JavaGuide–Java篇
本文避免重複造輪子,也是從JavaGuider中提取出來方便日後查閱的手冊
參考鏈接:
JavaGuider://javaguide.cn/java/basis/java-basic-questions-01/
🔥1.基礎概念與常識
1.1.Java語言特點
跨平台、面向對象(封裝繼承多態)、一次編寫到處運行、多執行緒可靠安全、編譯與解釋並存
1.2位元組碼與編譯和解釋並存
被編譯成.class後綴的文件就是位元組碼。而經過解釋器JIT第一次解釋後,後續熱點程式碼(頻繁使用的程式碼。消耗大部分系統資源的只有一小部分程式碼,這就是熱點程式碼)的位元組碼對應的機器碼就會被保存下來,然後每次程式碼執行的時候都會優化,這樣就會越來越快
1.3 字元常量和字元串常量區別
字元常量是單引號,佔一個位元組(但java中char是2個位元組),字元串常量是雙引號,占若干位元組
1.4 Java關鍵字
| 分類 | 關鍵字 | ||||||
|---|---|---|---|---|---|---|---|
| 訪問控制 | private | protected | public | ||||
| 類,方法和變數修飾符 | abstract | class | extends | final | implements | interface | native |
| new | static | strictfp | synchronized | transient | volatile | ||
| 程式控制 | break | continue | return | do | while | if | else |
| for | instanceof | switch | case | default | |||
| 錯誤處理 | try | catch | throw | throws | finally | ||
| 包相關 | import | package | |||||
| 基本類型 | boolean | byte | char | double | float | int | long |
| short | null | true | false | ||||
| 變數引用 | super | this | void | ||||
| 保留字 | goto | const |
1.5.泛型
Java泛型是偽泛型,即java運行期間所有類型擦除,數據類型被轉換成一個參數。比如:
-
泛型類:public Class Study
{} 實例化方式 Study genericInteger = new Study (123456); -
泛型介面:public interface Study
