劃分源碼
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map {
id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map {
id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
……
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
……
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions)
}
4.6 RDD 持久化
4.6.1 Cache 快取
RDD 通過 Cache 或者 Persist 方法將前面的計算結果快取,默認情況下會把數據以快取在 JVM 的堆記憶體中。但是並不是這兩個方法被調用時立即快取,而是觸發後面的 action 運算元時,該 RDD 將會被快取在計算節點的記憶體中,並供後面重用。
// cache 操作會增加血緣關係,不改變原有的血緣關係
println(wordToOneRdd.toDebugString)
// 數據快取。
wordToOneRdd.cache()
// 可以更改存儲級別
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
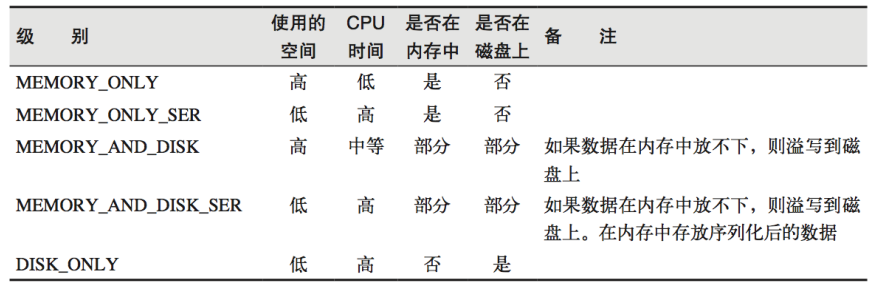
存儲級別
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
快取有可能丟失,或者存儲於記憶體的數據由於記憶體不足而被刪除,RDD 的快取容錯機制保證了即使快取丟失也能保證計算的正確執行。通過基於 RDD 的一系列轉換,丟失的數據會被重算,由於 RDD 的各個 Partition 是相對獨立的,因此只需要計算丟失的部分即可,並不需要重算全部 Partition。
Spark 會自動對一些 Shuffle 操作的中間數據做持久化操作(比如:reduceByKey)。這樣做的目的是為了當一個節點 Shuffle 失敗了避免重新計算整個輸入。但是,在實際使用的時候,如果想重用數據,仍然建議調用 persist 或 cache。
4.6.2 checkPoint 檢查點
所謂的檢查點其實就是通過將 RDD 中間結果寫入磁碟
由於血緣依賴過長會造成容錯成本過高,這樣就不如在中間階段做檢查點容錯,如果檢查點之後有節點出現問題,可以從檢查點開始重做血緣,減少了開銷。
對 RDD 進行 checkpoint 操作並不會馬上被執行,必須執行 Action 操作才能觸發。
// 設置檢查點路徑
sc.setCheckpointDir("./checkpoint1")
// 創建一個 RDD,讀取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input/1.txt")
// 業務邏輯
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
// 增加快取,避免再重新跑一個 job 做 checkpoint
wordToOneRdd.cache()
// 數據檢查點:針對 wordToOneRdd 做檢查點計算
wordToOneRdd.checkpoint()
// 觸發執行邏輯
wordToOneRdd.collect().foreach(println)
快取和檢查點區別
- Cache 快取只是將數據保存起來,不切斷血緣依賴。Checkpoint 檢查點切斷血緣依賴。
- Cache 快取的數據通常存儲在磁碟、記憶體等地方,可靠性低。Checkpoint 的數據通常存儲在 HDFS 等容錯、高可用的文件系統,可靠性高。
- 建議對 checkpoint()的 RDD 使用 Cache 快取,這樣 checkpoint 的 job 只需從 Cache 快取中讀取數據即可,否則需要再從頭計算一次 RDD
4.7 RDD 分區器
Spark 目前支援 Hash 分區和 Range 分區,和用戶自定義分區。Hash 分區為當前的默認分區。分區器直接決定了 RDD 中分區的個數、RDD 中每條數據經過 Shuffle 後進入哪個分區,進而決定了 Reduce 的個數。
- 只有 Key-Value 類型的 RDD 才有分區器,非 Key-Value 類型的 RDD 分區的值是 None
- 每個 RDD 的分區 ID 範圍:0 ~ (numPartitions – 1),決定這個值是屬於那個分區的
Hash 分區:對於給定的 key,計算其 hashCode,併除以分區個數取余
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
Range 分區:將一定範圍內的數據映射到一個分區中,盡量保證每個分區數據均勻,而且分區間有序
class RangePartitioner[K : Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner {
// We allow partitions = 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.")
private var ordering = implicitly[Ordering[K]]
// An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
...
