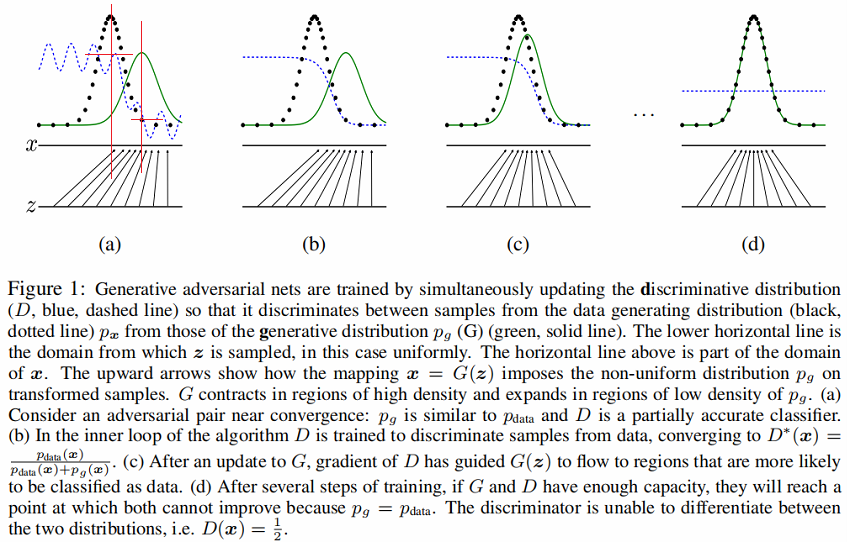
【《白話機器學習的數學》筆記1】回歸
【《白話機器學習的數學》筆記1】回歸
部落格園的顯示效果不是很好,推薦去我的GitHub或這個網站(其實就是個可以渲染GitHub上的notebook的網站,nbviewer.org)查看notebook筆記
基於《白話機器學習的數學》這本書中關於回歸的理論知識,準備自己動手利用程式碼實現一波,來一次真正地從源頭上的入門!(所有的應用案例都是貼合書中的內容的,比如現在這裡講回歸,所說的案例就是 利用廣告費來預測點擊量,那麼我接下來就通過程式碼來進行實現。)
回歸,常用於對連續數據的預測問題
簡單回歸
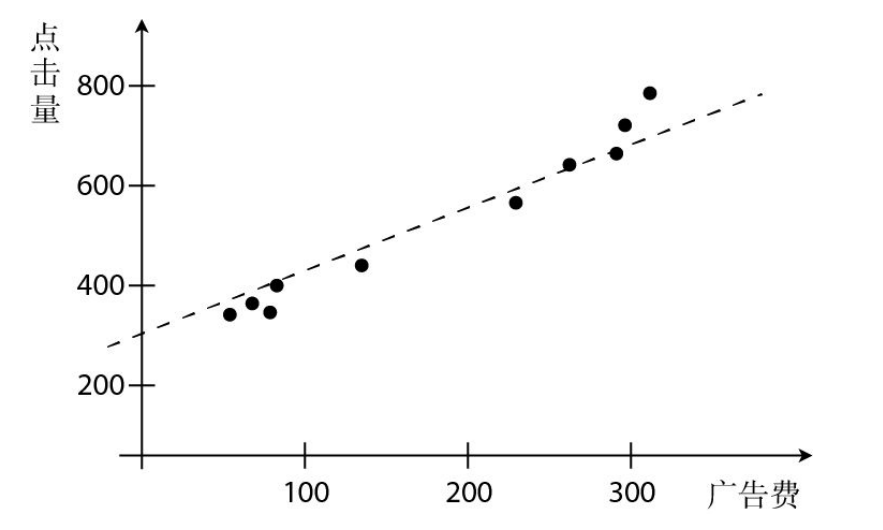
首先,在書中說到的是利用網站的廣告費與點擊量之間的關係進行的一次簡單的預測,即通過點擊量預測廣告費。
這樣的一次函數影像,我們在數學中一般都寫為$y=ax+b$,但這裡我們更加通用的是使用$\theta_{i}$來表示,即$y=\theta_{1}x+\theta_{0}$來定義我們的一次函數表達式。
我們所要做的就是去確定$\theta_{i}$的值,從而讓得到的直線儘可能地多過點。
# 導入matplotlib繪圖
import matplotlib.pyplot as plt
# 設置下面兩行,以正常顯示中文
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 模擬一些數據
data = [(60,320),(70,330),(78,323),(140,396),(150,410),(200,450),(236,510),(280,580),(300,600),(310,630)]
# 廣告費
ad_fee = [item[0] for item in data]
# 點擊量
click = [item[1] for item in data]
ad_fee,click
([60, 70, 78, 140, 150, 200, 236, 280, 300, 310],
[320, 330, 323, 396, 410, 450, 510, 580, 600, 630])
