擴展我們的分析處理服務(Smartly.io):使用 Citus 對 PostgreSQL 資料庫進行分片
- 2022 年 3 月 9 日
- 筆記

原文:Scaling Our Analytical Processing Service: Sharding a PostgreSQL Database with Citus
在線廣告商正在根據績效數據做出越來越多的決策。 無論是選擇要投資的受眾或創意,還是啟用廣告活動預算的演算法優化,決策越來越依賴於隨時可用的數據。 我們的開發團隊構建了強大的工具來幫助我們的客戶分析性能數據並做出更好的決策。
我們的解決方案由高度可訂製的報告組成,包括由我們自己的極其靈活的查詢語言提供支援的下鑽表和圖表。支援查詢語言的數據服務處理數 TB 的數據。除了作為我們面向用戶的分析工具的後端之外,它還為我們所有的自動優化功能和我們的一些內部 BI 系統提供支援。在這篇博文中,我將向您介紹我們如何通過對後端系統使用的資料庫進行分片來解決擴展問題。
海量資料庫等於擴展麻煩
我們的分析數據處理服務,稱為 Distillery,使用 PostgreSQL 資料庫。該服務將 JSON 格式的查詢安全地轉換為最終在資料庫級別運行的 SQL 查詢。大多數數據處理都發生在資料庫中,因此 Distillery 後端主要將我們自己的查詢語言轉換為 SQL 查詢。原始的 API 查詢很複雜,這使得一些生成的 SQL 查詢變得複雜,並使得它們對資料庫級別的要求很高。因此,當我們在報告系統的開發過程中遇到擴展問題時,我們並不感到驚訝。
過去,我們垂直擴展了我們的主副本資料庫架構,但後來很明顯我們已經達到了這種方法的極限。我們的資料庫在運行三年中積累了近 5TB 的數據,並且變得無法管理。大尺寸使得更新繁重的應用程式寫入速度變慢,維護任務難以執行。最後,最大的問題是我們的數據中心無法提供更大的伺服器。
解決方案:使用 Citus 分片 PostgreSQL 資料庫
當垂直擴展失敗時,我們不得不開始水平擴展我們的報告資料庫。這意味著我們需要在多個資料庫伺服器之間拆分數據和處理。我們還必須縮小包含每個單獨資料庫實例中統計數據的龐大資料庫表。
這種將資料庫數據切片成更小單元的方法稱為資料庫分片。我們的團隊決定使用 PostgreSQL Citus 插件來處理分片。這不是唯一的選擇 — 我們考慮使用自定義應用程式級分片,但決定使用 Citus 插件,因為:
- 我們有大量複雜的查詢,需要同時使用多個不同的分片。
Citus插件自動處理這些複雜的查詢並在分片之間分配處理。 - 它還廣泛支援我們運行複雜報告查詢所需的
PostgreSQL功能。 - 該擴展使分片管理相對容易,因此我們不必花費太多精力來管理單獨資料庫實例中的分片表。
Citus 基於 coordinator(協調器) 和 worker(工作器) PostgreSQL 資料庫實例。worker 持有資料庫表分片,coordinator 計劃 SQL 查詢,以便它們可以跨 worker 之間的多個分片表運行。 這允許將大型表分布在多個伺服器上,並分布到更小、更易於管理的資料庫表中。寫入較小的表更有效,因為資料庫索引維護成本降低。此外,寫入負載是並行化的,並在資料庫實例之間共享。Citus 解決了我們最大的兩個痛點:寫入效率低下和垂直擴展即將結束。
