全網最硬核 Java 新記憶體模型解析與實驗單篇版(不斷更新QA中)
- 2022 年 3 月 30 日
- 筆記
- JAVA, JVM, 全網最硬核解析JVM
個人創作公約:本人聲明創作的所有文章皆為自己原創,如果有參考任何文章的地方,會標註出來,如果有疏漏,歡迎大家批判。如果大家發現網上有抄襲本文章的,歡迎舉報,並且積極向這個 github 倉庫 提交 issue,謝謝支援~
本篇文章參考了大量文章,文檔以及論文,但是這塊東西真的很繁雜,我的水平有限,可能理解的也不到位,如有異議歡迎留言提出。本系列會不斷更新,結合大家的問題以及這裡的錯誤和疏漏,歡迎大家留言
JMM 相關文檔:
記憶體屏障,CPU 與記憶體模型相關:
x86 CPU 相關資料:
ARM CPU 相關資料:
各種一致性的理解:
Aleskey 大神的 JMM 講解:
相信很多 Java 開發,都使用了 Java 的各種並發同步機制,例如 volatile,synchronized 以及 Lock 等等。也有很多人讀過 JSR 第十七章 Threads and Locks(地址://docs.oracle.com/javase/specs/jls/se17/html/jls-17.html),其中包括同步、Wait/Notify、Sleep & Yield 以及記憶體模型等等做了很多規範講解。但是也相信大多數人和我一樣,第一次讀的時候,感覺就是在看熱鬧,看完了只是知道他是這麼規定的,但是為啥要這麼規定,不這麼規定會怎麼樣,並沒有很清晰的認識。同時,結合 Hotspot 的實現,以及針對 Hotspot 的源碼的解讀,我們甚至還會發現,由於 javac 的靜態程式碼編譯優化以及 C1、C2 的 JIT 編譯優化,導致最後程式碼的表現與我們的從規範上理解出程式碼可能的表現是不太一致的。並且,這種不一致,導致我們在學習 Java 記憶體模型(JMM,Java Memory Model),理解 Java 記憶體模型設計的時候,如果想通過實際的程式碼去試,結果是與自己本來可能正確的理解被帶偏了,導致誤解。
我本人也是不斷地嘗試理解 Java 記憶體模型,重讀 JLS 以及各路大神的分析。這個系列,會梳理我個人在閱讀這些規範以及分析還有通過 jcstress 做的一些實驗而得出的一些理解,希望對於大家對 Java 9 之後的 Java 記憶體模型以及 API 抽象的理解有所幫助。但是,還是強調一點,記憶體模型的設計,出發點是讓大家可以不用關心底層而抽象出來的一些設計,涉及的東西很多,我的水平有限,可能理解的也不到位,我會盡量把每一個論點的論據以及參考都擺出來,請大家不要完全相信這裡的所有觀點,如果有任何異議歡迎帶著具體的實例反駁並留言。
1. 理解「規範」與「實現」
首先,我想先參考 Aleksey Shipilëv 大神的理解思路,即首先分清楚規範(Specification)與實現(Implementation)的區別。前面提到的 JLS(Java Language Specification)其實就是一種規範,它規範了 Java 語言,並且所有能編譯運行 Java 語言的 JDK 實現都要實現它裡面規定的功能。但是對於實際的實現,例如 Hotspot JVM 的 JDK,就是具體的實現了,從規範到實際的實現,其實是有一定的差異的。首先是下面這個程式碼:

實際 HotSpot 最後編譯並且經過 JIT 優化與 CPU 指令優化運行的程式碼其實是:

即將結果 3 放入暫存器並返回,這樣與原始程式碼其實效果是一致的,省略了無用的本地變數操作,也是合理的。那麼你可能會有疑問:不會呀,我打斷點運行到這裡的時候,能看到本地變數 x,y,result 呀。這個其實是 JVM 運行時做的工作,如果你是以 DEBUG 模式運行 JVM,那麼其實 JIT 默認就不會啟用,只會簡單的解釋執行,所以你能看到本地變數。但是實際執行中,如果這個方法是熱點方法,經過 JIT 的優化,這些本地變數其實就不存在了。
還有一個例子是,Hotspot 會有鎖膨脹機制(這個我們後面還會測試),即:
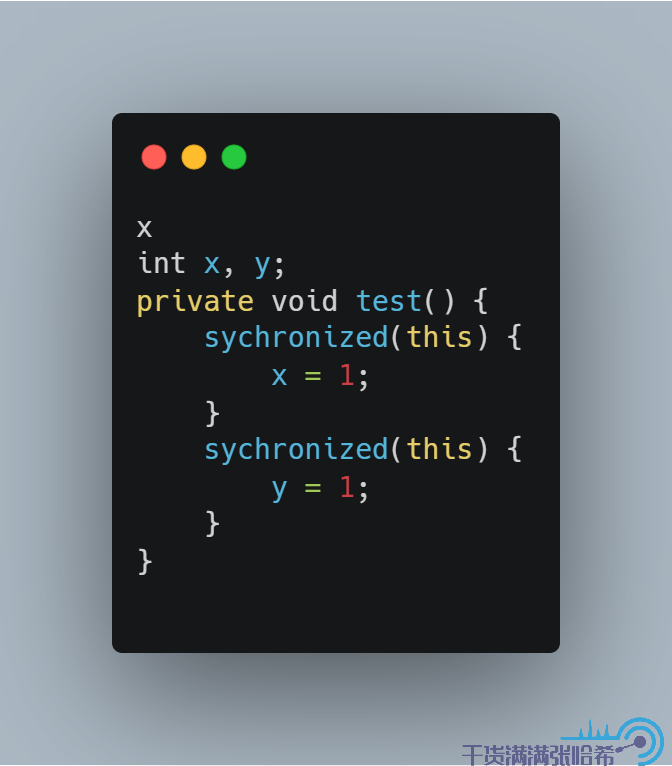
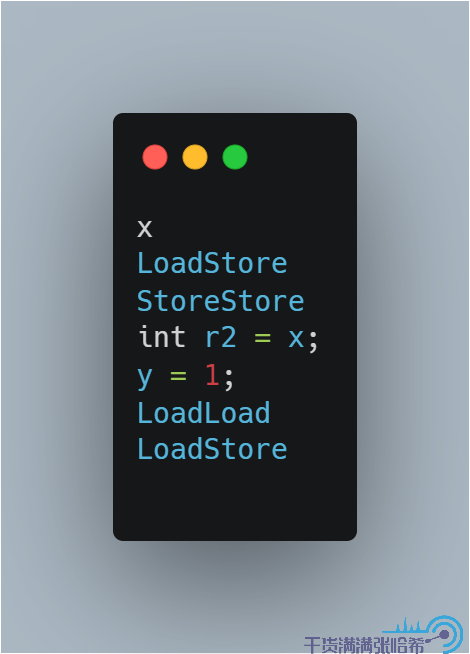
如果按照 JLS 的描述,那麼 x = 1 與 y = 1 這兩個操作是不能重排序的。但是 Hotspot 實際的實現會將上面的程式碼優化成:

那麼這樣,其實 x = 1 與 y = 1 這兩個操作就可以重排序了,這個我們後面也會驗證。
不同的 JVM 實現,實際的表現都會有些差異。並且就算是同一個 JVM 實現,在不同的作業系統,硬體環境等等,表現也有可能不一樣。例如下面這個例子:

正常情況下,r1 的值應該只有 {-1, 0} 這兩個結果之一。但是在某些 32 位的 JVM 上執行會有些問題,例如在 x86_32 的環境下,可能會有 {-1, 0, -4294967296, 4294967295} 這些結果。
所以,如果我們要全面的覆蓋底層到 JMM 設計以及 Hotspot 實現和 JIT 優化等等等等,涉及的東西太多太多,一層邏輯套邏輯,面面俱到我真的做不到。並且我也沒法保證我理解的百分百準確。如果我們要涉及太多的 HotSpot 實現,那麼我們可能就偏離了我們這個系列的主題,我們其實主要關心的是 Java 本身記憶體模型的設計規範,然後從中總結出我們在實際使用中,需要知道並且注意的點的最小集合,這個也是本系列要梳理的,同時,為了保證本系列梳理出的這個最小集合準確,會加上很多實際測試的程式碼,大家也可以跑一下看看這裡給出的結論以及對於 JMM 的理解是否正確。
2. 什麼是記憶體模型
任何需要訪問記憶體的語言,都需要有記憶體模型,描述如何訪問記憶體:即我可以用哪些方式去寫記憶體,可以用哪些方式去讀取記憶體,不同的寫入方式以及讀取方式,會有什麼不同的表現。當然,如果你的程式是一個簡單的串列程式,你讀取到的一定是最新寫入的值,這樣的情況下,其實你並不需要記憶體模型這種東西。一般是並發的環境下,才會需要記憶體模型這個東西。
Java 記憶體模型其實就是規定了在 Java 多執行緒環境下,以不同的特定方式讀取或者寫入記憶體的時候,能觀察到記憶體的合理的值。
也有是這麼定義 Java 記憶體的,即 Java 指令是會重排序的,Java 記憶體模型規定了哪些指令是禁止重排序的,實際上這也是 JLS 第 17 章中 Java 記憶體模型中的主要內容。這其實也是實現觀察到記憶體的合理的值的方式,即對於給定的源程式碼,可能的結果集是什麼。
我們接下來看兩個簡單的入門例子,作為熱身。分別是原子性訪問,以及字分裂。
3. 原子性訪問
原子性訪問,對於一個欄位的寫入與讀取,這個操作本身是原子的不可分割的。可能大家不經常關注的一點是根據 JLS 第 17 章中的說明,下面這兩個操作,並不是原子性訪問的:

因為大家當前的系統通常都是 64 位的,得益於此,這兩個操作大多是原子性的了。但是其實根據 Java 的規範,這兩個並不是原子性的,在 32 位的系統上就保證不了原子性。我這裡直接引用 JLS 第 17 章的一段原話:
For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
Writes and reads of volatile long and double values are always atomic.
翻譯過來,簡單來說非 volatile 的 long 或者 double 可能會按照兩次單獨的 32 位寫更新,所以是非原子性的。volatile 的 long 或者 double 讀取和寫入都是原子性的。
為了說明我們這裡的原子性,我引用一個 jcstress 中的一個例子:
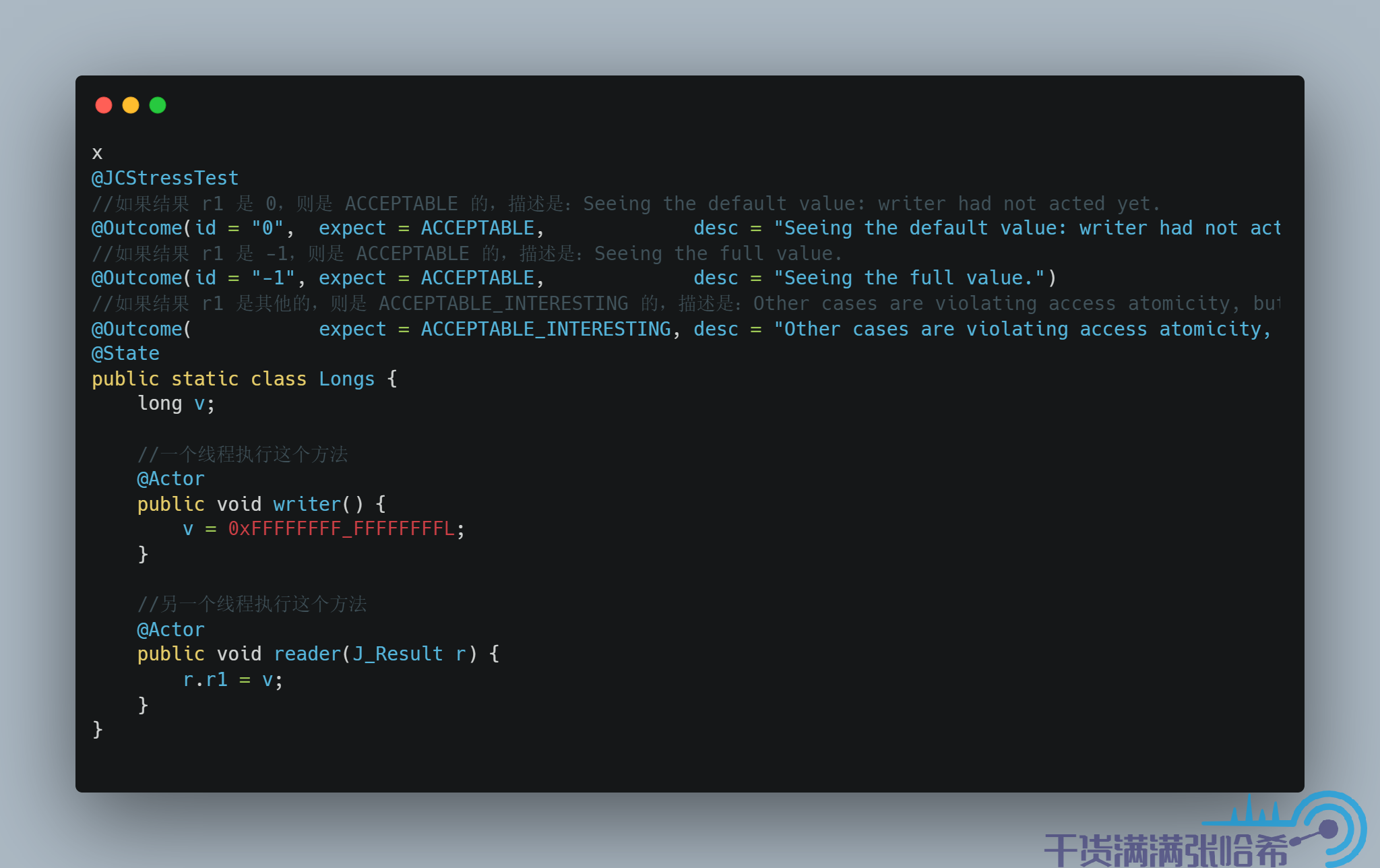
我們使用 Java 8 32bit (Java 9 之後就不再支援 32 位的機器了)的 JVM 運行這裡的程式碼,結果是:

可以看到,結果不止 -1 和 0 這種我們程式碼中的指定的值,還有一些中間結果。
4. 字分裂(word tearing)
字分裂(word tearing)即你更新一個欄位,數組中的一個元素,會影響到另一個欄位,數組中的另一個元素的值。例如處理器沒有提供寫單個 byte 的功能,假設最小維度是 int,在這樣的處理器上更新 byte 數組,若只是簡單地讀取 byte 所在的整個 int,更新對應的 byte,然後將整個 int 再寫回,這種做法是有問題的。Java 中沒有字分裂現象,欄位之間以及數組元素之間是獨立的,更新一個欄位或元素不能影響任何其它欄位或元素的讀取與更新。
為了說明什麼是字分裂,舉一個不太恰當的例子,即執行緒不安全的 BitSet。BitSet 的抽象是比特位集合(一個一個 0,1 這樣,可以理解為一個 boolean 集合),底層實現是一個 long 數組,一個 long 保存 64 個比特位,每次更新都是讀取這個 long 然後通過位運算更新對應的比特位,再更新回去。介面層面是一位一位更新,但是底層卻是按照 long 的維度更新的(因為是底層 long 數組),很明顯,如果沒有同步鎖,並發訪問就會並發安全問題從而造成字分裂的問題:
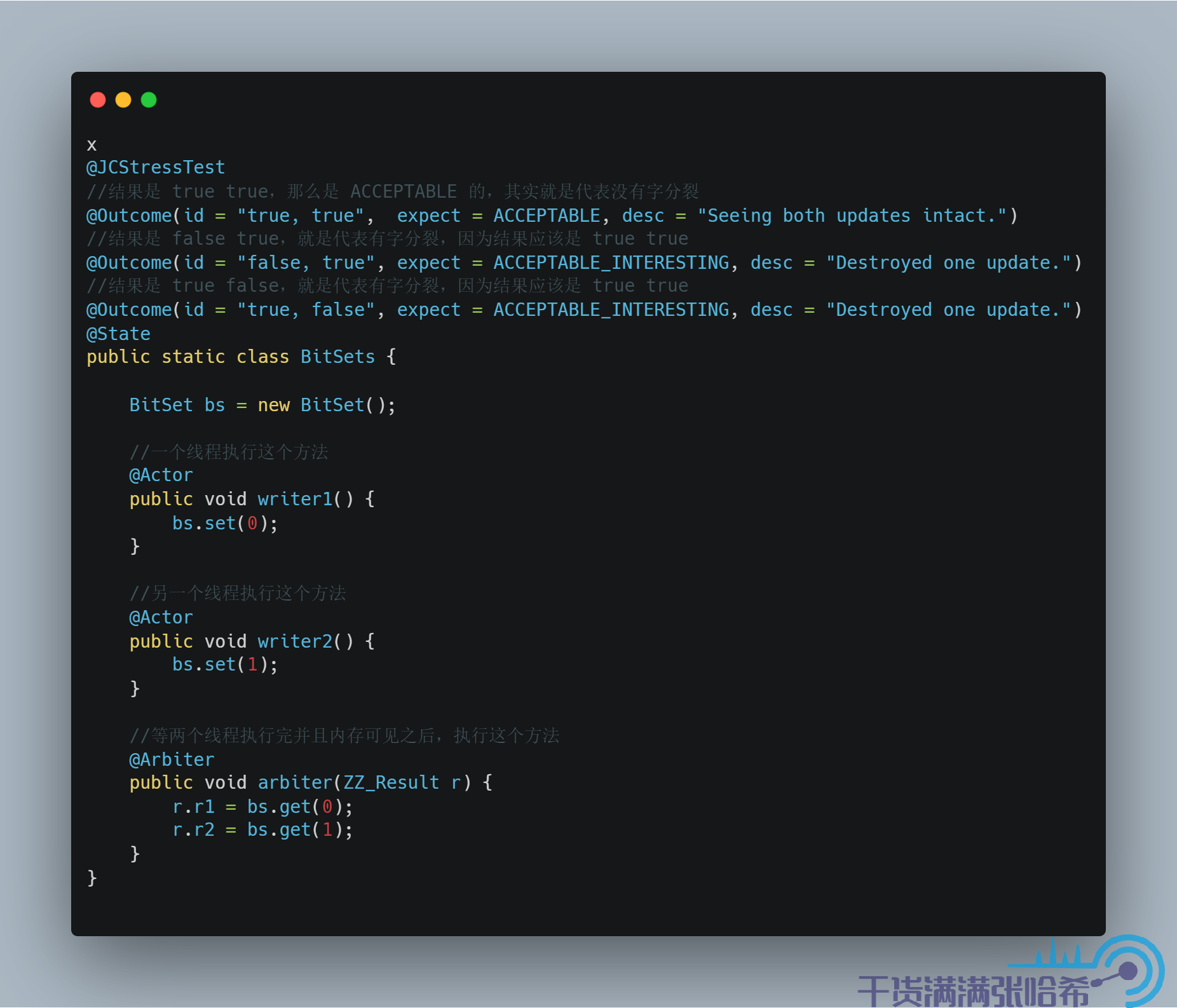
結果是:
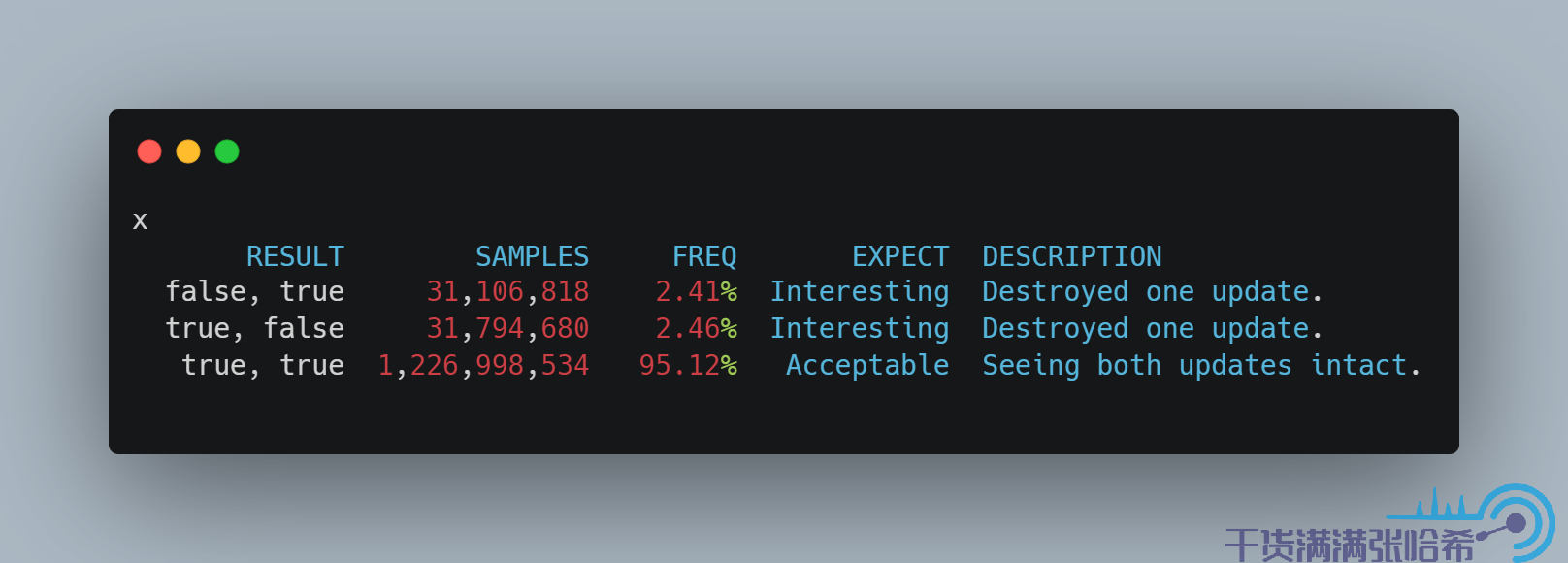
這裡用了一個不太恰當的例子來說明什麼是字分裂,Java 中是可以保證沒有字分裂的,對應上面的 BitSet 的例子就是我們嘗試更新一個 boolean 數組,這樣結果就只會是 true true:
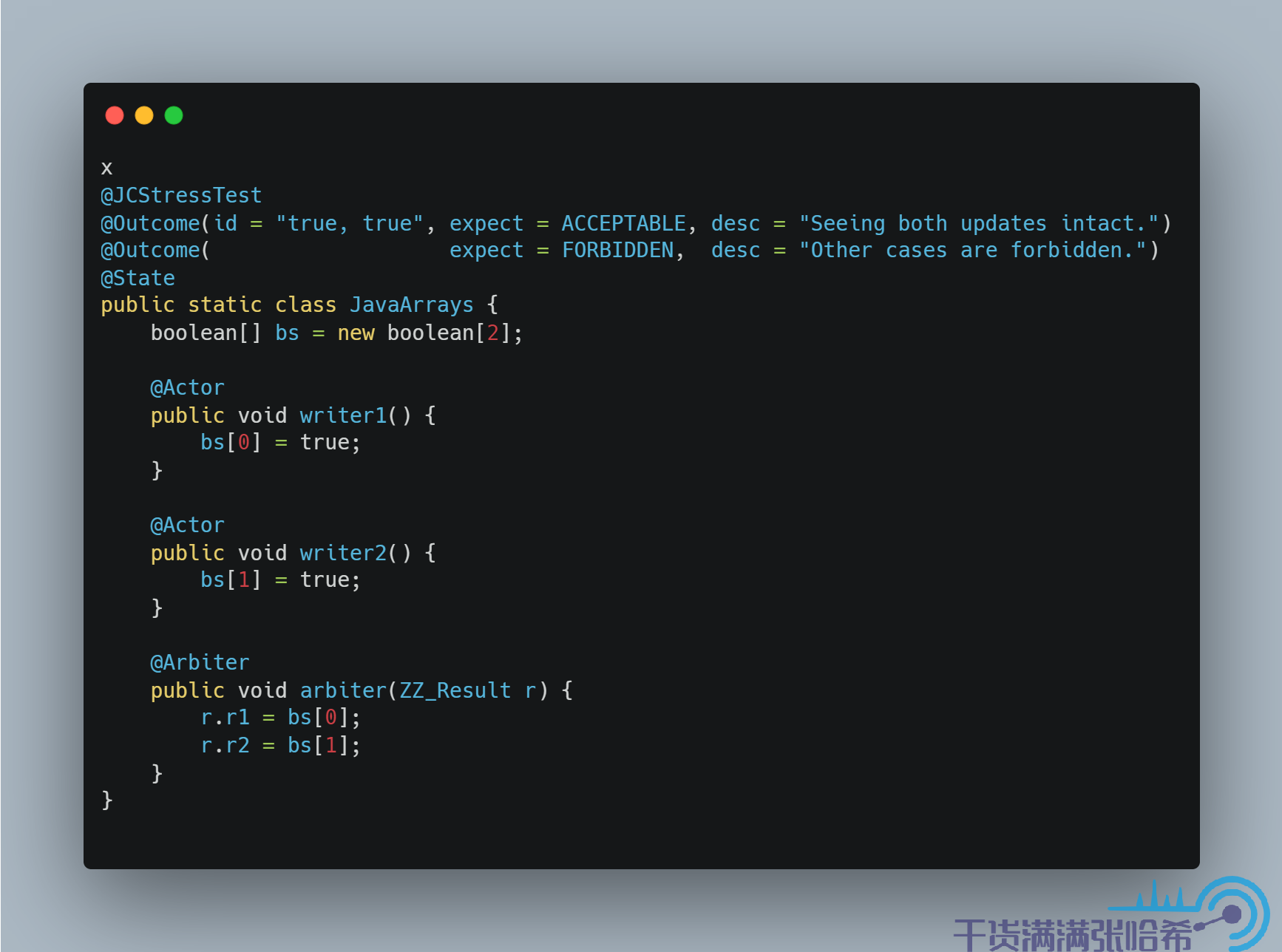
這個結果只會是 true true
接下來,我們將進入一個比較痛苦的章節了,記憶體屏障,不過大家也不用太擔心,從我個人的經驗來看,記憶體屏障很難理解的原因是因為網上基本上不會從 Java 已經為你屏蔽的底層細節去給你講,直接理解會很難說服自己,於是就會猜想一些東西然後造成誤解,所以本文不會上來丟給你 Doug Lea 抽象的並一直沿用至今的 Java 四種記憶體屏障(就是 LoadLoad,StoreStore,LoadStore 和 StoreLoad 這四個,其實通過後面的分析也能看出來,這四個記憶體屏障的設計對於現在的 CPU 來說已經有些過時了,現在用的更多的是 acquire, release 以及 fence)希望能通過筆者看的一些關於底層細節的文章論文中提取出便於大家理解的東西供大家參考,更好地更容易的理解記憶體屏障。
5. 記憶體屏障
5.1. 為何需要記憶體屏障
記憶體屏障(Memory Barrier),也有叫記憶體柵欄(Memory Fence),還有的資料直接為了簡便,就叫 membar,這些其實意思是一樣的。記憶體屏障主要為了解決指令亂序帶來了結果與預期不一致的問題,通過加入記憶體屏障防止指令亂序(或者稱為重排序,reordering)。
那麼為什麼會有指令亂序呢?主要是因為 CPU 亂序(CPU亂序還包括 CPU 記憶體亂序以及 CPU 指令亂序)以及編譯器亂序。記憶體屏障可以用於防止這些亂序。如果記憶體屏障對於編譯器和 CPU 都生效,那麼一般稱為硬體記憶體屏障,如果只對編譯器生效,那麼一般被稱為軟體記憶體屏障。我們這裡主要關注 CPU 帶來的亂序,對於編譯器的重排序我們會在最後簡要介紹下。
5.2. CPU 記憶體亂序相關
我們從 CPU 高速快取以及快取一致性協議出發,開始分析為何 CPU 中會有亂序。我們這裡假設一種簡易的 CPU 模型,請大家一定記住,實際的 CPU 要比這裡列舉的簡易 CPU 模型複雜的多
5.2.1. 簡易 CPU 模型 – CPU 高速快取的出發點 – 減少 CPU Stall
我們在這裡會看到,現代的 CPU 的很多設計,一切以減少 CPU Stall 出發。什麼是 CPU Stall 呢?舉一個簡單的例子,假設 CPU 需要直接讀取記憶體中的數據(忽略其他的結構,例如 CPU 快取,匯流排與匯流排事件等等):
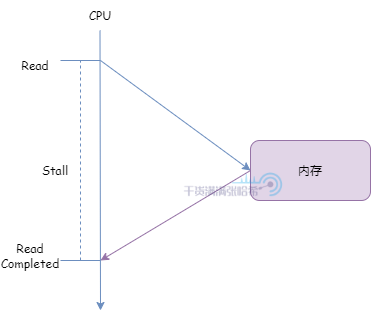
CPU 發出讀取請求,在記憶體響應之前,CPU 需要一直等待,無法處理其他的事情。這一段 CPU 就是處於 Stall 狀態。如果 CPU 一直直接從記憶體中讀取,CPU 直接訪問記憶體消耗時間很長,可能需要幾百個指令周期,也就是每次訪問都會有幾百個指令周期內 CPU 處於 Stall 狀態什麼也幹不了,這樣效率會很低。一般需要引入若干個高速快取(Cache)來減少 Stall:高速快取即與處理器緊挨著的小型存儲器,位於處理器和記憶體之間。
我們這裡不關心多級高速快取,以及是否存在多個 CPU 共用某一快取的情況,我們就簡單認為是下面這個架構:
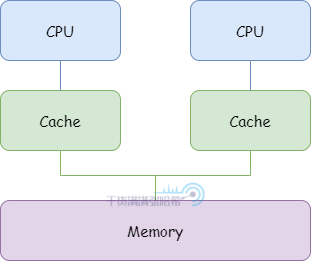
當需要讀取一個地址的值時,訪問高速快取看是否存在:存在代表命中(hit),直接讀取。不存在被稱為缺失(miss)。同樣的,如果需要寫一個值到一個地址,這個地址在快取中存在也就不需要訪問記憶體了。大部分程式都表現出較高的局部性(locality):
- 如果處理器讀或寫一個記憶體地址,那麼它很可能很快還會讀或寫同一個地址。
- 如果處理器讀或寫一個記憶體地址,那麼它很可能很快還會讀或寫附近的地址。
針對局部性,高速快取一般會一次操作不止一個字,而是一組臨近的字,稱為快取行。
但是呢,由於告訴快取的存在,就給更新記憶體帶來了麻煩:當一個 CPU 需要更新一塊快取行對應記憶體的時候,它需要將其他 CPU 快取中這塊記憶體的快取行也置為失效。為了維持每個 CPU 的快取數據一致性,引入了快取一致性協議(Cache Coherence Protocols)
5.2.2. 簡易 CPU 模型 – 一種簡單的快取一致性協議(實際的 CPU 用的要比這個複雜) – MESI
現代的快取一致性的協議以及演算法非常複雜,快取行可能會有數十種不同的狀態。這裡我們並不需要研究這種複雜的演算法,我們這裡引入一個最經典最簡單的快取一致性協議即 4 狀態 MESI 協議(再次強調,實際的 CPU 用的協議要比這個複雜,MESI 其實本身有些問題解決不了),MESI 其實指的就是快取行的四個狀態:
- Modified:快取行被修改,最終一定會被寫回入主存,在此之前其他處理器不能再快取這個快取行。
- Exclusive:快取行還未被修改,但是其他的處理器不能將這個快取行載入快取
- Shared:快取行未被修改,其他處理器可以載入這個快取行到快取
- Invalid:快取行中沒有有意義的數據
根據我們前面的 CPU 快取結構圖中所示,假設所有 CPU 都共用在同一個匯流排上,則會有如下這些資訊在匯流排上發送:
- Read:這個事件包含要讀取的快取行的物理地址。
- Read Response:包含前面的讀取事件請求的數據,數據來源可能是記憶體或者是其他高速快取,例如,如果請求的數據在其他快取處於 modified 狀態的話,那麼必須從這個快取讀取快取行數據作為 Read Response
- Invalidate:這個事件包含要過期掉的快取行的物理地址。其他的高速快取必須移除這個快取行並且響應 Invalidate Acknowledge 消息。
- Invalidate Acknowledge:收到 Invalidate 消息移除掉對應的快取行之後,回復 Invalidate Acknowledge 消息。
- Read Invalidate:是 Read 消息還有 Invalidate 消息的組合,包含要讀取的快取行的物理地址。既讀取這個快取行並且需要 Read Response 消息響應,同時發給其他的高速快取,移除這個快取行並且響應 Invalidate Acknowledge 消息。
- Writeback:這個消息包含要更新的記憶體地址以及數據。同時,這個消息也允許狀態為 modified 的快取行被剔除,以給其他數據騰出空間。
快取行狀態轉移與事件的關係:
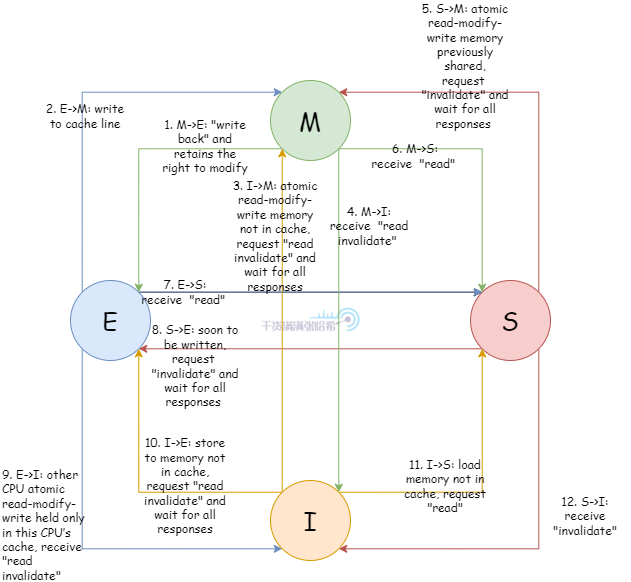
這裡只是列出這個圖,我們不會深入去講的,因為 MESI 是一個非常精簡的協議,具體實現的時候會有很多額外的問題 MESI 無法解決,如果詳細的去講,會把讀者繞進去,讀者會思考在某個極限情況下這個協議要怎麼做才能保證正確,但是 MESI 實際上解決不了這些。在實際的實現中,CPU 一致性協議要比 MESI 複雜的多得多,但是一般都是基於 MESI 擴展的。
舉一個簡單的 MESI 的例子:
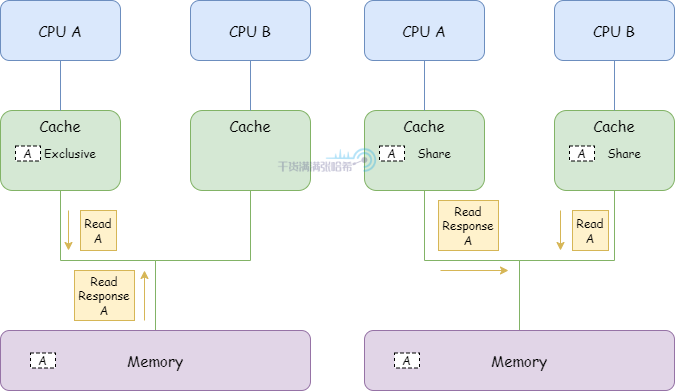
1.CPU A 發送 Read 從地址 a 讀取數據,收到 Read Response 將數據存入他的高速快取並將對應的快取行置為 Exclusive
2.CPU B 發送 Read 從地址 a 讀取數據,CPU A 檢測到地址衝突,CPU A 響應 Read Response 返回快取中包含 a 地址的快取行數據,之後,地址 a 的數據對應的快取行被 A 和 B 以 Shared 狀態裝入快取
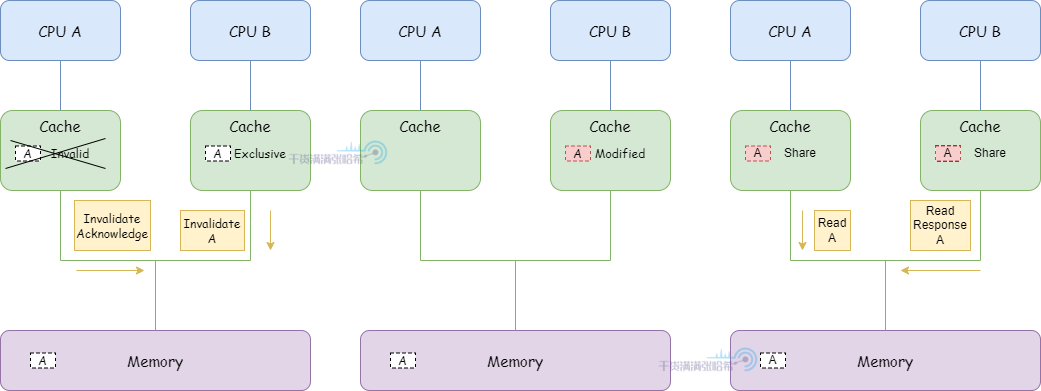
3.CPU B 對於 a 馬上要進行寫操作,發送 Invalidate,等待 CPU A 的 Invalidate Acknowledge 響應之後,狀態修改為 Exclusive。CPU A 收到 Invalidate 之後,將 a 所在的快取行狀態置為 Invalid 失效
4.CPU B 修改數據存儲到包含地址 a 的快取行上,快取行狀態置為 modified
5.這時候 CPU A 又需要 a 數據,發送 Read 從地址 a 讀取數據,CPU B 檢測到地址衝突,CPU B 響應 Read Response 返回快取中包含 a 地址的快取行數據,之後,地址 a 的數據對應的快取行被 A 和 B 以 Shared 狀態裝入快取
我們這裡可以看到,MESI 協議中,發送 Invalidate 消息需要當前 CPU 等待其他 CPU 的 Invalidate Acknowledge,也就是這裡有 CPU Stall。為了避免這個 Stall,引入了 Store Buffer
5.2.3. 簡易 CPU 模型 – 避免等待 Invalidate Response 的 Stall – Store Buffer
為了避免這種 Stall,在 CPU 與 CPU 快取之間添加 Store Buffer,如下圖所示:
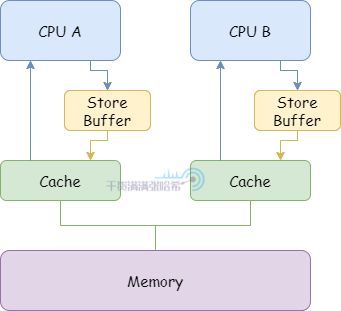
有了 Store Buffer,CPU 在發送 Invalidate 消息的時候,不用等待 Invalidate Acknowledge 的返回,將修改的數據直接放入 Store Buffer。如果收到了所有的 Invalidate Acknowledge 再從 Store Buffer 放入 CPU 的高速快取的對應快取行中。但是加入的這個 Store Buffer 又帶來了新的問題:
假設有兩個變數 a 和 b,不會處於同一個快取行,初始都是 0,a 現在位於 CPU A 的快取行中,b 現在位於 CPU B 的快取行中:
假設 CPU B 要執行下面的程式碼:

我們肯定是期望最後 b 會等於 2 的。但是真的會如我們所願么?我們來詳細看下下面這個運行步驟:
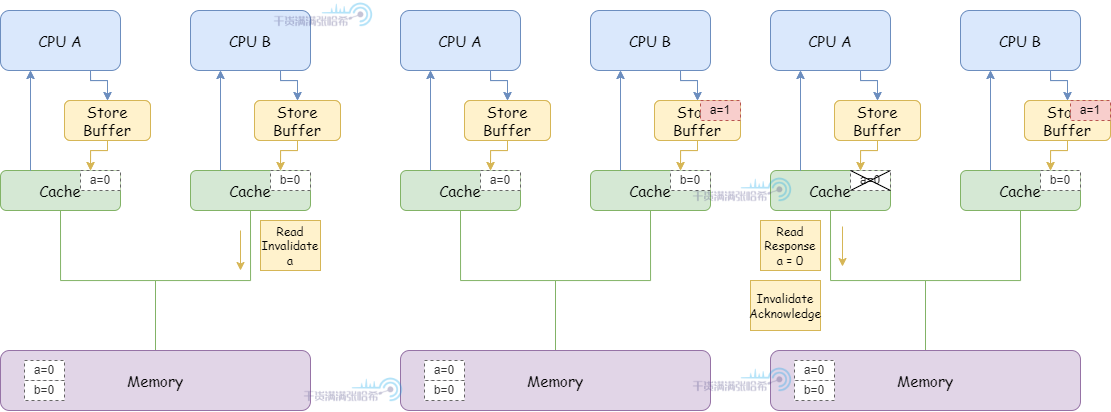
1.CPU B 執行 a = 1:
(1)由於 CPU B 快取中沒有 a,並且要修改,所以發布 Read Invalidate 消息(因為是要先把包含 a 的整個快取行讀取後才能更新,所以發的是 Read Invalidate,而不只是 Invalidate)。
(2)CPU B 將 a 的修改(a=1)放入 Storage Buffer
(3)CPU A 收到 Read Invalidate 消息,將 a 所在的快取行標記為 Invalid 並清除出快取,並響應 Read Response(a=0) 和 Invalidate Acknowlegde。
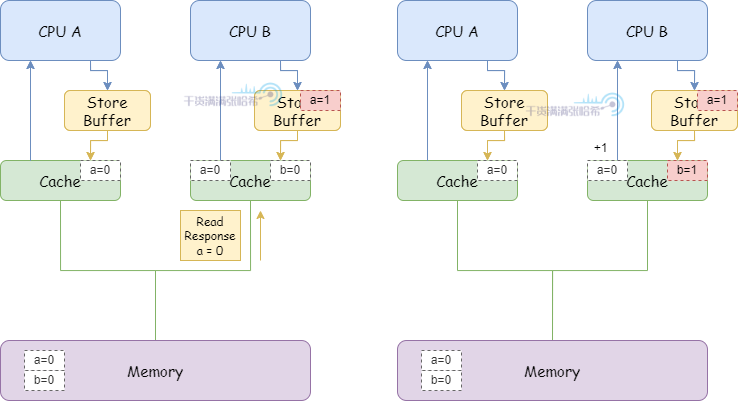
2.CPU B 執行 b = a + 1:
(1)CPU B 收到來自於 CPU A 的 Read Response,這時候這裡面 a 還是等於 0。
(2)CPU B 將 a + 1 的結果(0+1=1)存入快取中已經包含的 b。
3.CPU B 執行 assert(b == 2) 失敗
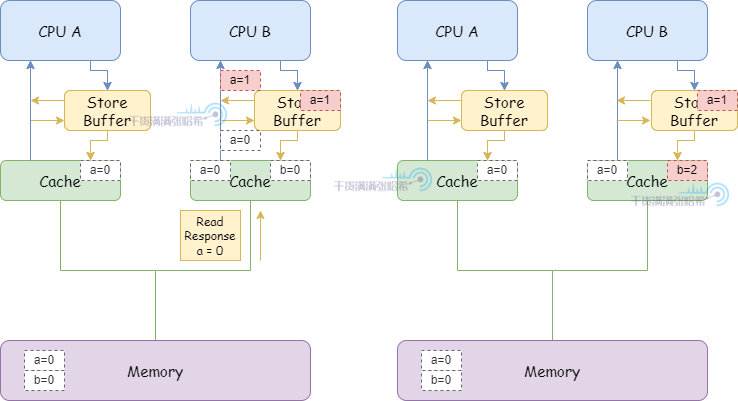
這個錯誤的原因主要是我們在載入到快取的時候沒考慮從 store buffer 最新的值,所以我們可以加上一步,在載入到快取的時候從 store buffer 讀取最新的值。這樣,就能保證上面我們看到的結果 b 最後是 2:
5.2.4. 簡易 CPU 模型 – 避免 Store Buffer 帶來的亂序執行 – 記憶體屏障
我們下面再來看一個示例:假設有兩個變數 a 和 b,不會處於同一個快取行,初始都是 0。假設 CPU A (快取行裡面包含 b,這個快取行狀態是 Exclusive)執行:

假設 CPU B 執行:

如果一切按照程式順序預期執行,那麼我們期望 CPU B 執行 assert(a == 1) 是成功的,但是我們來看下面這種執行流程:
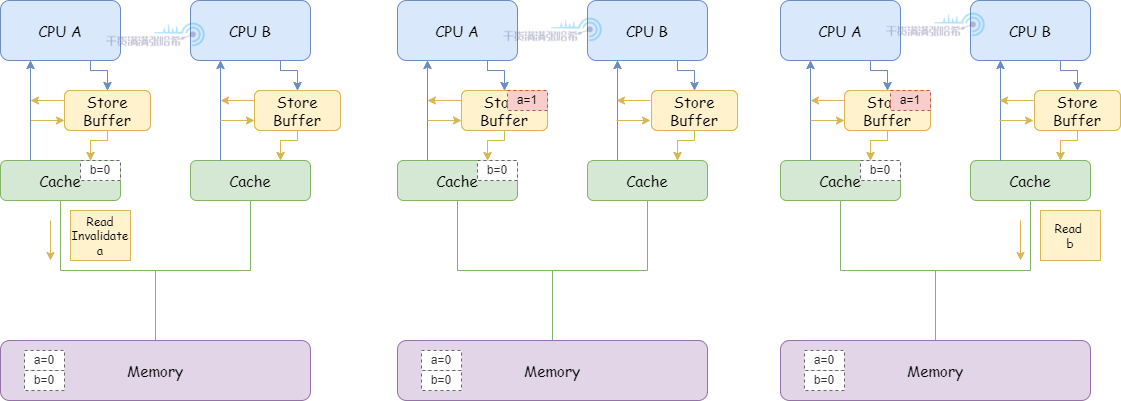
1.CPU A 執行 a = 1:
(1)CPU A 快取裡面沒有 a,並且要修改,所以發布 Read Invalidate 消息。
(2)CPU A 將 a 的修改(a=1)放入 Storage Buffer
2.CPU B 執行 while (b == 0) continue:
(1)CPU B 快取裡面沒有 b,發布 Read 消息。
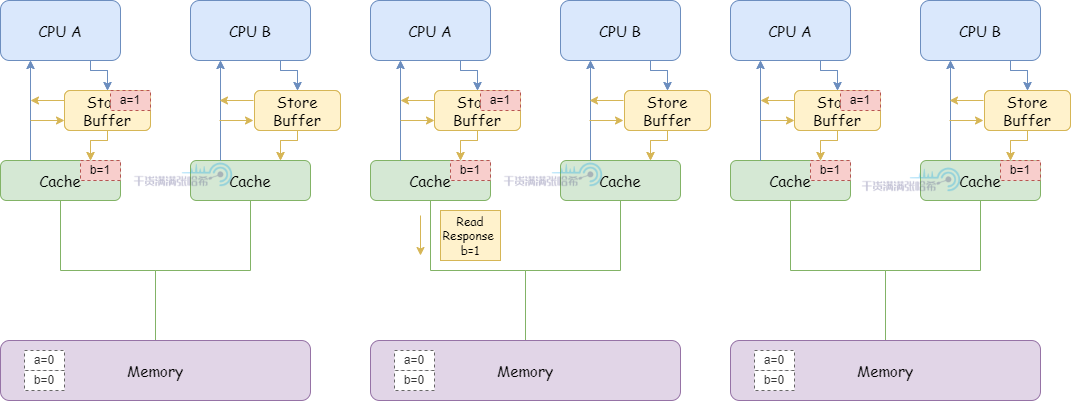
3.CPU A 執行 b = 1:
(1)CPU A 快取行裡面有 b,並且狀態是 Exclusive,直接更新快取行。
(2)之後,CPU A 收到了來自於 CPU B 的關於 b 的 Read 消息。
(3)CPU A 響應快取中的 b = 1,發送 Read Response 消息,並且快取行狀態修改為 Shared
(4)CPU B 收到 Read Response 消息,將 b 放入快取
(5)CPU B 程式碼可以退出循環了,因為 CPU B 看到 b 此時為 1
4.CPU B 執行 assert(a == 1),但是由於 a 的更改還沒更新,所以失敗了。
像這種亂序,CPU 一般是無法自動控制的,但是一般會提供記憶體屏障指令,告訴 CPU 防止亂序,例如:

smp_mb() 會讓 CPU 將 Store Buffer 中的內容刷入快取。加入這個記憶體屏障指令後,執行流程變成:
1.CPU A 執行 a = 1:
(1)CPU A 快取裡面沒有 a,並且要修改,所以發布 Read Invalidate 消息。
(2)CPU A 將 a 的修改(a=1)放入 Storage Buffer
2.CPU B 執行 while (b == 0) continue:
(1)CPU B 快取裡面沒有 b,發布 Read 消息。
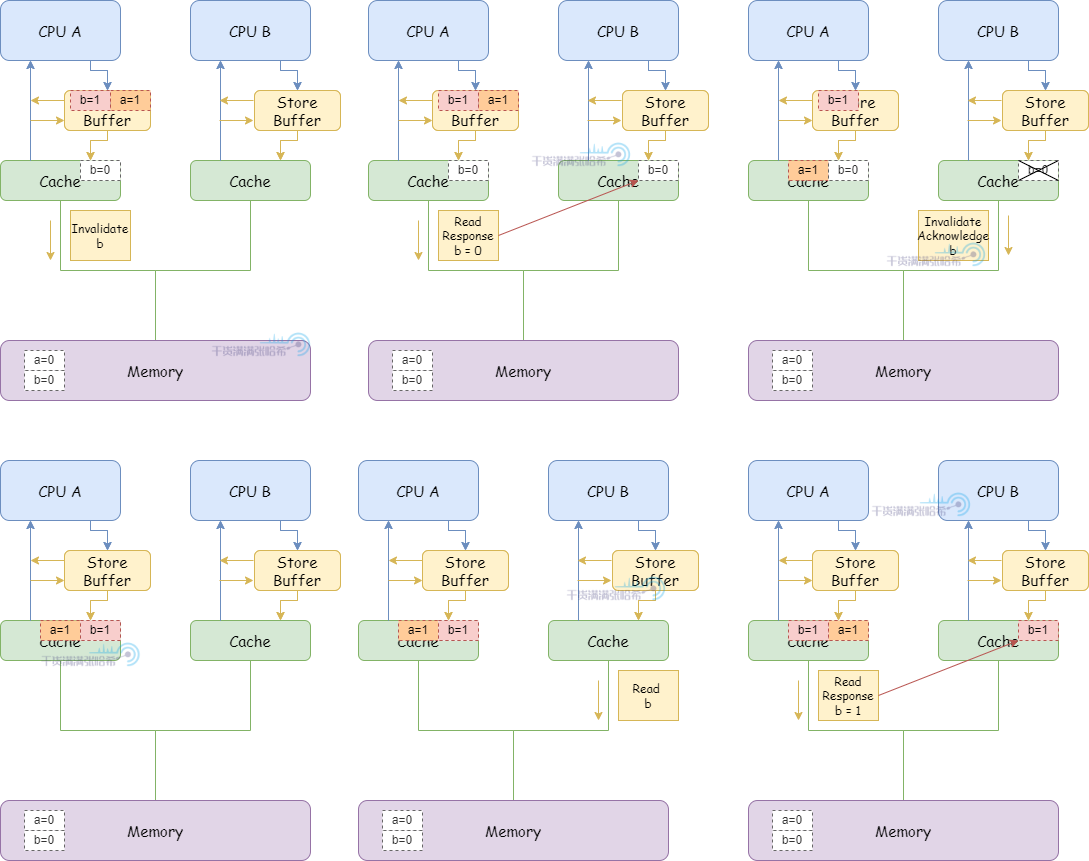
3.CPU B 執行 smp_mb():
(1)CPU B 將當前 Store Buffer 的所有條目打上標記(目前這裡只有 a,就是對 a 打上標記)
4.CPU A 執行 b = 1:
(1)CPU A 快取行裡面有 b,並且狀態是 Exclusive,但是由於 Store Buffer 中有標記的條目 a,不直接更新快取行,而是放入 Store Buffer(與 a 不同,沒有標記)。並發出 Invalidate 消息。
(2)之後,CPU A 收到了來自於 CPU B 的關於 b 的 Read 消息。
(3)CPU A 響應快取中的 b = 0,發送 Read Response 消息,並且快取行狀態修改為 Shared
(4)CPU B 收到 Read Response 消息,將 b 放入快取
(5)CPU B 程式碼不斷循環,因為 CPU B 看到 b 還是 0
(6)CPU A 收到前面對於 a 的 “Read Invalidate” 相關的消息響應,將 Store Buffer 中打好標記的 a 條目刷入快取,這個快取行狀態為 modified。
(7)CPU B 收到 CPU A 發的 Invalidate b 的消息,將 b 的快取行失效,回復 Invalidate Acknowledge
(8)CPU A 收到 Invalidate Acknowledge,將 b 從 Store Buffer 刷入快取。
(9)由於 CPU B 不斷讀取 b,但是 b 已經不在快取中了,所以發送 Read 消息。
(10)CPU A 收到 CPU B 的 Read 消息,設置 b 的快取行狀態為 shared,返回快取中 b = 1 的 Read Response
(11)CPU B 收到 Read Response,得知 b = 1,放入快取行,狀態為 shared
5.CPU B 得知 b = 1,退出 while (b == 0) continue 循環
6.CPU B 執行 assert(a == 1)(這個比較簡單,就不畫圖了):
(1)CPU B 快取中沒有 a,發出 Read 消息。
(2)CPU A 從快取中讀取 a = 1,響應 Read Response
(3)CPU B 執行 assert(a == 1) 成功
Store Buffer 一般都會比較小,如果 Store Buffer 滿了,那麼還是會發生 Stall 的問題。我們期望 Store Buffer 能比較快的刷入 CPU 快取,這是在收到對應的 Invalidate Acknowledge 之後進行的。但是,其他的 CPU 可能在忙,沒發很快應對收到的 Invalidate 消息並響應 Invalidate Acknowledge,這樣可能造成 Store Buffer 滿了導致 CPU Stall 的發生。所以,可以引入每個 CPU 的 Invalidate queue 來快取要處理的 Invalidate 消息。
5.2.5. 簡易 CPU 模型 – 解耦 CPU 的 Invalidate 與 Store Buffer – Invalidate Queues
加入 Invalidate Queues 之後,CPU 結構如下所示:
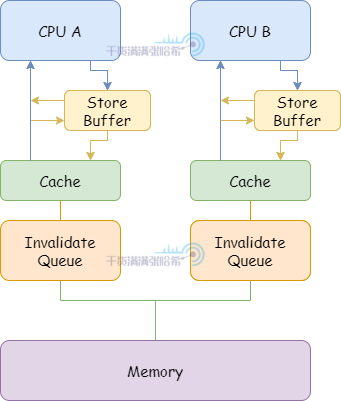
有了 Invalidate Queue,CPU 可以將 Invalidate 放入這個隊列之後立刻將 Store Buffer 中的對應數據刷入 CPU 快取。同時,CPU 在想主動發某個快取行的 Invalidate 消息之前,必須檢查自己的 Invalidate Queue 中是否有相同的快取行的 Invalidate 消息。如果有,必須等處理完自己的 Invalidate Queue 中的對應消息再發。
同樣的,Invalidate Queue 也帶來了亂序執行。
5.2.6. 簡易 CPU 模型 – 由於 Invalidate Queues 帶來的進一步亂序 – 需要記憶體屏障
假設有兩個變數 a 和 b,不會處於同一個快取行,初始都是 0。假設 CPU A (快取行裡面包含 a(shared), b(Exclusive))執行:

CPU B(快取行裡面包含 a(shared))執行:

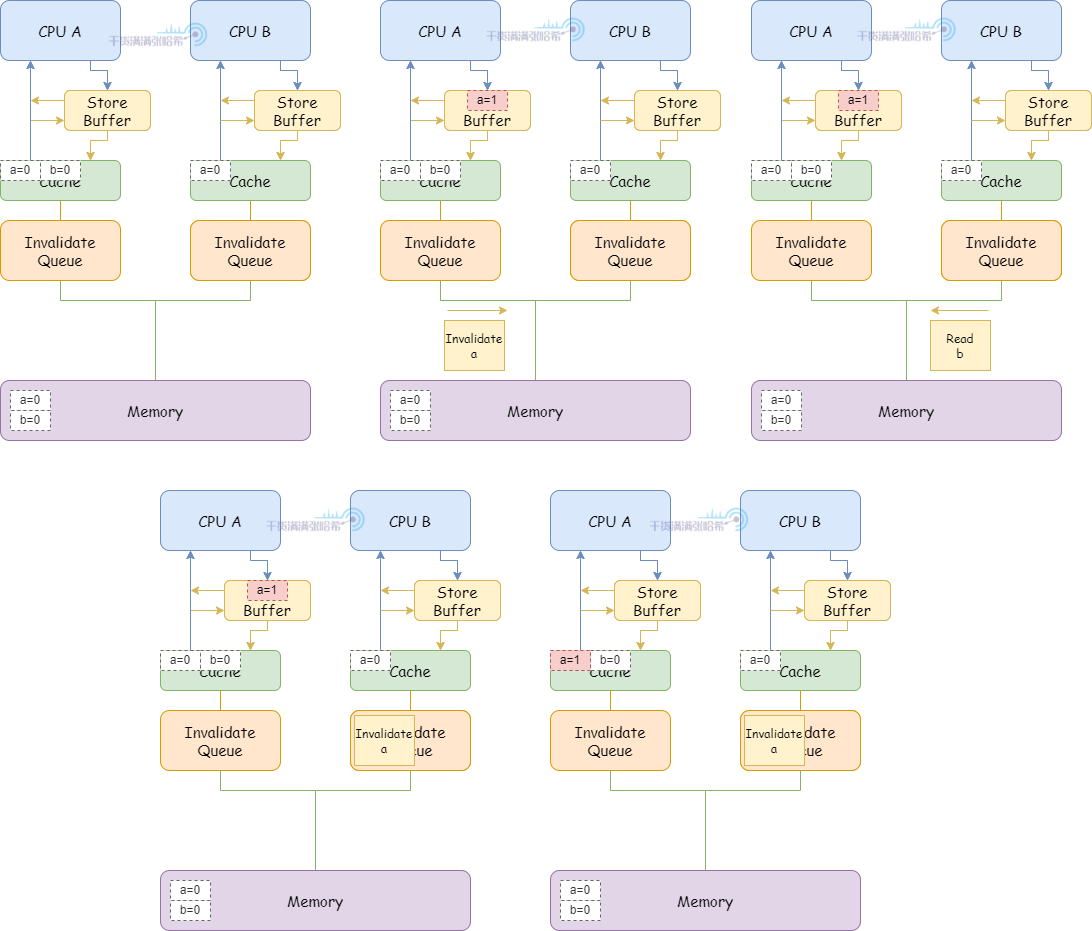
1.CPU A 執行 a = 1:
(1)CPU A 快取裡面有 a(shared),CPU A 將 a 的修改(a=1)放入 Store Buffer,發送 Invalidate 消息。
2.CPU B 執行 while (b == 0) continue:
(1)CPU B 快取裡面沒有 b,發布 Read 消息。
(2)CPU B 收到 CPU A 的 Invalidate 消息,放入 Invalidate Queue 之後立刻返回。
(3)CPU A 收到 Invalidate 消息的響應,將 Store Buffer 中的快取行刷入 CPU 快取
3.CPU A 執行 smp_mb():
(1)因為 CPU A 已經把 Store Buffer 中的快取行刷入 CPU 快取,所以這裡直接通過
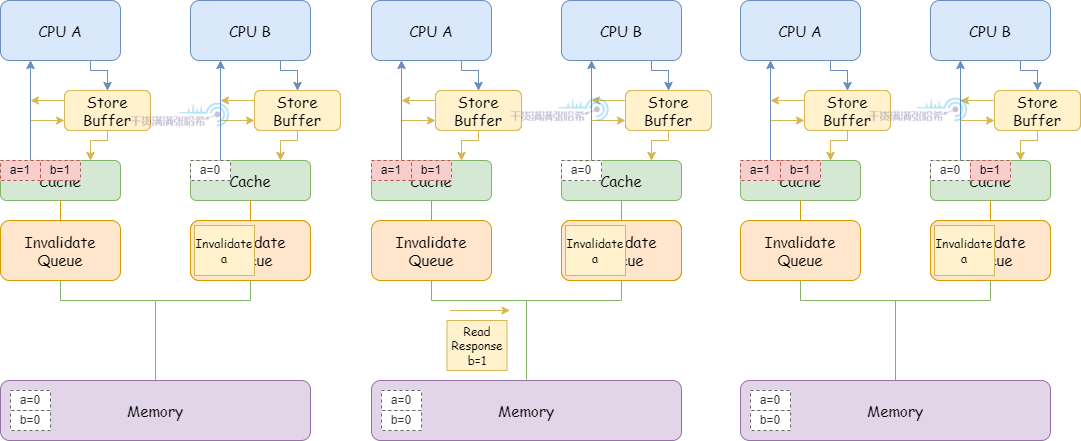
4.CPU A 執行 b = 1:
(1)因為 CPU A 本身包含 b 的快取行 (Exclusive),直接更新快取行即可。
(2)CPU A 收到 CPU B 之前發的 Read 消息,將 b 的快取行狀態更新為 Shared,之後發送 Read Response 包含 b 的最新值
(3)CPU B 收到 Read Response, b 的值為 1
5.CPU B 退出循環,開始執行 assert(a == 1)
(1)由於目前關於 a 的 Invalidate 消息還在 Invalidate queue 中沒有處理,所以 CPU B 看到的還是 a = 0,assert 失敗
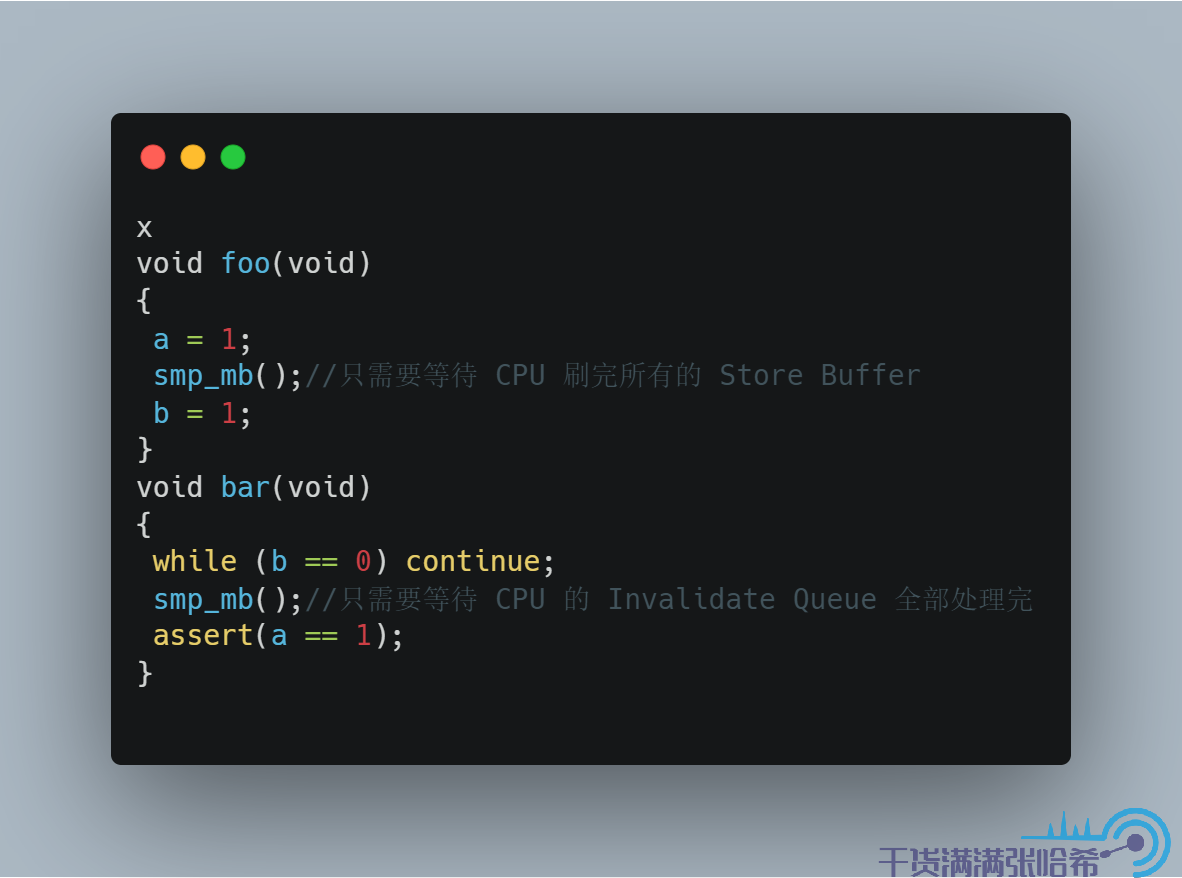
所以,我們針對這種亂序,在 CPU B 執行的程式碼中也加入記憶體屏障,這裡記憶體屏障不僅等待 CPU 刷完所有的 Store Buffer,還要等待 CPU 的 Invalidate Queue 全部處理完。加入記憶體屏障,CPU B 執行的程式碼是:

這樣,在前面的第 5 步,CPU B 退出循環,執行 assert(a == 1) 之前需要等待 Invalidate queue 處理完:
(1)處理 Invalidate 消息,將 b 置為 Invalid
(2)繼續程式碼,執行 assert(a == 1),這時候快取內不存在 b,需要發 Read 消息,這樣就能看到 b 的最新值 1 了,assert 成功。
5.2.7. 簡易 CPU 模型 – 更細粒度的記憶體屏障
我們前面提到,在我們前面提到的 CPU 模型中,smp_mb() 這個記憶體屏障指令,做了兩件事:等待 CPU 刷完所有的 Store Buffer,等待 CPU 的 Invalidate Queue 全部處理完。但是,對於我們這裡 CPU A 與 CPU B 執行的程式碼中的記憶體屏障,並不是每次都要這兩個操作同時存在:
所以,一般 CPU 還會抽象出更細粒度的記憶體屏障指令,我們這裡管等待 CPU 刷完所有的 Store Buffer 的指令叫做寫記憶體屏障(Write Memory Buffer),等待 CPU 的 Invalidate Queue 全部處理完的指令叫做讀記憶體屏障(Read Memory Buffer)。
5.2.8. 簡易 CPU 模型 – 總結
我們這裡通過一個簡單的 CPU 架構出發,層層遞進,講述了一些簡易的 CPU 結構以及為何會需要記憶體屏障,可以總結為下面這個簡單思路流程圖:
- CPU 每次直接訪問記憶體太慢,會讓 CPU 一直處於 Stall 等待。為了減少 CPU Stall,加入了 CPU 快取。
- CPU 快取帶來了多 CPU 間的快取不一致性,所以通過 MESI 這種簡易的 CPU 快取一致性協議協調不同 CPU 之間的快取一致性
- 對於 MESI 協議中的一些機制進行優化,進一步減少 CPU Stall:
- 通過將更新放入 Store Buffer,讓更新發出的 Invalidate 消息不用 CPU Stall 等待 Invalidate Response。
- Store Buffer 帶來了指令(程式碼)亂序,需要記憶體屏障指令,強制當前 CPU Stall 等待刷完所有 Store Buffer 中的內容。這個記憶體屏障指令一般稱為寫屏障。
- 為了加快 Store Buffer 刷入快取,增加 Invalidate Queue,
5.3. CPU 指令亂序相關
CPU 指令的執行,也可能會亂序,我們這裡只說一種比較常見的 – 指令並行化。
5.3.1. 增加 CPU 執行效率 – CPU 流水線模式(CPU Pipeline)
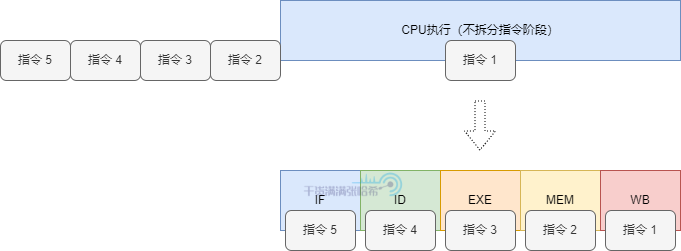
現代 CPU 在執行指令時,是以指令流水線的模式來運行的。因為 CPU 內部也有不同的組件,我們可以將執行一條指令分成不同階段,不同的階段涉及的組件不同,這樣偽解耦可以讓每個組件獨立的執行,不用等待一個指令完全執行完再處理下一個指令。
一般分為如下幾個階段:取指(Instrcution Fetch,IF)、解碼(Instruction Decode,ID)、執行(Execute,EXE)、存取(Memory,MEM)、寫回(Write-Back, WB)
5.3.2. 進一步降低 CPU Stall – CPU 亂序流水線(Out of order execution Pipeline)
由於指令的數據是否就緒也是不確定的,比如下面這個例子:

倘若數據 a 沒有就緒,還沒有載入到暫存器,那麼我們其實沒必要 Stall 等待載入 a,可以先執行 c = 1; 由此,我們可以將程式中,可以並行的指令提取出來同時安排執行,CPU 亂序流水線(Out of order execution Pipeline)就是基於這種思路:
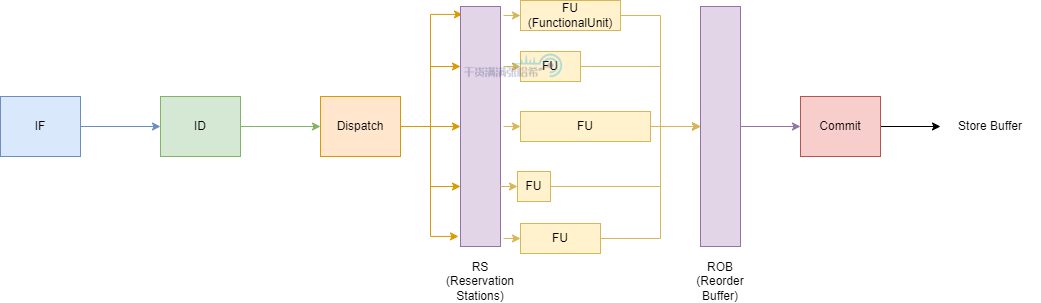
如圖所示,CPU 的執行階段分為:
- Instructions Fetch:批量拉取一批指令,進行指令分析,分析其中的循環以及依賴,分支預測等等
- Instruction Decode:指令解碼,與前面的流水線模式大同小異
- Reservation stations:需要操作數輸入的指令,如果輸入就緒,就進入 Functoinal Unit (FU) 處理,如果沒有沒有就緒就監聽 Bypass network,數據就緒發回訊號到 Reservation stations,讓指令進圖 FU 處理。
- Functional Unit:處理指令
- Reorder Buffer:會將指令按照原有程式的順序保存,這些指令會在被 dispatched 後添加到列表的一端,而當他們完成執行後,從列表的另一端移除。通過這種方式,指令會按他們 dispatch 的順序完成。
這樣的結構設計下,可以保證寫入 Store Buffer 的順序,與原始的指令順序一樣。但是載入數據,以及計算,是並行執行的。前面我們已經知道了在我們的簡易 CPU 架構裡面,有著多 CPU 快取 MESI, Store Buffer 以及 Invalidate Queue 導致讀取不到最新的值,這裡的亂序並行載入以及處理更加劇了這一點。並且,結構設計下,僅能保證檢測出同一個執行緒下的指令之間的互相依賴,保證這樣的互相依賴之間的指令執行順序是對的,但是多執行緒程式之間的指令依賴,CPU 批量取指令以及分支預測是無法感知的。所以還是會有亂序。這種亂序,同樣可以通過前面的記憶體屏障避免。
5.4. 實際的 CPU
實際的 CPU 多種多樣,有著不同的 CPU 結構設計以及不同的 CPU 快取一致性協議,就會有不同種類的亂序,如果每種單獨來看,就太複雜了。所以,大家通過一種標準來抽象描述不同的 CPU 的亂序現象(即第一個操作為 M,第二個操作為 N,這兩個操作是否會亂序,是不是很像 Doug Lea 對於 JMM 的描述,其實 Java 記憶體模型也是參考這個設計的),參考下面這個表格:
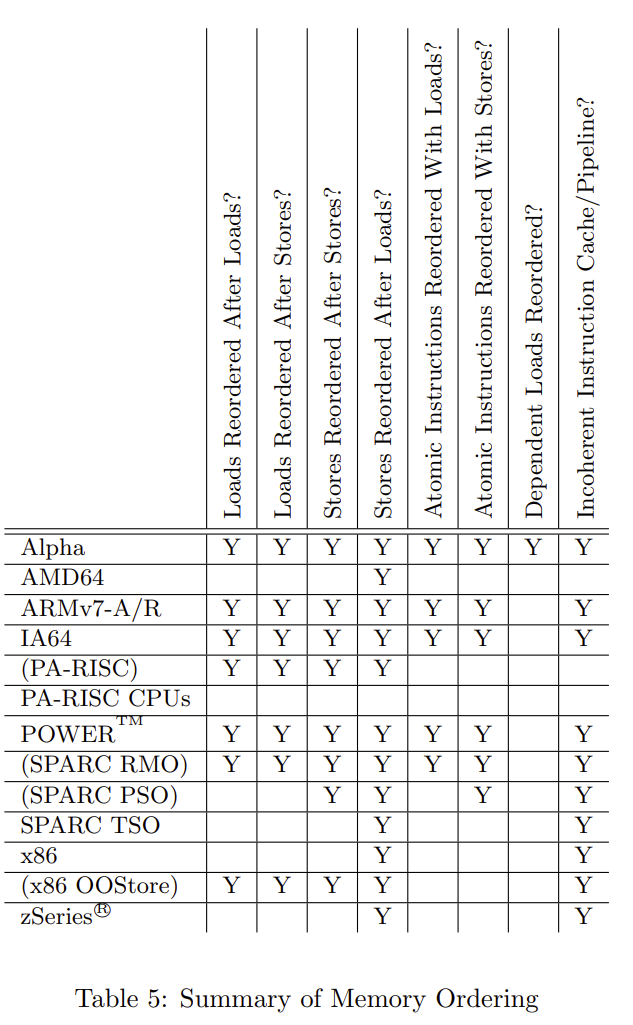
我們先來說一下每一列的意思:
- Loads Reordered After Loads:第一個操作是讀取,第二個也是讀取,是否會亂序。
- Loads Reordered After Stores:第一個操作是讀取,第二個是寫入,是否會亂序。
- Stores Reordered After Stores:第一個操作是寫入,第二個也是寫入,是否會亂序。
- Stores Reordered After Loads:第一個操作是寫入,第二個是讀取,是否會亂序。
- Atomic Instructions Reordered With Loads:兩個操作是原子操作(一組操作,同時發生,例如同時修改兩個字這種指令)與讀取,這兩個互相是否會亂序。
- Atomic Instructions Reordered With Stores:兩個操作是原子操作(一組操作,同時發生,例如同時修改兩個字這種指令)與寫入,這兩個互相是否會亂序。
- Dependent Loads Reordered:如果一個讀取依賴另一個讀取的結果,是否會亂序。
- Incoherent Instruction Cache/Pipeline:是否會有指令亂序執行。
舉一個例子來看即我們自己的 PC 上面常用的 x86 結構,在這種結構下,僅僅會發生 Stores Reordered After Loads 以及 Incoherent Instruction Cache/Pipeline。其實後面要提到的 LoadLoad,LoadStore,StoreLoad,StoreStore 這四個 Java 中的記憶體屏障,為啥在 x86 的環境下其實只需要實現 StoreLoad,其實就是這個原因。
5.5. 編譯器亂序
除了 CPU 亂序以外,在軟體層面還有編譯器優化重排序導致的,其實編譯器優化的一些思路與上面說的 CPU 的指令流水線優化其實有些類似。比如編譯器也會分析你的程式碼,對相互不依賴的語句進行優化。對於相互沒有依賴的語句,就可以隨意的進行重排了。但是同樣的,編譯器也是只能從單執行緒的角度去考慮以及分析,並不知道你程式在多執行緒環境下的依賴以及聯繫。再舉一個簡單的例子,假設沒有任何 CPU 亂序的環境下,有兩個變數 x = 0,y = 0,執行緒 1 執行:

執行緒 2 執行:

那麼執行緒 2 是可能 assert 失敗的,因為編譯器可能會讓 x = 1 與 y = 1 之間亂序。
編譯器亂序,可以通過增加不同作業系統上的編譯器屏障語句進行避免。例如執行緒一執行:

這樣就不會出現 x = 1 與 y = 1 之間亂序的情況。
同時,我們在實際使用的時候,一般記憶體屏障指的是硬體記憶體屏障,即通過硬體 CPU 指令實現的記憶體屏障,這種硬體記憶體屏障一般也會隱式地帶上編譯器屏障。編譯器屏障一般被稱為軟體記憶體屏障,僅僅是控制編譯器軟體層面的屏障,舉一個例子即 C++ 中的 volaile,它與 Java 中的 volatile 不一樣, C++ 中的 volatile 僅僅是禁止編譯器重排即有編譯器屏障,但是無法避免 CPU 亂序。
以上,我們就基本搞清楚了亂序的來源,以及記憶體屏障的作用。接下來,我們即將步入正題,開始我們的 Java 9+ 記憶體模型之旅。在這之前,再說一件需要注意的事情:為什麼最好不要自己寫程式碼驗證 JMM 的一些結論,而是使用專業的框架去測試
6. 為什麼最好不要自己寫程式碼驗證 JMM 的一些結論
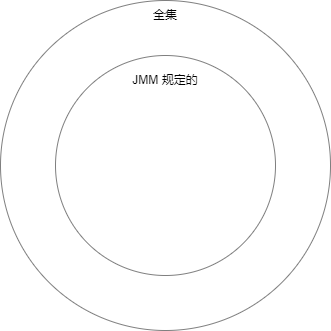
通過前面的一系列分析我們知道,程式亂序的問題錯綜複雜,假設一段程式碼,沒有任何限制所有可能的輸出結果是如下圖所示這個全集:

在 Java 記憶體模型的限制下,可能的結果被限制到了所有亂序結果中的一個子集:
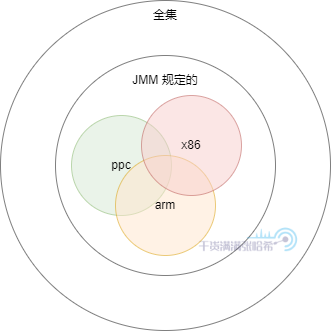
在 Java 記憶體模型的限制下,在不同的 CPU 架構上,CPU 亂序情況不同,有的場景有的 CPU 會亂序,有的則不會,但是都在 JMM 的範圍內所以是合理的,這樣所有可能的結果集又被限制到 JMM 的一個個不同子集:
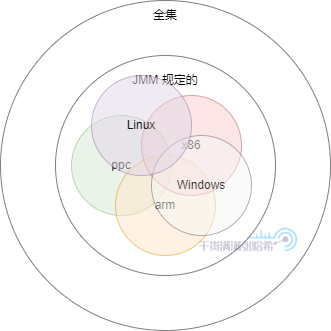
在 Java 記憶體模型的限制下,在不同的作業系統的編譯器編譯出來的 JVM 的程式碼執行順序不同,底層系統調用定義不同,在不同作業系統執行的 Java 程式碼又有可能會有些微小的差異,但是由於都在 JMM 的限制範圍內,所以也是合理的:
最後呢,在不同的執行方式以及 JIT 編譯下,底層執行的程式碼還是有差異的,進一步導致了結果集的分化:
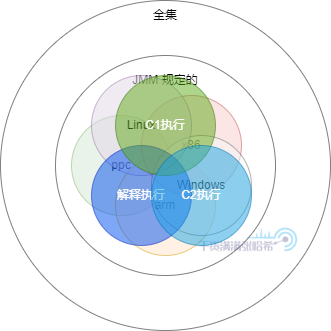
所以,如果你自己編寫程式碼在自己的唯一一台電腦唯一一種作業系統上面去試,那麼你所能試出來的結果集只是 JMM 的一個子集,很可能有些亂序結果你是看不到的。並且,有些亂序執行次數少或者沒走到 JIT 優化,還看不到,所以,真的不建議你自己寫程式碼去實驗。
那麼應該怎麼做呢?使用較為官方的用來測試並發可見性的框架 – jcstress,這個框架雖然不能模擬不同的 CPU 架構和不同作業系統,但是能讓你排除不同執行(解釋執行,C1執行,C2執行)以及測試壓力不足次數少的原因,後面的所有講解都會附上對應的 jcstress 程式碼實例供大家使用。
7. 層層遞進可見性與 Java 9+ 記憶體模型的對應 API
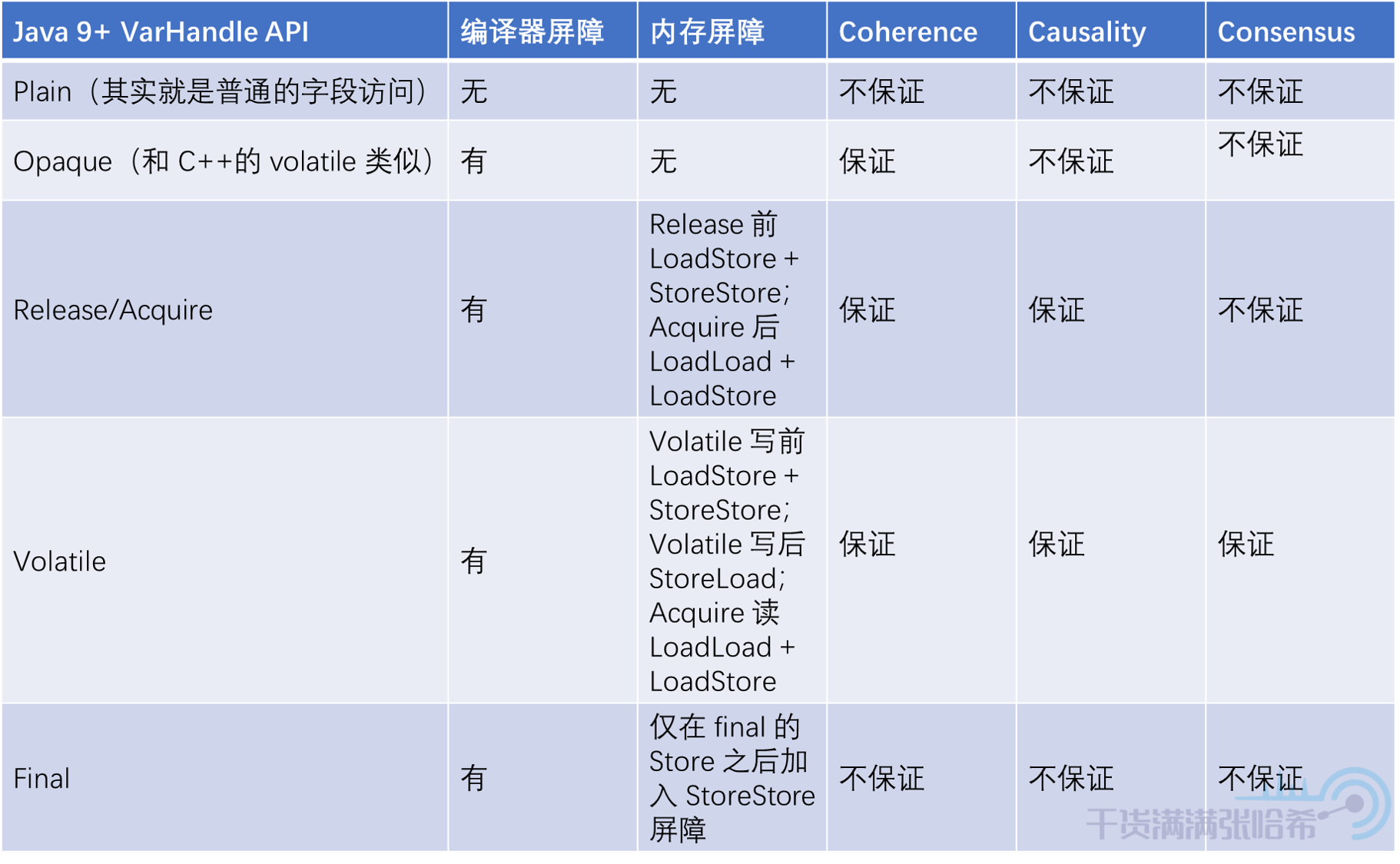
這裡主要參考了 Aleksey 大神的思路,去總結出不同層次,層層遞進的 Java 中的一些記憶體可見性限制性質以及對應的 API。Java 9+ 中,將原來的普通變數(非 volatile,final 變數)的普通訪問,定義為了 Plain。普通訪問,沒有對這個訪問的地址做任何屏障(不同 GC 的那些屏障,比如分代 GC 需要的指針屏障,不是這裡要考慮的,那些屏障只是 GC 層面的,對於這裡的可見性沒啥影響),會有前面提到的各種亂序。那麼 Java 9+ 記憶體模型中究竟提出了那些限制以及對應這些限制的 API 是啥,我們接下層層遞進講述。
7.1. Coherence(相干性,連貫性)與 Opaque

這裡的標題我不太清楚究竟應該翻譯成什麼,因為我看網上很多地方把 CPU Cache Coherence Protocol 翻譯成了 CPU 快取一致性協議,即 Coherence 在那種語境下代表一致性,但是我們這裡的 Coherence 如果翻譯成一致性就不太合適。所以,之後的一些名詞我也直接沿用 Doug Lea 大神的以及 Aleksey 大神的定義。
那麼這裡什麼是 coherence 呢?舉一個簡單的例子:假設某個對象欄位 int x 初始為 0,一個執行緒執行:

另一個執行緒執行(r1, r2 為本地變數):

