大數據在車聯網行業的實踐與應用
- 2022 年 5 月 3 日
- 筆記
- DataFunTalk, 人工智慧, 大數據, 演算法

導讀:聯友科技是一家旨在提供在汽車行業全價值鏈解決方案的科技公司。公司以數字化、智慧零部件以及智慧網聯為三大核心業務領域,涵蓋研發/製造/營銷等領域的資訊化產品、系統運行維護服務、雲服務、大數據分析服務、智慧網聯及數字化運營服務、車載智慧部件及汽車設計等業務。本次分享會圍繞以下四點展開:
- 車聯網平台
- 數據存儲
- 數據接入
- 數據應用
—
01 車聯網平台
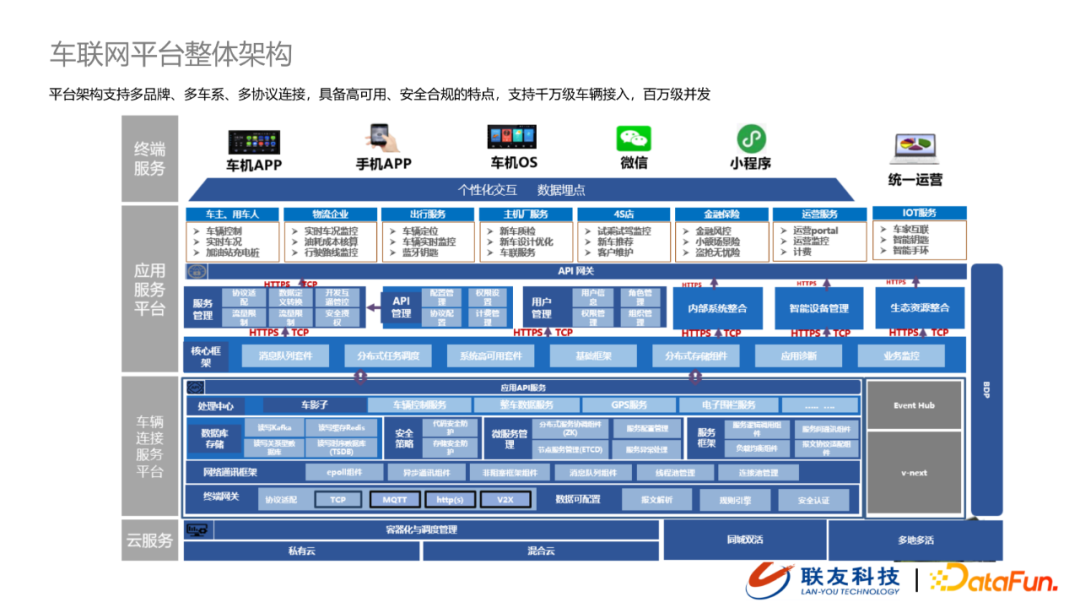
聯友科技車聯網整體架構由下往上分為四層,分別是雲服務、車輛連接服務平台、應用服務平台以及終端服務。目前平台架構支援多品牌、多車系、多協議鏈接,具備高可用、安全合規,支援千萬級車輛接入以及百萬級並發。
- 雲服務:支援私有雲、混合雲部署,支援同城雙活和異地多活
- 車輛連接管理服務平台:負責車輛連接,包括終端網關(接入協議、數據源可配置)、網路通訊框架、數據存儲以及處理中心
- 應用平台:提供統一的能力開放,包括核心框架能力、服務管理、API管理、用戶管理等,在對外能力上包括內部系統能力整合、提供與車輛相關數據服務與業務服務
- 終端服務:提供個性化的服務以及數據埋點,支援到多終端、多協議應用設備的接入
