開發一個不需要重寫成Hive QL的大數據SQL引擎
摘要:開發一款能支援標準資料庫SQL的大數據倉庫引擎,讓那些在Oracle上運行良好的SQL可以直接運行在Hadoop上,而不需要重寫成Hive QL。
本文分享自華為雲社區《從零開發大數據SQL引擎》,作者:JavaEdge 。
學習大數據技術的核心原理,掌握一些高效的思考和思維方式,構建自己的技術知識體系。明白了原理,有時甚至不需要學習,順著原理就可以推導出各種實現細節。
各種知識表象看雜亂無章,若只是學習繁雜知識點,固然自己的知識面是有限的,並且遇到問題的應變能力也很難提高。所以有些高手看起來似乎無所不知,不論談論起什麼技術,都能頭頭是道,其實並不是他們學習、掌握了所有技術,而是他們是在談到這個問題時,才開始進行推導,並迅速得出結論。
高手不一定要很資深、經驗豐富,把握住技術的核心本質,掌握快速分析推導的能力,能迅速將自己的知識技能推到陌生領域,就是高手。
本系列專註大數據開發需要關注的問題及解決方案。跳出繁雜知識表象,掌握核心原理和思維方式,進而融會貫通各種技術,再通過各種實踐訓練,成為終極高手。
大數據倉庫Hive
作為一個成功的大數據倉庫,它將SQL語句轉換成MapReduce執行過程,並把大數據應用的門檻下降到普通數據分析師和工程師就可以很快上手的地步。
但Hive也有問題,由於它使用自定義Hive QL,對熟悉Oracle等傳統數據倉庫的分析師有上手難度。特別是很多企業使用傳統數據倉庫進行數據分析已久,沉澱大量SQL語句,非常龐大也非常複雜。某銀行的一條統計報表SQL足足兩張A4紙,光是完全理解可能就要花很長時間,再轉化成Hive QL更費力,還不說可能引入bug。
開發一款能支援標準資料庫SQL的大數據倉庫引擎,讓那些在Oracle上運行良好的SQL可以直接運行在Hadoop上,而不需要重寫成Hive QL。
Hive處理過程
- 將輸入的Hive QL經過語法解析器轉換成Hive抽象語法樹(Hive AST)
- 將Hive AST經過語義分析器轉換成MapReduce執行計劃
- 將生成的MapReduce執行計劃和Hive執行函數程式碼提交到Hadoop執行
可見,最簡單的,對第一步改造即可。考慮替換Hive語法解析器:能將標準SQL轉換成Hive語義分析器能處理的Hive抽象語法樹,即紅框代替黑框。
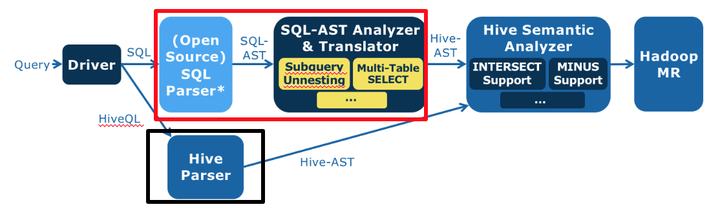
紅框內:淺藍色是個開源的SQL語法解析器,將標準SQL解析成標準SQL抽象語法樹(SQL AST),後面深藍色訂製開發的SQL抽象語法樹分析與轉換器,將SQL AST轉換成Hive AST。
那麼關鍵問題就來了:
標準SQL V.S Hive QL
- 語法表達方式,Hive QL語法和標準SQL語法略有不同
- Hive QL支援的語法元素比標準SQL要少很多,比如,數據倉庫領域主要的測試集TPC-H所有的SQL語句,Hive都不支援。尤其是Hive不支援複雜嵌套子查詢,而數據倉庫分析中嵌套子查詢幾乎無處不在。如下SQL,where條件existes里包含了另一條SQL:
select o_orderpriority, count(*) as order_count from orders where o_orderdate >= date '[DATE]' and o_orderdate < date '[DATE]' + interval '3' month and exists (select * from lineitem where l_orderkey = o_orderkey and l_commitdate < l_receiptdate) group by o_orderpriority order by o_orderpriority;
開發支援標準SQL語法的SQL引擎難點,就是消除複雜嵌套子查詢掉,即讓where里不包含select。
SQL理論基礎是關係代數,主要操作僅包括:並、差、積、選擇、投影。而一個嵌套子查詢可等價轉換成一個連接(join)操作,如:
select s_grade from staff where s_city not in ( select p_city from proj where s_empname = p_pname )
這是個在where條件里嵌套了not in子查詢的SQL語句,它可以用left outer join和left semi join進行等價轉換,示例如下,這是Panthera自動轉換完成得到的等價SQL。這條SQL語句不再包含嵌套子查詢,