}
def numPartitions: Int = rangeBounds.length + 1
private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K]
def getPartition (key: Any): Int = {
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <= 128) {
// If we have less than 128 partitions naive search
while (partition < rangeBounds.length && ordering.gt (k, rangeBounds (partition) ) ) {
partition += 1
}
} else {
// Determine which binary search method to use only once.
partition = binarySearch (rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition < 0) {
partition = - partition - 1
}
if (partition > rangeBounds.length) {
partition = rangeBounds.length
}
}
if (ascending) {
partition
} else {
rangeBounds.length - partition
}
}
override def equals (other: Any): Boolean = other match {
...
}
override def hashCode (): Int = {
...
}
@throws(classOf[IOException])
private def writeObject (out: ObjectOutputStream): Unit =
Utils.tryOrIOException {
...
}
@throws(classOf[IOException])
private def readObject (in: ObjectInputStream): Unit = Utils.tryOrIOException {
...
}
}
4.8 RDD 文件讀取與保存
Spark 的數據讀取及數據保存可以從兩個維度來作區分:文件格式以及文件系統。
文件格式分為:text 文件、csv 文件、sequence 文件以及 Object 文件
文件系統分為:本地文件系統、HDFS、HBASE 以及資料庫
text 文件
// 讀取輸入文件
val inputRDD: RDD[String] = sc.textFile("input/1.txt")
// 保存數據
inputRDD.saveAsTextFile("output")
sequence 文件
SequenceFile 文件是 Hadoop 用來存儲二進位形式的 key-value 對而設計的一種平面文件(Flat File)。在 SparkContext 中,可以調用 sequenceFile[keyClass, valueClass](path)
// 保存數據為 SequenceFile
dataRDD.saveAsSequenceFile("output")
// 讀取 SequenceFile 文件
sc.sequenceFile[Int,Int]("output").collect().foreach(println)
object 對象文件
對象文件是將對象序列化後保存的文件,採用 Java 的序列化機制。可以通過 objectFile[T: ClassTag](path)函數接收一個路徑,讀取對象文件,返回對應的 RDD,也可以通過調用 saveAsObjectFile()實現對對象文件的輸出。因為是序列化所以要指定類型
// 保存數據
dataRDD.saveAsObjectFile("output")
// 讀取數據
sc.objectFile[Int]("output").collect().foreach(println)
4.9 累加器
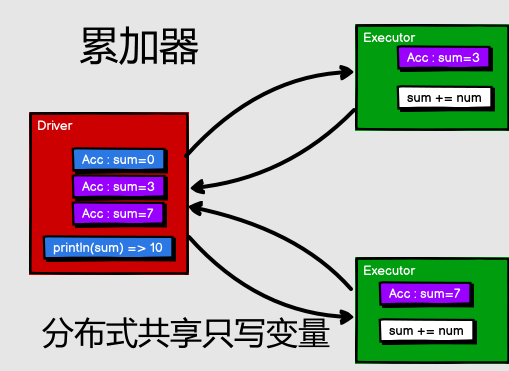
