編程入門之字元編碼與亂碼
——「為什麼伺服器收到的請求或者打開的文本文件有時會亂碼?」
——「因為編碼不對。」
——「編碼的本質是什麼?為什麼編碼不對就會亂碼?一段文本是如何在網路中傳輸後最終顯示給用戶的?Java String默認使用什麼編碼?」
——「……」
亂碼問題相信很多同學都有幸遇到過的,也解決過,但根據個人面試的經驗,對該問題知其然亦知其所以然的同學,是少之又少的。故在這裡做一下分享,以備在其他的面試中被問到:-)。
因為電腦已經發明很久了,「不要重複發明輪子」也是一句大家耳熟能詳的古訓,我們已經習慣了編寫Print(“A”),就會在螢幕上顯示一個字元A的便利,認為這一切自然而然。而過程中需要哪些支援,發生了什麼,思考的人已經越來越少了。下面我們推理下在輪子還不那麼齊全的年代,如何實現一個顯示字元的「記事本」程式。
一、文本的存儲
.txt文件非常常見,當我們在windows桌面右鍵新建一個「文本文檔」,在其中輸入A之後保存,就在桌面形成了一個保存著A的文本文檔A。然後我們雙擊它打開,就會看到這個保存的A。
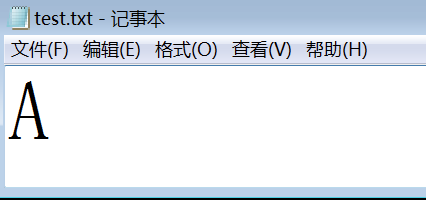
而學校里的課程告訴我們,電腦中存儲的都是0和1這種2進位數據,無法存儲「A」,那磁碟存儲的究竟是什麼?我們換另外一類工具來打開這個文本文檔,這類工具叫做16進位編輯器,這裡使用HxD編輯器。顯示如下內容。

這裡顯示了實際的存儲內容為一個位元組0x41,對應的文本是A。 這時我們在41這個位元組之後輸入一個位元組0x42,這時對應的文本顯示了B

保存後用記事本打開這個存儲了兩個位元組的文件,同樣會顯示AB,即我們通過輸入0x42的方式,輸入了字元B。

二、字符集
上面揭示了,我在記事本程式中輸入字元A後保存,存儲在磁碟文件的實際是數字0x41(對應二進位0100 0001),而如果我在16進位編輯器中直接追加一個0x42,則用記事本打開會顯示B。所以記事本程式一定有一個轉換功能,這個轉換規則可能是輸入一個字元A,則轉換存儲為0x41。反之讀取時,如果是0x41則顯示字元A,如果是0x42則顯示B,其實可以理解為一個保存編碼,顯示解碼過程。顯然字母有26個,算上大小寫可能有27個,再加上些加減乘除,愛心符號,所以我們需要全面的定義這種對應關係,對常用的字元定義完成後,可能會得到下面這樣一張表,就是傳說中的ascii字符集。
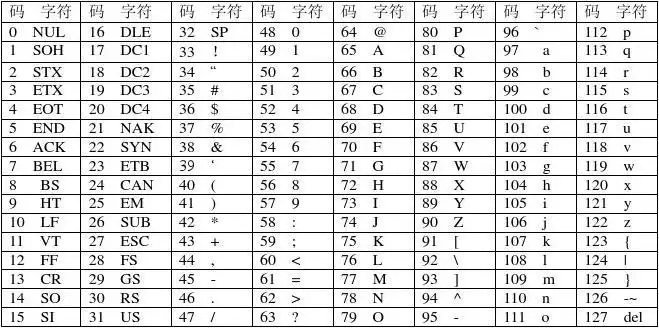
這張表定義了字元與電腦存儲二進位數據間的對應關係,因此要實現記事本程式,本質上是實現了一個將二進位與可見字元轉換的程式。當輸入字元時保存為二進位,當讀取二進位時,轉換為字元顯示。是不是看上去簡單的記事本比想像中的略複雜了些。但字符集是抽象的。所謂抽象是指定義了字元的編碼之後,仍然無法在螢幕上顯示出一個字元A。接下來需要考慮,要把一個字元A顯示在螢幕上,需要做哪些具體的工作。
三、字型檔(字體)
螢幕上顯示的A實際上是一個圖形,顯示A的過程,本質上是需要在螢幕上畫出一個形狀為A的圖形。並且A的寫法有很多種,如下面都是A。因此我們需要具體定義出當我們要顯示字元A的時候需要把A繪製成什麼樣子,當然還要同樣定義B,C,D等。