{} 實例化方式 class StudyImpl implements Study {} -
泛型方法:public static
void printArray(){E[] inputArray}
項目哪裡用到了泛型?
- 項目介面返回Result
參數的時候 - ExcelUtil
生成excel的時候 - 工具類Collections.sort這些地方
(註:個人覺得泛型適用性強,在和外部介面對接的時候,為防止外部參數類型經常變更,可以改成泛型。或者自己復用引用高的程式碼塊的時候,也可以把程式碼塊改成泛型。)
1.6. ==和equals(),HashCode()
==比較地址equals()比較對象,
HashCode是對堆上的對象產生獨特值(不唯一,因為因hash演算法也會產生不同對象相同hash值),如果重寫equals不重寫hashcode,那兩個相同對象也會有不同的hashcode
1.7 基本數據類型
這 8 種基本數據類型的默認值以及所佔空間的大小如下:
| 基本類型 | 位數 | 位元組 | 默認值 |
|---|---|---|---|
int |
32 | 4 | 0 |
short |
16 | 2 | 0 |
long |
64 | 8 | 0L |
byte |
8 | 1 | 0 |
char |
16 | 2 | ‘u0000’ |
float |
32 | 4 | 0f |
double |
64 | 8 | 0d |
boolean |
1 | false |
引用類型Byte,Short,IntegerLong創建了[-128,127]的快取,Character創建了[0,127]的快取
註:頻繁拆箱裝箱也非常影響系統性能
1.7 基本數據類型
序列化:數據結構或對象轉成二進位位元組流
反序列化:序列化生成的二進位轉成數據結構或對象
1.8 I/O操作
分為InputStream/Reader:位元組輸入流與字元輸入流
OutputStream/Writer:位元組輸出流與字元輸出流
1.9 I/O操作
反射:程式在運行時分析類和執行類方法的能力。(比如@Value就能在運行時給某個對象賦值,相比正射的set,get方法更靈活)
1.10 Java值傳遞
1.11 靜態代理與動態代理
靜態代理是由代理對象和目標對象實現一樣的介面
動態代理是利用反射機制在運行時創建代理類。
動態代理:JDK動態代理實現了介面的類或直接代理介面,而CGLIB可代理未實現任何介面的類。與基於Java位元組碼實現的Javassist
動態代理更靈活,不需要實現介面就可以代理實現類。靜態代理是在編譯時將介面、實現類、代理類生成.class文件
動態代理底層:反射
Proxy:生產代理實例
InvocationHandler:處理代理實例並返回結果
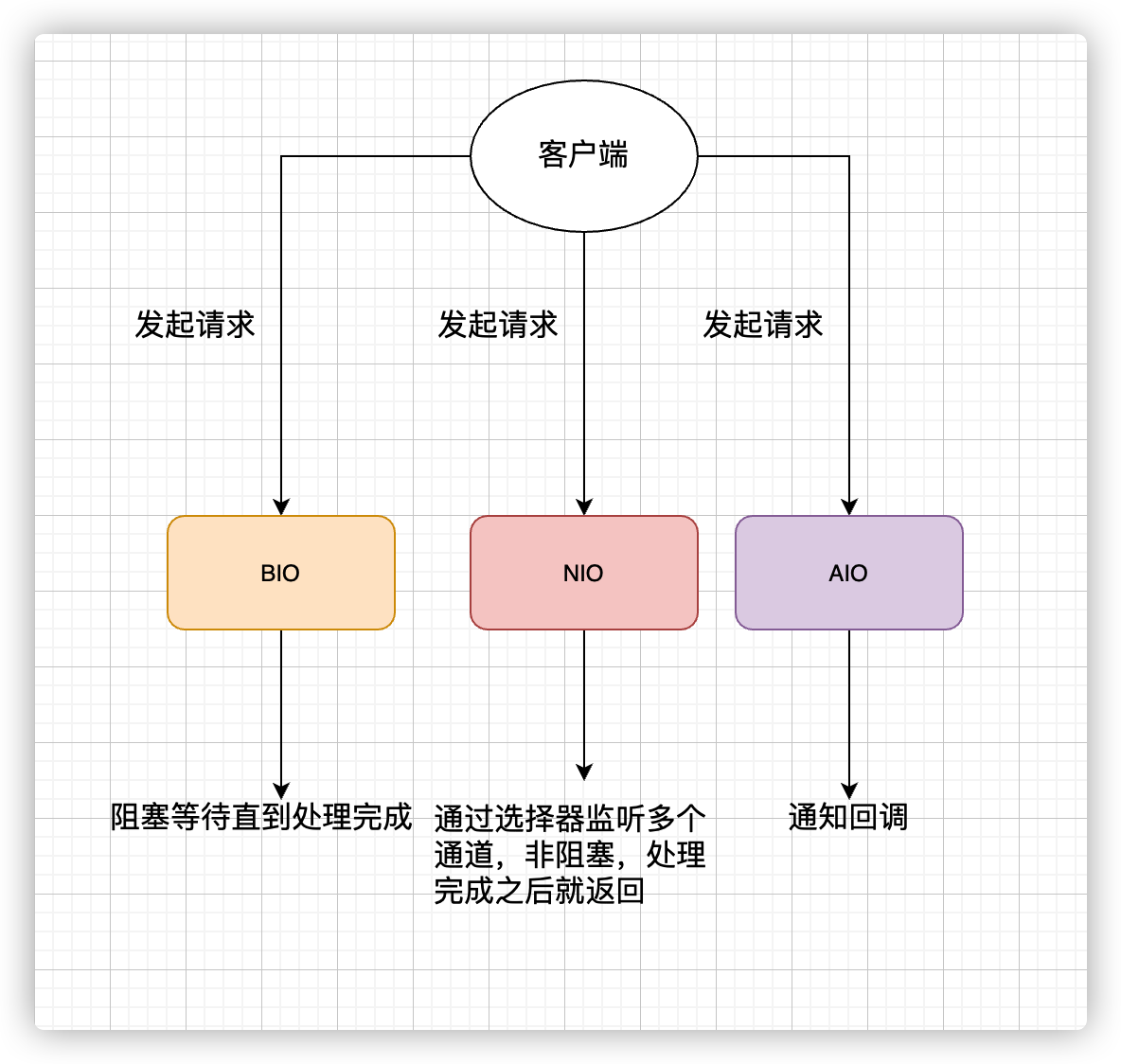
1.12 IO模型
同步阻塞IO:BIO
同步非阻塞IO:NIO
非同步IO:AIO
🔥2.容器
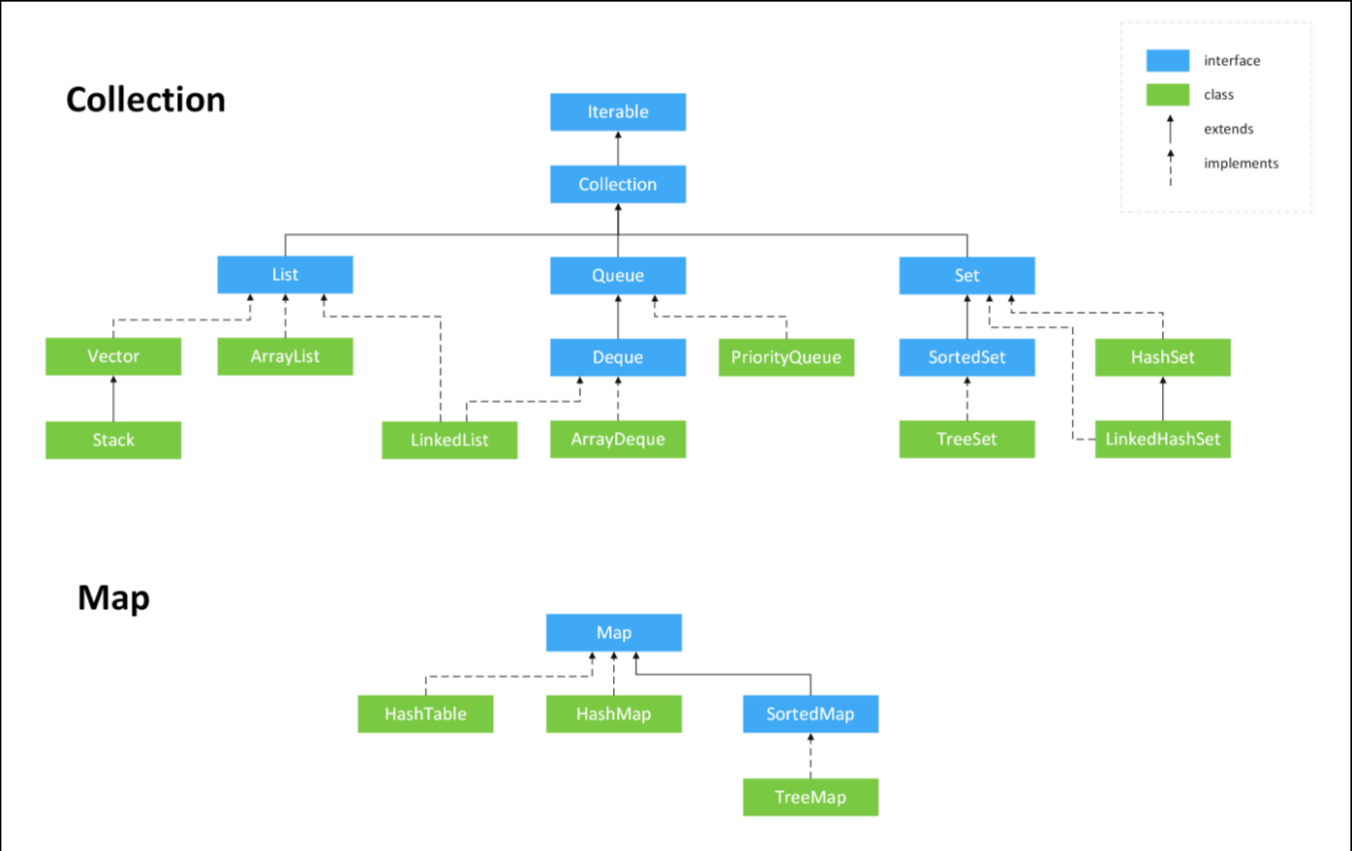
2.1.Java集合
Java集合:
1. Collection介面:list,queue,set
2. Map介面
2.2.==與 equals 的區別
對於基本類型來說,== 比較的是值是否相等;
對於引用類型來說,== 比較的是兩個引用是否指向同一個對象地址(兩者在記憶體中存放的地址(堆記憶體地址)是否指向同一個地方);
對於引用類型(包括包裝類型)來說,equals 如果沒有被重寫,對比它們的地址是否相等;如果 equals()方法被重寫(例如 String),則比較的是字元串值是否相等。
2.3 HashMap底層實現(JDK1.8前後)
JDK1.8 之前 HashMap 底層是 數組和鏈表 結合在一起使用也就是 鏈表散列。
JDK1.8之後HashMap 通過 key 的 hashCode 經過擾動函數處理過後得到 hash 值,然後通過 (n – 1) & hash 判斷當前元素存放的位置(這裡的 n 指的是數組的長度),如果當前位置存在元素的話,就判斷該元素與要存入的元素的 hash 值以及 key 是否相同,如果相同的話,直接覆蓋,不相同就通過拉鏈法解決衝突。
(put邏輯:如果定位到的數組位置沒有元素 就直接插入。
如果定位到的數組位置有元素就和要插入的 key 比較,如果 key 相同就直接覆蓋,如果 key 不相同,就判斷 p 是否是一個樹節點,如果是就調用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)將元素添加進入。如果不是就遍歷鏈表插入(插入的是鏈表尾部)。)
相比於之前的版本, JDK1.8 之後在解決哈希衝突時有了較大的變化,當鏈表長度大於閾值(默認為 8)(將鏈錶轉換成紅黑樹前會判斷,如果當前數組的長度小於 64,那麼會選擇先進行數組擴容,而不是轉換為紅黑樹)時,將鏈錶轉化為紅黑樹,以減少搜索時間。
2.4 ConcurrentHashmap底層原理
JDK1.8之後ConcurrentHashMap 取消了 Segment 分段鎖,採用 CAS 和 synchronized 來保證並發安全。數據結構跟 HashMap1.8 的結構類似,數組+鏈表/紅黑二叉樹。Java 8 在鏈表長度超過一定閾值(8)時將鏈表(定址時間複雜度為 O(N))轉換為紅黑樹(定址時間複雜度為 O(log(N)))