那麼在 Java 記憶體模型下,可能的結果是包括:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
其中第三個結果很有意思,從程式上理解即我們先看到了 x = 1,之後又看到了 x 變成了 0.當然,通過前面的分析,我們知道實際上是因為編譯器亂序。如果我們不想看到這個第三種結果,我們所需要的特性即 coherence。
coherence 的定義,我引用下原文:
The writes to the single memory location appear to be in a total order consistent with program order.
即對單個記憶體位置的寫看上去是按照與程式順序一致的總順序進行的。看上去有點難以理解,結合上面的例子,可以這樣理解:在全局,x 由 0 變成了 1,那麼每個執行緒中看到的 x 只能從 0 變成 1,而不會可能看到從 1 變成 0.
正如前面所說,Java 記憶體模型定義中的 Plain 讀寫,是不能保證 coherence 的。但是如果大家跑一下針對上面的測試程式碼,會發現跑不出來第三種結果。這是因為 Hotspot 虛擬機中的語義分析會認為這兩個對於 x 的讀取(load)是互相依賴的,進而限制了這種亂序:
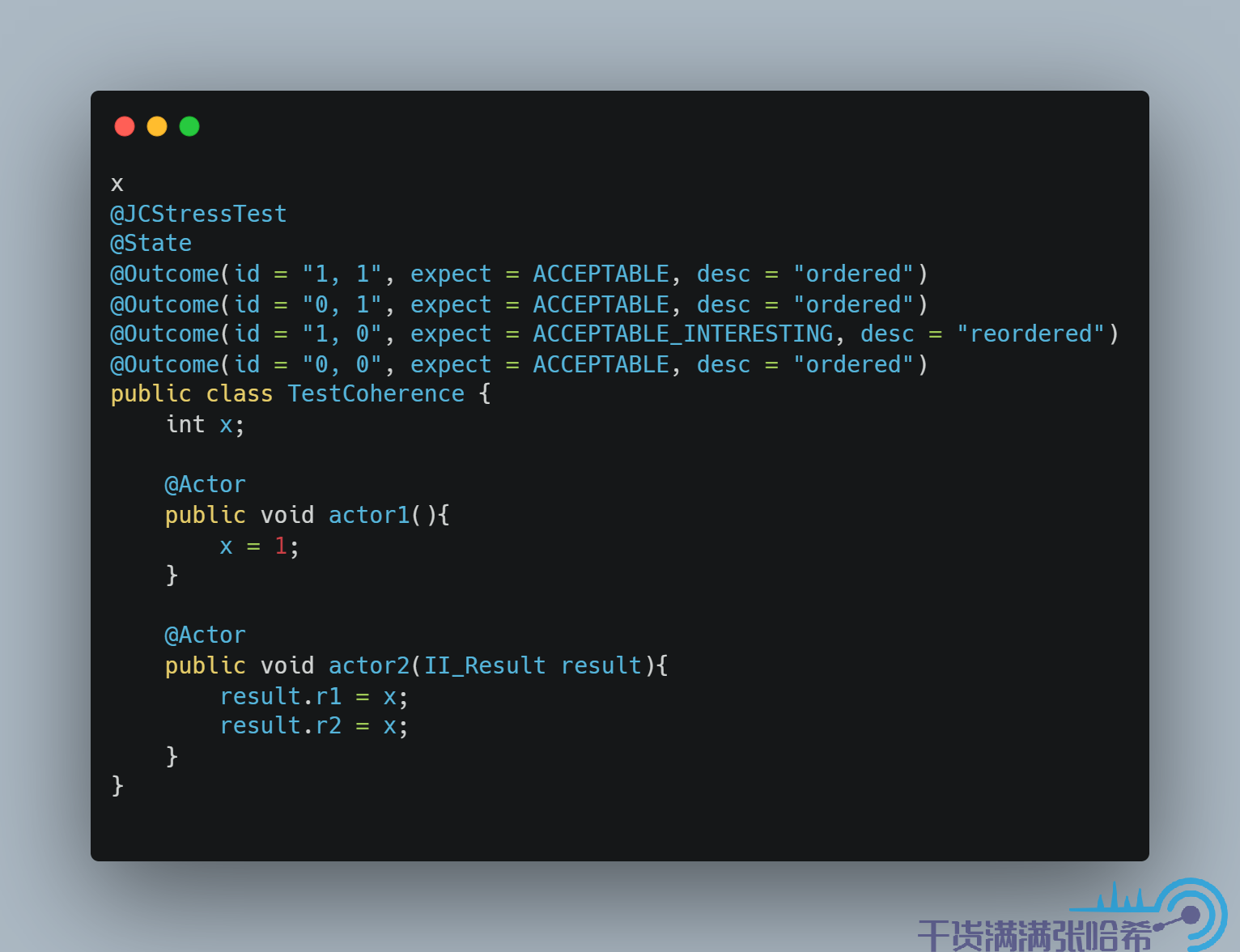
這就是我在前面一章中提到的,為什麼最好不要自己寫程式碼驗證 JMM 的一些結論。雖然在 Java 記憶體模型的限制中,是允許第三種結果 1, 0 的,但是這裡通過這個例子是試不出來的。
我們這裡通過一個彆扭的例子來騙過 Java 編譯器造成這種亂序:
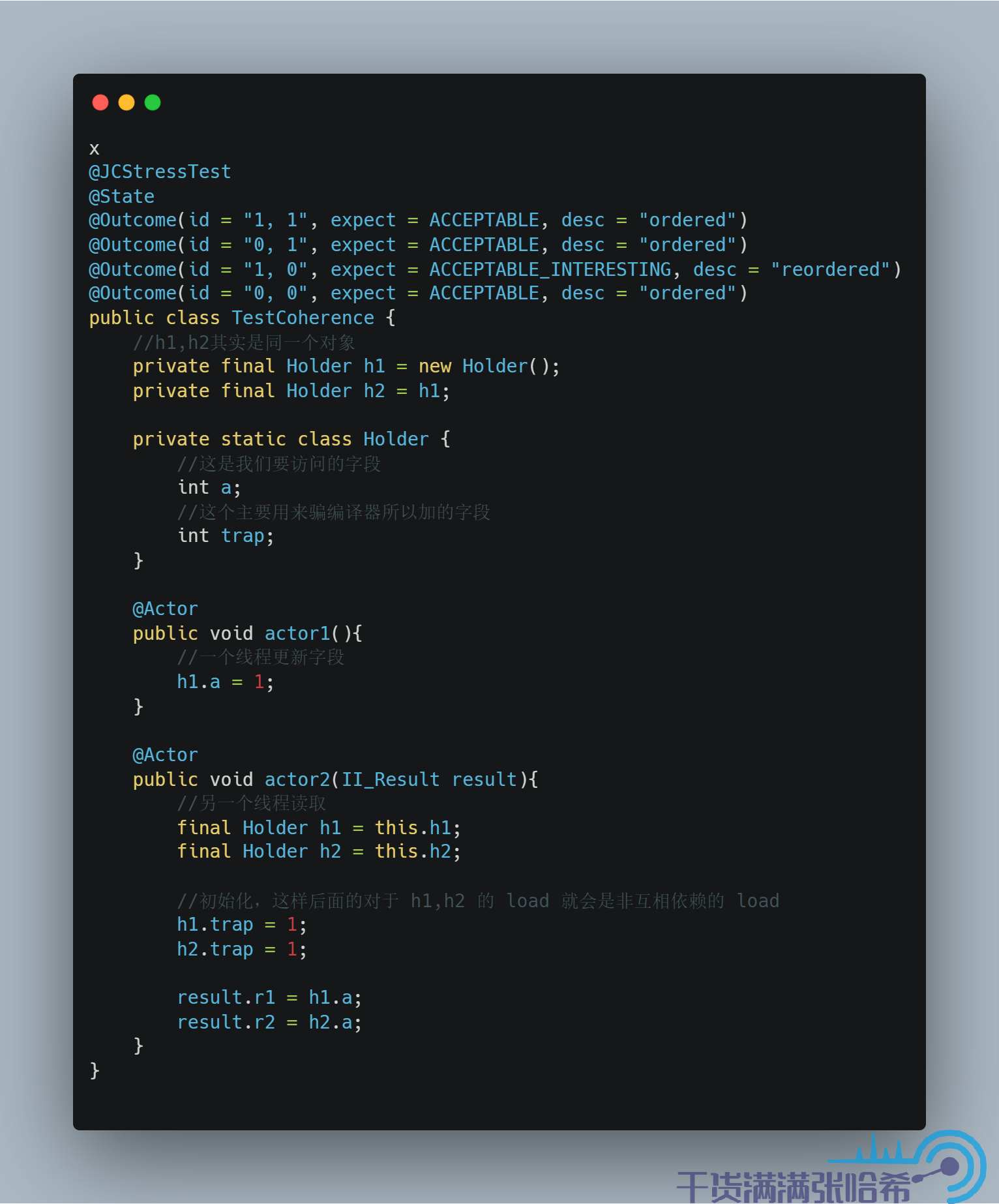
我們不用太深究其原理,直接看結果:
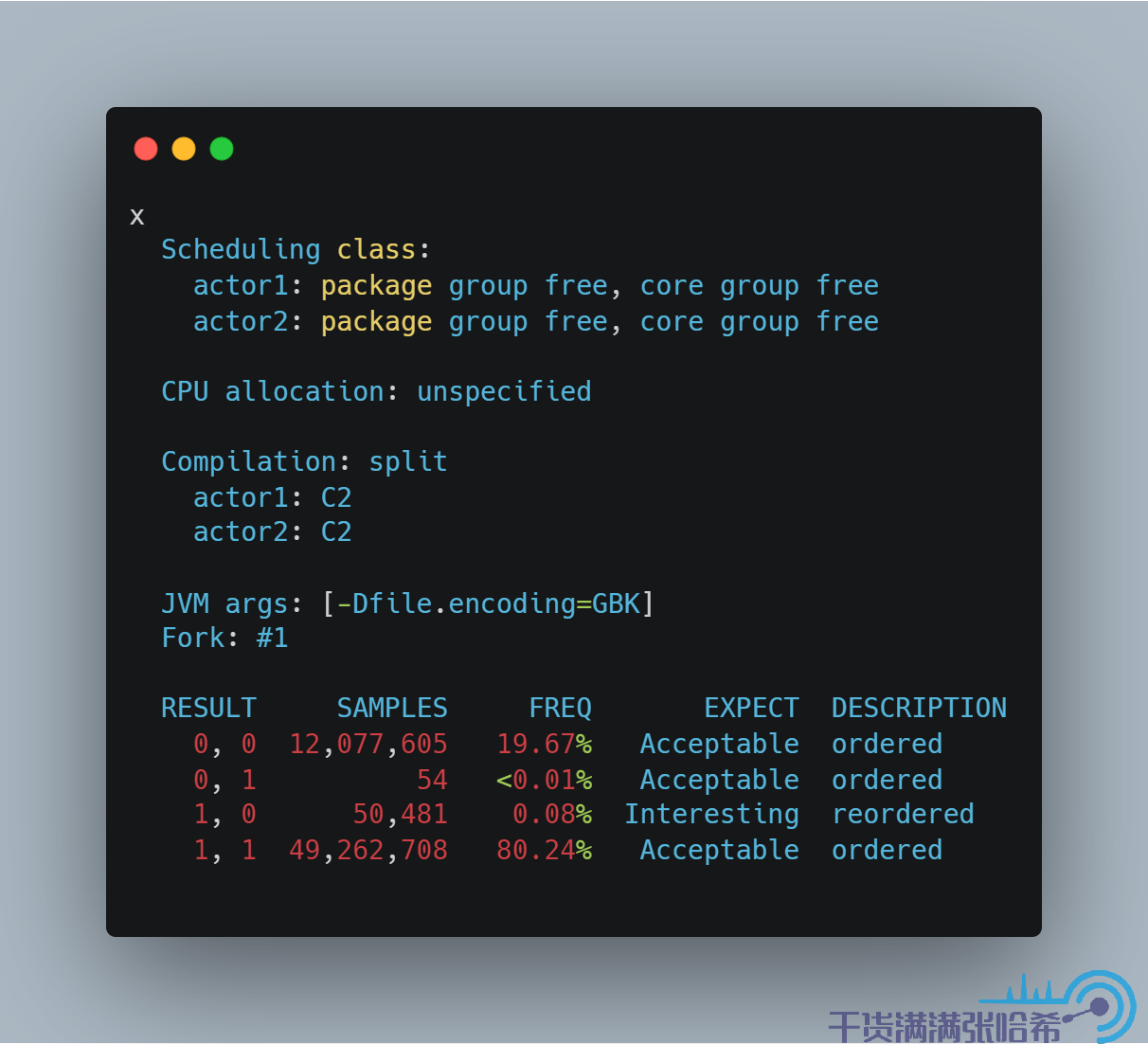
發現出現了亂序的結果,並且,如果你自己跑一下這個例子,會發現這個亂序是發生在執行 JIT C2 編譯後的 actor2 方法才會出現。
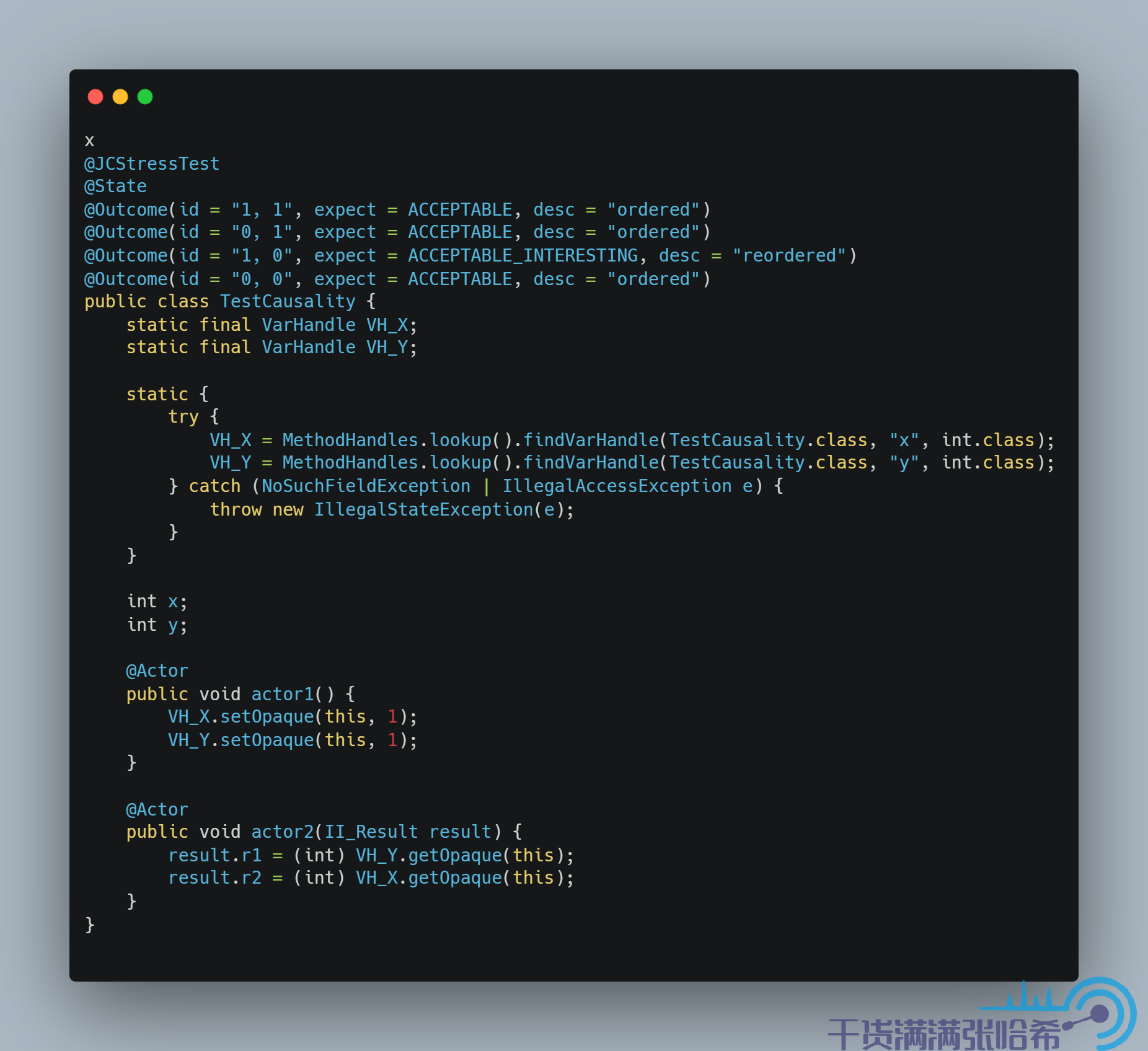
那麼如何避免這種亂序呢?使用 volatile 肯定是可以避免的,但是這裡我們並不用勞煩 volatile 這種重操作出馬,就用 Opaque 訪問即可。Opaque 其實就是禁止 Java 編譯器優化,但是沒有涉及任何的記憶體屏障,和 C++ 中的 volatile 非常類似。測試下:
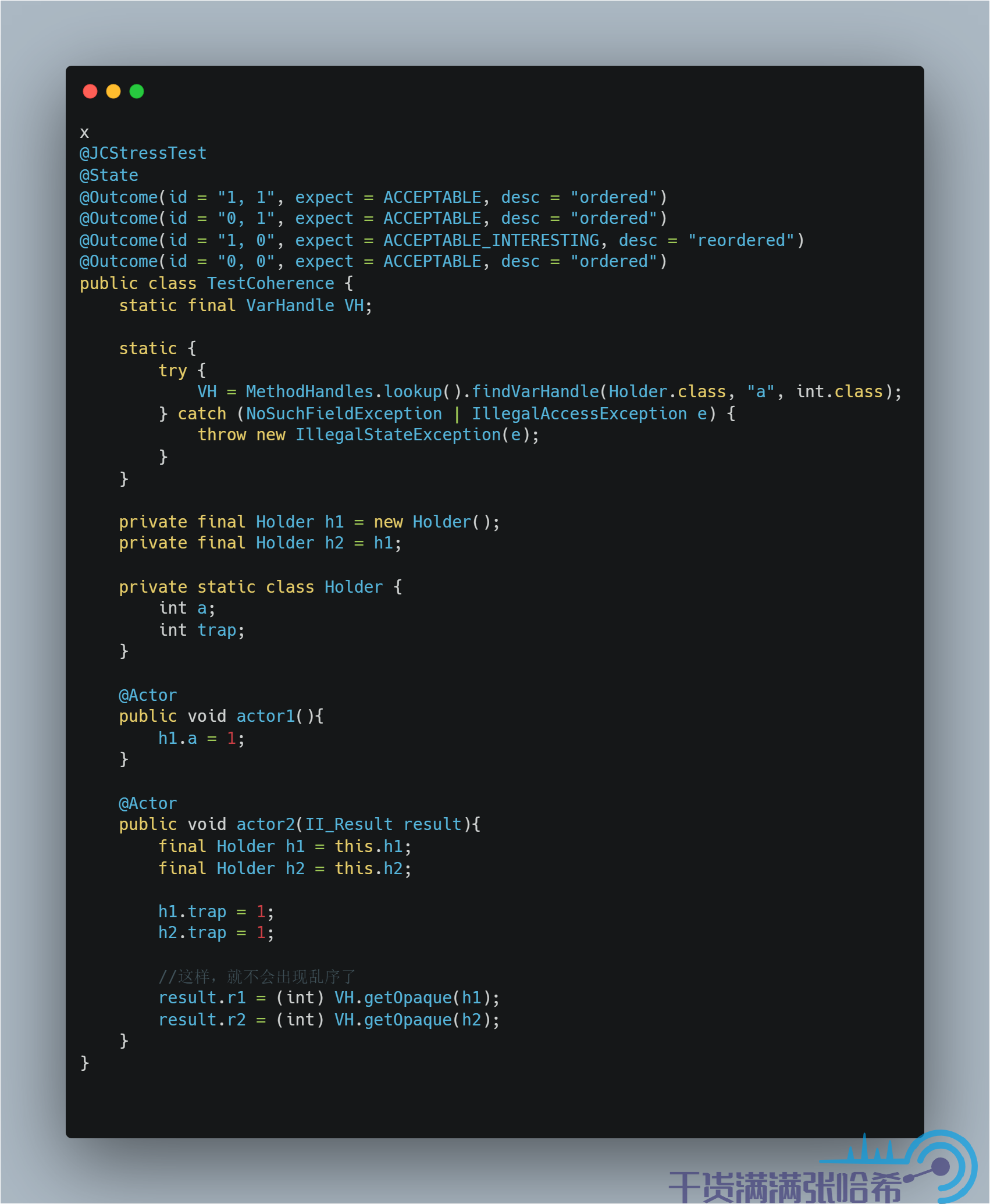
運行下,可以發現,這個就沒有亂序了(命令行如果沒有 ACCEPTABLE_INTERESTING,FORBIDDEN,UNKNOWN 的 結果就不會輸出了,只能最後看輸出的 html):
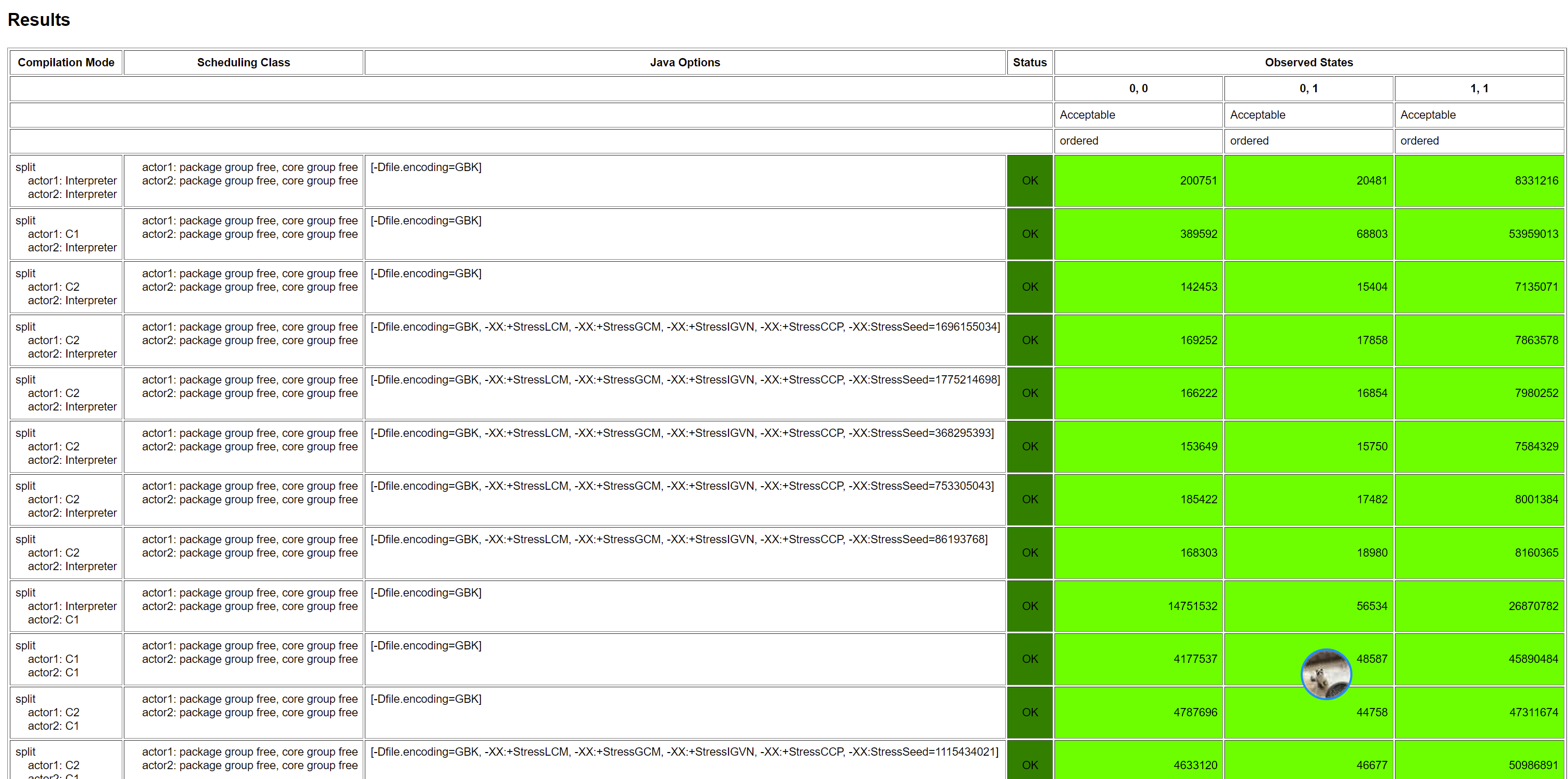
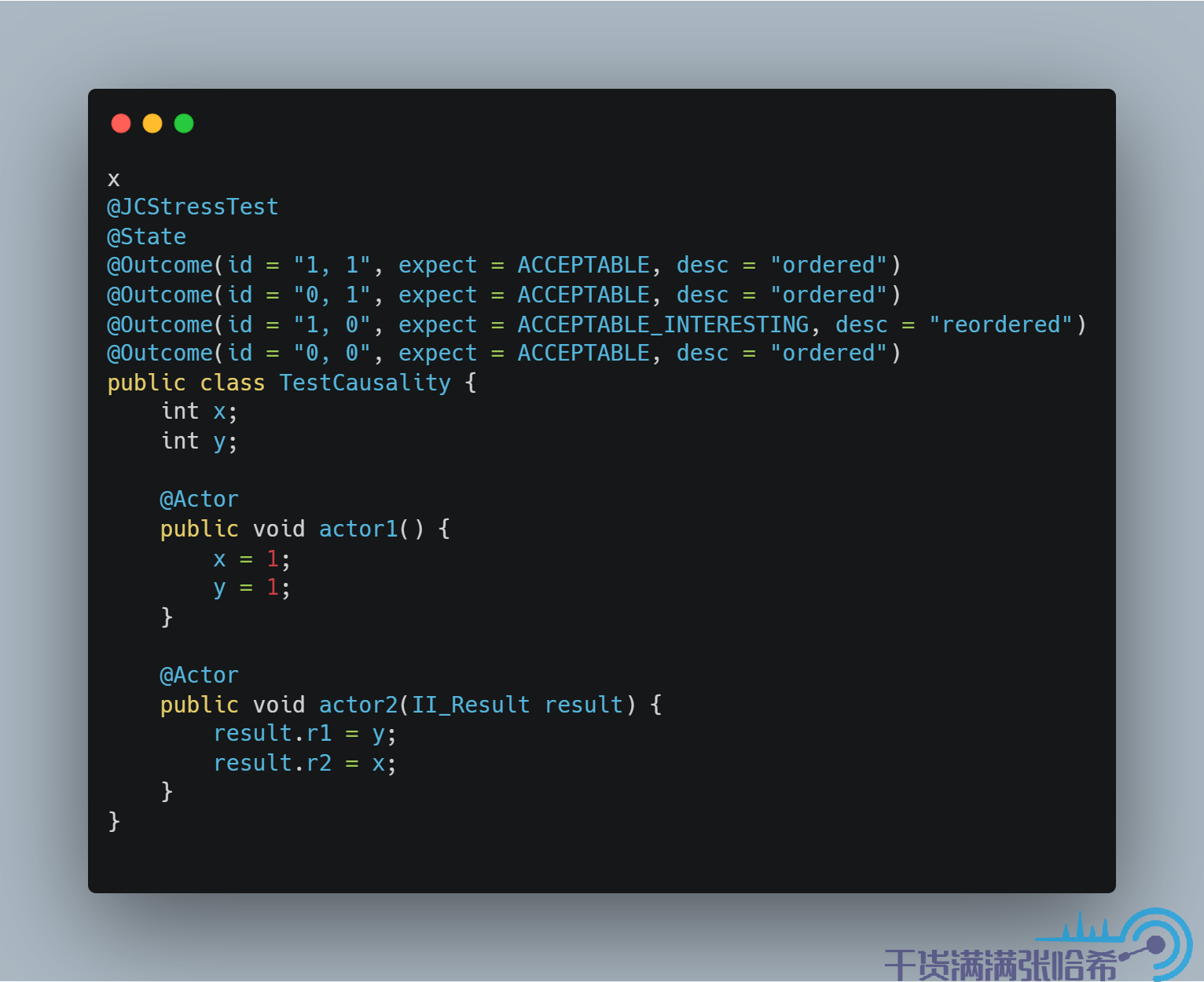
7.2. Causality(因果性)與 Acquire/Release
在 Coherence 的基礎上,我們一般在某些場景還會需要 Causality
一般到這裡,大家會接觸到兩個很常見的詞,即 happens-before 以及 synchronized-with order,我們這裡先不從這兩個比較晦澀的概念開始介紹(具體概念介紹不會在這一章節解釋),而是通過一個例子,即假設某個對象欄位 int x 初始為 0,int y 也初始為 0,這兩個欄位不在同一個快取行中(後面的 jcstress 框架會自動幫我們進行快取行填充),一個執行緒執行:

另一個執行緒執行(r1, r2 為本地變數):

這個例子與我們前面的 CPU 快取那裡的亂序分析舉得例子很像,在 Java 記憶體模型中,可能的結果有:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
同樣的,第三個結果也是很有趣的,第二個執行緒先看到 y 更新,但是沒有看到 x 的更新。這個在前面的 CPU 快取亂序那裡我們詳細分析,在前面的分析中,我們需要像這樣加記憶體屏障才能避免第三種情況的出現,即:

以及

簡單回顧下,執行緒 1 執行 x = 1 之後,在 y = 1 之前執行了寫屏障,保證 store buffer 的更新都更新到了快取,y = 1 之前的更新都保證了不會因為存在 store buffer 中導致不可見。執行緒 2 執行 int r1 = y 之後執行了讀屏障,保證 invalidate queue 中的需要失效的數據全部被失效,保證當前快取中不會有臟數據。這樣,如果執行緒 2 看到了 y 的更新,就一定能看到 x 的更新。
我們進一步更形象的描述一下:我們把寫屏障以及後面的一個 Store(即 y = 1)理解為將前面的更新打包,然後將這個包在這點發射出去,讀屏障與前面一個 Load(即 int r1 = y)理解成一個接收點,如果接收到發出的包,就在這裡將包打開並讀取進來。所以,如下圖所示:
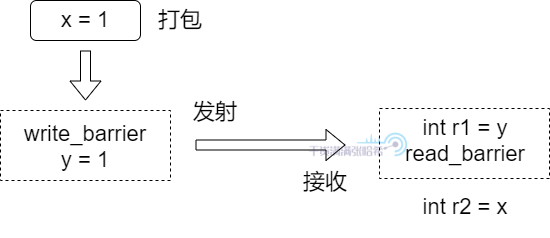
在發射點,會將發射點之前(包括發射點本身的資訊)的所有結果打包,如果在執行接收點的程式碼的時候接收到了這個包,那麼在這個接收點之後的所有指令就能看到包裡面的所有內容,即發射點之前以及發射點的內容。Causality(因果性),有的地方也叫做 Casual Consistency(因果一致性),它在不同的語境下有不同的含義,我們這裡僅特指:可以定義一系列寫入操作,如果讀取看到了最後一個寫入,那麼這個讀取之後的所有讀取操作,都能看到這個寫入以及之前的所有寫入操作。這是一種 Partial Order(半順序),而不是 Total Order(全順序),關於這個定義將在後面的章節詳細說明。
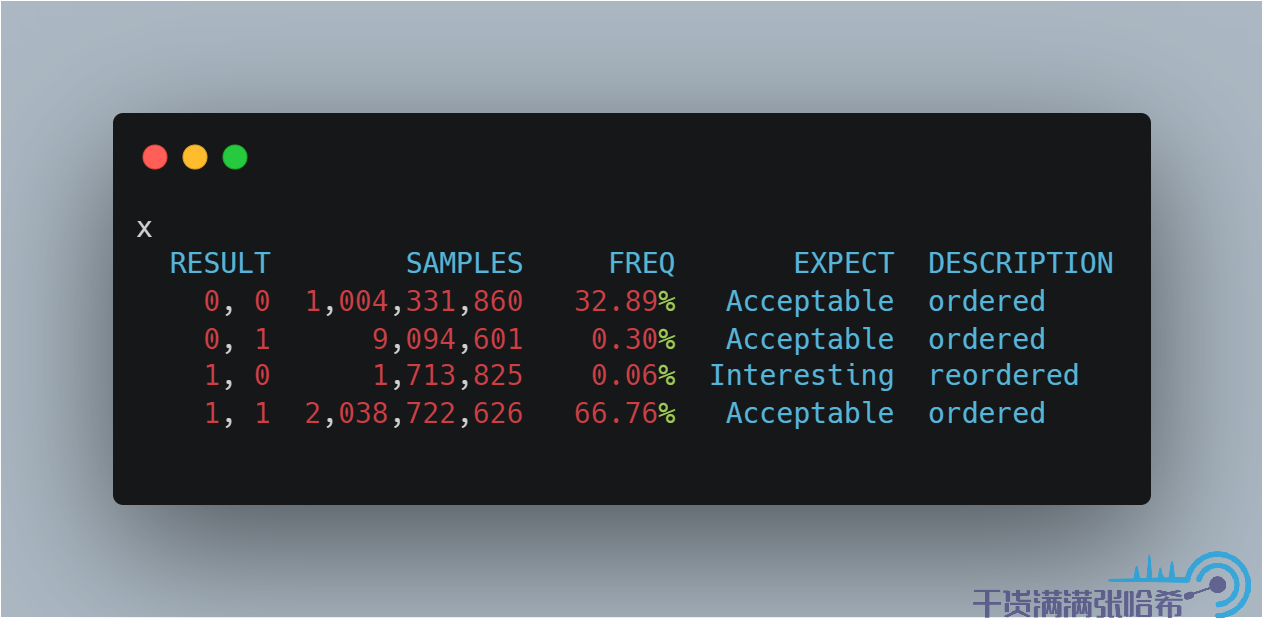
在 Java 中,Plain 訪問與 Opaque 訪問都不能保證 Causality,因為 Plain 沒有任何的記憶體屏障,Opaque 只是有編譯器屏障,我們可以通過如下程式碼測試出來:
首先是 Plain:
結果是:
然後是 Opaque:
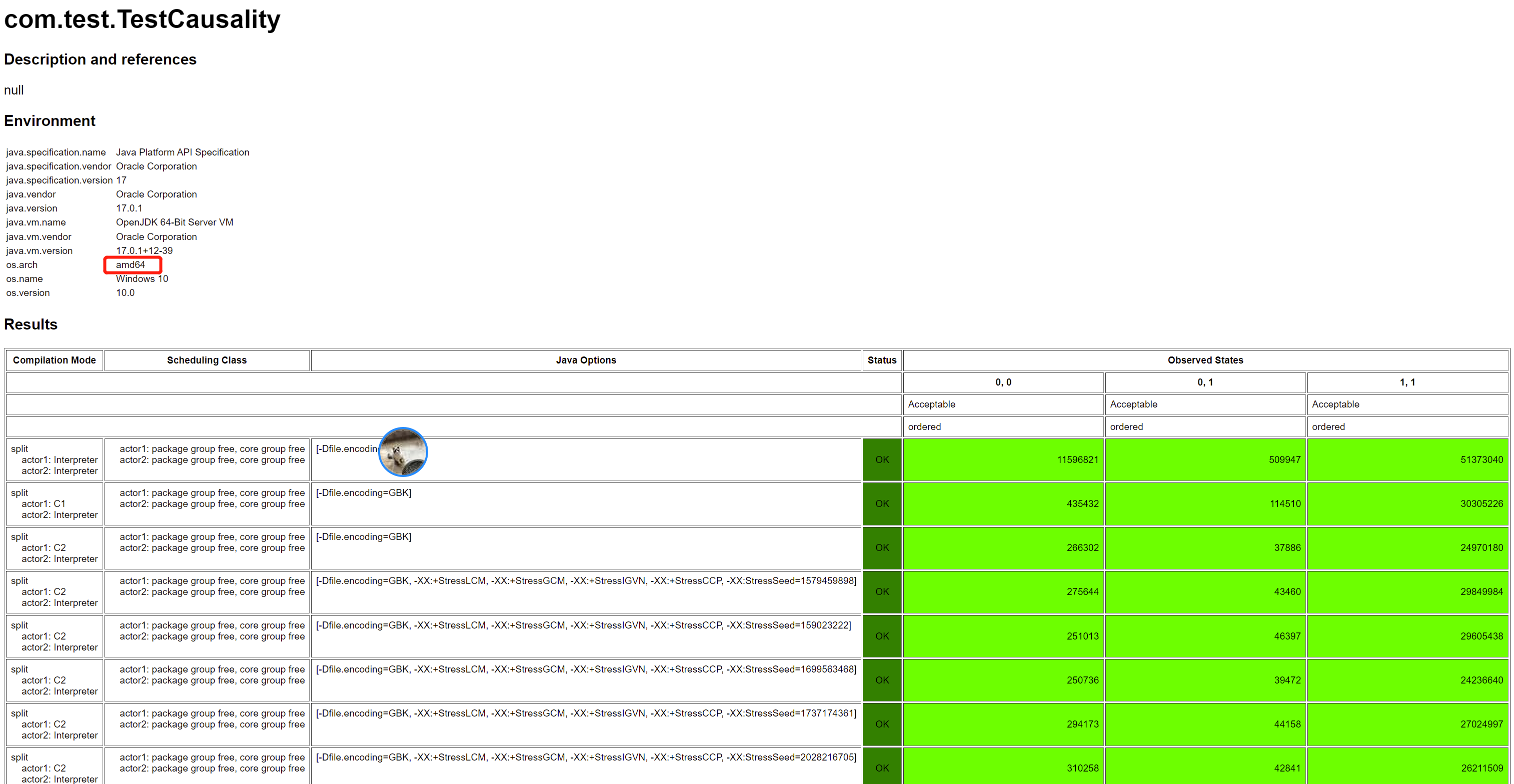
這裡我們需要注意:由於前面我們看到, x86 CPU 是天然保證一些指令不亂序的,稍後我們就能看到是哪些不亂序保證了這裡的 Causality,所以 x86 的 CPU 都看不到亂序,Opaque 訪問就能看到因果一致性的結果,如下圖所示(AMD64 是一種 x86 的實現):
但是,如果我們換成其他稍微弱一致一些的 CPU,就能看到 Opaque 訪問保證不了因果一致性,下面的結果是我在 aarch64 (是一種 arm 的實現):
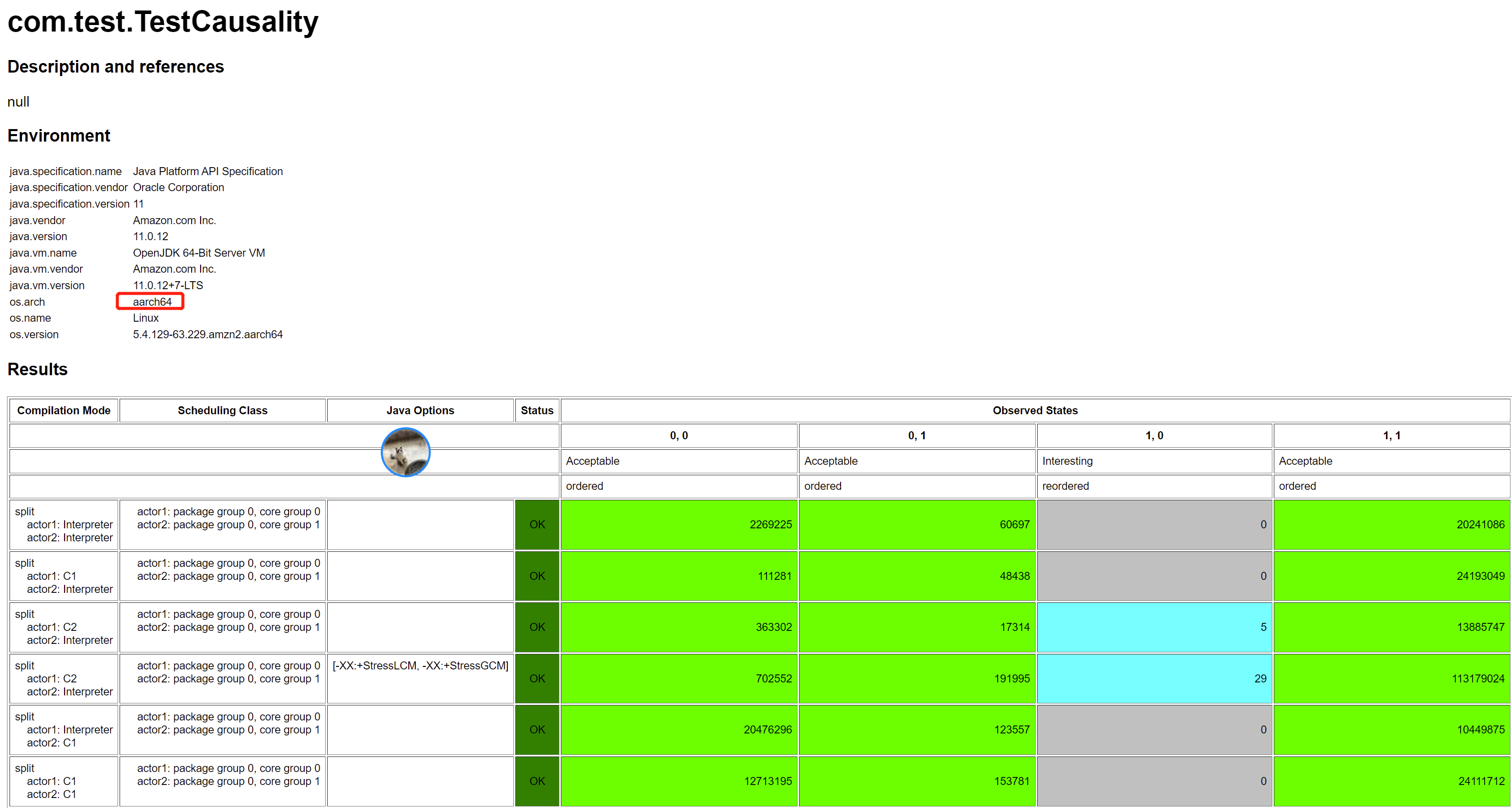
並且,還有一個比較有意思的點,即亂序都是 C2 編譯執行的時候發生的。
那麼,我們如何保證 Causality 呢?同樣的,我們同樣不必勞煩 volatile 這麼重的操作,採用 release/acquire 模式即可。release/acquire 可以保證 Coherence + Causality。release/acquire 必須成對出現(一個 acquire 對應一個 release),可以將 release 視為前面提到的發射點,acquire 視為前面提到的接收點,那麼我們就可以像下圖這樣實現程式碼:
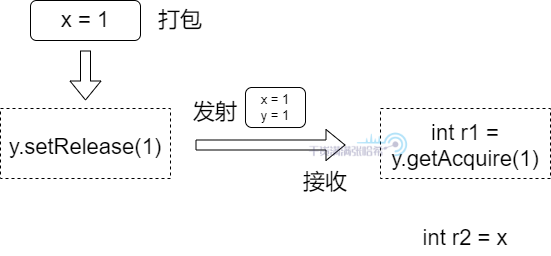
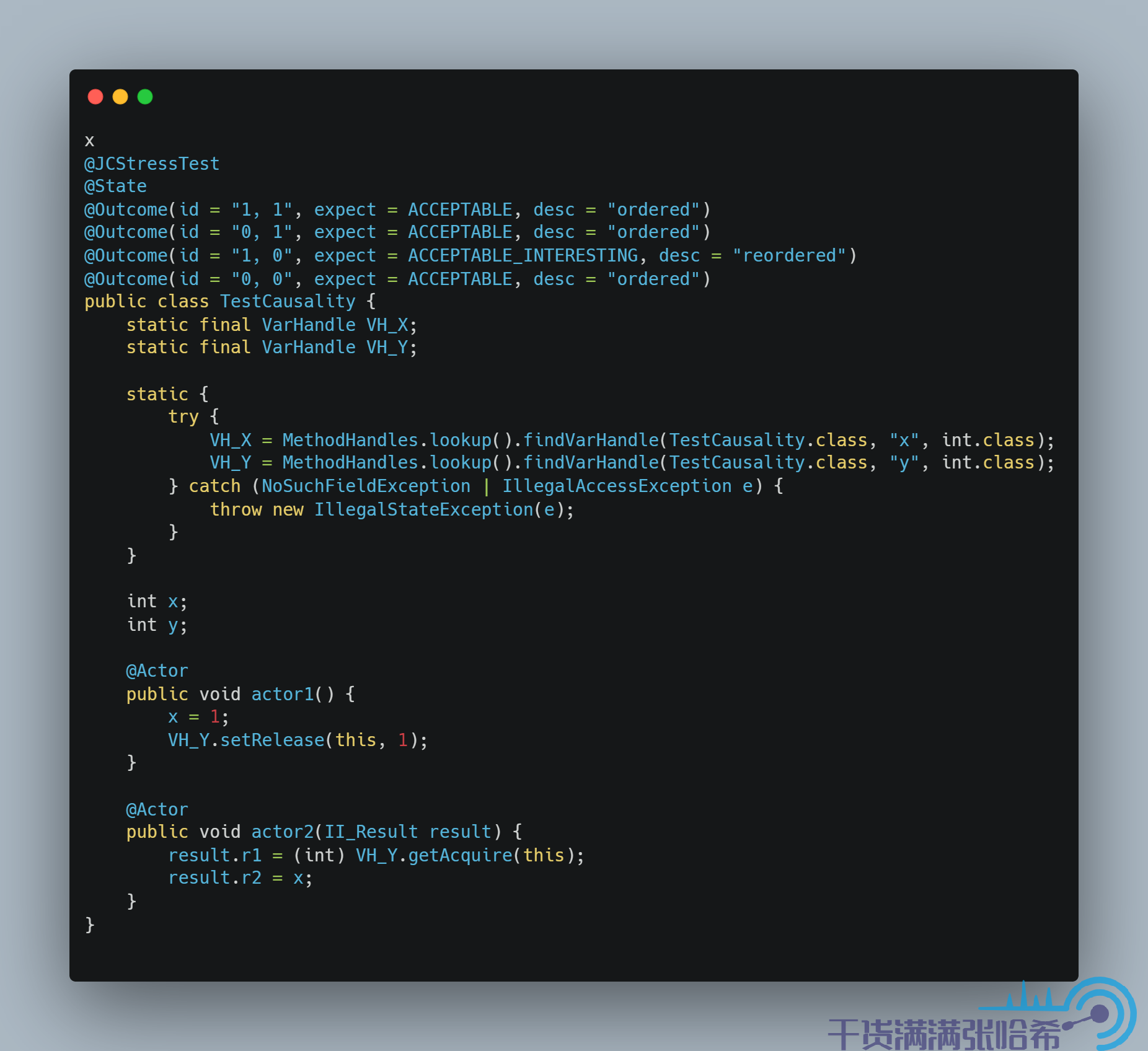
然後,繼續在剛剛的 aarch64 的機器上面執行,結果是:
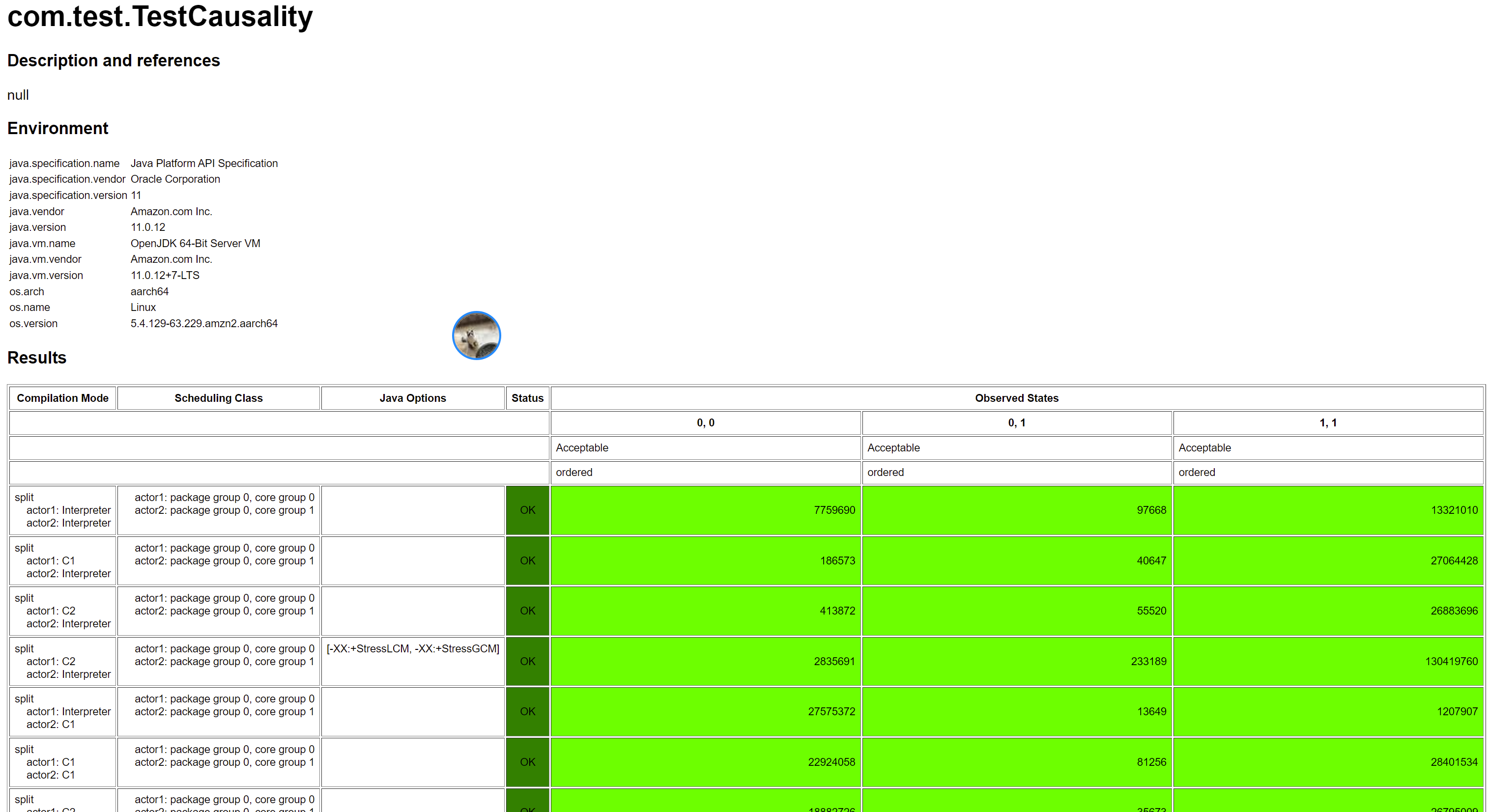
可以看出,Causuality 由於使用了 Release/Acquire 保證了 Causality。注意,對於發射點和接收點的選取一定要選好,例如這裡我們如果換個位置,那麼就不對了:
示例一:發射點只會打包之前的所有更新,對於 x = 1 的更新在發射點之後,相當於沒有打包進去,所以還是會出現 1,0 的結果。

示例二:在接收點會解包,從而讓後面的讀取看到包裡面的結果,對於 x 的讀取在接收點之前,相當於沒有看到包裡面的更新,所以還是會出現 1,0 的結果。

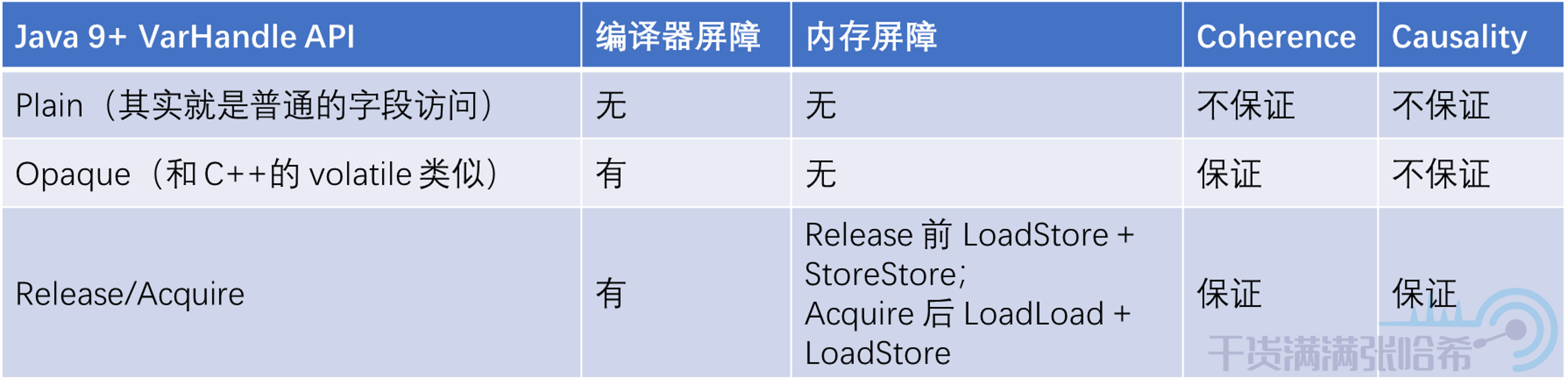
由此,我們類比下 Doug Lea 的 Java 記憶體屏障設計,來看看這裡究竟用了哪些 Java 中設計的記憶體屏障。在 Doug Lea 的很早也是很經典的一篇文章中,介紹了 Java 記憶體模型以及其中的記憶體屏障設計,提出了四種屏障:
1.LoadLoad
如果有兩個完全不相干的互不依賴(即可以亂序執行的)的讀取(Load),可以通過 LoadLoad 屏障避免它們的亂序執行(即在 Load(x) 執行之前不會執行 Load(y)):

2.LoadStore
如果有一個讀取(Load)以及一個完全不相干的(即可以亂序執行的)的寫入(Store),可以通過 LoadStore 屏障避免它們的亂序執行(即在 Load(x) 執行之前不會執行 Store(y)):

3.StoreStore
如果有兩個完全不相干的互不依賴(即可以亂序執行的)的寫入(Store),可以通過 StoreStore 屏障避免它們的亂序執行(即在 Store(x) 執行之前不會執行 Store(y)):

4.StoreLoad
如果有一個寫入(Store)以及一個完全不相干的(即可以亂序執行的)的讀取(Load),可以通過 LoadStore 屏障避免它們的亂序執行(即在 Store(x) 執行之前不會執行 Load(y)):

那麼如何通過這些記憶體屏障實現的 Release/Acquire 呢?我們可以通過前面我們的抽象推出來,首先是發射點。發射點首先是一個 Store,並且保證打包前面的所有,那麼不論是 Load 還是 Store 都要打包,都不能跑到後面去,所以需要在 Release 的前面加上 LoadStore,StoreStore 兩種記憶體屏障來實現。同理,接收點是一個 Load,並且保證後面的都能看到包裡面的值,那麼無論 Load 還是 Store 都不能跑到前面去,所以需要在 Acquire 的後面加上 LoadLoad,LoadStore 兩種記憶體屏障來實現。
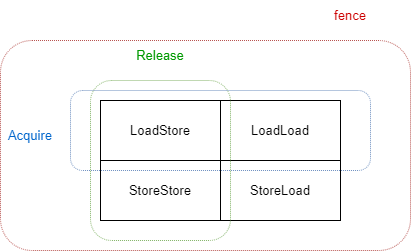
但是呢我們可以在下一章中看到,其實目前來看這四個記憶體屏障的設計有些過時了(由於 CPU 的發展以及 C++ 語言的發展) ,JVM 內部用的更多的是 acquire,release,fence 這三個。這裡的 acquire 以及 release 其實就是我們這裡提到的 Release/Acquire。這三個與傳統的四螢幕障的設計的關係是:
我們這裡知道了 Release/Acquire 的記憶體屏障,x86 為何沒有設置這個記憶體屏障就沒有這種亂序呢?參考前面的 CPU 亂序圖:
通過這裡我們知道,x86 對於 Store 與 Store,Load 與 Load,Load 與 Store 都不會亂序,所以天然就能保證 Casuality
7.3. Consensus(共識性)與 Volatile
最後終於來到我們所熟悉的 Volatile 了,Volatile 其實就是在 Release/Acquire 的基礎上,進一步保證了 Consensus;Consensus 即所有執行緒看到的記憶體更新順序是一致的,即所有執行緒看到的記憶體順序全局一致,舉個例子:假設某個對象欄位 int x 初始為 0,int y 也初始為 0,這兩個欄位不在同一個快取行中(後面的 jcstress 框架會自動幫我們進行快取行填充),一個執行緒執行:

另一個執行:

在 Java 記憶體模型下,同樣可能有4種結果:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
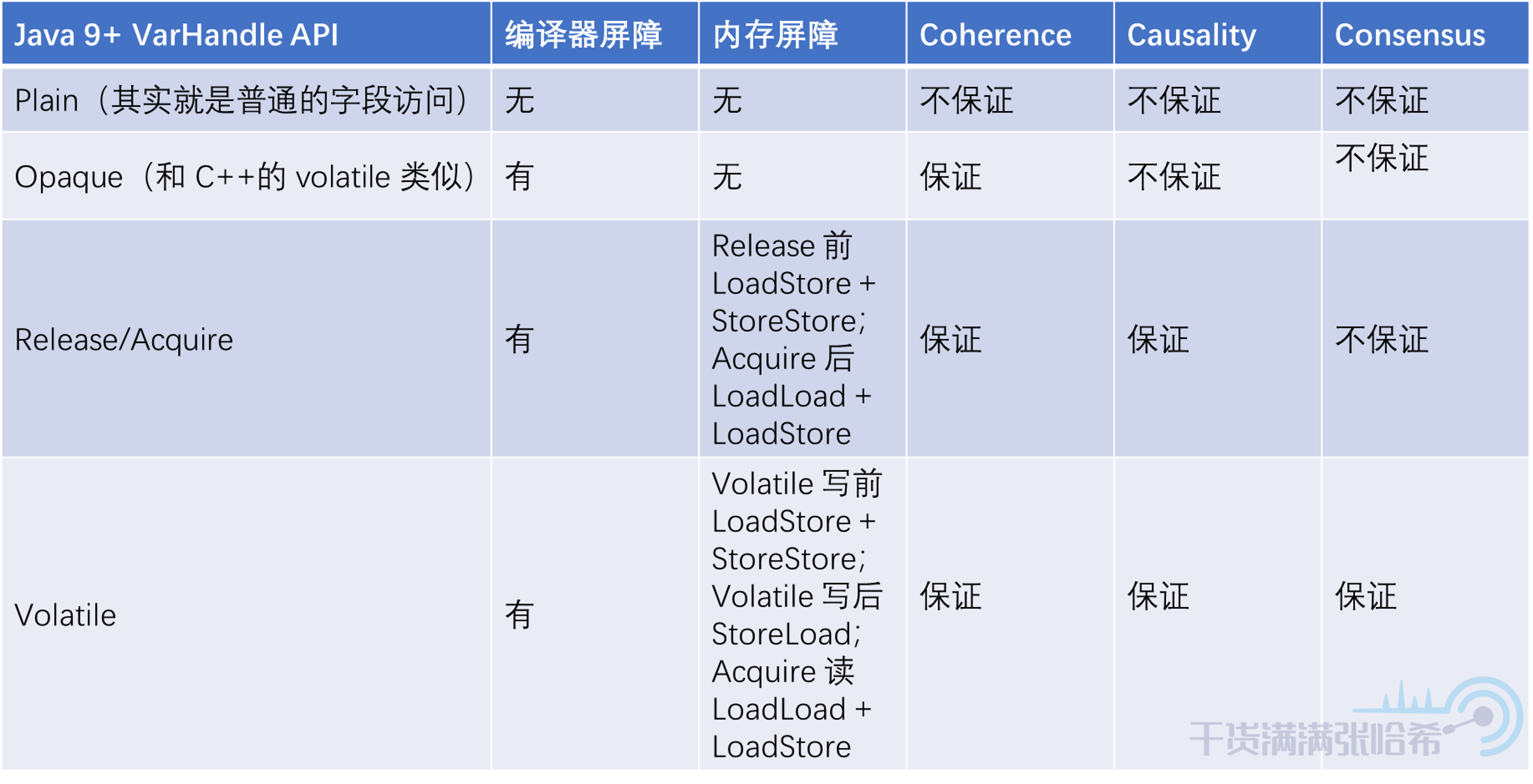
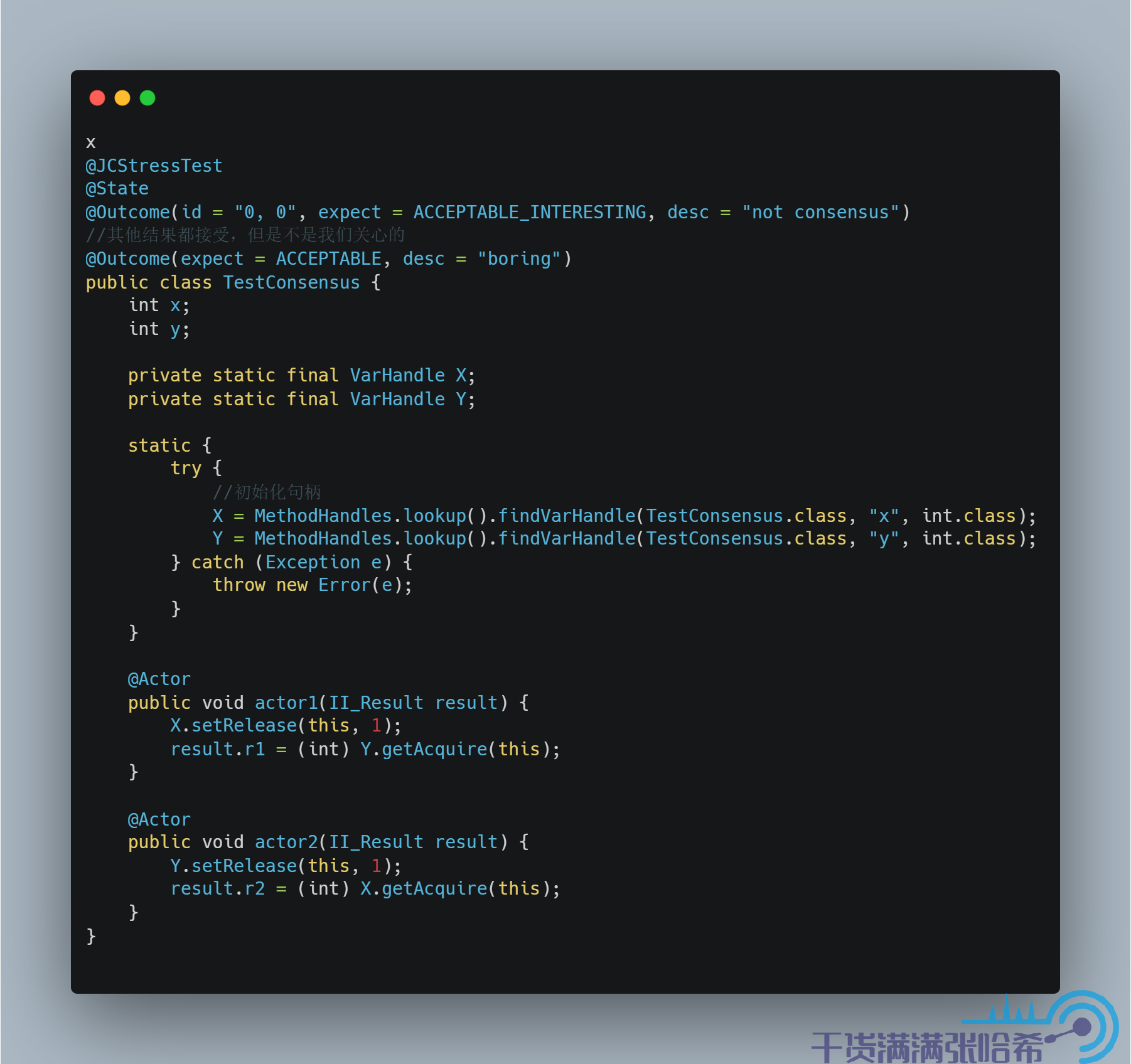
第四個結果比較有意思,他是不符合 Consensus 的,因為兩個執行緒看到的更新順序不一樣(第一個執行緒看到 0 代表他認為 x 的更新是在 y 的更新之前執行的,第二個執行緒看到 0 代表他認為 y 的更新是在 x 的更新之前執行的)。如果沒有亂序,那麼肯定不會看到 x, y 都是 0,因為執行緒 1 和執行緒 2 都是先更新後讀取的。但是也正如前面所有的講述一樣,各種亂序造成了我們可以看大第三個這樣的結果。那麼 Release/Acquire 能否保證不會出現這樣的結果呢?我們來簡單分析下,如果對於 x,y 的訪問都是 Release/Acquire 模式的,那麼執行緒 1 實際執行的就是:
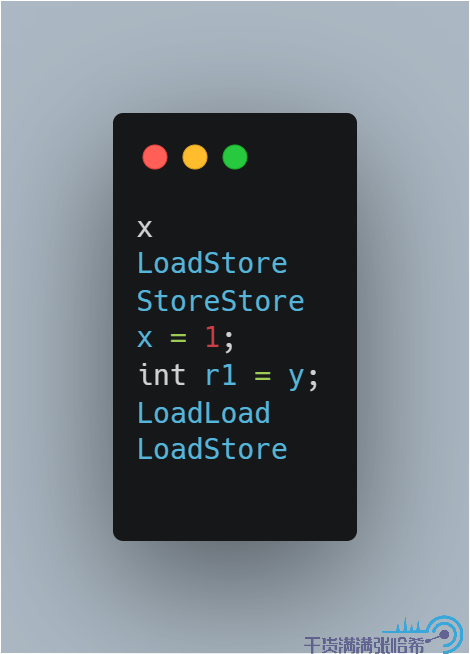
這裡我們就可以看出來,x = 1 與 int r1 = y 之間沒有任何記憶體屏障,所以實際可能執行的是:
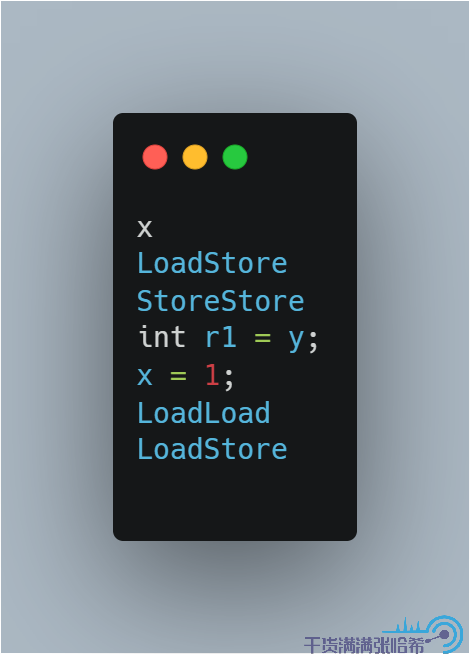
同理,執行緒 2 可能執行的是:
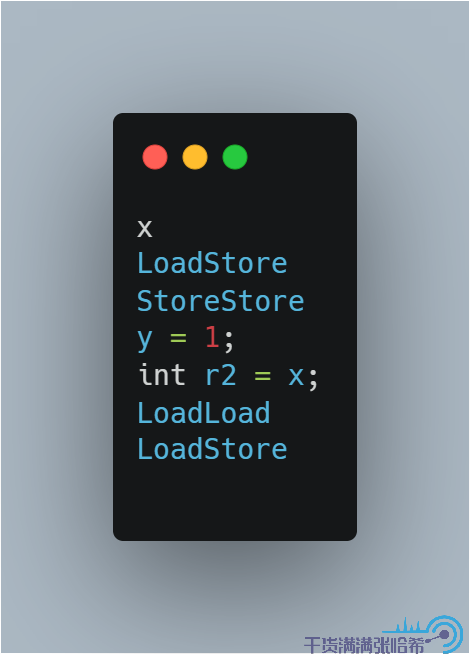
或者:
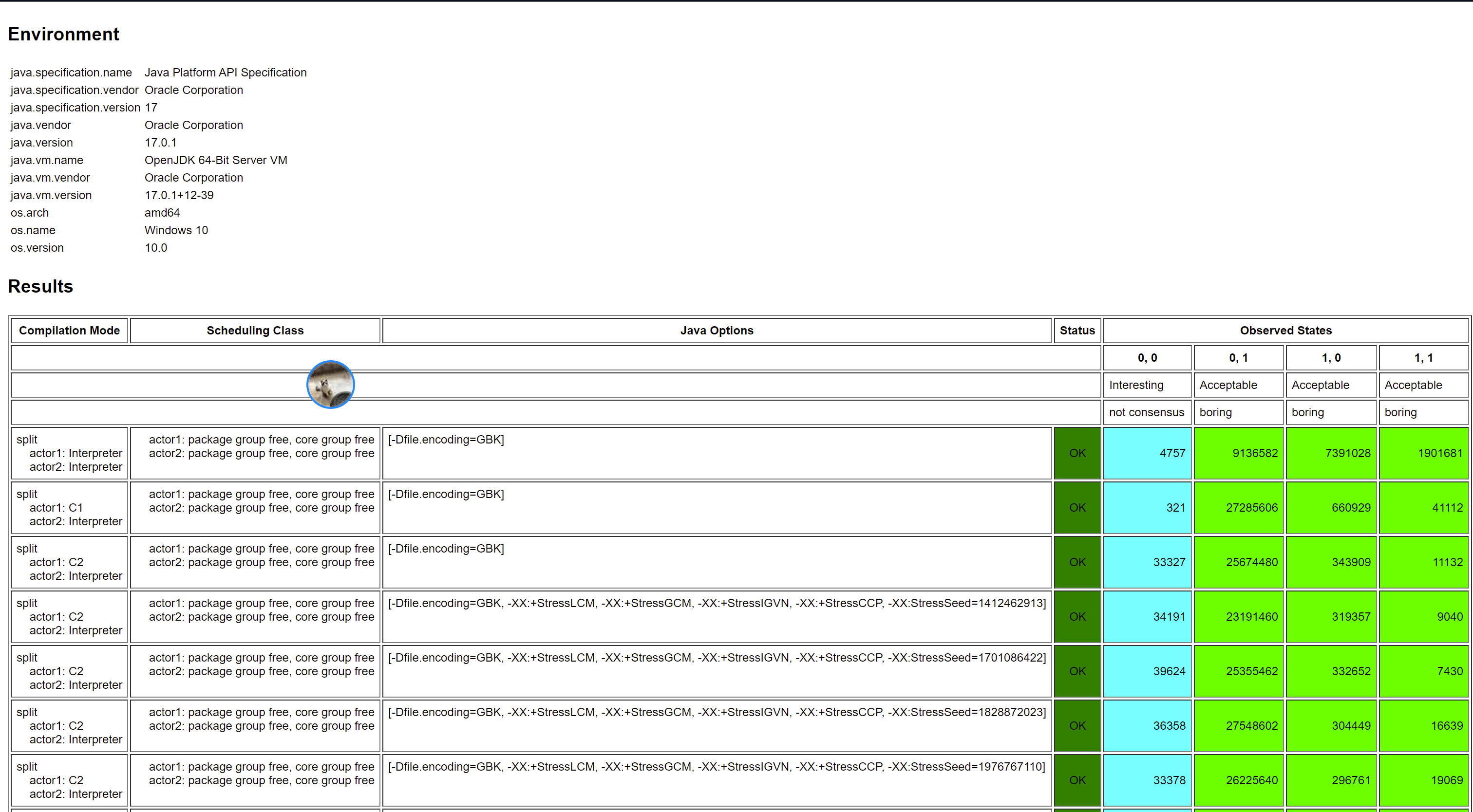
這樣,就會造成我們可能看到第四種結果。我們通過程式碼測試下:
測試結果是:
如果要保證 Consensus,我們只要保證執行緒 1 的程式碼與執行緒 2 的程式碼不亂序即可,即在原本的記憶體屏障的基礎上,添加 StoreLoad 記憶體屏障,即執行緒 1 執行:

執行緒 2 執行:

這樣就能保證不會亂序,這其實就是 volatile 訪問了。Volatile 訪問即在 Release/Acquire 的基礎上增加 StoreLoad 屏障,我們來測試下:
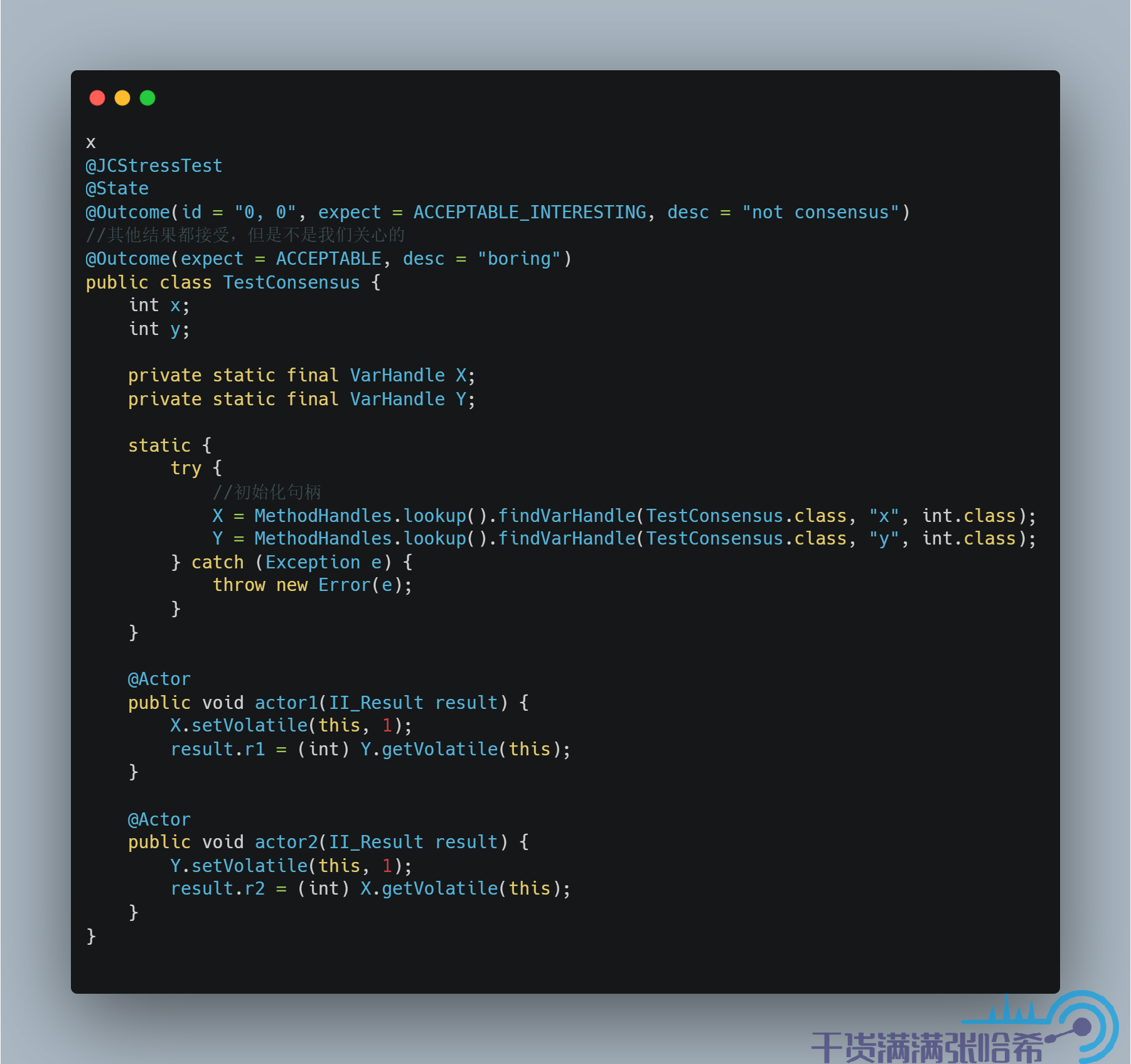
結果是:
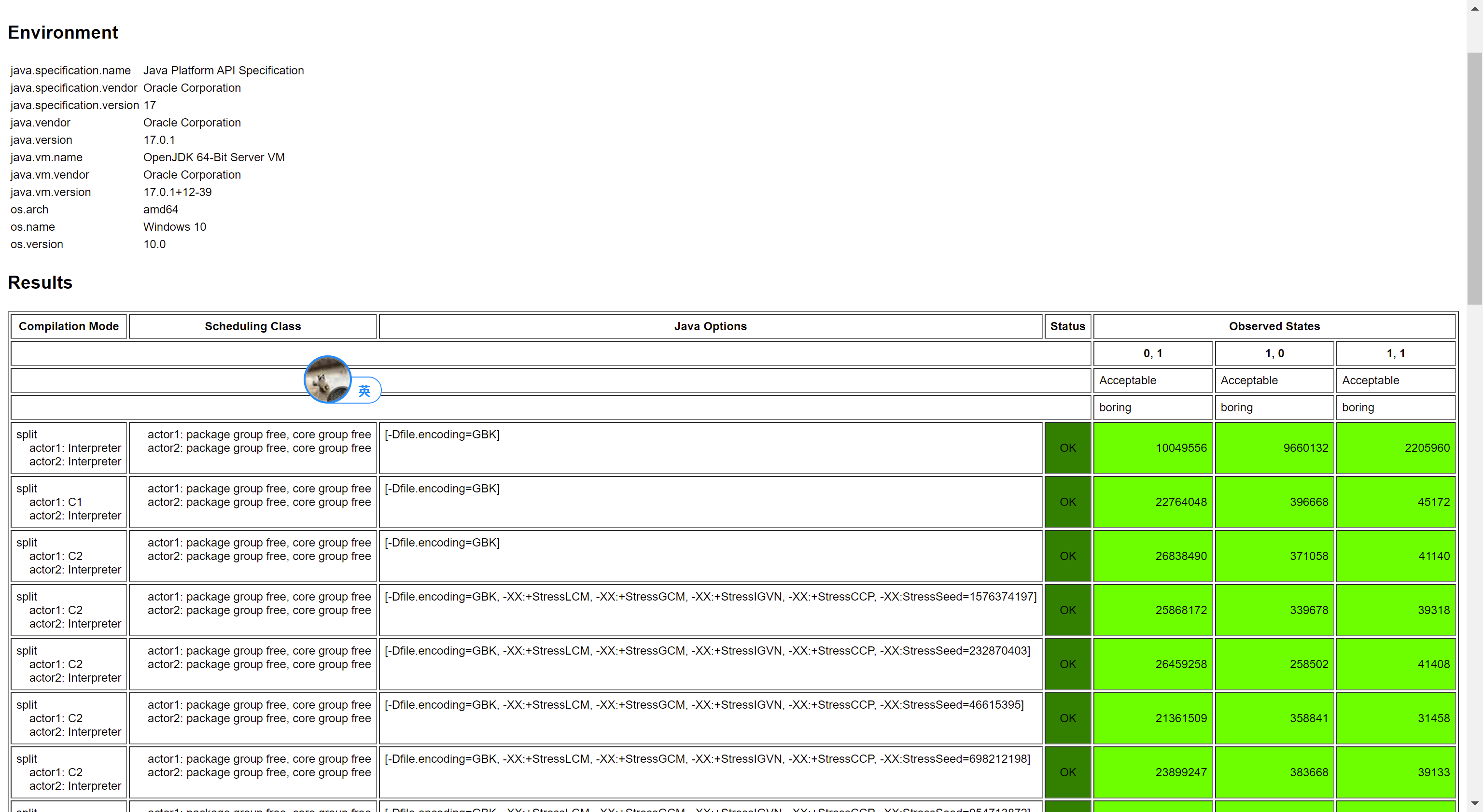
那麼引出另一個問題,這個 StoreLoad 屏障是 Volatile Store 之後添加,還是 Volatile Load 之前添加呢?我們來做下這個實驗:
首先保留 Volatile Store,將 Volatile Load 改成 Plain Load,即:
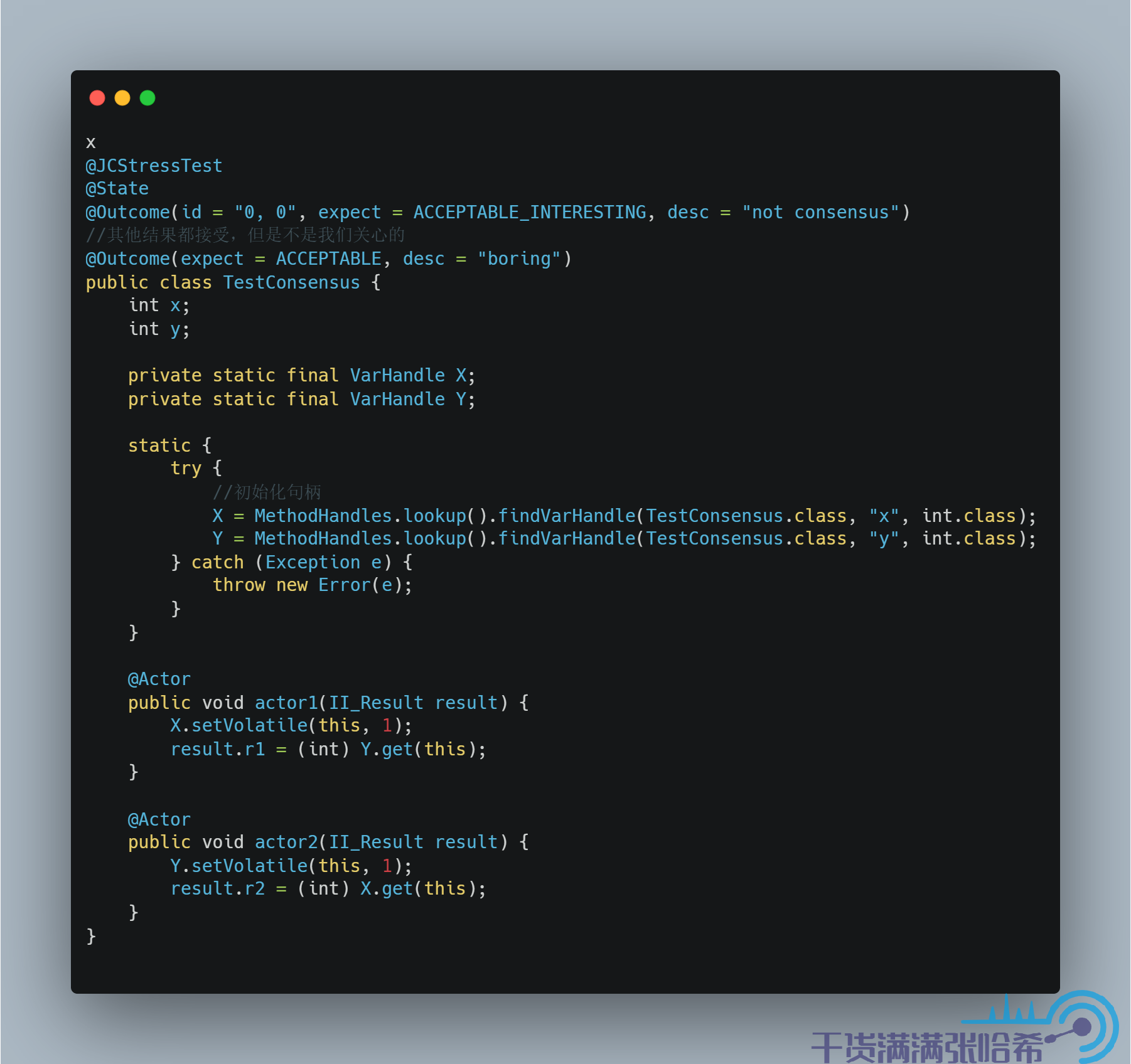
測試結果:
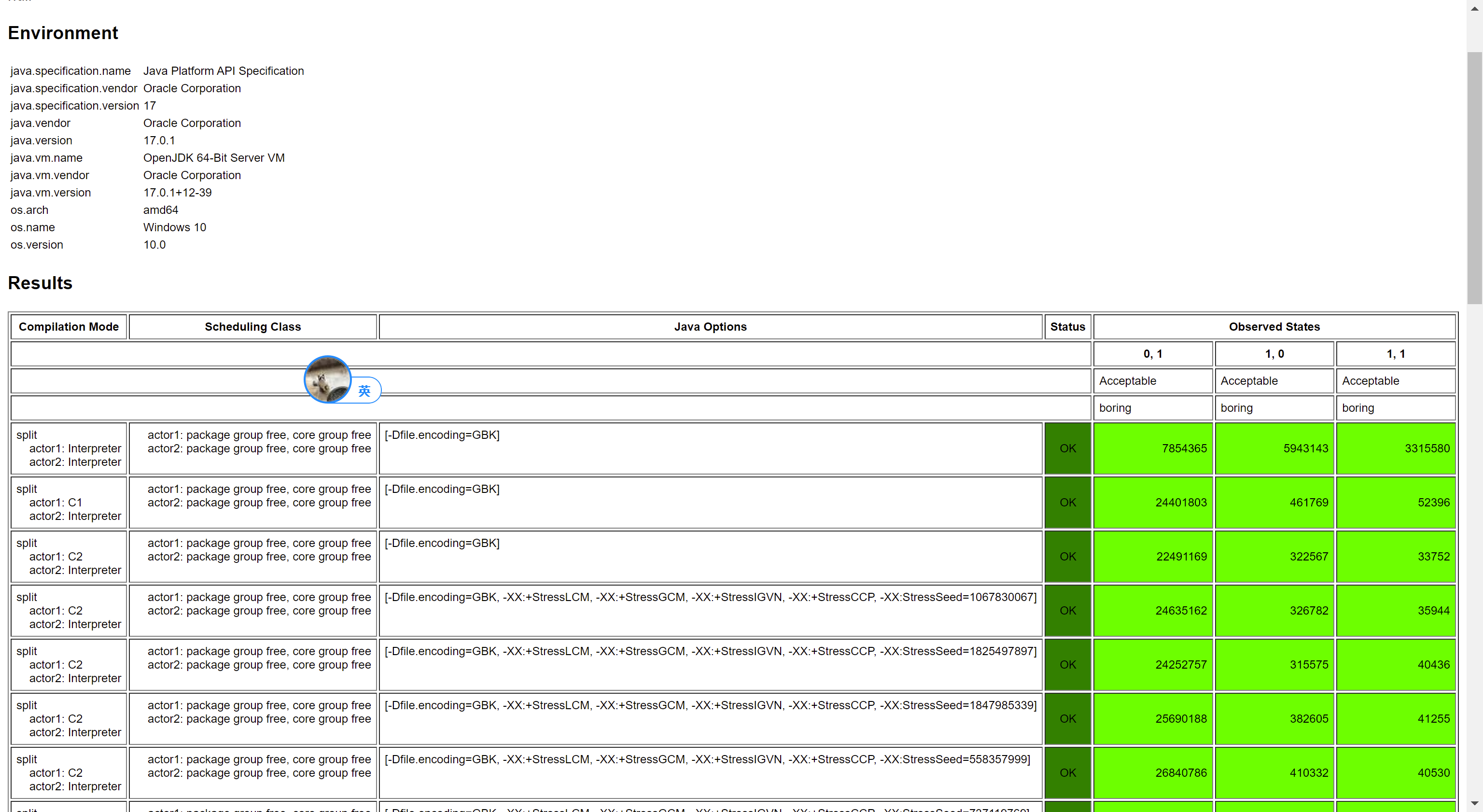
從結果中可以看出,仍然保持了 Consensus。再來看保留 Volatile Load,將 Volatile Store 改成 Plain Store:
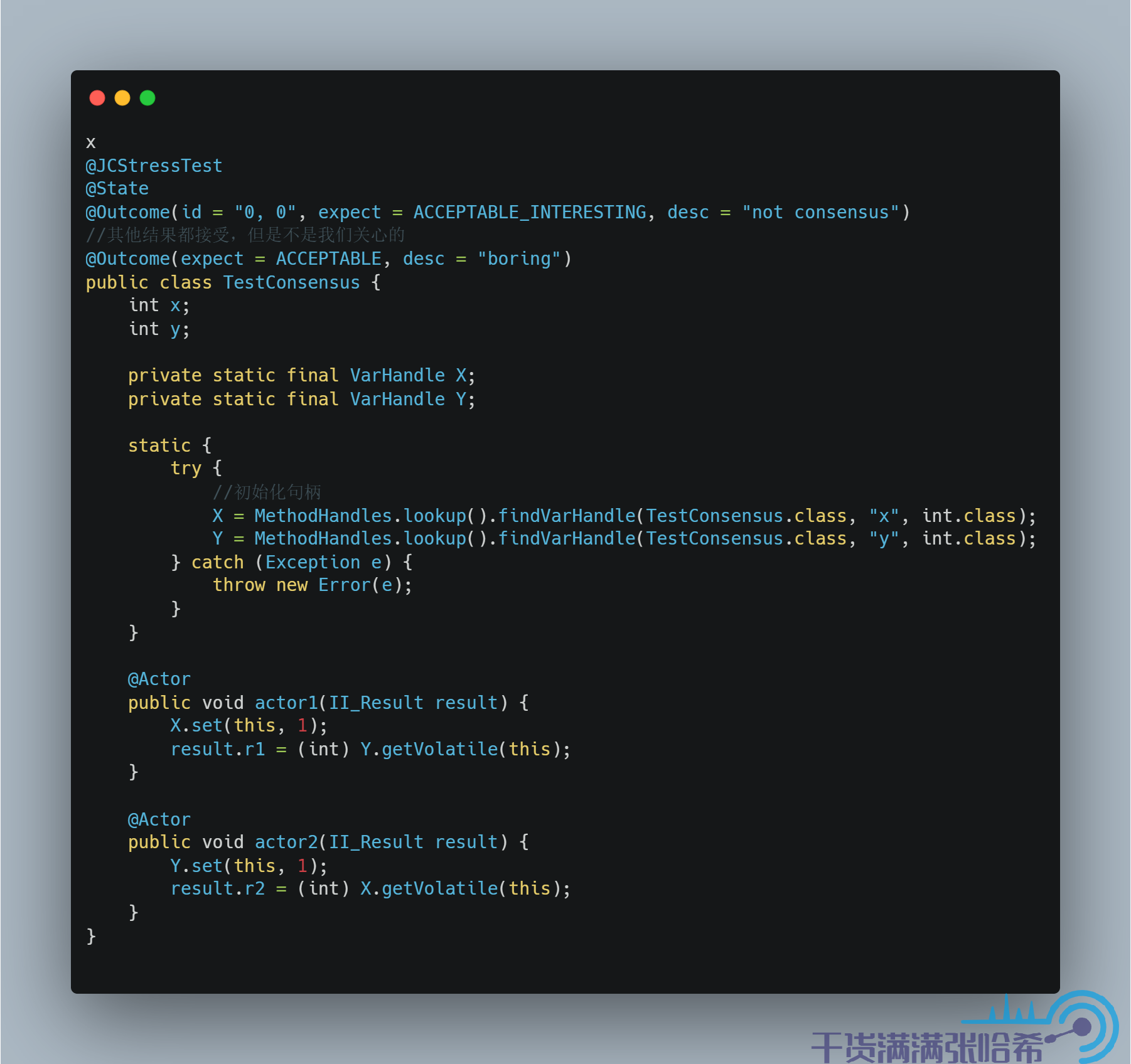
測試結果:
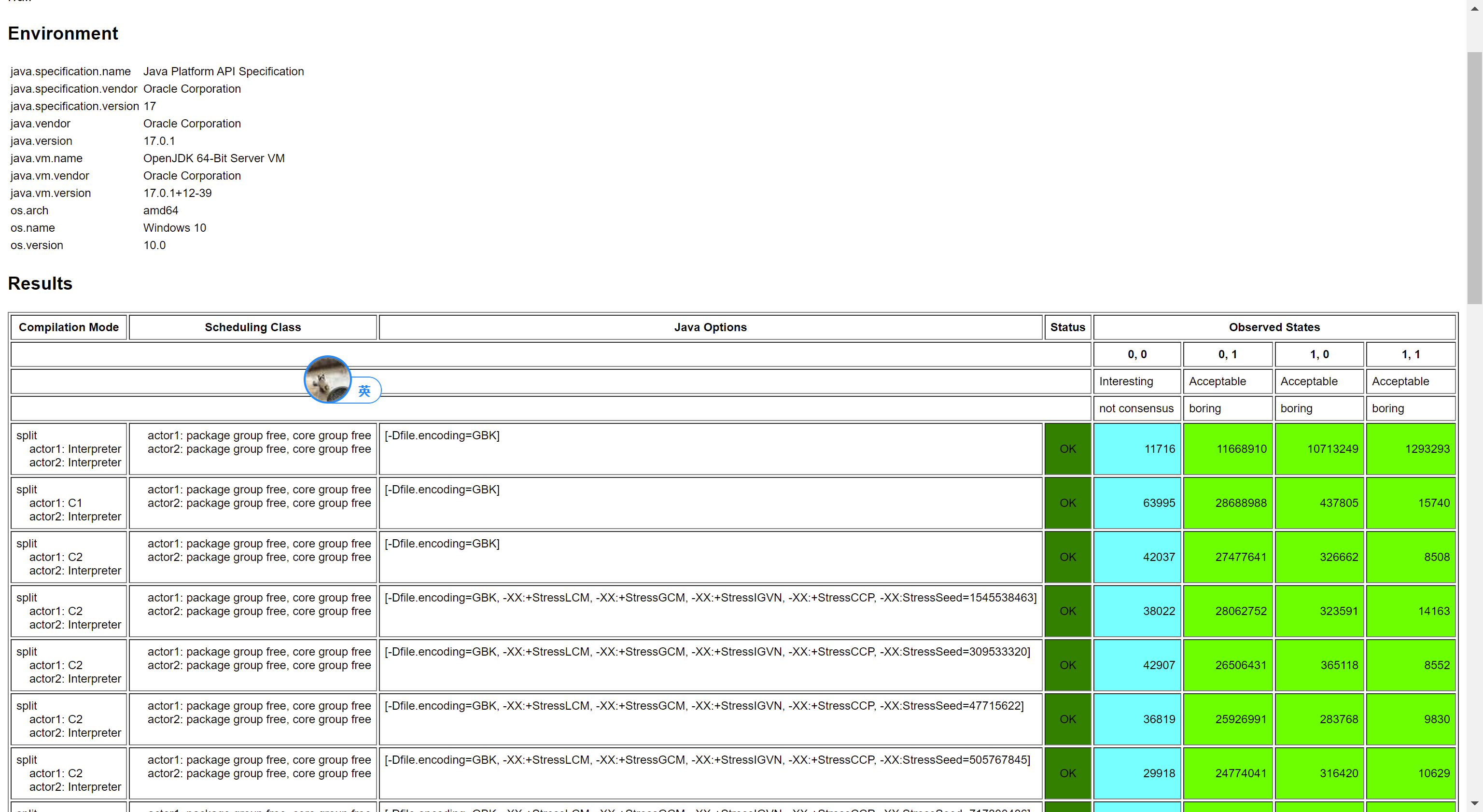
發現又亂序了。
所以,可以得出結論,這個 StoreLoad 是加在 Volatile 寫之後的,在後面的 JVM 底層源碼分析我們也能看出來。
7.4 Final 的作用
Java 中,創建對象通過調用類的構造函數實現,我們還可能在構造函數中放一些初始化一些欄位的值,例如:
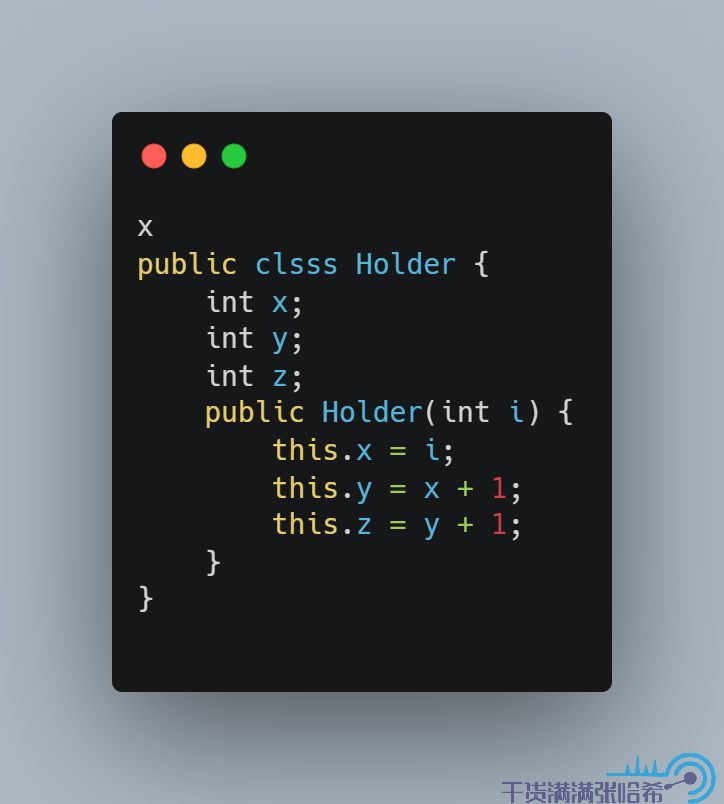
我們可以這樣調用構造器創建一個對象:
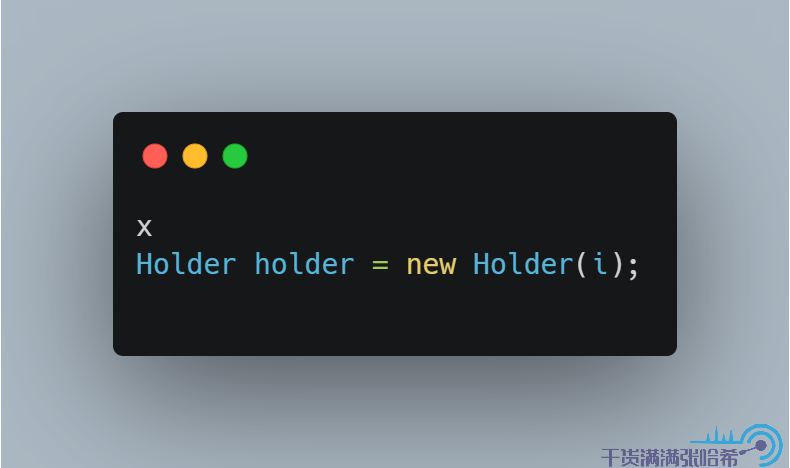
我們合併這些步驟,用偽程式碼表示底層實際執行的是:
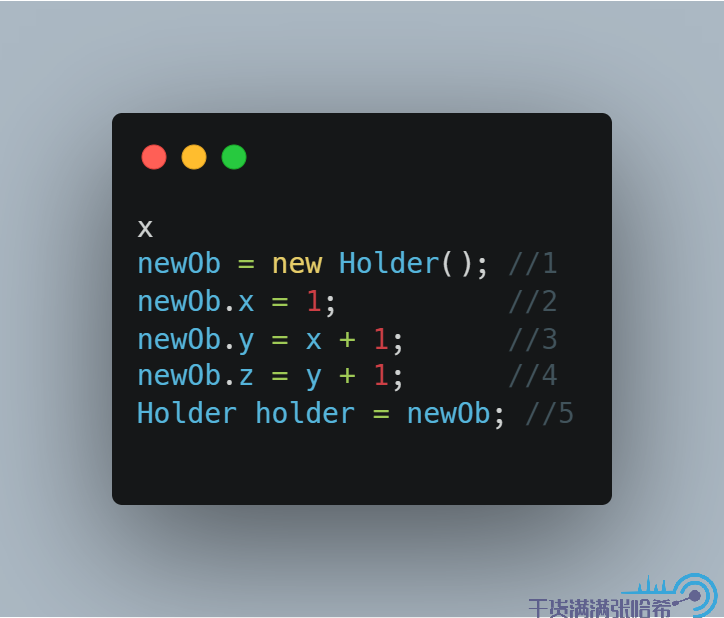
他們之間,沒有任何記憶體屏障,同時根據語義分析,1 和 5 之間有依賴關係,所以 1 和 5 的前後順序不能變。1,2,3,4 之間有依賴,所以 1,2,3,4 的前後順序也不能變。2,3,4 與 5 之間,沒有任何關係,他們之間的執行順序是可能亂序的。如果 5 在 2,3,4 中的任一一步之前執行,那麼就會造成我們可能看到構造器還未執行完,x,y,z 還是初始值的情況。測試下:
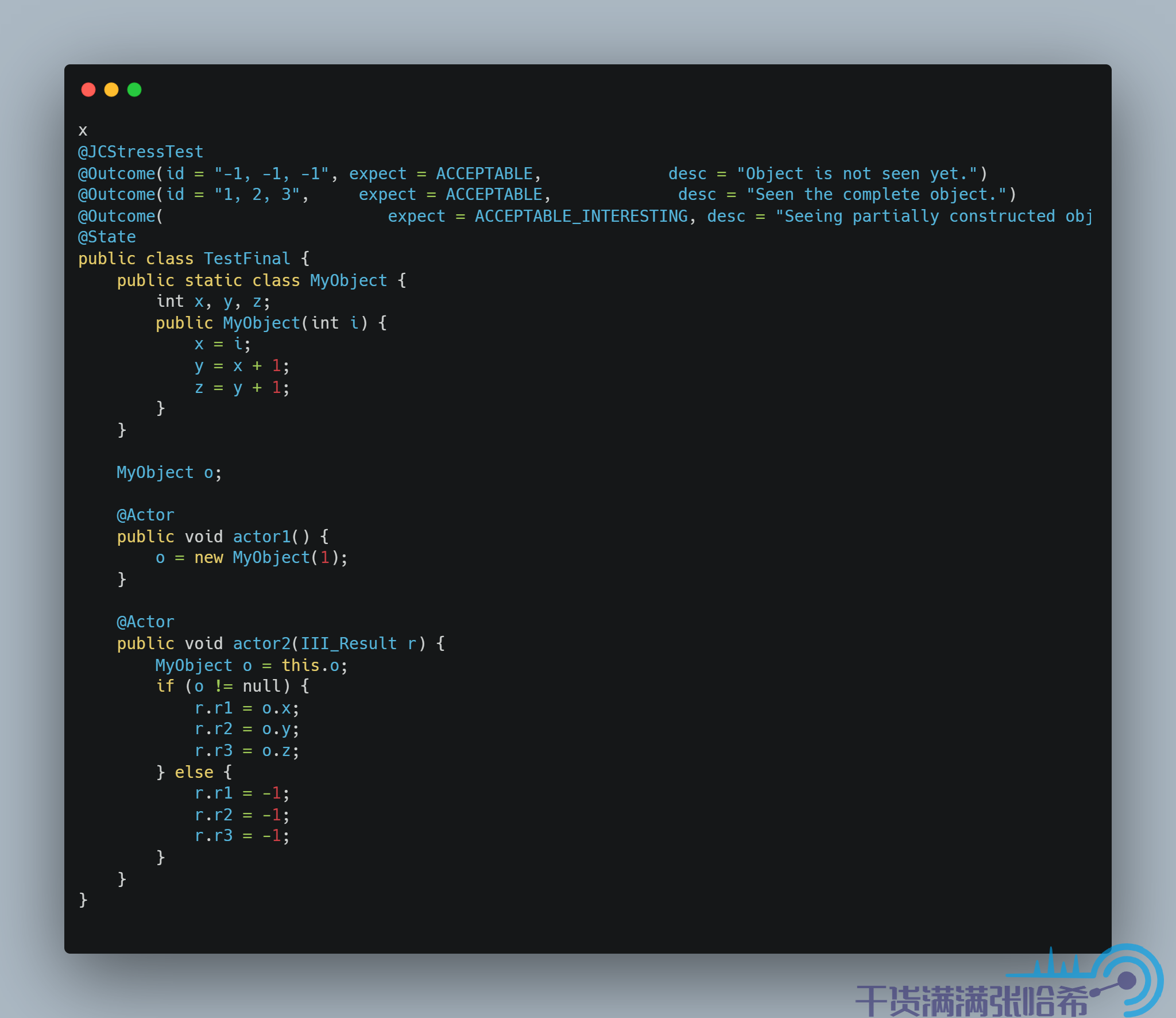
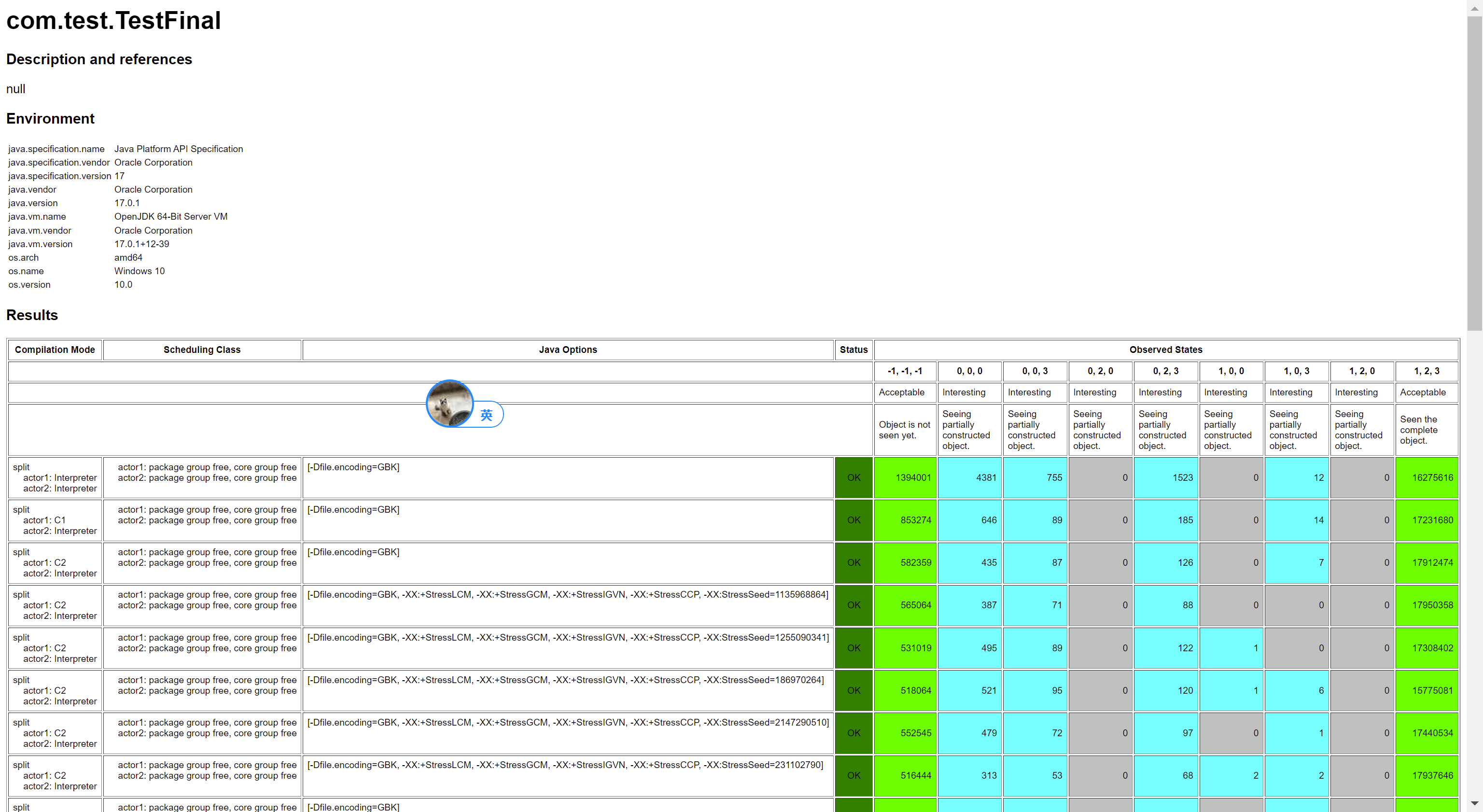
在 x86 平台的測試結果,你只會看到兩個結果,即 -1, -1, -1(代表沒看到對象初始化)和 1, 2, 3(看到對象初始化,並且沒有亂序),結果如下圖所示(AMD64 是一種 x86 的實現):
這是因為,前文我們也提到過類似的, x86 CPU 是比較強一致性的 CPU,這裡不會亂序。至於由於 x86 哪種不亂序性質這裡才不亂序,我們後面會看到。
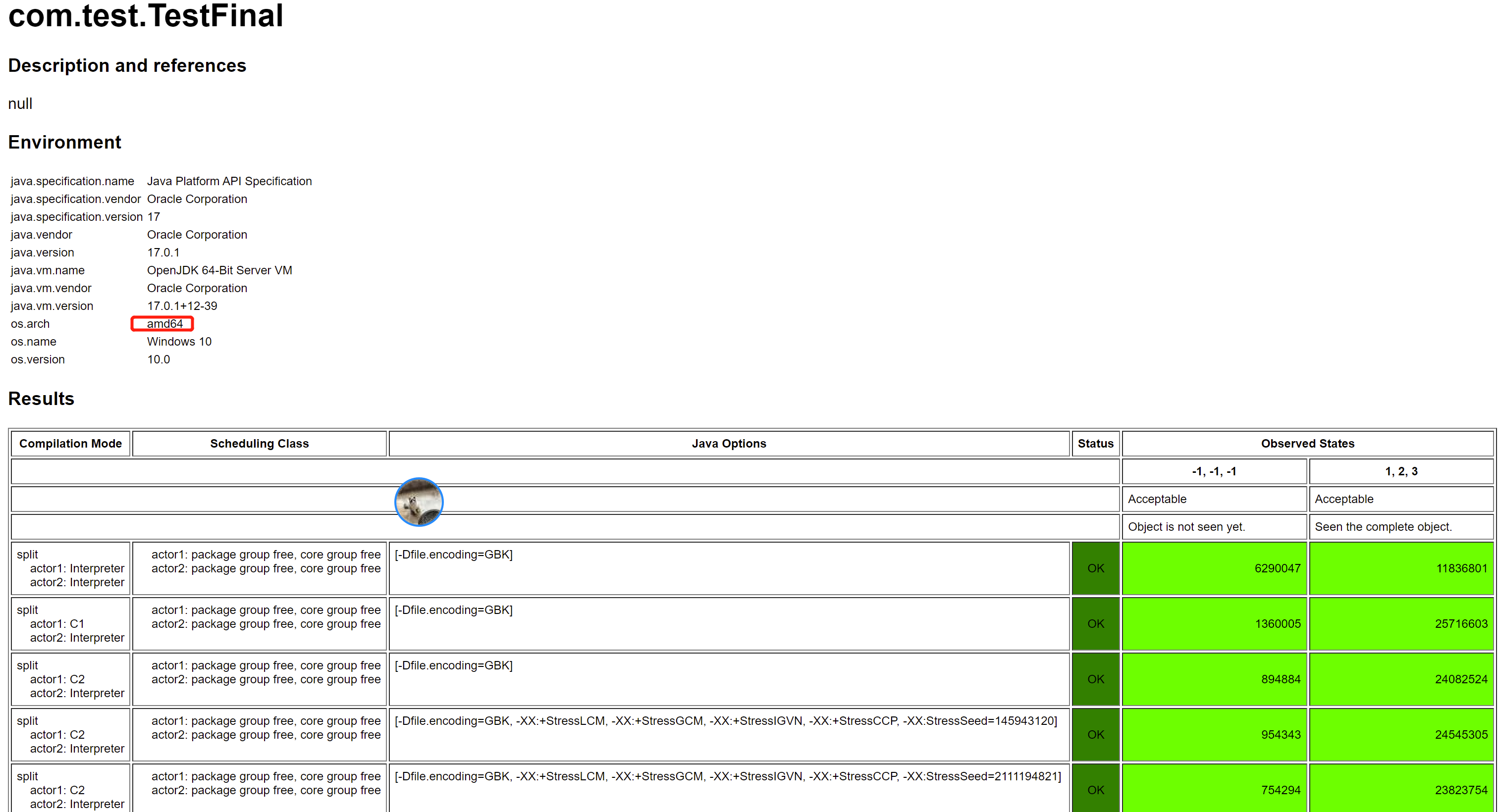
還是和前文一樣,我們換到不那麼強一致性的 CPU (ARM)上執行,這裡看到的結果就比較熱鬧了,如下圖所示(aarch64 是一種 ARM 實現):