# 繪製影像
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_xlabel("廣告費")
ax.set_ylabel("點擊量")
ax.scatter(ad_fee,click)
plt.show()
"""
定義擬合函數,這裡先隨機選定下參數
(這裡一般把參數稱之為權值)
"""
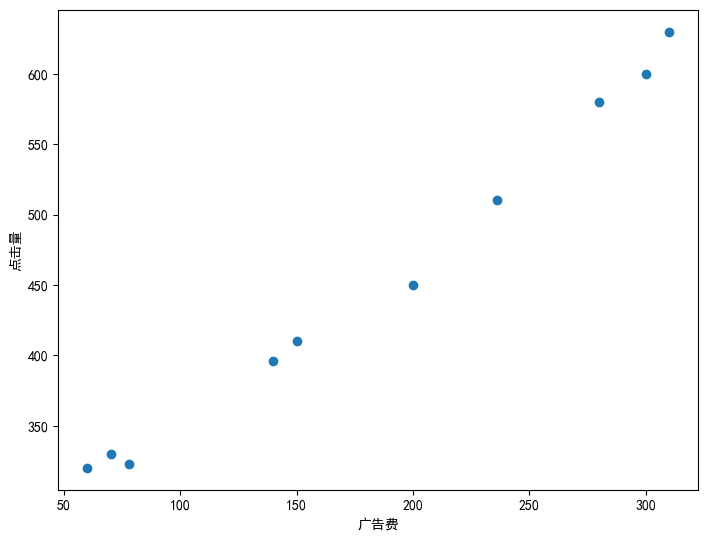
theta_1 = 2
theta_0 = 1
# 確定表達式
pred_y = [theta_1*x+theta_0 for x in ad_fee]
pred_y
[121, 141, 157, 281, 301, 401, 473, 561, 601, 621]
# 繪製影像
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_xlabel("廣告費")
ax.set_ylabel("點擊量")
ax.scatter(ad_fee,click)
ax.plot(ad_fee,pred_y)
plt.show()
可以看到這裡隨機定的直線並沒有能夠儘可能過多的點,那麼我們要怎麼樣才能夠得到更優的直線呢?這裡就要引出我們的目標函數了——$E(\theta)=\frac{1}{2}\sum (y-y_{\theta})^{2} $,這裡E其實表示的是ERROR,得到的$E(\theta)$是與真實值的差距。(這裡並沒有說為什麼不直接使用預測值與真實值的差值來估計誤差,或者預測值與真實值的差值的絕對值來估計,可以思考一下,書中有詳細解答。)
註:其實上面所說的$E(\theta)$就是最小二乘法,最小二乘法廣泛應用於誤差估計,通過最小化誤差的平方和來尋找數據的最佳函數匹配
這裡可以先用之前隨便定的參數來看一下$E(\theta)$的值
E = sum([(click[i]-pred_y[i])**2 for i in range(len(click))])/2
E
66098.5
66098.5,可以看到誤差很大,因此需要調整$\theta_{i}$,獲取最佳的函數。這裡的調整當然並不是一直隨機選,先明確下我們的目的是什麼?