select panthera_10.panthera_1 as s_grade from (select panthera_1, panthera_4, panthera_6, s_empname, s_city from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname as s_empname, s_city as s_city from staff) panthera_14 left outer join (select panthera_16.panthera_7 as panthera_7, panthera_16.panthera_8 as panthera_8, panthera_16.panthera_9 as panthera_9, panthera_16.panthera_12 as panthera_12, panthera_16.panthera_13 as panthera_13 from (select panthera_0.panthera_1 as panthera_7, panthera_0.panthera_4 as panthera_8, panthera_0.panthera_6 as panthera_9, panthera_0.s_empname as panthera_12, panthera_0.s_city as panthera_13 from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname, s_city from staff) panthera_0 left semi join (select p_city as panthera_3, p_pname as panthera_5 from proj) panthera_2 on (panthera_0.panthera_4 = panthera_2.panthera_3) and (panthera_0.panthera_6 = panthera_2.panthera_5) where true) panthera_16 group by panthera_16.panthera_7, panthera_16.panthera_8, panthera_16.panthera_9, panthera_16.panthera_12, panthera_16.panthera_13) panthera_15 on ((((panthera_14.panthera_1 <=> panthera_15.panthera_7) and (panthera_14.panthera_4 <=> panthera_15.panthera_8)) and (panthera_14.panthera_6 <=> panthera_15.panthera_9)) and (panthera_14.s_empname <=> panthera_15.panthera_12)) and (panthera_14.s_city <=> panthera_15.panthera_13) where ((((panthera_15.panthera_7 is null) and (panthera_15.panthera_8 is null)) and (panthera_15.panthera_9 is null)) and (panthera_15.panthera_12 is null)) and (panthera_15.panthera_13 is null)) panthera_10 ;
通過可視化工具將上面兩條SQL的語法樹展示出來,是這樣的。

這是原始的SQL抽象語法樹。

這是等價轉換後的抽象語法樹,內容太多被壓縮的無法看清,不過你可以感受一下(笑)。
那麼,在程式設計上如何實現這樣複雜的語法轉換呢?當時Panthera項目組合使用了幾種經典的設計模式,每個語法點被封裝到一個類里去處理,每個類通常不過幾十行程式碼,這樣整個程式非常簡單、清爽。如果在測試過程中遇到不支援的語法點,只需為這個語法點新增加一個類即可,團隊協作與程式碼維護非常容易。
使用裝飾模式的語法等價轉換類的構造,Panthera每增加一種新的語法轉換能力,只需要開發一個新的Transformer類,然後添加到下面的構造函數程式碼里即可。
private static SqlASTTransformer tf = new RedundantSelectGroupItemTransformer( new DistinctTransformer( new GroupElementNormalizeTransformer( new PrepareQueryInfoTransformer( new OrderByTransformer( new OrderByFunctionTransformer( new MinusIntersectTransformer( new PrepareQueryInfoTransformer( new UnionTransformer( new Leftsemi2LeftJoinTransformer( new