這個定義我可以硬編碼在我的「記事本程式」中,那這個定義就是一種私有的定義,保存的文件拿到其他的文本編輯器,就無法正確的顯示出我保存的A的樣子了。因為其他程式繪製A的方式也許不同。一個比較好的注意是把這個定義公開出來,定義一個標準格式,這樣大家都可能解析,編製這個定義字元形狀的文件,可以保證顯示的通用一致性,這個就叫做字體文件。實踐中字符集定義和字體文件的定義都是標準公開的,這樣系統內的程式都可以將相同的文件內容對應成相同的字元,如果願意,也使用相同的字體來顯示,保持風格的一致。
字元形狀(字體)的定義無疑包含至少包含兩個要素,這個字元的圖形和這個字元的索引編碼。程式需要繪製字元A的時候可以用編碼0x41,去字體文件搜索對應的字體定義,然後調用其他的繪圖API把A「畫」出來,繪圖API可以理解為一些比較底層的繪圖方法,實現類似將第一排第一列的像素點顯示為黑色這樣的功能,驅動顯示晶片在顯示器上繪圖。
字體是一種符合直覺的定義方式

按照定義將其繪製到對應螢幕像素點上,就形成了文字。當然問題是縮放可能會比較模糊,定義時可能會加入字型大小資訊,為不同的字型大小,定義一系列不同的像素點陣,改善顯示效果。高級的做法也容易想到,就是用數學描述的方式來定義文字,形成所謂矢量字體,優點可以無極縮放,缺點可能是需要繪製邏輯比較複雜,對資源佔用高。
四、亂碼的產生
有了以上的背景知識,推而廣之就容易想到亂碼是如何產生的了。亂碼的產生本質是由於「記事本」之類的程式,對文件的二進位內容無法正確轉換為字元進行繪製而產生。
如果全世界只存在ascii一種字符集則簡單的多。但因為世界範圍內的語言文字眾多,除了英文字母外,還有中文,希臘文,日文……。這些文字元號也有被電腦存儲顯示的要求,如中國會有顯示中文的需求,因此會存在眾多的字符集,通常是以國家區域推行,自己的事情自己操心嘛。於是可能存在這樣的定義。
如在某字符集編碼中約定(GBK編碼集)
兩個位元組 0xD6 0xD0 對應字元 「中」
我們使用了一個強大的支援中文編輯的「中文記事本」輸入了一個「中”保存了起來。 實際存儲內容為 0xD6 0xD0。 此時我們用上面那個「功能簡單的記事本」讀取顯示該文件,假設它只支援ascii編碼集, 那他會逐個位元組對文件內容進行處理顯示,讀取第一個位元組0xD6去ascii編碼集中尋找對應的字元進行顯示,之後讀取0xD0進行顯示,於是變成了下面這樣的所謂「亂碼」。由此可見,亂碼的原因,可能是對應了錯誤的字元,或者對應不可見字元,或者根本就不存在的字元如何處理顯示取決於程式自身的處理。

思考題:但為啥實際中的windows記事本是可以記錄中文的,為何它打開0xD6 0xD0 會知道是以GBK編碼保存的呢?:-)
當然很久很久之後,分久必合,自然而然產生了unicode編碼,即統一碼,可以以一套編碼編碼全世界所有的語言文字元號。避免了編碼各自(各國各民族)為戰的情況。
五、總結
- 電腦文件的存儲及網路傳輸都是基於二進位數據流進行的。
- 亂碼現象是由於輸入存儲(編碼)的字元編碼,與讀取顯示的編碼(解碼)不一致產生的。
- 需要用相同的字元編碼集進行 字元->二進位->字元 的轉換過程, 以避免亂碼問題的產生。
思考題:Java中遍地的String, 是如何在記憶體中存儲的呢?使用何種編碼呢?