synchronized 只鎖定當前鏈表或紅黑二叉樹的首節點,這樣只要 hash 不衝突,就不會產生並發,效率又提升 N 倍
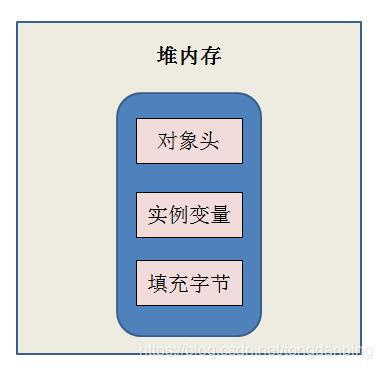
2.6 Synchronized的升降級
對象分為對象頭(MarkWord)、實例變數、填充位元組。
鎖的4中狀態:無鎖狀態、偏向鎖狀態(弄人開啟)、輕量級鎖狀態、重量級鎖狀態(級別從低到高)
Java8 中的 ConcurrentHashMap 使用的 Synchronized 鎖加 CAS 的機制。結構也由 Java7 中的 Segment 數組 + HashEntry 數組 + 鏈表 進化成了 Node 數組 + 鏈表 / 紅黑樹,Node 是類似於一個 HashEntry 的結構。它的衝突再達到一定大小時會轉化成紅黑樹,在衝突小於一定數量時又退回鏈表。
🔥3.並發編程
3.1.進程與執行緒
進程:啟動一個程式(啟動main函數就是啟動了一個jvm進程),而main函數的的執行緒就是這個進程中的一部分
多個執行緒共享記憶體中的堆與方法區,但是各個執行緒又有自己的虛擬機棧、本地方法棧、程式計數器。

3.2.上下文切換
執行緒會有主動阻塞(Sleep,wait)讓出CPU、時間片用完、IO阻塞等執行緒切換情況,這時需要保留現場方便後續CPU調用,同時載入下一次執行緒用CPU的上下文,這就叫上下文切換。
3.3 Sleep與wait區別
Sleep沒有釋放鎖,會自動喚醒,而wait釋放了鎖,必須要notify/notifyall喚醒
3.4 start與run
start啟動執行緒做了執行緒準備工作後調用run方法並讓執行緒進入就緒狀態,CPU分配了時間片後就可以開始執行,而run方法並不會在某個執行緒中執行,不屬於多執行緒。
3.5 Synchronized關鍵字
掛起或喚醒一個執行緒,都需要OS操作用戶態到核心態的轉換,這個過程非常耗時。
Synchronized作用域
- 修飾實例方法:作用於對象實例
- 修飾靜態方法,作用於類.class
- 修飾程式碼塊,作用域對象的鎖(this,OBject)或類的鎖(類.calss)
3.6 其他參數
以下內容見《JUC並發編程》
volatile(非執行緒安全)
ThreadLocal(執行緒本地變數)
執行緒池(三大方法、七大參數,四種拒絕策略)
3.7 AQS
簡介:是juc下具體類
核心原理:多執行緒情況下,空閑的共享資源加鎖,非空閑的共享資源使用CLH隊列鎖(內部是虛擬的雙向隊列,FIFO)進行執行緒隊列等待與喚醒的鎖分配策略
定義資源的共享方式:
1. Exclusive(獨佔):Reentranlock,synchronized
2. Share(共享):Countdownlatch,semaphore,cyclicBarrier,readwriteLock
3.8 補充
this逃逸:構造函數返回之前其他執行緒就持有該對象引用,其他執行緒調用尚未構造完全的對象方法引發錯誤
🔥4.JVM
4.1 JVM記憶體區域詳解
4.1.0 JVM記憶體區域
1. PC程式計數器:執行緒中的訊號指示器,用於用來讀取下一條指令功能。、
2. Java虛擬機棧:包含一個個棧幀(局部變數表等等,局部變數表又包含8個基本數據類型(),對象應用)
3. 本地方法棧:虛擬機棧為java服務,本地方法棧為虛擬機用到的Native服務(也有本地方法的局部變數表等待)
4. 堆:存放分配幾乎所有對象實例與數組記憶體、**字元串常量池、靜態變數(jdk1.8之後)**
1. 字元串常量池:存放"asd" + "abc"(**常量摺疊**)
5. 方法區:存儲已被虛擬機載入的類資訊(類如何放入方法區,reference如何指向就是這裡)、常量。**方法區和永久代的關係很像 Java 中介面和類的關係**
1. 運行時常量池:類的版本、欄位、方法、介面等描述資訊外,還有常量池表(類的相關資訊)
2. **jdk1.8之後是把永久代實現方法區方式換成了元空間實現方式**
6. 直接記憶體(堆外記憶體):NIO
4.1.1對象的創建
Java對象創建分如下5步:
- 類載入檢查:遇到new 指令時,進行類的檢查與載入。
- 分配記憶體:在堆中分配記憶體,有指針碰撞與空閑列表2種分配方式。Java堆是否規整由垃圾回收演算法決定。


保證記憶體分配的執行緒安全:
CAS+失敗重試: CAS 是樂觀鎖的一種實現方式。所謂樂觀鎖就是,每次不加鎖而是假設沒有衝突而去完成某項操作,如果因為衝突失敗就重試,直到成功為止。虛擬機採用 CAS 配上失敗重試的方式保證更新操作的原子性。
TLAB: 為每一個執行緒預先在 Eden 區分配一塊兒記憶體,JVM 在給執行緒中的對象分配記憶體時,首先在 TLAB 分配,當對象大於 TLAB 中的剩餘記憶體或 TLAB 的記憶體已用盡時,再採用上述的 CAS 進行記憶體分配
- 初始化零值:給每個new 對象有初始化值
- 設置對象頭:markword
- 執行init方法:按照程式碼進行init,比如定義數組大小。上述可以說只是定義分配了記憶體位置,這裡根據init定義具體大小。
new ArrayList<>(3);
4.1.2 對象訪問
- 句柄訪問:Java棧的本地變數表訪問堆中的句柄池中的實例對象指針(類似於作業系統中的虛擬地址表),然後訪問堆或者方法區中的實例對象。缺點就是多訪問了一次指針定位實例數據的時間。
- 直接指針:Java棧的本地變數表存的就是直接訪問堆中的實例對象的地址。訪問方法區就是堆中存了實例對象地址。缺點就是後續垃圾回收移動對象地址的時候,需要改變棧中的本地變數表。