累加器用來把 Executor 端變數資訊聚合到 Driver 端。在 Driver 程式中定義的變數,在 Executor 端的每個 Task 都會得到這個變數的一份新的副本,每個 task 更新這些副本的值後, 傳回 Driver 端進行 merge
4.9.1 系統累加器
val rdd = sc.makeRDD(List(1,2,3,4,5))
// 聲明累加器
var sum = sc.longAccumulator("sum");
rdd.foreach(
num => {
// 使用累加器
sum.add(num)
}
)
// 獲取累加器的值
println("sum = " + sum.value)
4.9.2 自定義累加器
// 自定義累加器
// 1. 繼承 AccumulatorV2,並設定泛型
// 2. 重寫累加器的抽象方法
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]]{
var map : mutable.Map[String, Long] = mutable.Map()
// 累加器是否為初始狀態
override def isZero: Boolean = {
map.isEmpty
}
// 複製累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new WordCountAccumulator
}
// 重置累加器
override def reset(): Unit = {
map.clear()
}
// 向累加器中增加數據 (In)
override def add(word: String): Unit = {
// 查詢 map 中是否存在相同的單詞
// 如果有相同的單詞,那麼單詞的數量加 1
// 如果沒有相同的單詞,那麼在 map 中增加這個單詞
map(word) = map.getOrElse(word, 0L) + 1L
}
// 合併累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]):
Unit = {
val map1 = map
val map2 = other.value
// 兩個 Map 的合併
map = map1.foldLeft(map2)(
( innerMap, kv ) => {
innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2
innerMap
}
)
}
// 返回累加器的結果 (Out)
override def value: mutable.Map[String, Long] = map
}
4.10 廣播變數
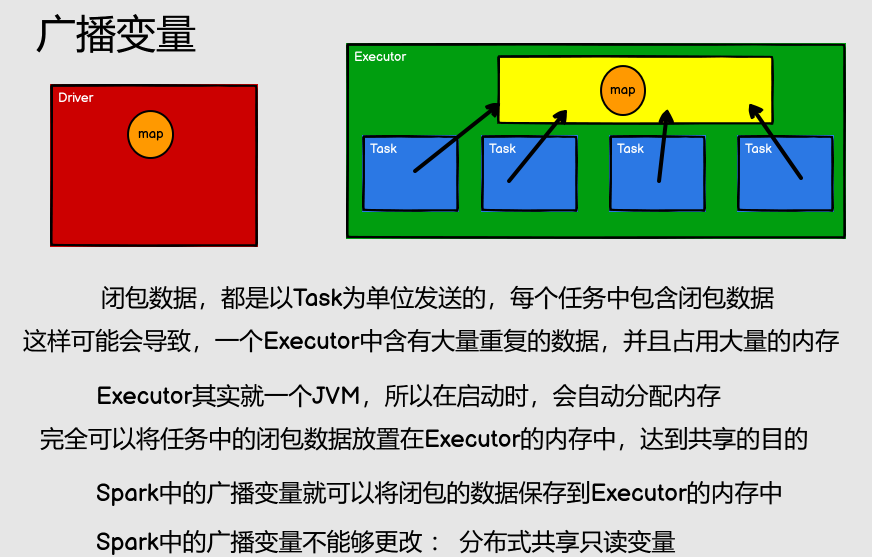
廣播變數用來高效分發較大的對象。向所有工作節點發送一個較大的只讀值,以供一個或多個 Spark 操作使用。比如,如果你的應用需要向所有節點發送一個較大的只讀查詢表, 廣播變數用起來都很順手。在多個並行操作中使用同一個變數,但是 Spark 會為每個任務分別發送
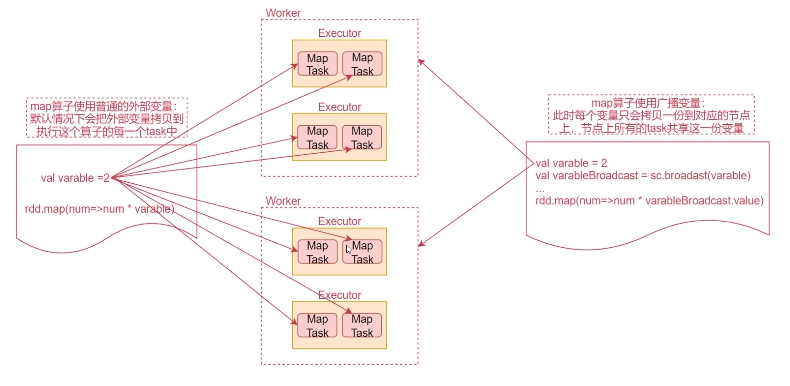
val rdd1 = sc.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4)
val list = List( ("a",4), ("b", 5), ("c", 6), ("d", 7) )
// 聲明廣播變數
val broadcast: Broadcast[List[(String, Int)]] = sc.broadcast(list)
val resultRDD: RDD[(String, (Int, Int))] = rdd1.map {
case (key, num) => {
var num2 = 0
// 使用廣播變數
for ((k, v) <- broadcast.value) {
if (k == key) {
num2 = v
}
}
(key, (num, num2))
}
}
5. 進階
5.1 SortByKey原理

有一台伺服器:32G記憶體,如何在記憶體中對1T數據排序
- 先抽樣,看分布,然後分塊(至少32塊),對每個塊進行排序,最後合併
5.2 shuffle
在Spark中,什麼情況下,會產生shuffle?