Citus 的資料庫分片帶來了額外的好處,因為新架構加速了我們的報告查詢。我們的一些查詢命中了多個 worker 實例和分片,Citus 擴展可以對其進行優化以在不同的資料庫實例中並行運行它們。 由於較小的表索引和更多資源可用於在單獨的 worker 中進行查詢處理,因此僅針對單個 worker 分片的查詢也會加快速度。
將大型資料庫和複雜的報告查詢遷移到這種類型的分片資料庫架構中絕非易事。它涉及仔細的準備和計劃,我們將在接下來進行研究。
遷移到新資料庫
過去,我們通過舊的 PHP 單體運行報告查詢。早在資料庫擴展問題出現之前,我們就開始使用 Ruby on Rails 構建更新的報告後端。在決定只在新後端處理 SQL 查詢遷移後,我們開始逐步淘汰舊後端。這使我們能夠專門針對 Citus 優化新的報告查詢。它使從應用程式級別的遷移更容易,因為我們只需遷移此服務即可與 Citus 分片 PostgreSQL 一起使用。
分片資料庫對資料庫模式有一定的要求。模式必須具有一個作為分片條件的值。分片邏輯使用此值來區分數據位於哪個分片上。 在 Citus-PostgreSQL 中,分片是使用表主鍵控制的。此複合主鍵包含一個或多個列,其中第一個定義的列用作分片值:
ALTER TABLE ad_stats ADD PRIMARY KEY (account_id, ad_id, date);
SELECT create_distributed_table('ad_stats', 'account_id'); -- Defines sharding for Citus cluster
這裡 account ID 列用作分片鍵,這意味著我們正在根據我們的客戶帳戶分配數據(單個客戶也可以有多個帳戶)。這意味著單個帳戶的數據位於單個表分片中。我們必須確保所有主鍵都採用這種格式,並且表中包含帳戶 ID 資訊。我們還必須更改一些外鍵和唯一性約束,因為它們還必須包含分片列。幸運的是,所有這些更改都可以安全地應用於正在運行的生產資料庫,而沒有任何性能或數據完整性問題,儘管我們不得不進行一些更廣泛的資料庫索引重建。
第二步是讓我們的報表後端生成的 SQL 查詢與分片資料庫兼容。首先,查詢必須包含 SQL WHERE 子句中的分片值。這意味著,例如,過濾器必須採用以下形式
SELECT * FROM campaigns WHERE account_id = 'xxx' AND name = 'yyy'
如果我們沒有 account_id 條件,Citus 分散式查詢計劃器將沒有資訊需要從哪個分片中找到相關行。從所有可能的分片中讀取不會像從單個分片中讀取那樣有效。
此外,Citus 對您可以在分片表之間執行的 JOIN 類型有一定的限制。通常 JOIN 要求分片列出現在 JOIN 條件中。例如,這將不起作用:
SELECT *
FROM
campaigns
LEFT JOIN ads ON campaigns.id = ads.campaign_id
WHERE
campaigns.account_id = 'xxx'
這將導致錯誤:
ERROR: cannot run outer join query if join is not on the partition column&
這意味著 SQL 外連接需要 Citus 無法從查詢中確定的表分片之間的一對一匹配。因此,查詢需要在 JOIN 條件中包含分片列,Citus 能夠從中檢測到 ads 表連接的範圍在一個分片內:
SELECT *
FROM
campaigns
LEFT JOIN ads ON campaigns.account_id = ads.account_id -- Use sharding column
AND campaigns.id = ads.campaign_id
WHERE
campaigns.account_id = 'xxx'
我們進行了各種其他 SQL 查詢優化,使 Citus 查詢規劃器能夠有效地運行我們複雜的統計報告查詢。 例如,我們使用通用表表達式 (CTE) 組織查詢,這允許 Citus 查詢計劃器為涉及同時讀取多個分片的繁重查詢選擇最佳計劃。 這些針對多個帳戶的查詢也在 Citus worker 集群中高度並行化,從而提高數據處理效率。 此外,我們還為 Citus 擴展做出了貢獻,增加了對 PostgreSQL JSON(B) 聚合的支援,我們的報告查詢將其用於某些數據預聚合步驟。您可以在 Github 中查看PR。
PR
運行中的新資料庫系統
我們的資料庫系統完全從單一主副本配置遷移到 coordinator + 4 個 worker 伺服器,每個伺服器都複製以實現高可用性。這意味著我們包含 5TB 數據的舊資料庫被分割成一個集群,其中每個資料庫伺服器保存大約 1TB 數據。Citus 允許我們相當容易地添加更多的 worker 伺服器,以便在公司繼續發展時將其進一步分割。我們還可以將擁有大量統計數據的最苛刻的客戶隔離到他們自己的資料庫伺服器上。
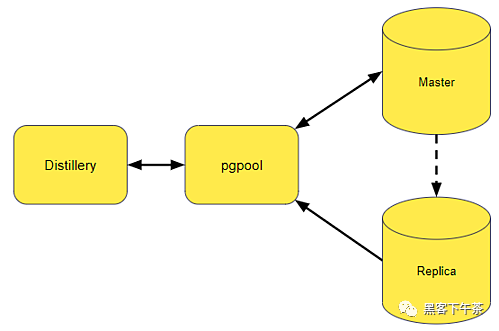
遷移前的資料庫架構。
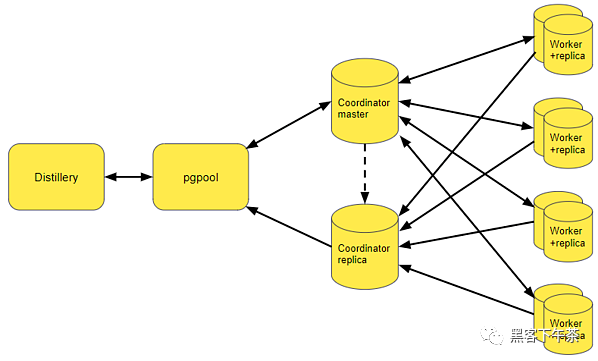
遷移後的資料庫架構。
上圖描繪了遷移前後的資料庫架構。與之前擁有 2 台大型資料庫伺服器的狀態相比,我們現在總共擁有 10 台資料庫伺服器。這些較小的資料庫實例更易於管理,因為大多數數據存在於單獨的資料庫工作伺服器中。協調器持有較少量的數據,例如一些元數據和對分片不敏感的數據。第二張圖還顯示了我們用來確保在一個資料庫實例出現故障時快速恢復的資料庫副本。這種從 primary master 伺服器到副本伺服器的故障轉移由 pgpool 組件處理。副本還共享來自主伺服器的一些讀取負載。
最後,我們在數據處理方面要求最高的數據透視表報告查詢從新資料庫系統中獲得了 2-10 倍的性能提升。 此功能生成的資料庫查詢非常複雜,因為我們允許用戶自由定義數據的分組、過濾和聚合方式。它還允許查詢跨分片自由運行,因為用戶可以定義任何帳戶組合。Citus 分片資料庫的好處真正體現在這些特定的查詢中。資料庫遷移非常必要,因為我們的舊資料庫基礎架構幾乎被它生成的複雜查詢所淹沒。
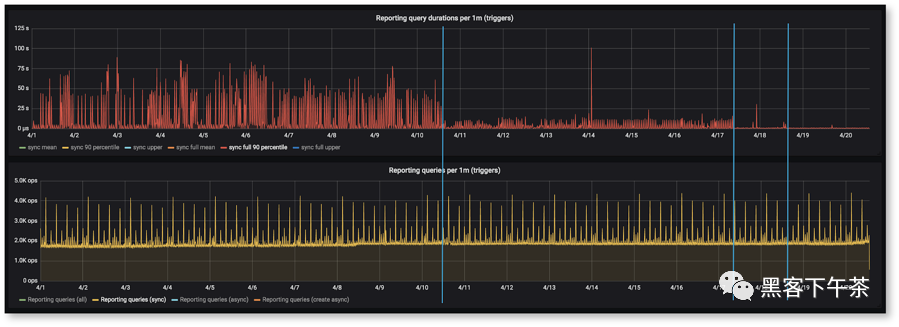
該圖顯示了在資料庫遷移項目期間,某些類型的查詢獲得性能提升的 90 個百分點的持續時間。