// 上面說了new ArrayList<3>,這裡說的2種方法就是一整條語句了。
List<Integer> list = new ArrayList<>(3);
4.2 JVM垃圾回收詳解
4.2.1 Jvm垃圾回收相關問題
註:JVM垃圾回收在於執行緒共享區域:即堆、方法區(已被虛擬機載入的靜態變數、常量等程式碼與運行時常量池)
下面介紹JVM垃圾回收具體流程:

4.2.2 對象是否死亡
1.如何判斷對象是否死亡:引用計數器與可達性演算法
2.指向對象的引用:強引用,軟引用,弱引用,幻想引用(虛引用)
目前尚有一個疑問?
目前垃圾回收器普遍都是分代回收演算法,但是又說JDK1.8是默認採用Parallel scavenge+Serial Old收集器,但這2個收集器並不是GC演算法,是否衝突?
答:相當於所有垃圾回收器都默認使用了分代回收演算法
4.2.3. 垃圾回收(演算法與工具)
垃圾回收演算法:
1. Mark-sweep(標記-清除 MS演算法):標記全部堆中可回收資源進行回收
2. Copying(複製 CP演算法):堆記憶體分成2半,一半用完了複製並整理整齊到另一半上,然後把這一半清空。
3. Mark-Compact(標記-整理 MC演算法):MS與CP結合,將全部堆內容標記,然後整理整齊清空。
4. Generation Collection(分代收集 GC演算法):根據對象存活周期將記憶體分為新生代與老生代進行收集。垃圾收集器:
1. Serial Old收集器:MC演算法
2. ParNew收集器:Serial的多執行緒版本,MC演算法
3. Parallel Scavenge:Cp演算法
4. Parallel Old:MC演算法
5. CMS:MS演算法
6. G1:MS演算法
4.3 類文件結構、類載入過程(略)
4.4 JVM性能調優(待續)
能力有限,暫時用不到這些,後面用到了進一步了解。
學習鏈接://javaguide.cn/java/jvm/jvm-parameters-intro/#_3-2-gc記錄
4.5 JVM排查命令
參考命令://javaguide.cn/java/jvm/jdk-monitoring-and-troubleshooting-tools/#jps-查看所有-java-進程
註:Jdk1.8默認採用Parallel Scavenge(新生代) + Serial Old(老年代)
🔥5.新特性
5.1 Java8新特性實戰、《Java8指南》、JDK9~15、小技巧(略)
權當手冊查了。
書山有路勤為徑,學海無涯苦作舟。程式設計師不僅要懂程式碼,更要懂生活,關注我,一起進步。