那我們如何保證看到構造器執行完的結果呢?
用前面的記憶體屏障設計,我們可以把偽程式碼的第五步改成 setRelease,即:
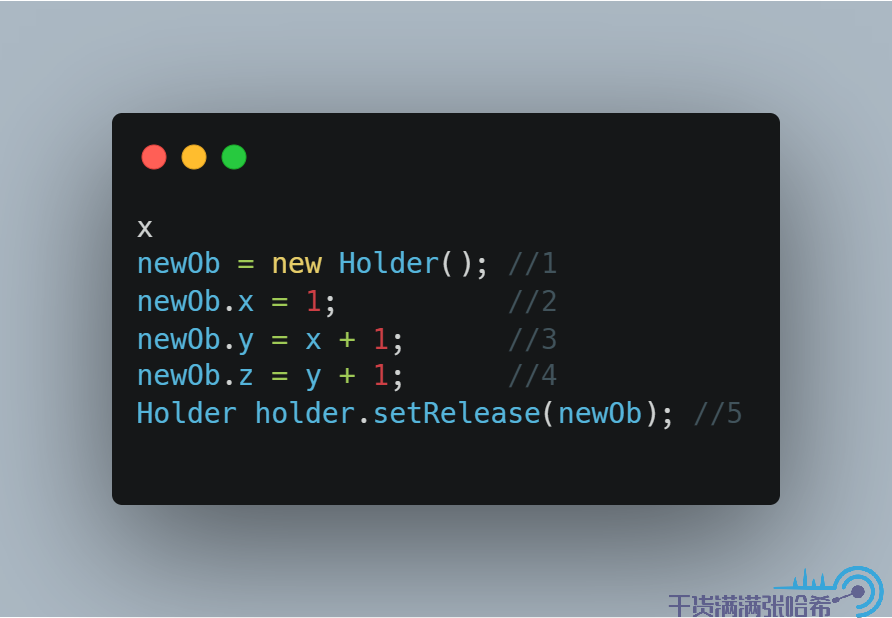
前面我們提到過 setRelease 會在前面加上 LoadStore 和 StoreStore 屏障,StoreStore 屏障會防止 2,3,4 與 5 亂序,所以可以避免這個問題,我們來試試看:
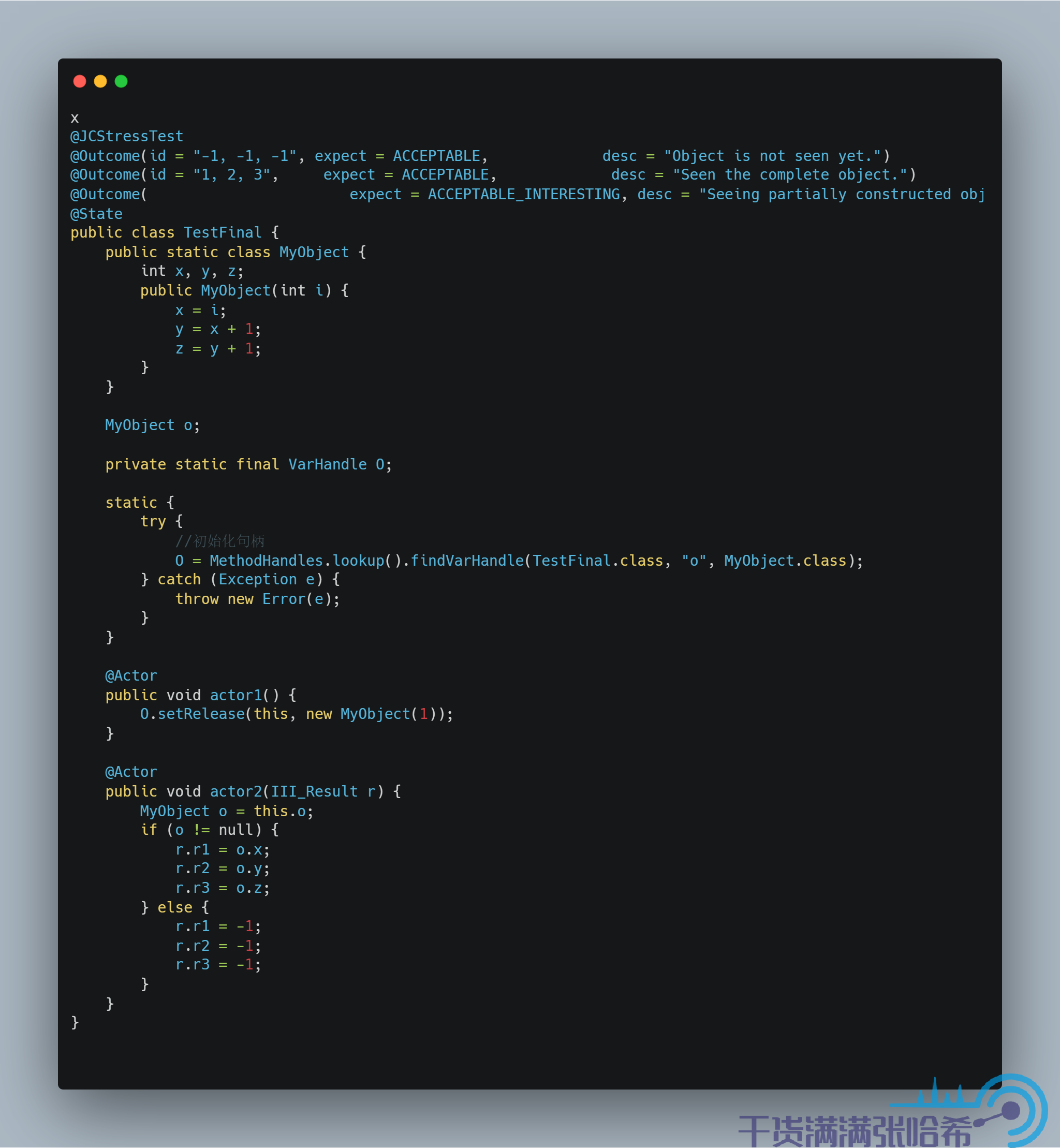
再到前面的 aarch64 機器上試一下,結果是:
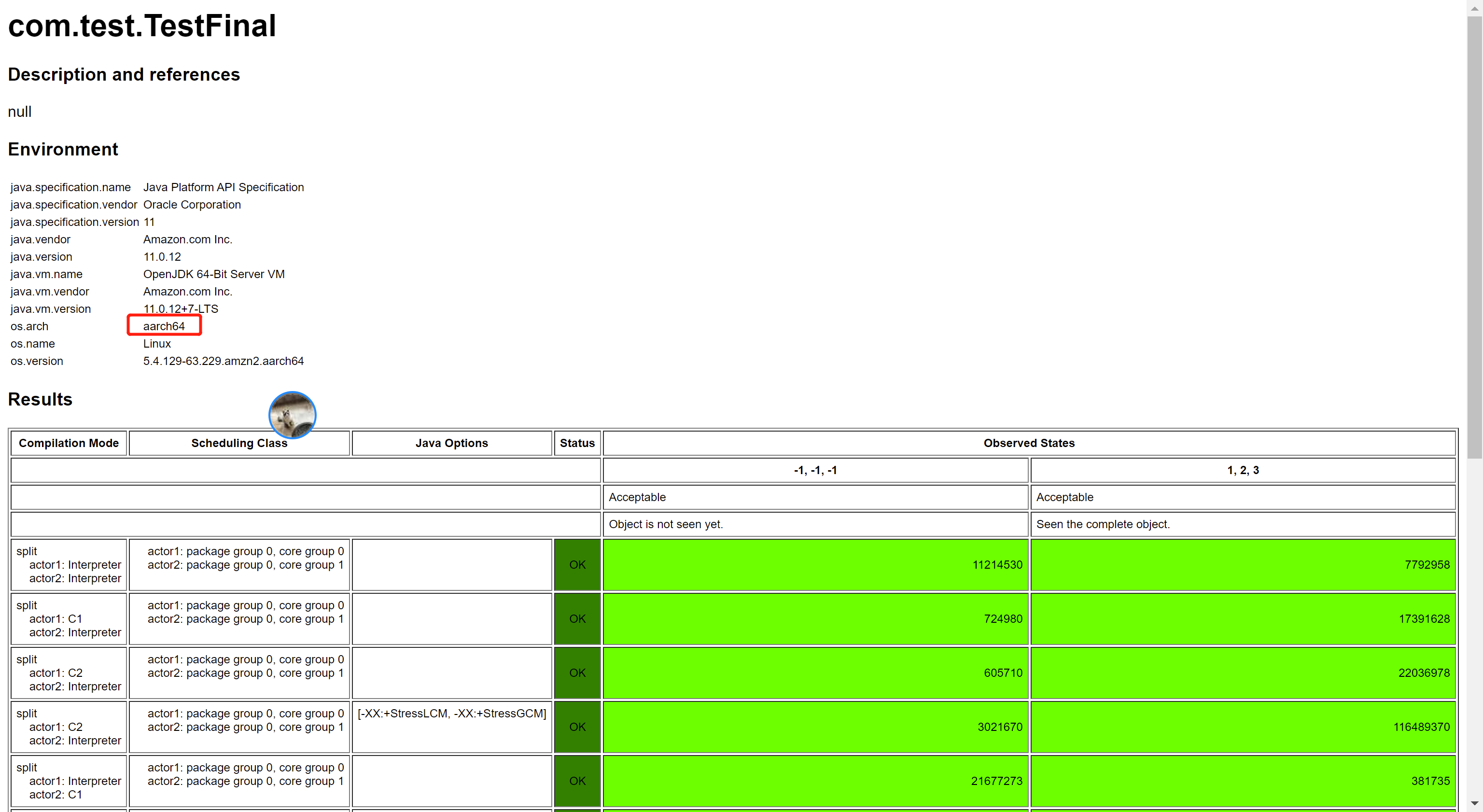
從結果可以看出,只能看到要麼沒初始化,要麼完整的構造器執行後的結果了。
我們再進一步,其實我們這裡只需要 StoreStore 屏障就夠了,由此引出了 Java 的 final 關鍵字:final 其實就是在更新後面緊接著加入 StoreStore 屏障,這樣也相當於在構造器結束之前加入 StoreStore 屏障,保證了只要我們能看到對象,對象的構造器一定是執行完了的。測試程式碼:
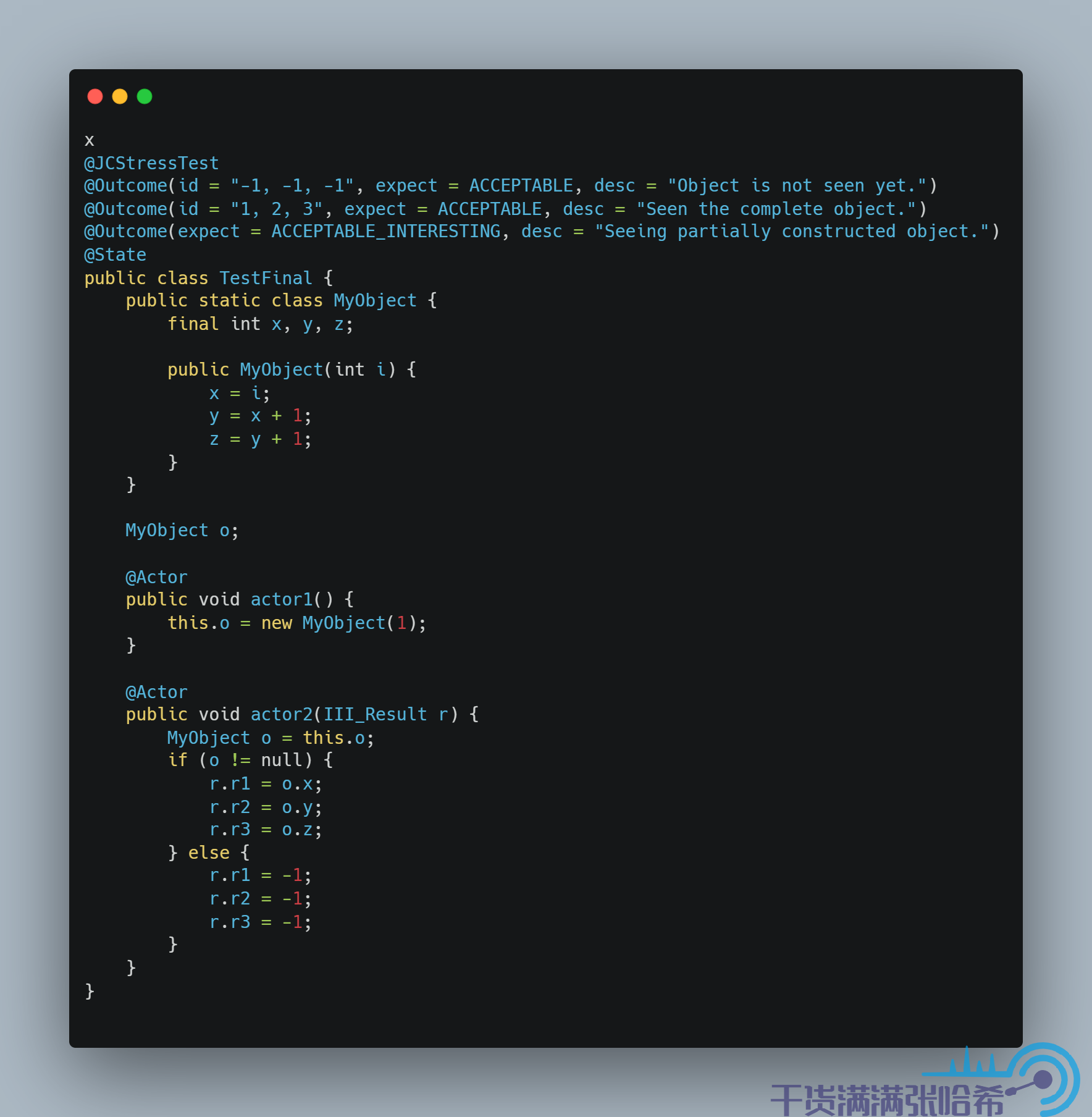
我們再進一步,由於偽程式碼中 2,3,4 是互相依賴的,所以這裡我們只要保證 4 先於 5 執行,那麼2,3,一定先於 5 執行,也就是我們只需要對 z 設置為 final,從而加 StoreStore 記憶體屏障,而不是每個都聲明為 final,從而多加記憶體屏障:
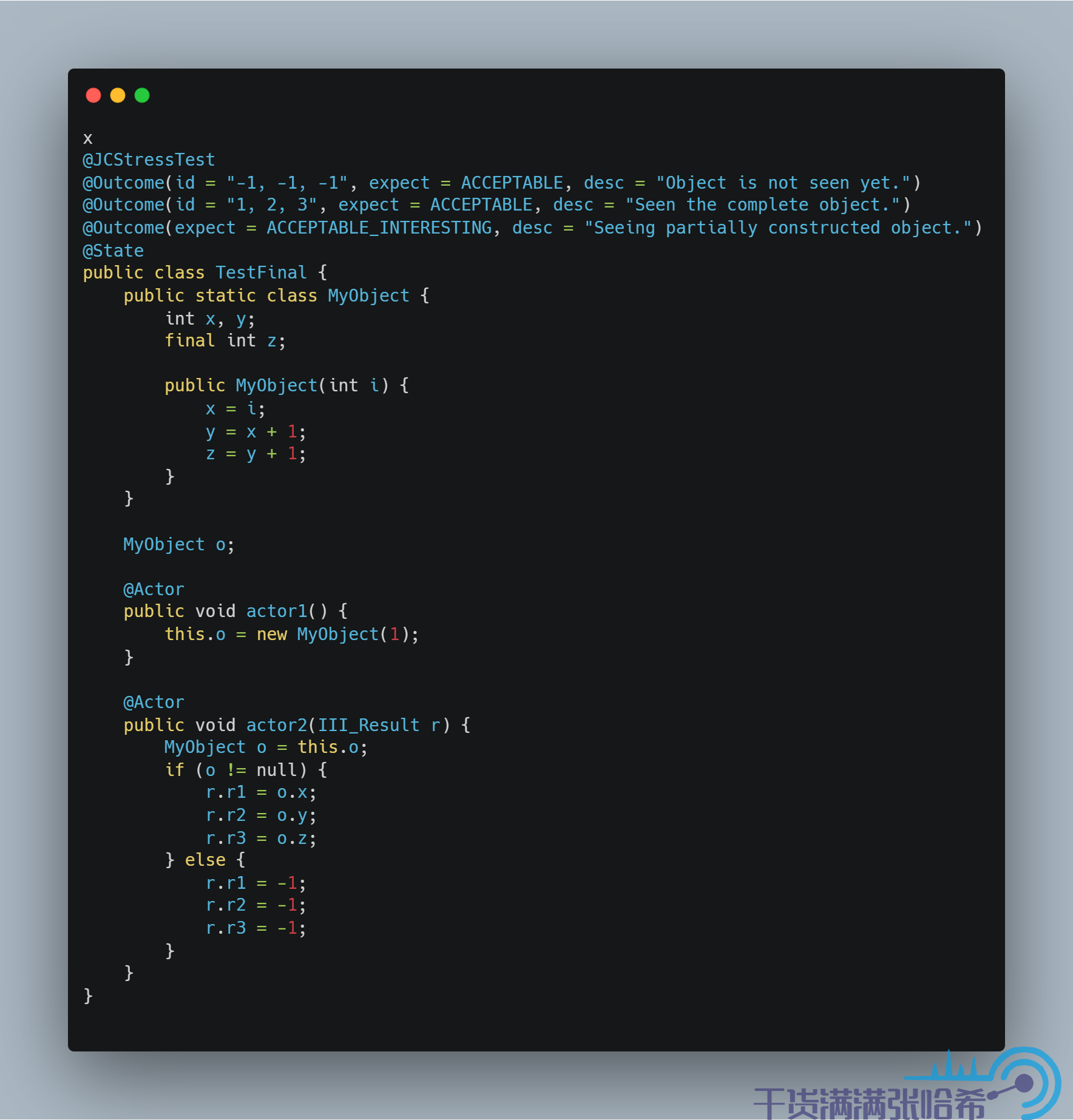
然後,我們繼續用 aarch64 測試,測試結果依然是對的:
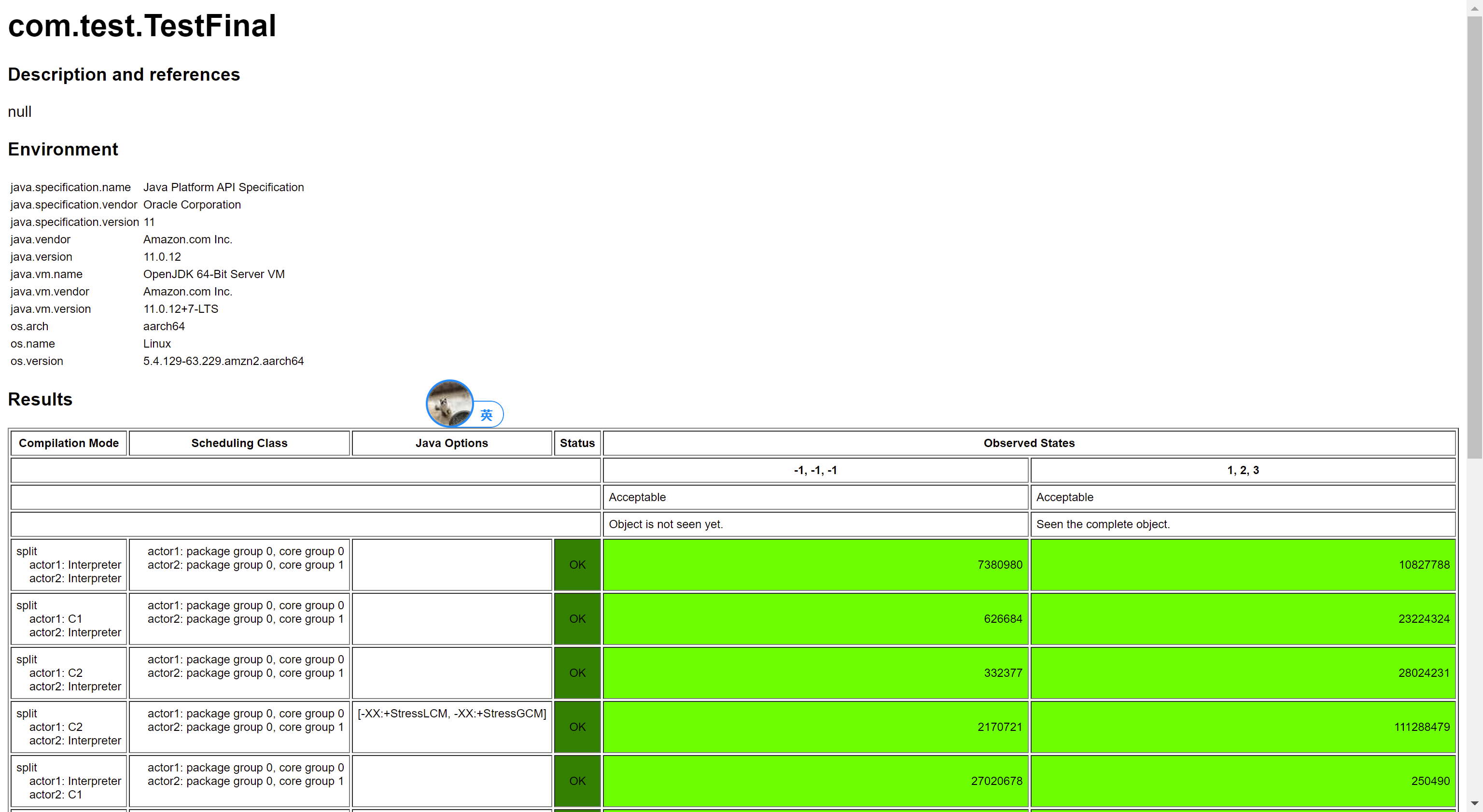
最後我們需要注意,final 僅僅是在更新後面加上 StoreStore 屏障,如果你在構造器過程中,將 this 暴露了出去,那麼還是會看到 final 的值沒有初始化,我們測試下:
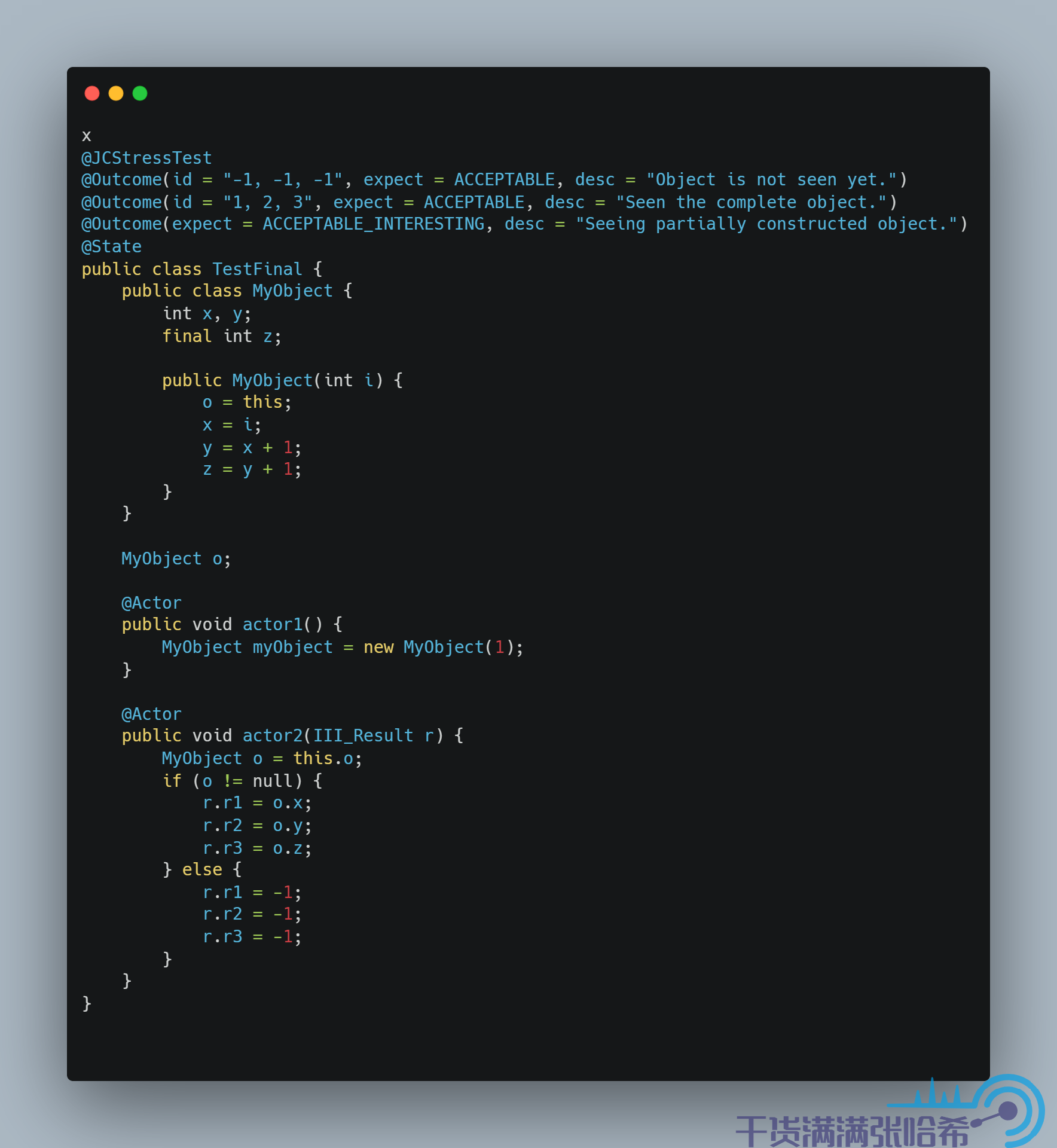
這次我們在 x86 的機器上就能看到 final 沒有初始化:
最後,為何這裡的示例中 x86 不需要記憶體屏障就能實現,參考前面的 CPU 圖:
x86 本身 Store 與 Store 之間就不會亂序,天然就有保證。
最後給上表格:
8. 底層 JVM 實現分析
8.1. JVM 中的 OrderAccess 定義
JVM 中有各種用到記憶體屏障的地方:
- 實現 Java 的各種語法元素(volatile,final,synchronized,等等)
- 實現 JDK 的各種 API(VarHandle,Unsafe,Thread,等等)
- GC 需要的記憶體屏障:因為要考慮 GC 多執行緒與應用執行緒(在 GC 演算法中叫做 Mutator)的工作方式,究竟是停止世界(Stop-the-world, STW)的方式,還是並發的方式
- 對象引用屏障:例如分代 GC,複製演算法,年輕代 GC 的時候我們一般是從一個 S 區複製存活對象到另一個 S 區,如果複製的過程,我們不想停止世界(Stop-the-world, STW),而是和應用執行緒同時進行,那麼我們就需要記憶體屏障,例如;
- 維護屏障:例如分區 GC 演算法,我們需要維護每個區的跨區引用表以及使用情況表,例如 Card Table。這個如果我們想要應用執行緒與 GC 執行緒並發修改訪問,而不是停止世界,那麼也需要記憶體屏障。
- JIT 也需要記憶體屏障:同樣地,應用執行緒究竟是解釋執行程式碼還是執行 JIT 優化後的程式碼,這裡也是需要記憶體屏障的。
這些記憶體屏障,不同的 CPU,不同的作業系統,底層需要不同的程式碼實現,統一的介面設計是:
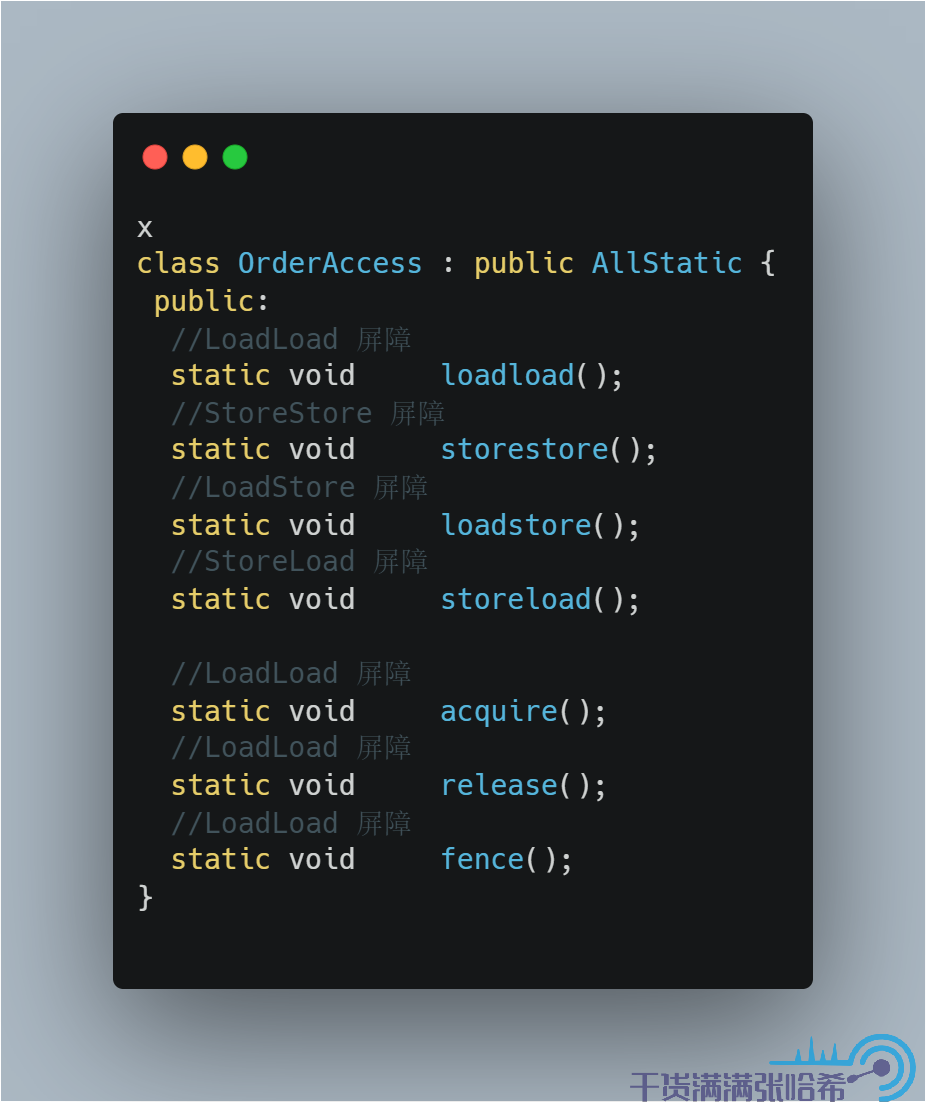
不同的 CPU,不同的作業系統實現是不一樣的,結合前面 CPU 亂序表格:
我們來看下 linux + x86 的實現:
源程式碼地址:orderAccess_linux_x86.hpp
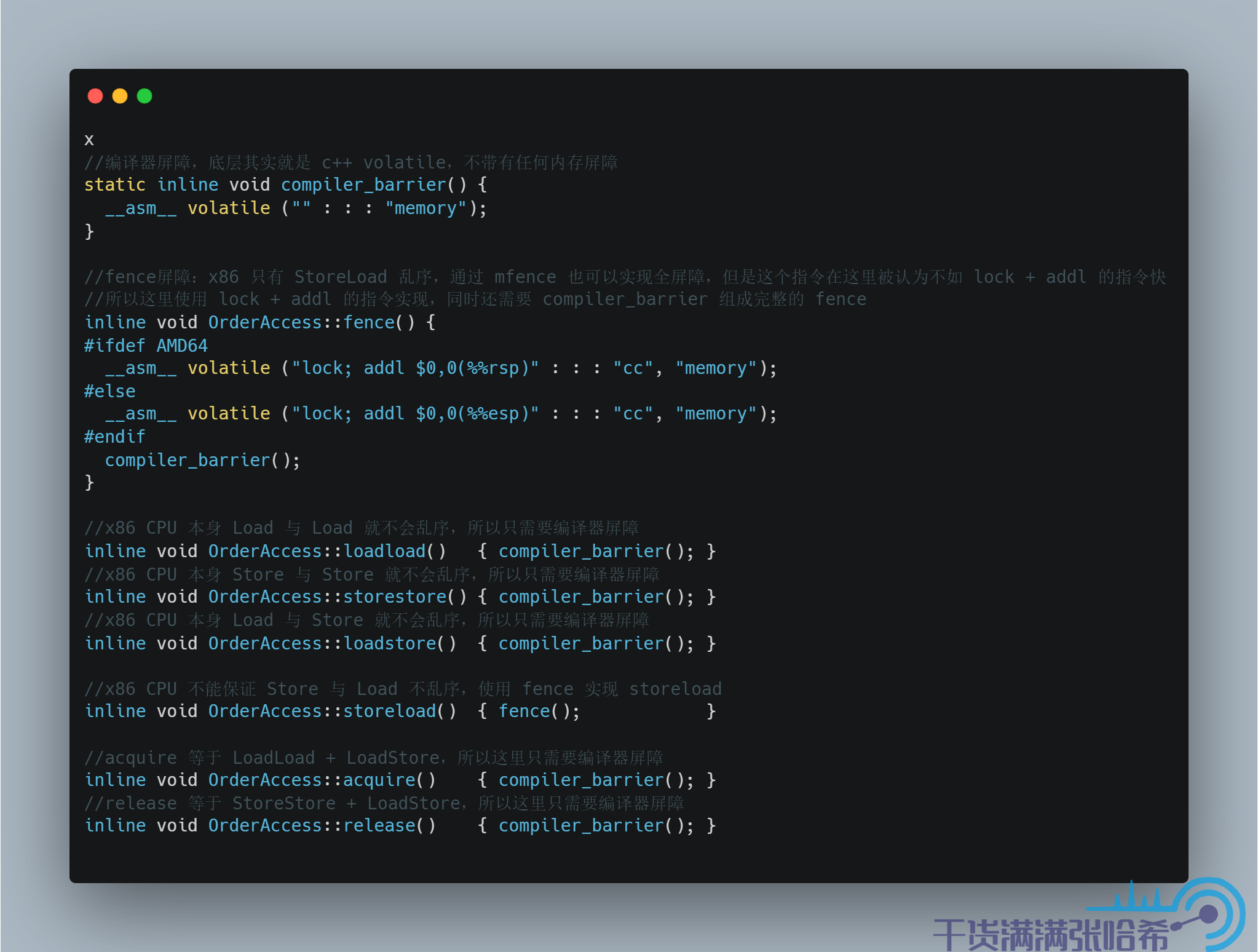
對於 x86,由於 Load 與 Load,Load 與 Store,Store 與 Store 本來有一致性保證,所以只要沒有編譯器亂序,那麼就天生有 StoreStore,LoadLoad,LoadStore 屏障,所以這裡我們看到 StoreStore,LoadLoad,LoadStore 屏障的實現都只是加了編譯器屏障。同時,前文中我們分析過,acquire 其實就是相當於在 Load 後面加上 LoadLoad,LoadStore 屏障,對於 x86 還是需要編譯器屏障就夠了。release 我們前文中也分析過,其實相當於在 Store 前面加上 LoadStore 和 StoreStore,對於 x86 還是需要編譯器屏障就夠了。於是,我們有如下表格:
我們再看下前面我們經常使用的 Linux aarch64 下的實現:
源程式碼地址:orderAccess_linux_aarch64.hpp
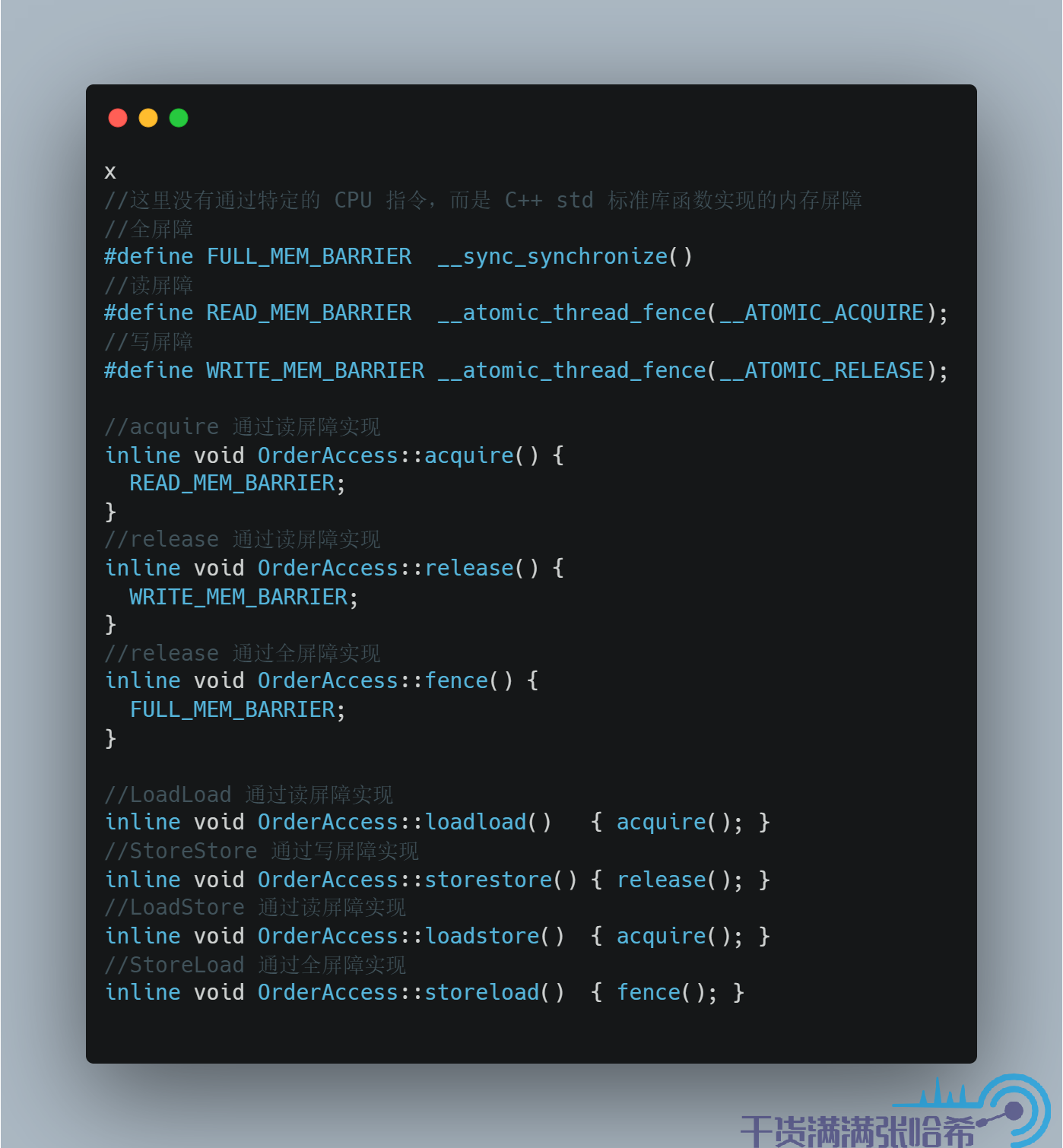
如前面表格裡面說,ARM 的 CPU Load 與 Load,Load 與 Store,Store 與 Store,Store 與 Load 都會亂序。JVM 針對 aarch64 沒有直接使用 CPU 指令,而是使用了 C++ 封裝好的記憶體屏障實現。C++ 封裝好的很像我們前面講的簡易 CPU 模型的記憶體屏障,即讀記憶體屏障(__atomic_thread_fence(__ATOMIC_ACQUIRE)),寫記憶體屏障(__atomic_thread_fence(__ATOMIC_RELEASE)),讀寫記憶體屏障(全記憶體屏障,__sync_synchronize())。acquire 的作用是作為接收點解包讓後面的都看到包裡面的內容,類比簡易 CPU 模型,其實就是阻塞等待 invalidate queue 完全處理完保證 CPU 快取沒有臟數據。release 的作用是作為發射點將前面的更新打包發出去,類比簡易 CPU 模型,其實就是阻塞等待 store buffer 完全刷入 CPU 快取。所以,acquire,release 分別使用讀記憶體屏障和寫記憶體屏障實現。
LoadLoad 保證第一個 Load 先於第二個,那麼其實就是在第一個 Load 後面加入讀記憶體屏障,阻塞等待 invalidate queue 完全處理完;LoadStore 同理,保證第一個 Load 先於第二個 Store,只要 invalidate queue 處理完,那麼當前 CPU 中就沒有對應的臟數據了,就不需要等待當前的 CPU 的 store buffer 也清空。
StoreStore 保證第一個 Store 先於第二個,那麼其實就是在第一個寫入後面放讀記憶體屏障,阻塞等待 store buffer 完全刷入 CPU 快取;對於 StoreLoad,比較特殊,由於第二個 Load 需要看到 Store 的最新值,也就是更新不能只到 store buffer,同時過期不能存在於 invalidate queue 未處理,所以需要讀寫記憶體屏障,即全螢幕障。
8.2. volatile 與 final 的記憶體屏障源碼
我們接下來看一下 volatile 的記憶體屏障插入的相關程式碼,以 arm 為例子. 我們其實通過跟蹤 iload 這個位元組碼就可以看出來如果 load 的是 volatile 關鍵字或者 final 關鍵字修飾的欄位會怎麼樣,以及 istore就可以看出來如果 store的是 volatile 關鍵字或者 final 關鍵字修飾的欄位會怎麼樣
對於欄位訪問,JVM 中也有快速路徑和慢速路徑,我們這裡只看快速路徑的程式碼:
對應源碼:
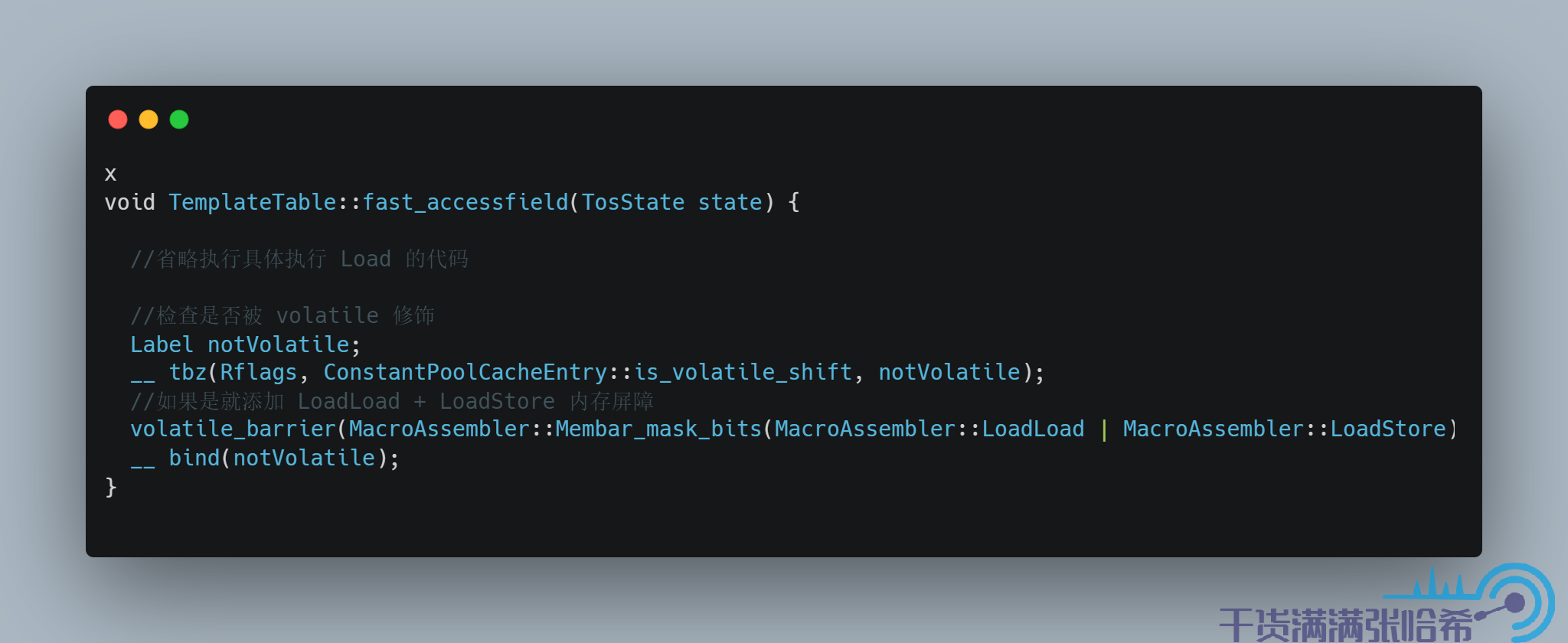
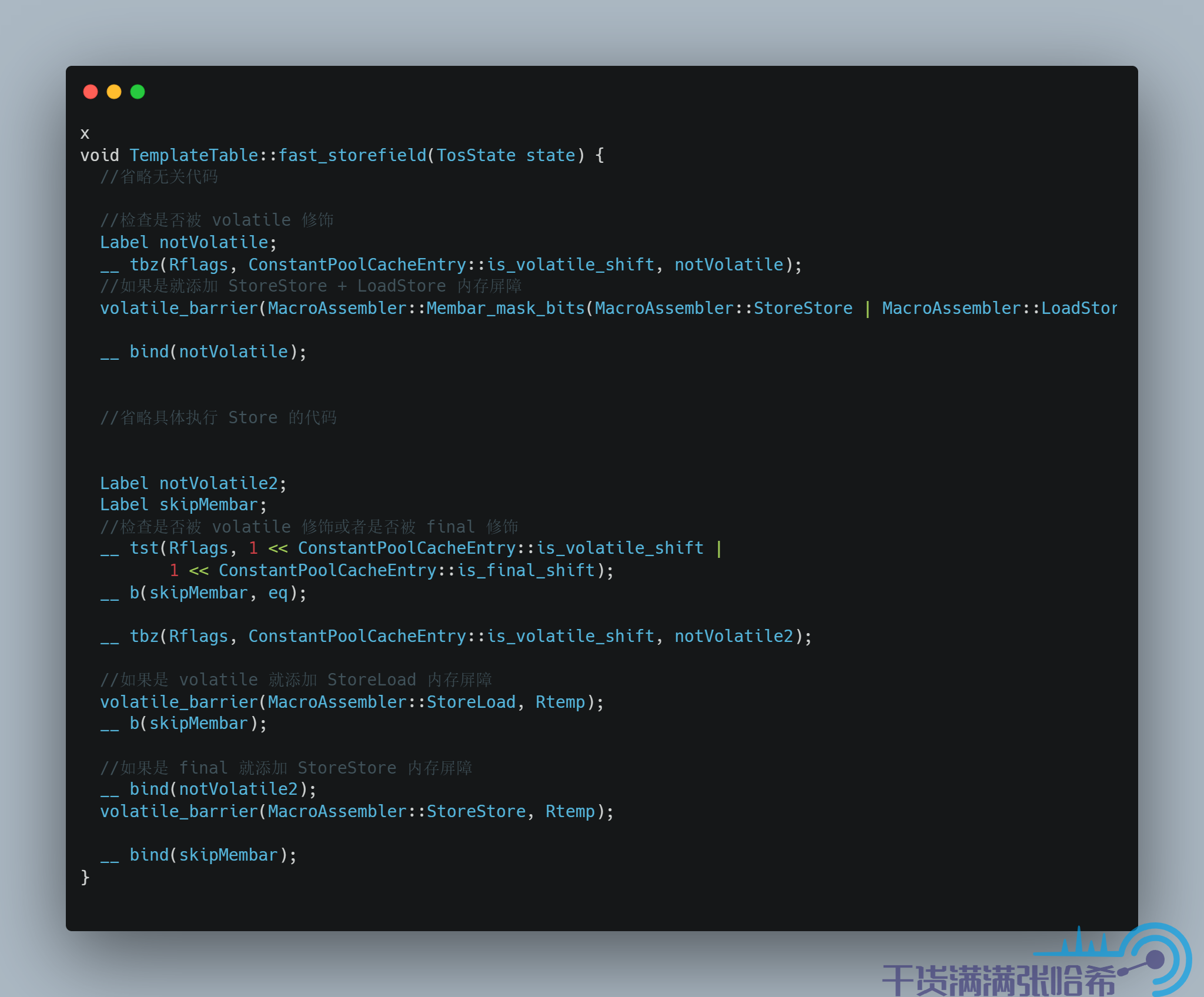
9. 一些 QA
9.1. 為什麼看到某些地方在方法本地變數使用 final
對於本地變數中的 final(和前面提到的修飾欄位的 final 不是一回事),這個單純從語義上講,其實並沒有什麼性能方面的考慮,僅僅是作為一種標記。即:你可能在方法本地聲明很多變數,但是為了語義清晰,就將肯定不會改的聲明為 final。
JDK 的開發者一般用 final 本地變數來做這樣一件事,假設有如下程式碼:

假設編譯器不會做任何優化,那麼 1,2,4 我們都各做了一次對於欄位的訪問。如果有編譯器優化參與進來,那麼是有可能優化成下面的程式碼的:
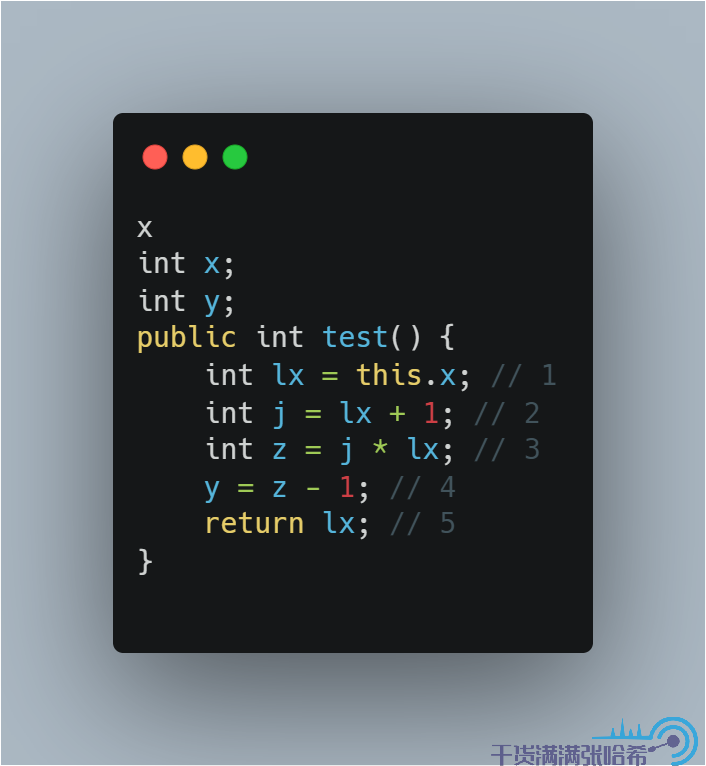
這樣,只會讀取 1 次 x 欄位。這樣造成的問題是,程式碼在被解釋器執行,不同的 JIT 優化執行的時候,如果 x 有並發的更新,那麼看到的可能的結果集是不一樣的。為了避免這種歧義,如果我們確定我們這裡的函數只想讀取一次 x,那麼就直接寫成:

為了標記 lx 是不會變的(同時也為了表達我們只想讀一次 x),加上 final,就變成:
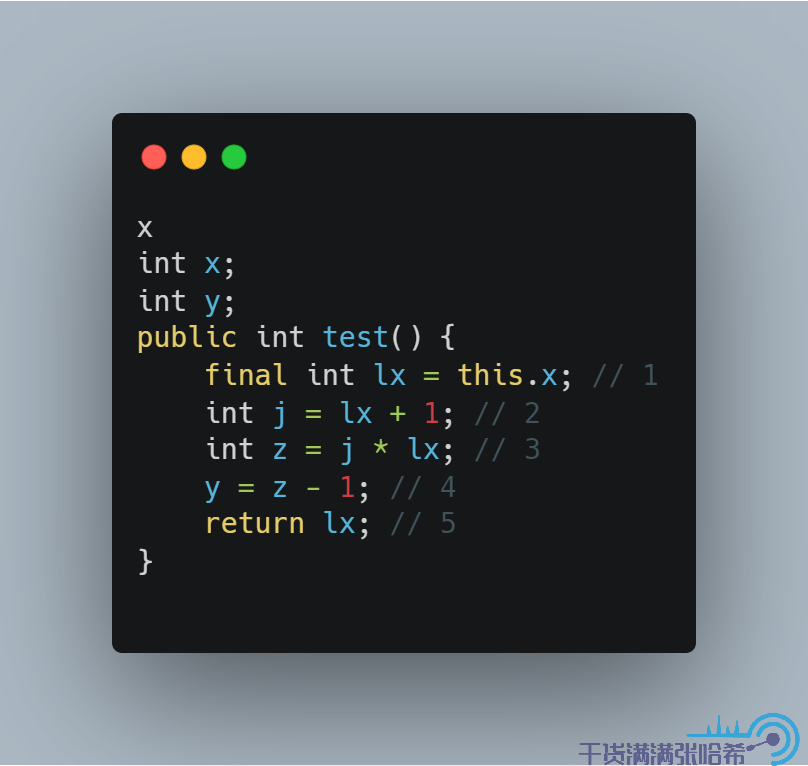
微信搜索「我的編程喵」關注公眾號,加作者微信,每日一刷,輕鬆提升技術,斬獲各種offer:
我會經常發一些很好的各種框架的官方社區的新聞影片資料並加上個人翻譯字幕到如下地址(也包括上面的公眾號),歡迎關註:



