經典論文系列 | 目標檢測–CornerNet & 又名 anchor boxes的缺陷
- 2021 年 7 月 14 日
- 筆記
前言:
目標檢測的預測框經過了滑動窗口、selective search、RPN、anchor based等一系列生成方法的發展,到18年開始,開始流行anchor free系列,CornerNet算不上第一篇anchor free的論文,但anchor freee的流行卻是從CornerNet開始的,其中體現的一些思想仍值得學習。
看過公眾號以往論文解讀文章的讀者應該能感覺到,以往論文解讀中會有不少我自己的話來表述,文章寫得也很簡練。但這篇論文的寫作實在很好,以至於這篇解讀文章幾乎就是對論文的翻譯,幾乎沒有改動。
論文提出了 CornerNet,這是一種新的目標檢測方法,我們使用單個卷積神經網路將對象邊界框檢測為一對關鍵點,即左上角和右下角。 通過將對象檢測為成對的關鍵點,我們無需設計一組在先前單級檢測器中常用的錨框。 除了我們的新範式外,我們還引入了corner pooling,這是一種新型的池化層,可幫助網路更好地定位角點。
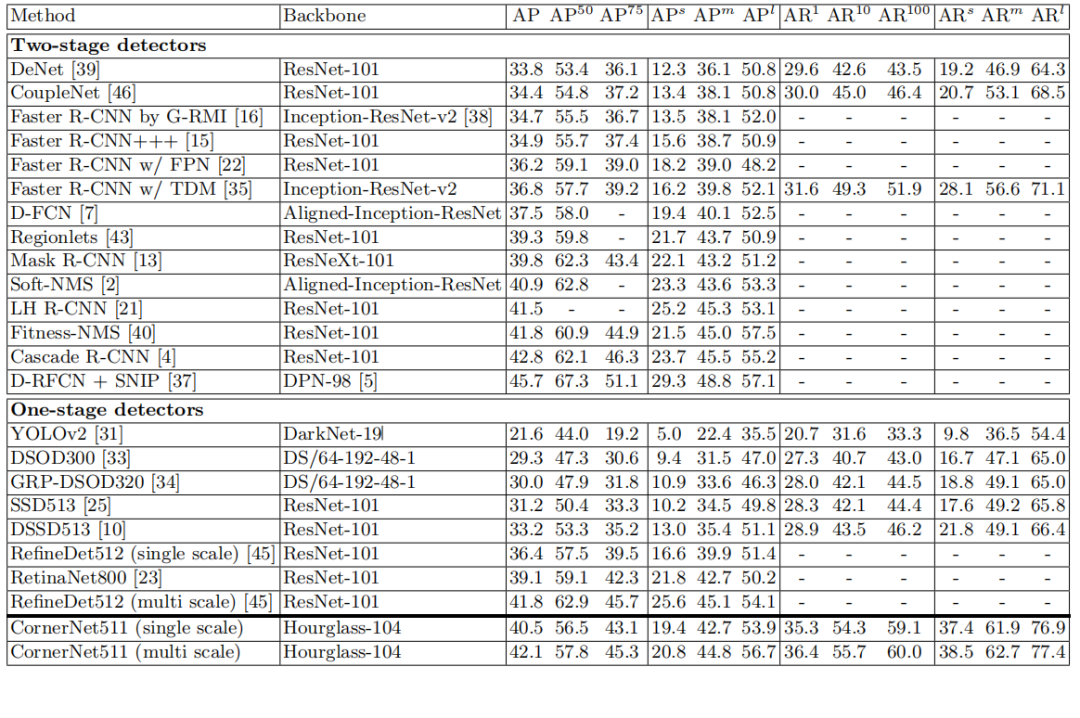
實驗表明,CornerNet 在 MS COCO 上實現了 42.1% 的 AP,優於所有現有的單級檢測器。
論文://arxiv.org/abs/1808.01244v2
程式碼://github.com/umichvl/CornerNet
關注公眾號CV技術指南,及時獲取更多電腦視覺的內容。
論文出發點|anchor box的缺陷
目標檢測中SOTA模型中一個常見組成部分是錨框,它是各種大小和縱橫比的框,用作檢測候選框。Anchor box廣泛應用於one-stage檢測器中,可以在效率更高的情況下獲得與two-stages檢測器極具競爭力的結果。one-stage檢測器將錨框密集地放置在影像上,並通過對錨框進行評分並通過回歸細化其坐標來生成最終的框預測。
但是使用錨框有兩個缺點。
首先,我們通常需要一組非常大的錨框,例如 在 DSSD 中超過 40k,在 RetinaNet 中超過 100k。這是因為檢測器被訓練來對每個錨框是否與一個ground truth框充分重疊進行分類,並且需要大量的anchor box來確保與大多數ground truth框有足夠的重疊。結果,只有一小部分錨框會與ground truth重疊; 這會造成正負錨框之間的巨大不平衡並減慢訓練速度。
其次,錨框的使用引入了許多超參數和設計選擇。 這些包括多少個box、多大scale和多大aspect ratios。 這種選擇主要是通過臨時啟發式進行的,當與多尺度體系結構相結合時會變得更加複雜,多尺度體系即單個網路在多個解析度下進行單獨預測,每個尺度使用不同的特徵和自己的一組錨框。
methods
受到 Newell 等人提出的關聯嵌入方法的啟發。誰在多人人體姿勢估計的背景下檢測和分組關鍵點。論文提出了 CornerNet,這是一種新的one-stage目標檢測方法,無需錨框。
我們將一個對象檢測為一對關鍵點——邊界框的左上角和右下角。我們使用單個卷積網路來預測同一對象類別的所有實例的左上角的熱圖、所有右下角的熱圖以及每個檢測到的角的嵌入向量。嵌入用於對屬於同一對象的一對角進行分組——網路經過訓練以預測它們的相似嵌入。
這種方法極大地簡化了網路的輸出並消除了設計錨框的需要。
下圖說明了方法的整體流程
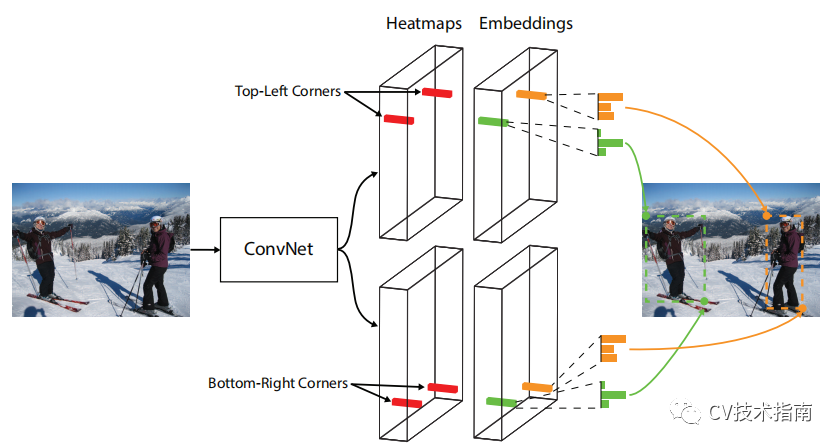
![]()
CornerNet 的另一個新穎組件是corner pooling,這是一種新型的池化層,可幫助卷積網路更好地定位邊界框的角點。 邊界框的角通常在對象之外——考慮圓形的情況以及下面圖(中)示例。

![]()
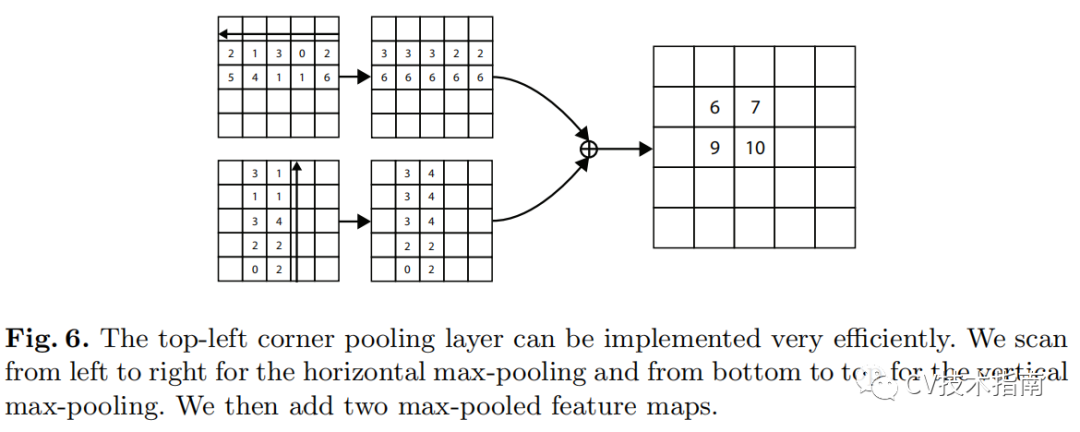
在這種情況下,不能基於局部證據來定位角。 相反,要確定像素位置是否有左上角,我們需要水平向右看對象的最上邊界,垂直向下看最左邊界。 基於這一點,我們提出了corner pooling。