在後續的部分我們主要針對車聯網數據流在車聯網平台架構中的實現展開介紹,承載這部分能力的模組叫做 BDP。
1. 車聯網平台整體架構
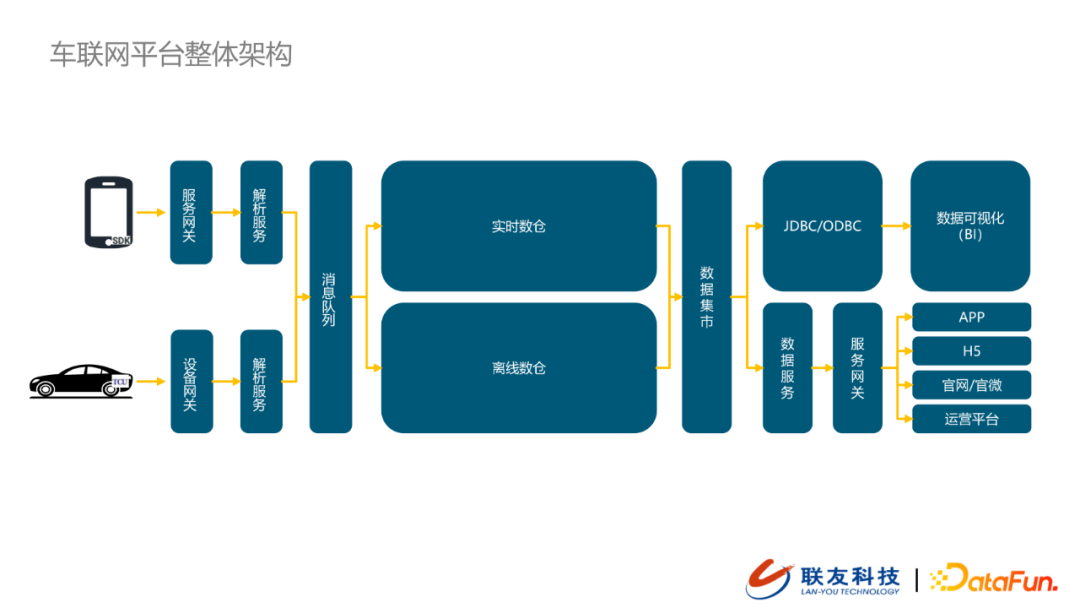
架構由左往右在大概可以分為三個階段:數據接入、數據存儲、數據開放。
由車機和智慧設備採集到數據會經過數據接入模組歸集到數據消息隊列,並最終落入到數據存儲層(實時數倉+離線數倉)。數據在數倉中經過清洗之後,會形成規範化的主題數據,這類數據我們會統一放到數據集市層。為了滿足到下游的數據獲取和傳統的數據可視化的需求,我們提供了統一開放的數據消費方式(JDBC/ODBC),支援下游BI需求。同時,對於數據集市中的數據,我們提供數據服務將數據按照數據主題封裝,並通過服務網關向外提供數據查詢的能力,為APP、H5、官網/官微、運營平台等提供規範的數據。
—
02 數據接入
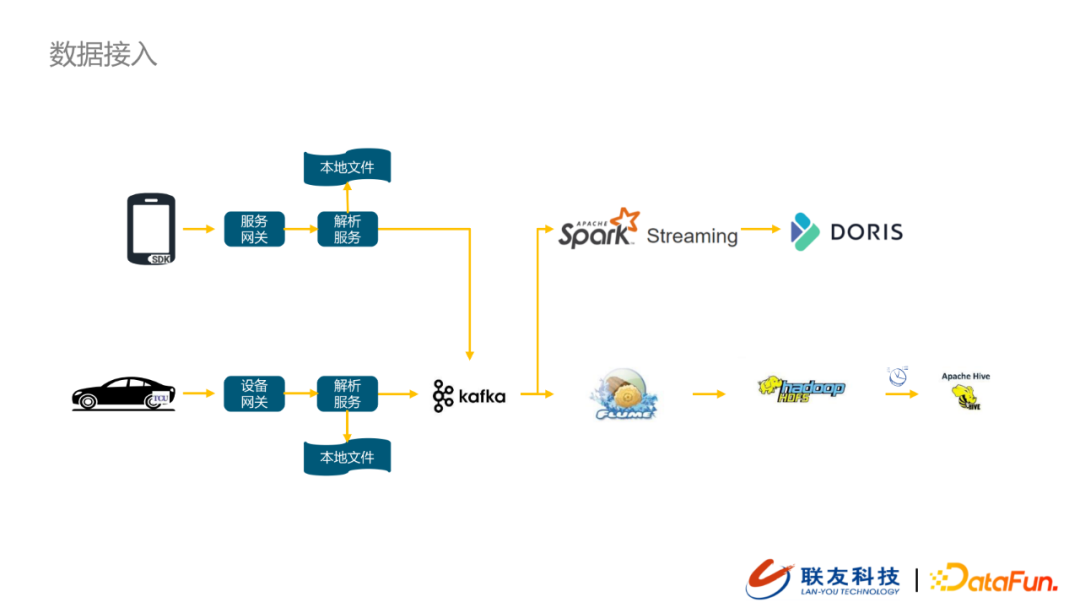
- 數據源
-
車輛終端:通過TCU上報數據到設備網關,原始上報的數據經過數據解析服務完成數據的解碼,然後將語義化的消息推送到數據接入層的消息隊列中。
-
設備終端:通過數據採集SDK將智慧終端產生的數據上報到服務網關,同樣在數據解析服務模組完成數據解析,並注入到數據接入層的消息隊列中。
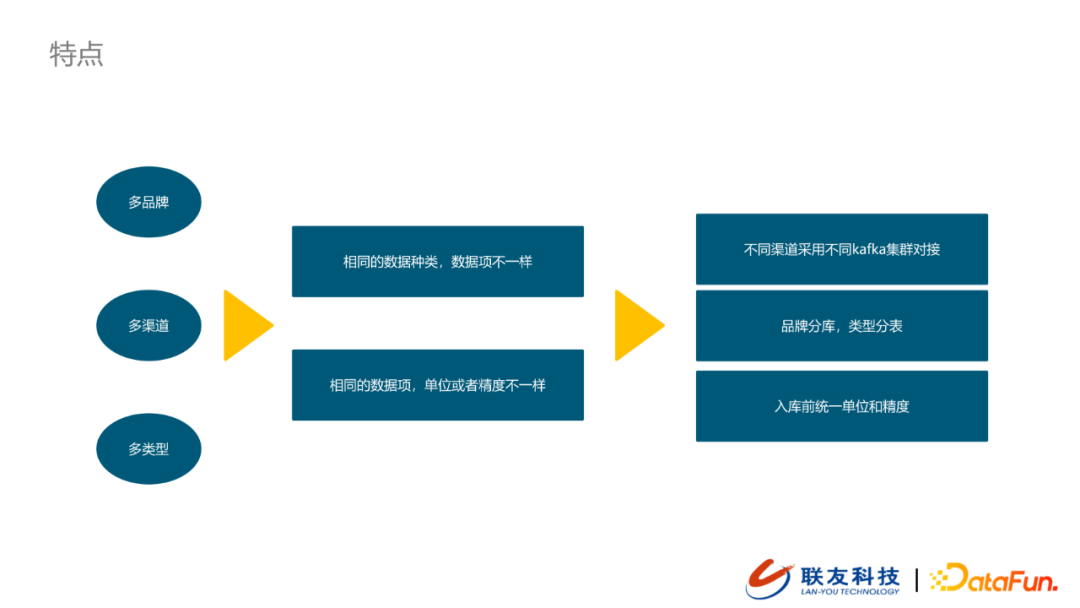