我們要做的就是最小化誤差,讓$E(\theta)$儘可能的小。所以求最小值,這裡可以引出我們的極值(當然,極值並不一定是最值,但對於我們這裡的二次拋物線來說,並不需要考慮這麼多)。
OK,知道了要求極值,首先想到的一定是求導,找一階導為0的點吧。但是,我們需要知道並不是所有的函數都能夠直接求出一階導為0的點。可以類比下牛頓法求解方程,我們沒有辦法直接求出方程的解,但是可以通過迭代的方式不斷地逼近我們的解。
那麼問題又來了,要怎樣迭代得到所需的解呢?這裡就需要了解梯度下降法,在微分學中我們都知道梯度的方向變化速度最快,而梯度相反的方向則是函數值下降最快的方向。這裡$E(\theta)$的未知數是$\theta$,因此,我們要做的就是讓$\theta$沿著梯度下降的方向走就可以了。
我們知道,在極小值點的左側是遞減的,右側是遞增的,也就是說左側的導數值小於0,右側的導數值大於0。所以,我們只需要加上當前導數值的相反數就可以往極小值的方向移動了,即根據導數的符號來決定移動的方向。
$$
x=x-\eta d\frac{g(x)}{dx}
$$
其中的$\eta$是學習率,可以認為是每次值更新的一個跨度,跨的太大和跨的太大都不太好,因此需要選擇一個比較合適的大小。$g(x)$對$x$的求導在這裡則是$E(\theta)$對$\theta$的求導,但因為我們這裡有$\theta_{0}$和$\theta_{1}$兩個變數,所以需要求偏導,其實步驟都是一樣的,就算一個變成了算兩個。
- 對$y_{\theta}$求導
$$
-\sum (y-y_{\theta})
$$ - 對$\theta_{0}$和$\theta_{1}$求導($y_{\theta} = \theta_{1}x+\theta_{0}$)
$$
對\theta_{0}求導 : -\sum (y-y_{\theta})1
$$
$$
對\theta_{1}求導 : -\sum (y-y_{\theta})x
$$ - 更新$\theta_{0}$和$\theta_{1}$
$$
\theta_{0} = \theta_{0}-\eta \sum [(y_{\theta}-y)1]
$$
$$
\theta_{1} = \theta_{1}-\eta \sum [(y_{\theta}-y)x]
$$
注意:這裡的$x$和$y$是樣本點,是已知的。這裡的自變數是$\theta_{0}$和$\theta_{1}$,因變數是$y_{\theta}$。
# 隨機設置參數(這裡重新設置一下,方便後面每次調整,就不用老是往上翻)
theta_0 = 1
theta_1 = 2
# 設置學習率,這裡學習率的設置還是要多調一下的,其實個人覺得可以分別給theta_0和theta_1設置學習率,因為兩個參數的變化幅度不太一樣
learning_rate = 0.000001
# 迭代次數
n = 1000000
# 重新設置pred_y
pred_y = [theta_1*x+theta_0 for x in ad_fee]
# 列印測試
pred_y
[121, 141, 157, 281, 301, 401, 473, 561, 601, 621]
# 測試
sum([(pred_y[i]-click[i])*1 for i in range(len(pred_y))])
-891
# 迭代更新theta_0,theta_1
for i in range(n):
theta_0 = theta_0 - learning_rate*sum([(pred_y[i]-click[i])*1 for i in range(len(pred_y))])
theta_1 = theta_1 - learning_rate*sum([(pred_y[i]-click[i])*ad_fee[i] for i in range(len(pred_y))])
# 更新預測值,其實也就是對pred_y中的theta_0和theta_1進行更新
pred_y = [theta_1*x+theta_0 for x in ad_fee]
# print(theta_0,theta_1)
# print(pred_y)
# 繪製更新後的影像
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.scatter(ad_fee,click)
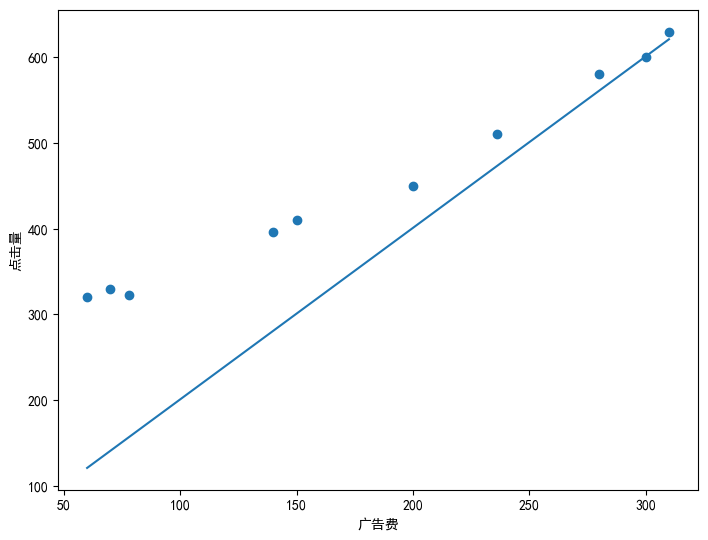
ax.plot(ad_fee,pred_y)
plt.show()
# 列印更新後的參數
print(f"theta_0:{theta_0} , theta_1:{theta_1}")

theta_0:201.55686898237883 , theta_1:1.3549571632210207
# 可以對比一下訓練前和訓練後的影像
fig = plt.figure()
# 原圖
ax1 = fig.add_axes([0,0,0.5,0.5])
ax1.scatter(ad_fee,click)
ax1.plot(ad_fee,[2*x+1 for x in ad_fee])
ax1.set_title("原圖")
# 更新後
ax2 = fig.add_axes([0.6,0,0.5,0.5])