- reduceByKey,groupByKey,sortByKey,countByKey,join等等
Spark shuffle一共經歷了這幾個過程:
- 未優化的 Hash Based Shuffle
- 優化後的 Hash Based Shuffle
- Sort-Based Shuffle
5.2.1 ShuffleMapStage 與 ResultStage
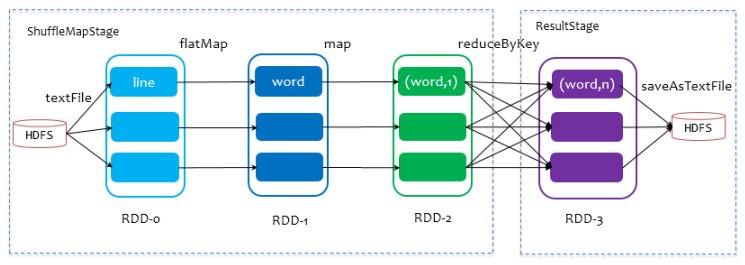
在劃分 stage 時,最後一個 stage 稱為 finalStage,它本質上是一個 ResultStage 對象,前面的所有 stage 被稱為 ShuffleMapStage。
ShuffleMapStage
- 的結束伴隨著 shuffle 文件的寫磁碟。
ResultStage
- 基本上對應程式碼中的 action 運算元,即將一個函數應用在 RDD 的各個 partition 的數據集上,意味著一個 job 的運行結束。
5.2.2 HashShuffle 解析
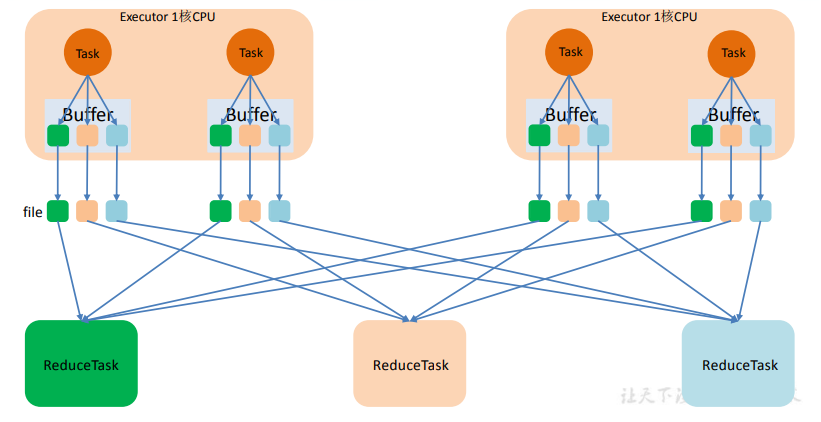
1. 未優化的 HashShuffle
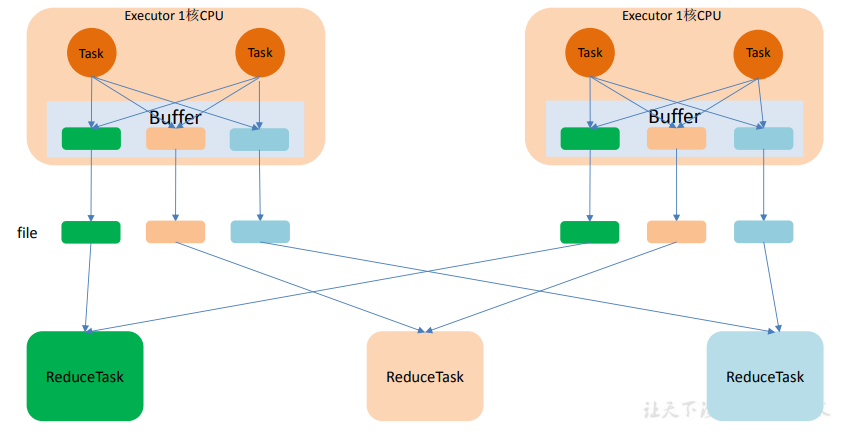
如下圖中有 3 個 Reducer,從 Task 開始那邊各自把自己進行 Hash 計算(分區器: hash/numreduce 取模),分類出 3 個不同的類別,每個 Task 都分成 3 種類別的數據,想把不同的數據匯聚然後計算出最終的結果,所以 Reducer 會在每個 Task 中把屬於自己類別的數 據收集過來,匯聚成一個同類別的大集合,每 1 個 Task 輸出 3 份本地文件,這裡有 4 個 Mapper Tasks,所以總共輸出了 4 個 Tasks x 3 個分類文件 = 12 個本地小文件。
2. 優化後的 HashShuffle
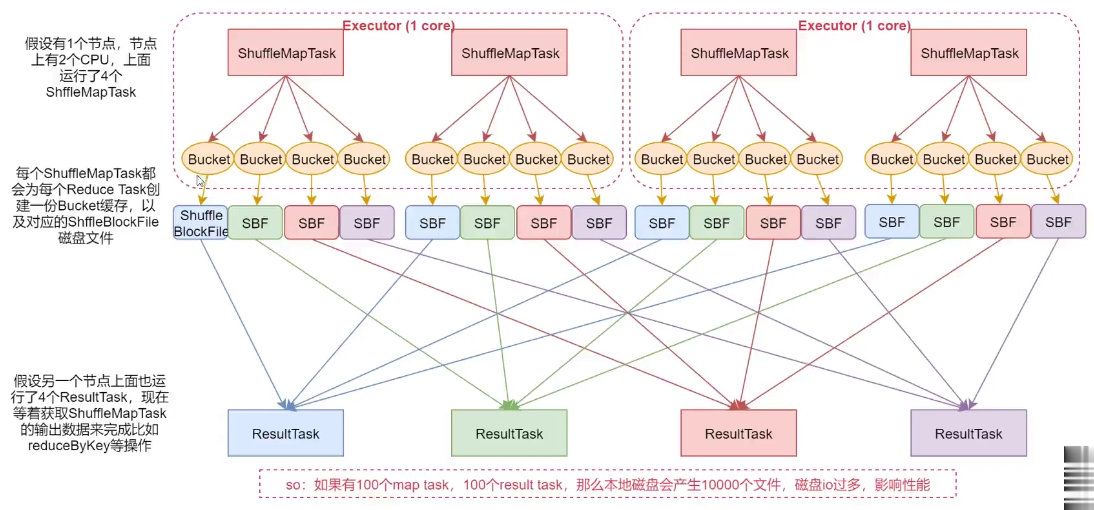
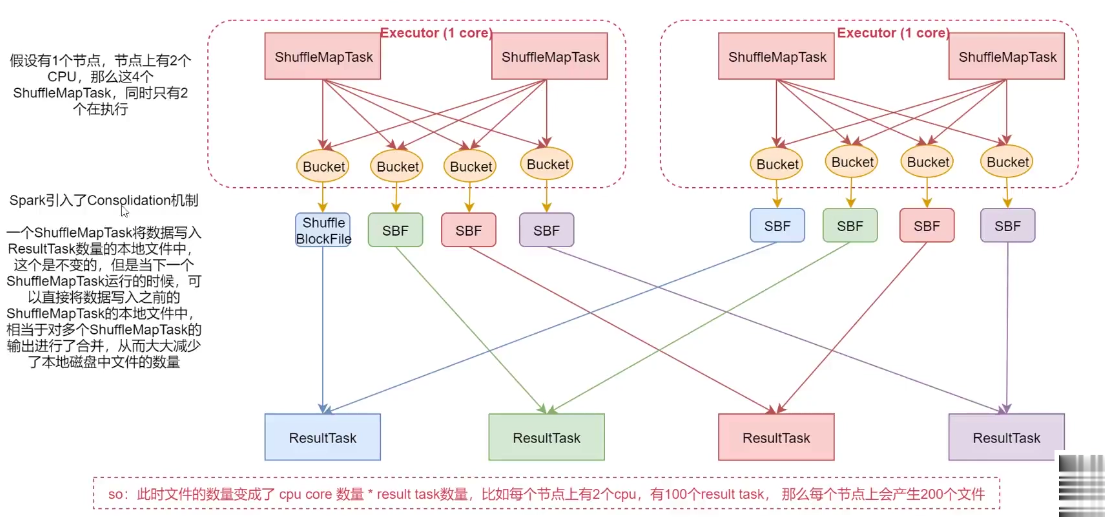