當前數據平台接入的數據源具有多品牌、多渠道、多類型等特點,也正因為數據源的多樣性,我們在數據接入上分渠道,在數據清洗時統一單位和精度,在數據存儲上分庫&分表,以便於向下游提供同一規範的數據。
2. 數據接入架構演進(配置化數據接入)
長期的業務過程證明,不同的「廠商」、不同的「車型」對數據採集項的要求是不一樣的。以前的做法是採用統一的數據採集協議,這就引入了一個問題,不同的車型對於數據採集項是不一樣的,例如我們採集欄位的枚舉有3000個,但是某一個車型的數據欄位只有2000個,而「統一數據採集協議」要求所有回傳的數據都具有同樣的結構,這就要求上傳車型需要冗餘其中1000個不屬於自己的欄位,並且全部置空,這會導致數據傳輸過程中存在大量的冗餘資訊。但是我們希望車輛只回傳自己需要回傳的欄位。那麼如何解決這類問題呢?我們後續的演進方向是支援「配置化數據接入」,具體的示意圖如下:
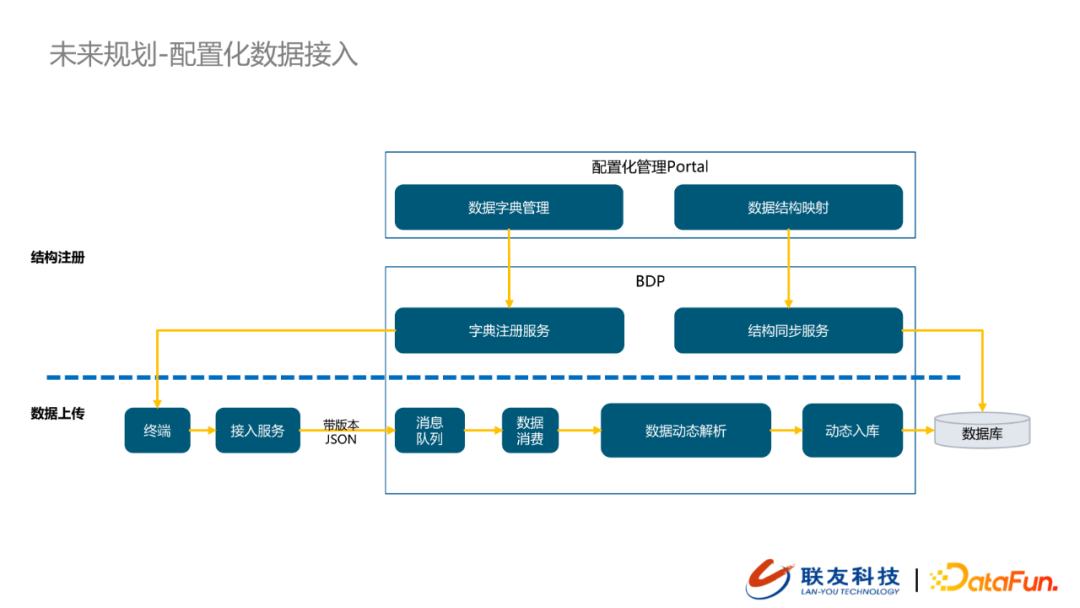
在「配置化數據接入」中會有一個配置化管理portal,在介面上用戶可以配置數據字典,配置生效的數據採集協議會在欄位註冊服務中完成欄位註冊,並將數據採集協議下發到終端TCU。同時會將已經配置好的數據採集協議映射成後台資料庫的數據結構,並走「結構同步服務」將最新的數據採集協議同步到資料庫中。當終端接收到新的數據協議之後,就會按照新的數據協議上報帶協議版本的數據到數據接入服務,並推送到雲端的kafka中。雲端數據解析服務會從kafka中消費消息,然後根據「數據字典」中註冊的數據協議完成數據的動態解析,再根據數據結構執行數據動態入庫(表格schema已經被「結構同步服務」變更)。