它輸入兩個特徵圖; 在每個像素位置,它最大池化第一個特徵圖右側的所有特徵向量,最大池化第二個特徵圖正下方的所有特徵向量,然後將兩個合併的結果加在一起。
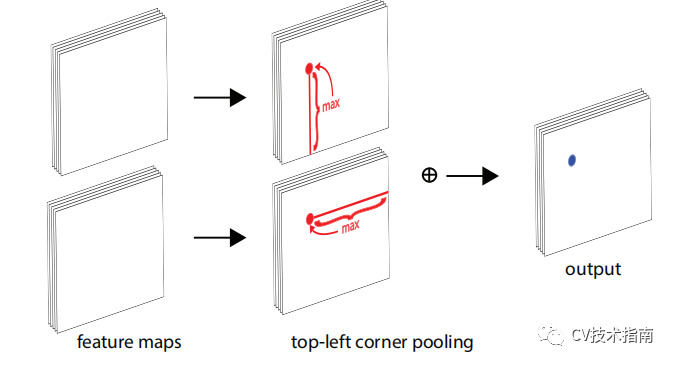
![]()
我們假設檢測角點比邊界框中心或提案更有效的兩個原因。 首先,一個box的中心可能更難定位,因為它取決於目標的所有 4 個邊,而定位一個角取決於 2 個邊,因此更容易,對於corner pooling更是如此,它編碼了一些關於角的定義的明確的先驗知識。 其次,角提供了一種更有效的方法來密集離散框的空間:我們只需要 O(wh) 個角來表示 O(wh)^2 個可能的錨框。
一些細節
![]()
![]()
整體實現
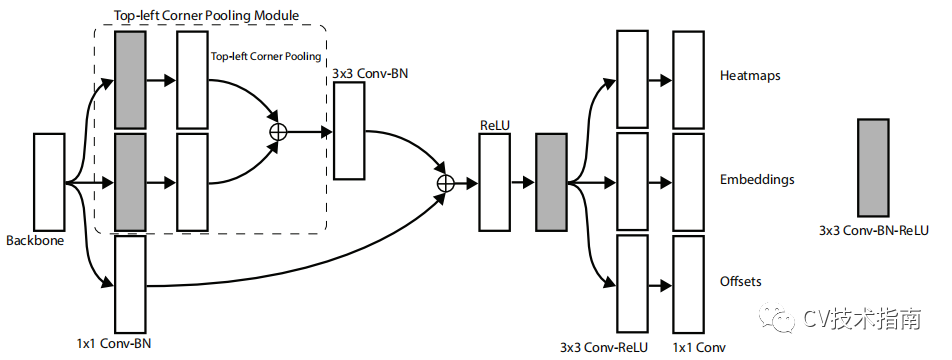
在 CornerNet 中,我們將一個對象檢測為一對關鍵點——邊界框的左上角和右下角。卷積網路預測兩組熱圖來表示不同對象類別的角的位置,一組用於左上角,另一組用於右下角。每組熱圖都有C個通道,C為類別數量(不含背景),每個通道是關於一個類別角點位置的二進位掩碼。
該網路還為每個檢測到的角點預測一個嵌入向量,使得來自同一對象的兩個角點的嵌入之間的距離很小。 為了產生更緊密的邊界框,網路還預測偏移量以稍微調整角的位置。 使用預測的熱圖、嵌入和偏移量,我們應用一個簡單的後處理演算法來獲得最終的邊界框。
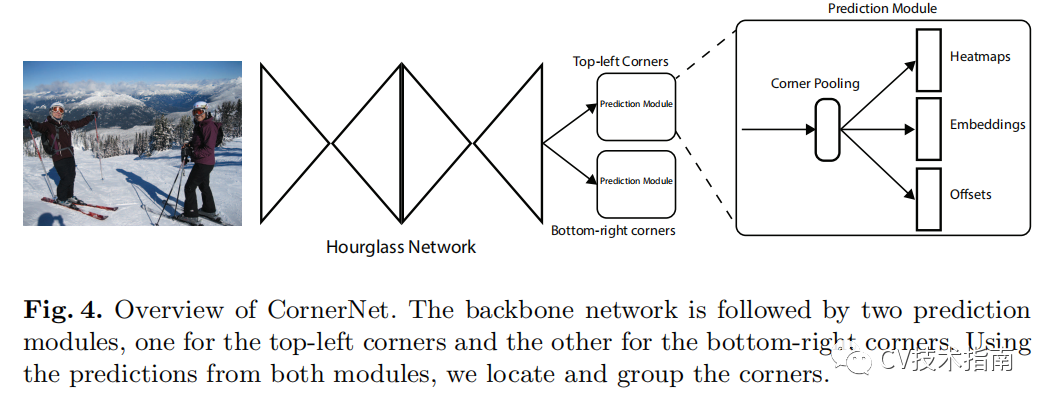
![]()
使用沙漏網路作為 CornerNet 的骨幹網路。沙漏網路之後是兩個預測模組。一個模組用於左上角,而另一個用於右下角。每個模組都有自己的corner pooling模組,用於在預測熱圖、嵌入和偏移之前從沙漏網路中池化特徵。 與許多其他目標檢測器不同,我們不使用不同尺度的特徵來檢測不同尺寸的物體。 我們只將這兩個模組應用於沙漏網路的輸出。
對於每個Corner,有一個ground truth正位置,所有其他位置都是負位置。 在訓練期間,我們不是對負位置進行同等懲罰,而是減少對正位置半徑內的負位置的懲罰。 這是因為一對錯誤的角點檢測,如果它們靠近各自的ground truth位置,仍然可以產生一個與ground truth框充分重疊的框。 我們通過對象的大小來確定半徑,方法是確保半徑內的一對點將生成一個具有至少 t IoU 的邊界框,並帶有ground truth標註。
Corners分組
使用「pull」損失訓練網路對角點進行分組,使用「push」損失來分離角點:
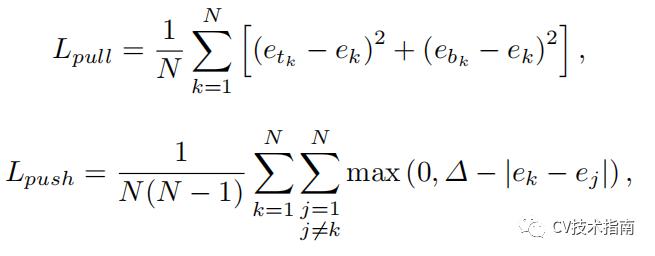
![]()
Corner Pooling
![]()
預測模組
![]()
沙漏網路
CornerNet 使用沙漏網路作為其骨幹網路。沙漏網路首先被引入用於人體姿勢估計任務。它是一個完全卷積的神經網路,由一個或多個沙漏模組組成。沙漏模組首先通過一系列卷積和最大池化層對輸入特徵進行下取樣。然後通過一系列上取樣和卷積層將特徵上取樣回原始解析度。由於最大池化層中的細節丟失,因此添加了跳過層以將細節帶回上取樣特徵。沙漏模組在單個統一結構中捕獲全局和局部特徵。當多個沙漏模組堆疊在網路中時,沙漏模組可以重新處理特徵以捕獲更高級別的資訊。這些特性也使沙漏網路成為目標檢測的理想選擇。事實上,目前很多檢測器已經採用了類似於沙漏網路的網路。
結論
實驗表明,CornerNet 在 MS COCO 上實現了 42.1% 的 AP,優於所有現有的單級檢測器。
![]()
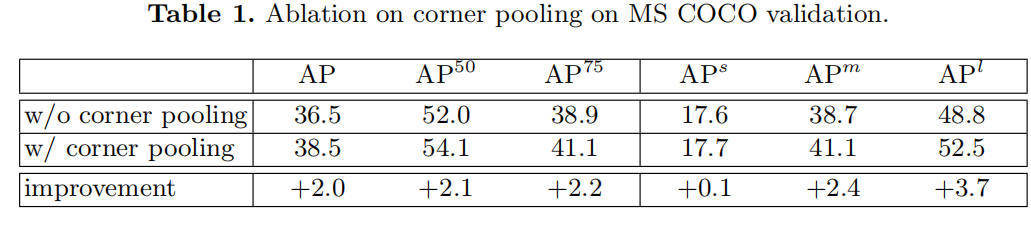
Corner Pooling的消融實驗
![]()
本文來源於公眾號 CV技術指南 的論文分享系列。
歡迎關注公眾號 CV技術指南 ,專註於電腦視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公眾號中回復關鍵字 「技術總結」 可獲取以下文章的匯總pdf。

其它文章
經典論文系列 | 目標檢測–CornerNet & 又名 anchor boxes的缺陷
在做演算法工程師的道路上,你掌握了什麼概念或技術使你感覺自我提升突飛猛進?