優化的 HashShuffle 過程就是啟用合併機制,合併機制就是復用 buffer,開啟合併機制 的配置是 spark.shuffle.consolidateFiles。該參數默認值為 false,將其設置為 true 即可開啟優化機制。通常來說,如果我們使用 HashShuffleManager,那麼都建議開啟這個選項。
這裡還是有 4 個 Tasks,數據類別還是分成 3 種類型,因為 Hash 演算法會根據你的 Key 進行分類,在同一個進程中,無論是有多少過 Task,都會把同樣的 Key 放在同一個 Buffer 里,然後把 Buffer 中的數據寫入以 Core 數量為單位的本地文件中,(一個 Core 只有一種類 型的 Key 的數據),每 1 個 Task 所在的進程中,分別寫入共同進程中的 3 份本地文件,這裡 有 4 個 Mapper Tasks,所以總共輸出是 2 個 Cores x 3 個分類文件 = 6 個本地小文件。
5.2.3 SortShuffle 解析
1. 普通 SortShuffle
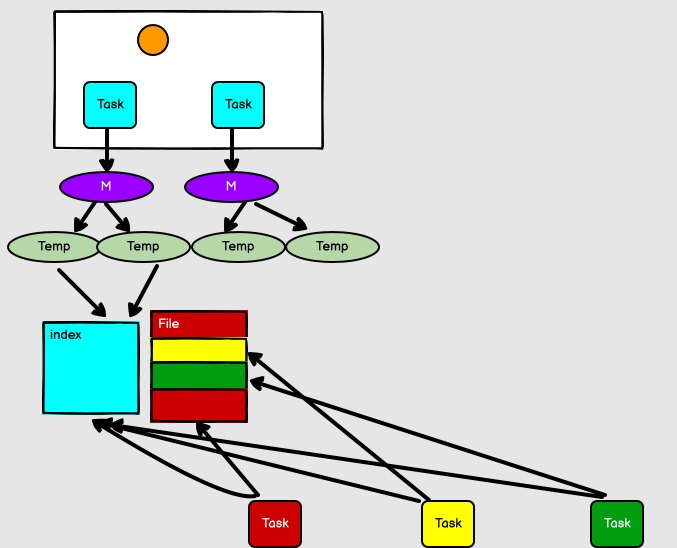
在該模式下,數據會先寫入一個數據結構,reduceByKey 寫入 Map,一邊通過 Map 局部聚合,一邊寫入記憶體。Join 運算元寫入 ArrayList 直接寫入記憶體中。然後需要判斷是否達到閾值,如果達到就會將記憶體數據結構的數據寫入到磁碟,清空記憶體數據結構。
在溢寫磁碟前,先根據 key 進行排序,排序過後的數據,會分批寫入到磁碟文件中。默認批次為 10000 條,數據會以每批一萬條寫入到磁碟文件。寫入磁碟文件通過緩衝區溢寫的方式,每次溢寫都會產生一個磁碟文件,也就是說一個 Task 過程會產生多個臨時文件。
最後在每個 Task 中,將所有的臨時文件合併,這就是 merge 過程,此過程將所有臨時文件讀取出來,一次寫入到最終文件。意味著一個 Task 的所有數據都在這一個文件中。同時單獨寫一份索引文件,標識下游各個Task的數據在文件中的索引,start offset和end offset。
2. bypass SortShuffle
bypass 運行機制的觸發條件如下:
- shuffle reduce task 數量小於等於 spark.shuffle.sort.bypassMergeThreshold 參數的值,默認為 200
- 不是聚合類的 shuffle 運算元(比如 reduceByKey)
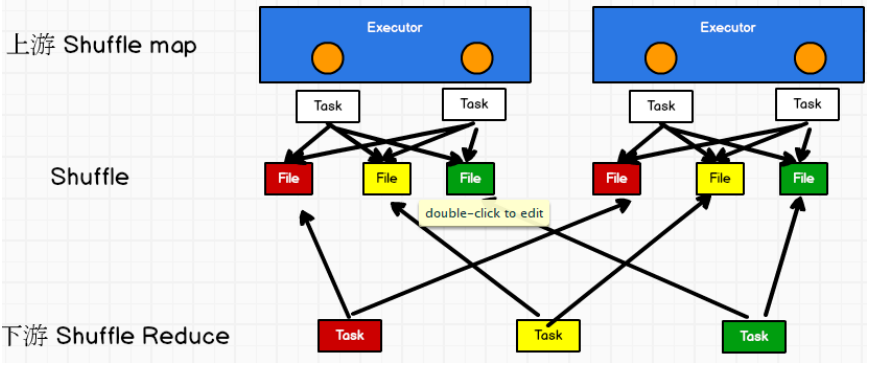
此時 task 會為每個 reduce 端的 task 都創建一個臨時磁碟文件,並將數據按 key 進行 hash 然後根據 key 的 hash 值,將 key 寫入對應的磁碟文件之中。當然,寫入磁碟文件時也是先寫入記憶體緩衝,緩衝寫滿之後再溢寫到磁碟文件的。最後,同樣會將所有臨時磁碟文件都合併成一個磁碟文件,並創建一個單獨的索引文件。
該過程的磁碟寫機制其實跟未經優化的 HashShuffleManager 是一模一樣的,因為都要創建數量驚人的磁碟文件,只是在最後會做一個磁碟文件的合併而已。因此少量的最終磁碟文件,也讓該機制相對未經優化的 HashShuffleManager 來說,shuffle read 的性能會更好。
而該機制與普通 SortShuffleManager 運行機制的不同在於:不會進行排序。也就是說, 啟用該機制的最大好處在於,shuffle write 過程中,不需要進行數據的排序操作,也就節省掉了這部分的性能開銷。
6. 性能優化
6.1 高性能序列化庫
- Spark傾向於序列化的便捷性,默認使用了Java序列化機制
- Java序列化機制的性能並不高,序列化的速度相對較慢,而且序列化以後的數據,相對來說比較大,比較佔用記憶體空間
- Spark提供了兩種序列化機制:Java序列化和Kryo序列化
Kryo序列化
- Kryo序列化比Java序列化更快,而且序列化後的數據更小,通常小十倍
- 如果要使用Kryo序列化機制,首先要用SparkConf和Spark序列化器設置為KryoSerializer
- 使用Kryo時,針對需要序列化的類,需要預先進行註冊,這樣才能獲得最佳性能,如果不註冊,Kryo必須時刻保存類型的全類名,反而佔用不少記憶體
- Spark默認對Scala中常用的類型自動在Kryo進行了註冊
- 如果在運算元中,使用了外部的自定義類型的對象,那麼還是需要對其進行註冊
- 格式:
conf.registerKryoClasses(...)
- 格式:
- 注意:如果要序列化的自定義的類型,欄位特別多,此時就需要對Kryo本身進行優化,因為Kryo內部的換存儲可能不夠存放那麼大的class對象
- 需要調用SparkConf.set()方法,設置spark.kryoserializer.buffer.mb參數的值,將其調大,默認值為2,單位是MB
6.2 持久化&checkpoint
- 針對程式中多次被transformation或者action操作的RDD進行持久化操作,避免對一個RDD反覆進行計算,再進一步優化,使用序列化Kryo的持久化級別
- 為了保證RDD持久化數據在可能丟失的情況下還能實現高可靠,則需要對RDD執行CheckPoint操作
6.3 JVM垃圾回收調優
默認情況下,Spark使用每個Executor 60%的記憶體空間來快取RDD,那麼只有40%的記憶體空間來存放運算元執行期間創建的對象
- 如果垃圾回收頻繁發生,就需要對這個比例進行調優,通過參數spark.storage.memoryFraction來修改比例
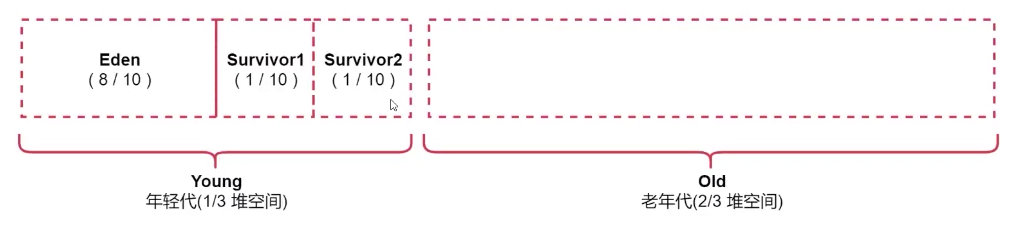
統一記憶體管理
統一記憶體管理機制,與靜態記憶體管理的區別在於存儲記憶體和執行記憶體共享同一塊空間,可以動態佔用對方的空閑區域,統一記憶體管理的堆內記憶體結構如圖所示:
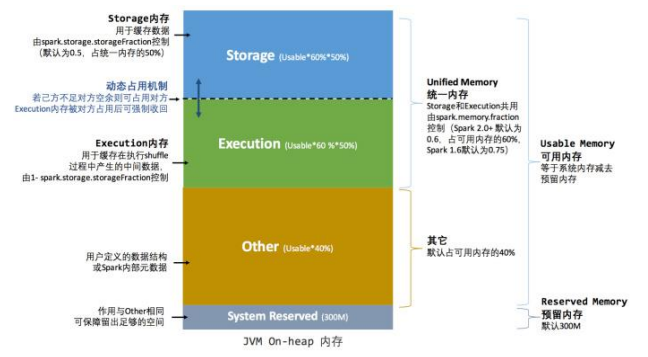
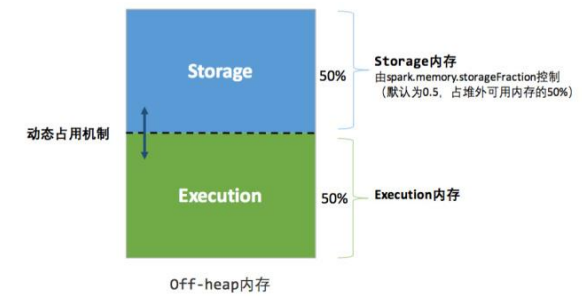
其中最重要的優化在於動態佔用機制,其規則如下:
- 設定基本的存儲記憶體和執行記憶體區域(spark.storage.storageFraction 參數),該設定確定了雙方各自擁有的空間的範圍
- 雙方的空間都不足時,則存儲到硬碟;若己方空間不足而對方空餘時,可借用對方的空間;(存儲空間不足是指不足以放下一個完整的 Block)
- 執行記憶體的空間被對方佔用後,可讓對方將佔用的部分轉存到硬碟,然後」歸還」借用的空間
- 存儲記憶體的空間被對方佔用後,無法讓對方」歸還」,因為需要考慮 Shuffle 過程中的很多因素,實現起來較為複雜。
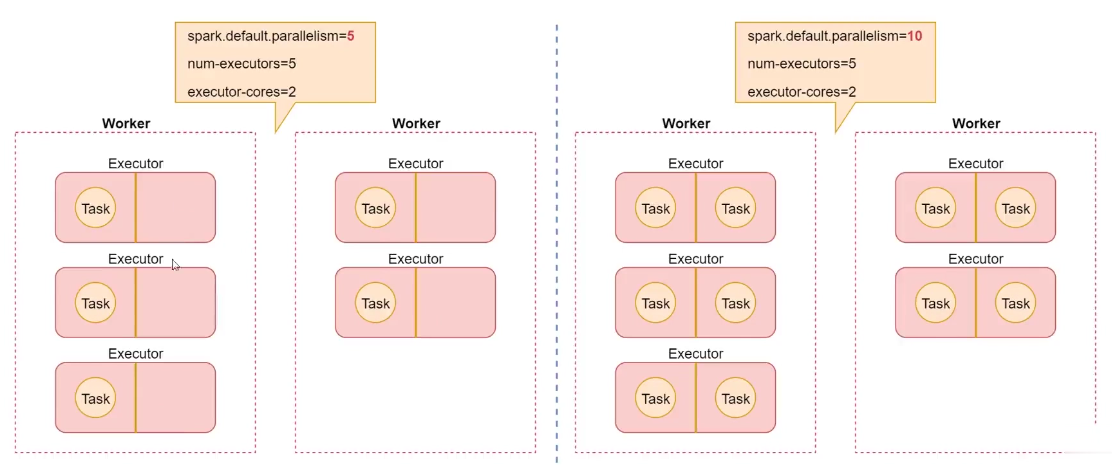
6.4 提高並行度
-
要盡量設置合理的並行度,來充分地利用集群的資源,才能充分提高Spark程式的性能
-
可以手動使用textFile()、parallelize()等方法的第二個參數來設置並行度,也可以使用spark.default.parallelism參數,來設置統一的並行度,Spark官方推薦,給集群的每個cpu core設置2-3個task
6.5 數據本地化
| 數據本地化級別 | 解釋 |
|---|---|
| PROCESS_LOCAL | 數據和計算它的程式碼在同一個JVM進程中 |
| NODE_LOCAL | 數據和計算它的程式碼在一個節點上,但是不在一個JVM進程中 |
| NO_PREF | 數據從哪裡過來,性能都是一樣的 |
| RACK_LOCAL | 數據和計算它的程式碼在一個機架上 |
| ANY | 數據可能在任意地方,比如其他網路環境內,或者其它機架上 |
- Spark傾向於使用最好的本地化級別調度task,但不現實
- Spark默認會等待指定時間,期望task要處理的數據所在的節點上的Executor空閑出一個cpu,從而將task分配過去,只要超過了時間,那麼spark就會將task分配到其他任意一個空閑的Executor上
- 可以設置spark.locality系列參數,來調節spark等待task可以進行數據本地化的時間
- spark.locality.wait.process
- spark.locality.wait.node
- spark.locality.wait.rack
6.6 運算元優化
6.6.1 map vs mapPartitions
-
map: 一次處理一條數據
- 因為可以GC回收處理過的數據,所以一般不會導致OOM異常
-
mapPartitions: 一次處理一個分區的數據
- 如果元素過多,可能會導致OOM異常
- 性能更高
建議針對初始化鏈接之類的操作,使用mapPartitions,放在mapPartitions內部
例如:創建資料庫鏈接,使用mapPartitions可以減少鏈接創建的次數,提高性能
注意:創建資料庫鏈接的程式碼建議放在次數,不要放在Driver端或者it.foreach內部
資料庫鏈接放在Driver端會導致鏈接無法序列化,無法傳遞到對應的task中執行,所以運算元在執行的時候會報錯
資料庫鏈接放在it.foreach()內部還是會創建多個鏈接,和使用map運算元的效果是一樣的
6.6.2 foreach vs foreachPartition
- foreach:一次處理一條數據
- foreachPartition:一次處理一個分區的數據
6.6.3 repartition
- 對RDD進行重分區
- 可以調整RDD的並行度
- 可以解決RDD中數據傾斜的問題
6.6.4 reduceByKey vs groupByKey
reduceByKey會先進行預聚合,會減少數據量,性能更高