—
03 數據存儲
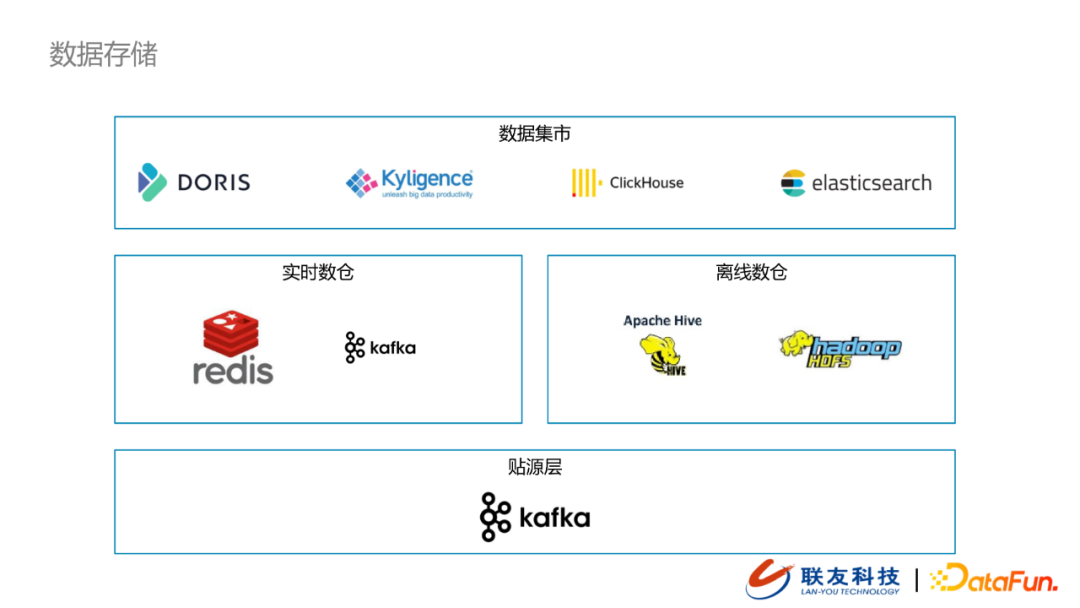
當前所有接入的數據在經過數據接入流程之後,會統一寫到貼源層的kafka集群。當前我們的數倉層分為兩塊:實時數倉、離線數倉。
- 實時數倉我們採用的是kafka+redis的組合
- 離線數倉我們採用的還是傳統的Hive+HDFS的方案
經過數倉清洗之後的數據會分主題推送到數據集市中。我們面向不同的應用場景選用了不同的解決方案:
- Doris:基於埋點數據分析用戶的運營活動,例如流程分析,漏斗分析等
- Kyligence:支援數據的多維分析(MOLAP),面向固定報表分析
- Clickhouse:支援數據自定義分析,體現數據分析的靈活性
- Elasticsearch:分數據視圖,支援數據檢索
1. 實時數倉
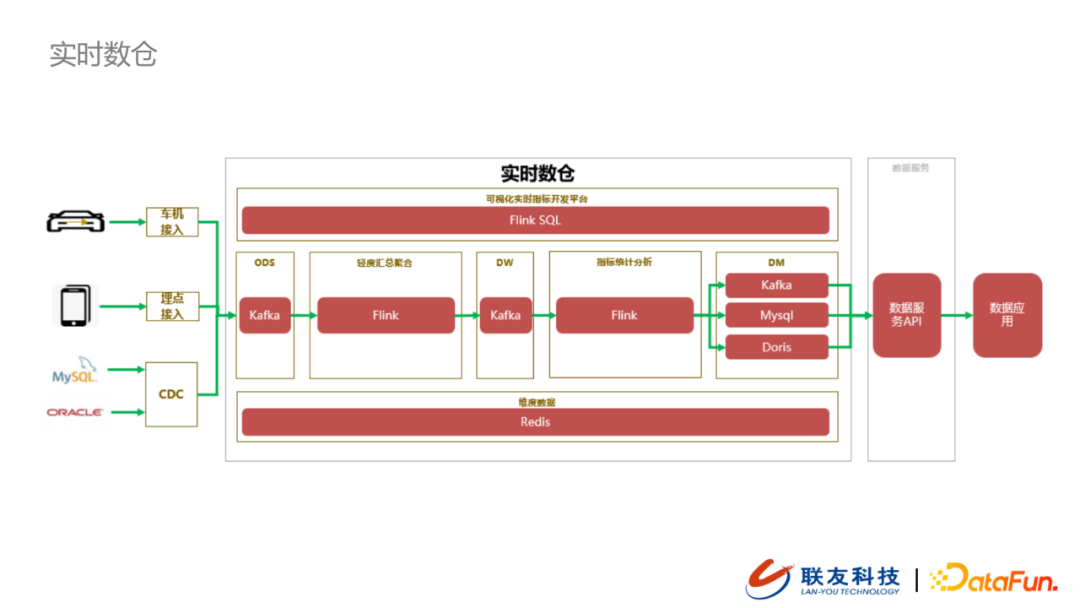
除了之前提到的車機數據接入以及埋點數據接入以外,我們數倉的數據源還包括車企內部系統的數據,針對這類數據,我們採用了CDC的方式從數據源(MySQL或者Oracle)中捕獲數據,並寫入到貼源層的kafka中。Kafka中的數據會被下游的Flink Job消費,並做數據的輕度匯總,然後寫入到DW(kafka)中。