CountAsteriskPositionTransformer( new FilterInwardTransformer( //use leftJoin method to handle not exists for correlated new CrossJoinTransformer( new PrepareQueryInfoTransformer( new SubQUnnestTransformer( new PrepareFilterBlockTransformer( new PrepareQueryInfoTransformer( new TopLevelUnionTransformer( new FilterBlockAdjustTransformer( new PrepareFilterBlockTransformer( new ExpandAsteriskTransformer( new PrepareQueryInfoTransformer( new CrossJoinTransformer( new PrepareQueryInfoTransformer( new ConditionStructTransformer( new MultipleTableSelectTransformer( new WhereConditionOptimizationTransformer( new PrepareQueryInfoTransformer( new InTransformer( new TopLevelUnionTransformer( new MinusIntersectTransformer( new NaturalJoinTransformer( new OrderByNotInSelectListTransformer( new RowNumTransformer( new BetweenTransformer( new UsingTransformer( new SchemaDotTableTransformer( new NothingTransformer())))))))))))))))))))))))))))))))))))));
而在具體的Transformer類中,則使用組合模式對抽象語法樹AST進行遍歷,以下為Between語法節點的遍歷。我們看到使用組合模式進行樹的遍歷不需要用遞歸演算法,因為遞歸的特性已經隱藏在樹的結構裡面了。
@Override protected void transform(CommonTree tree, TranslateContext context) throws SqlXlateException { tf.transformAST(tree, context); trans(tree, context); } void trans(CommonTree tree, TranslateContext context) { // deep firstly for (int i = 0; i < tree.getChildCount(); i++) { trans((CommonTree) (tree.getChild(i)), context); } if (tree.getType() == PantheraExpParser.SQL92_RESERVED_BETWEEN) { transBetween(false, tree, context); } if (tree.getType() == PantheraExpParser.NOT_BETWEEN) { transBetween(true, tree, context); } }
將等價轉換後的抽象語法樹AST再進一步轉換成Hive格式的抽象語法樹,就可以交給Hive的語義分析器去處理了,從而也就實現了對標準SQL的支援。
當時Facebook為證明Hive對數據倉庫的支援,手工將TPC-H的測試SQL轉換成Hive QL,將這些手工Hive QL和Panthera進行對比測試,兩者性能各有所長,總體上不相上下,說明Panthera自動進行語法分析和轉換的效率還行。
Panthera(ASE)和Facebook手工Hive QL對比測試:
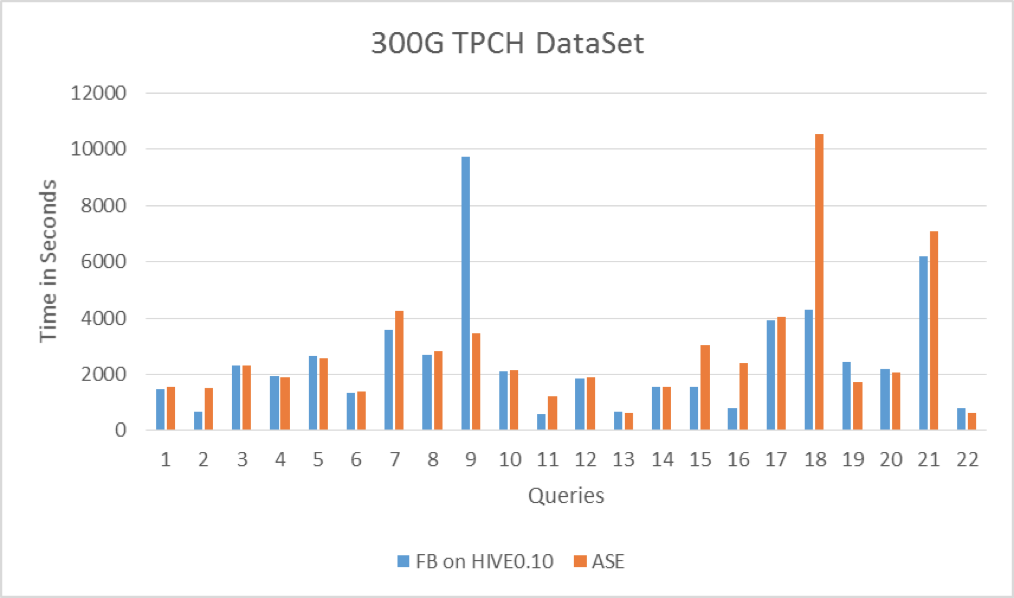
標準SQL語法集的語法點很多,007進行各種關係代數等價變形,也不可能適配所有標準SQL語法。
SQL注入
常見的Web攻擊手段,如下圖所示,攻擊者在HTTP請求中注入惡意SQL命令(drop table users;),伺服器用請求參數構造資料庫SQL命令時,惡意SQL被一起構造,並在資料庫中執行。

但JDBC的PrepareStatement可阻止SQL注入攻擊,MyBatis之類的ORM框架也可以阻止SQL注入,請從資料庫引擎的工作機制解釋PrepareStatement和MyBatis的防注入攻擊的原理。