下游支援實時指標計算的 Flink job 會從數據DW中拉取數據完成指標計算,並按照下游需求,將計算結果推送DM層。在實時數倉的最上層是基於Flink SQL構建的可視化實時指標開發平台,用戶可以通過寫SQL的方式,完成實時指標開發。所有DM層的指標數據會通過數據服務API的方式供下游的數據應用查詢。
2. 離線數倉
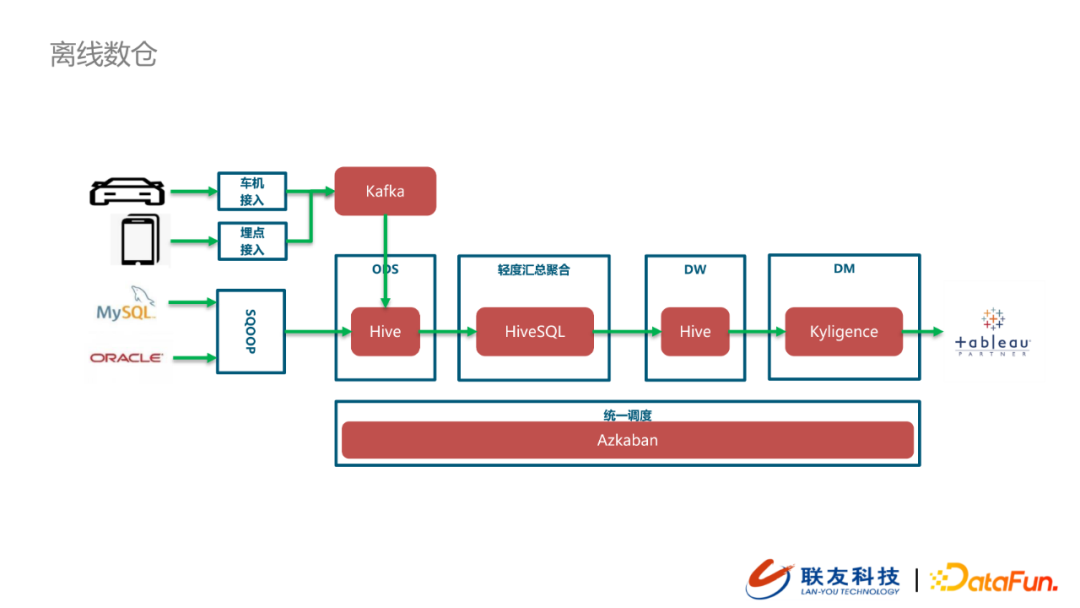
可以看到,離線數倉與實時數倉的數據源是相同的,都包括車機數據埋點、設備接入埋點以及外部系統數據。埋點數據統一接入kafka,然後寫入ODS(Hive),而在外部系統數據同步上存在差異。離線數倉在同步外部系統數據時採用的是sqoop。數據統一入倉之後會做輕度的數據匯總,並寫入到DW層(Hive)。下游的DM層會對數據按照主題做分塊(cube)與分片(slice),應對穩定的BI需求(Kyligence)。在數據可視化層,採用的是Tableau,支援到MOLAP場景的需求。內部的各種數據ETL任務會統一在底層的調度層(Azkaban)來做編排與調度。
在數據集市層,我們主要面臨兩類需求:固定報表分析與實時多維報表分析。
- 固定報表分析 – Kyligence
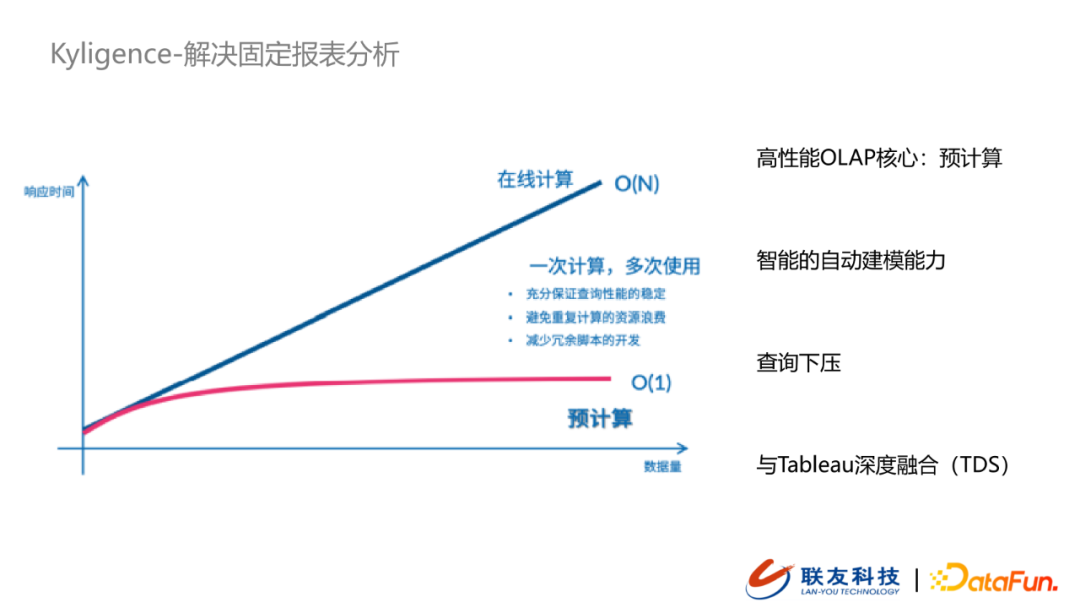
應對MOLAP場景時,Kyligence使用的是典型的空間換時間的方式支援到高性能的OLAP計算(預計算),除此之外,還能夠做到自動建模與查詢下壓。其中我們選擇Kyligence的一個很大的原因是由於其提供了與Tableau深度融合的能力,目前我們的客戶在數據可視化方案上採用的是Tableau,Kyligence提供的TDS很好地支援到我們將數據集市中的數據對接到Tableau,而不需要再走定時數據同步,提升了數據性能。
- 實時報表分析 – Doris
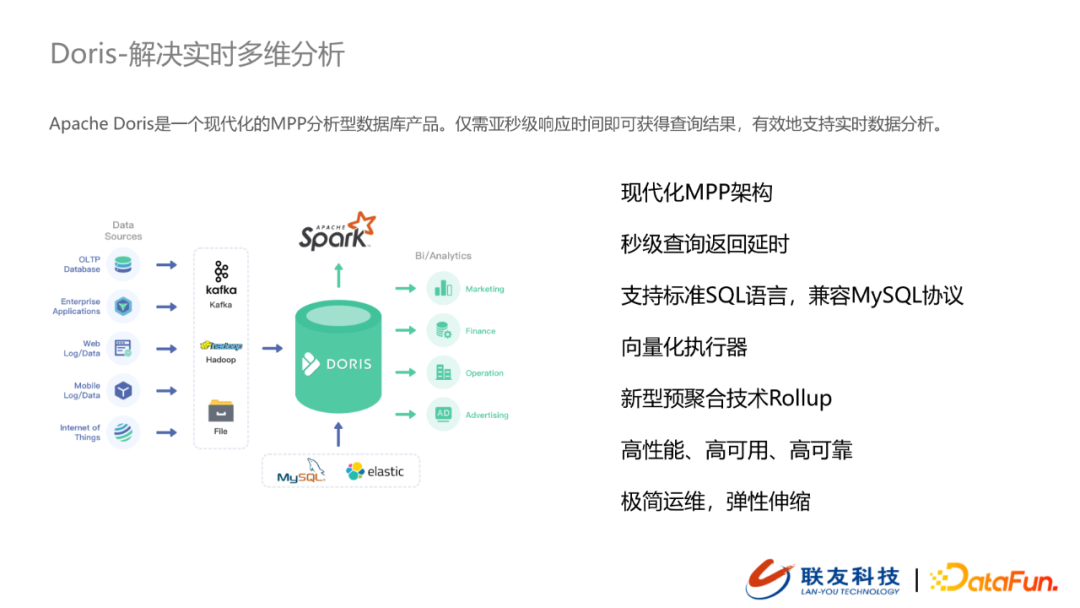
當前我們的埋點數據主要是用戶行為數據,這類數據會統一在用戶運營平台完成用戶行為的分析(熱點事件,漏斗分析),這個過程會涉及到輕量級的join分析,Doris就非常適合這類場景。
—
04 數據應用
1. 用戶運營 – 離線
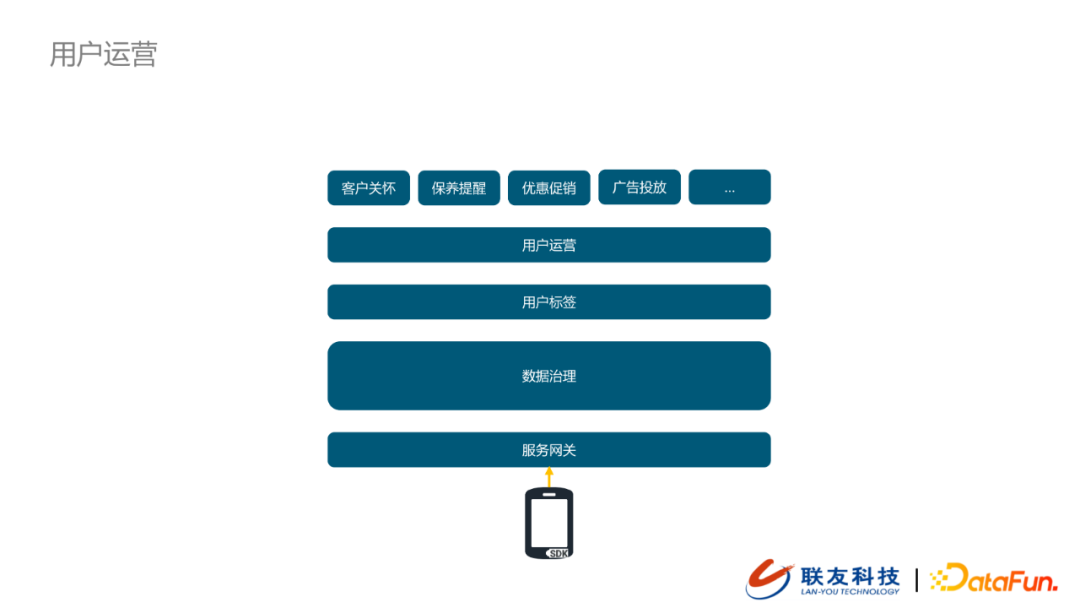
我們APP、車機、官網/官微的數據會通過服務網關的方式採集到大數據平台,經過數據輕度匯聚之後,將用戶特徵與我們標籤體系中的標籤特徵做匹配,並打上相應的標籤。用戶運營人員會做大量的用戶群體分類篩選,這些資訊會支援我們對特定的用戶做客戶關懷、保養提醒、優惠促銷、廣告投放等服務。
2. 智慧推薦 – 實時
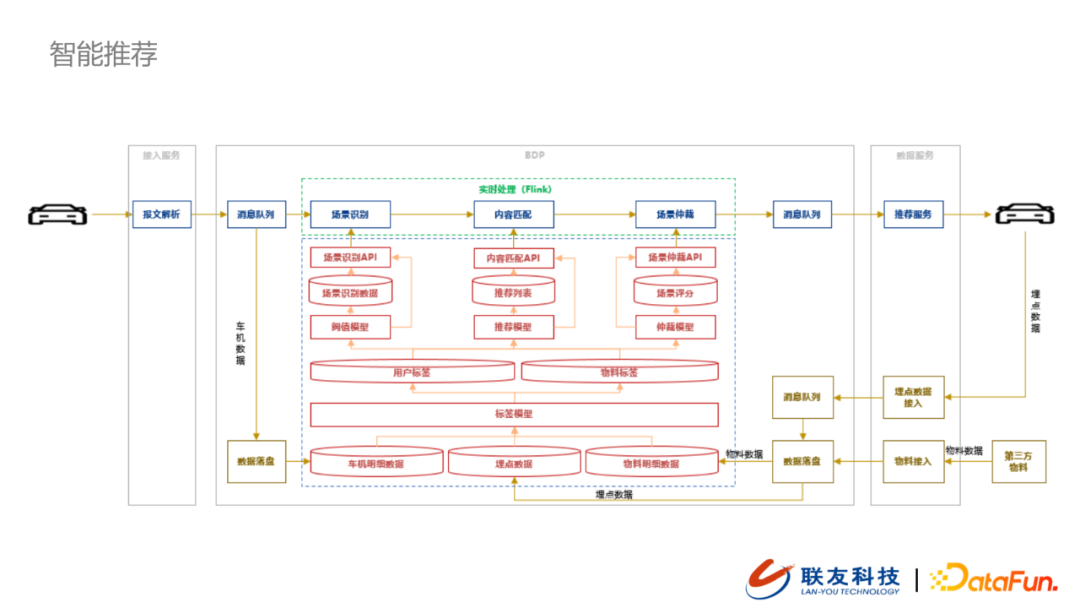
根據上圖所示,智慧推薦核心業務過程包括場景識別、內容匹配、場景仲裁。我們在支援智慧推薦應用上主要有如下幾個數據流程:
- 車機數據上報:車機上報的狀態數據經過報文解析為格式化的數據之後,會推送到BDP的數據接入層。這類數據在消息隊列之後會做數據的分流:一條鏈路是數據落盤歸檔,作為最穩定的原始數據,支撐上游的分析與業務應用;另外一條鏈路會支援到實時業務場景應用。
- 埋點數據回傳:用戶終端在接收到這類推送之後會有自己的回饋,這類數據會以埋點數據的形式再回傳到大數據平台
- 第三方數據:我們會與第三方廠商做一些合作,拉取物料數據到我們的大數據平台,豐富我們的數據基礎。
基於以上三類數據源,在打上初步的標籤(物料標籤或者用戶標籤)之後會支援我們構建如下三個核心能力:
- 場景庫
將海量的用戶基礎數據與標籤數據經過閾值模型對用戶以及用戶行為進行分類後的結果豐富場景資料庫,下游的場景識別API可以基於場景庫與閾值模型做出場景識別,例如我們可以基於用戶真實加油習慣做加油時機的推薦。
- 內容庫
內容庫與場景庫建設類似,進入系統的用戶標籤數據與物料標籤數據輸入到推薦模型之後,會生成推薦列表,再通過內容匹配API開放給實時業務流程的內容匹配模組。
- 場景仲裁
在數據流經仲裁模組之後,場景仲裁模型會根據用戶配置的場景優先順序進行場景評分。評分之後的場景會也通過場景仲裁API開放給實時業務模組。
由以上業務過程與數據流程可知,我們的數據流程是在不斷運轉迭代的,智慧推薦業務在上線之後,會產生源源不斷的用戶回饋數據,這些回饋數據會迴流到我們的數據系統中,幫助我們提升推薦的準確度。例如基於提取到的車輛位置資訊,我們能了解到車輛軌跡資訊在空間上的分布,這類資訊可以支撐我們做一些加油站與充電樁的選址與建設。再例如我們可以基於收集到的用戶駕駛行為數據(急加速,急轉彎等)對用戶進行分類,並基於類別資訊作合適的維保推薦。在智慧推薦中還有一個比較成功的場景是我們基於用戶的駕駛行為數據構建了用戶畫像與駕駛行為知識圖譜,基於知識圖譜搭建了一個智慧客服,當前用戶90%的問題夠可以通過我們的智慧客服來解決,很大程度上節約了我們的人力成本。
—
05 數據應用
問:剛才老師有提到我們有採集車輛的位置數據,那我們的數據合規與數據安全問題是怎麼解決的呢?
答:數據安全與數據合規是我們在做數據採集時必須要考慮的。首先,用戶在購買搭載我們車聯網方案的車之後,在開始使用我們提供的服務之前,我們會讓用戶瀏覽我們的數據採集協議,在徵得用戶同意之後,我們才會做協議範圍內的用戶資訊採集。其次,我們採集到的用戶隱私數據(例如位置資訊)只會在我們的數據中心存儲七天,七天之前的數據我們會做清理與銷毀。最後,我們基於用戶位置資訊加工產生的隱私數據(例如公司地點、居住地點等)在滿足數據合規要求的前提下進行持久化,這類數據我們目前持有的時間周期是30天,超出數據持有周期的數據我們同樣會做清理與銷毀。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號DataFunTalk」,歡迎轉載分享,轉載請留言或評論。