ax2.scatter(ad_fee,click)
ax2.plot(ad_fee,pred_y)
ax2.set_title("更新後的圖")
# 顯示影像
plt.show()
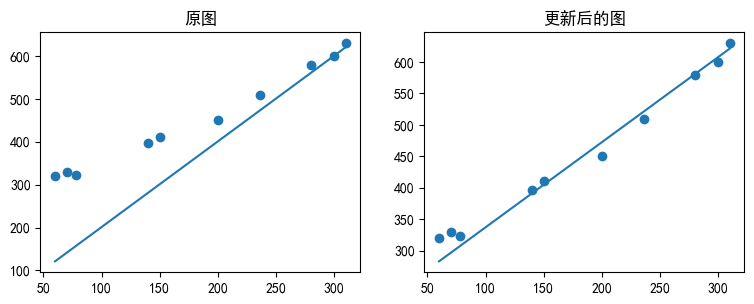
可以看到和之前相比,使用新的參數得到的直線比之前要好很多。我們可以來看一下現在的$E(\theta)$是多少,也就是誤差。
#計算誤差
E = sum([(click[i]-pred_y[i])**2 for i in range(len(click))])/2
E
1789.6736022830057
可以看到這裡比原來的誤差要小了很多,這樣我們就可以利用現在的直線來進行預測了。比如,假設現在廣告費增到500,那麼應該可以得到的點擊量應該是
theta_1*500+theta_0
879.0354505928892
也就是說若廣告費到500的話,那麼點擊量應該會到880左右。
當然,雖然現在比一開始要好很多了,但是還是有差距。那麼要怎麼樣進一步地去縮小差距呢?接下來進入多項式回歸
多項式回歸
剛剛使用的是一次函數$y=\theta_{1}x+\theta_{0}$,也就是直線來進行逼近的。現在,我們可以使用曲線來逼近,二次函數甚至三次、n次函數進行擬合。
$$
f_{\theta}(x) = \theta_{2}x^{2}+\theta_{1}x+\theta_{0}
$$
$$
f_{\theta}(x) = \theta_{n}x{n}+…+\theta_{2}x{2}+\theta_{1}x+\theta_{0}
$$
但需要知道的是,雖然越高次的多項式越擬合的更好,但是這就會出現過擬合的情況,導致對訓練樣本的預測很准,但是對驗證樣本的效果不佳,也就是模型的泛化能力不行。
這裡我們可以用二次多項式再來試一次!
$$
\theta_{0} = \theta_{0}-\sum [(y_{\theta}-y)1]
$$
$$
\theta_{1} = \theta_{1}-\sum [(y_{\theta}-y)x]
$$
$$
\theta_{2} = \theta_{2}-\sum [(y_{\theta}-y)*x^{2}]
$$
# 定義參數
theta_0 = 239.66
theta_1 = 1.02
theta_2 = 0.00062
# 設置學習率
learning_rate = 0.000001
# 迭代次數
n = 1600000
print([theta_2*x**2+theta_1*x+theta_0 for x in ad_fee])
# 更新參數
for i in range(n):
pred_y = [theta_2*x**2+theta_1*x+theta_0 for x in ad_fee]
theta_0 = theta_0 - learning_rate*sum([(pred_y[i]-click[i])*1 for i in range(len(pred_y))])
# print([(pred_y[i]-click[i])*1 for i in range(len(pred_y))]) 傻逼了,搞了半天,忘記乘學習率了,就說怎麼一直這麼大
theta_1 = theta_1 - learning_rate*sum([(pred_y[i]-click[i])*ad_fee[i] for i in range(len(pred_y))])
theta_2 = theta_2 - learning_rate*0.00001*sum([(pred_y[i]-click[i])*ad_fee[i]**2 for i in range(len(pred_y))])
pred_y = [theta_2*x**2+theta_1*x+theta_0 for x in ad_fee]
# 列印更新後的參數
print(f"theta_0:{theta_0} theta_1:{theta_1} theta_2:{theta_2}")
# 繪製影像
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.scatter(ad_fee,click)
ax.plot(ad_fee,pred_y)
plt.show()
[303.092, 314.098, 322.99208, 394.61199999999997, 406.61, 468.46000000000004, 514.91152, 573.868, 601.46, 615.442]
theta_0:259.6565186661426 theta_1:0.7812284302914565 theta_2:0.001244416554768104

E = sum([(click[i]-pred_y[i])**2 for i in range(len(pred_y))])/2
E
307.59714460729487
看比之前的1700多更低了,我們成功實現了從66000多的誤差到1700多,到現在的300多,大飛躍!
不過我們通常會使用的是MSE(Mean Square Error),即均分誤差來衡量回歸模型的精度,其實就是上面的Error這個目標函數除2改成除n,來求平方和的平均值,至於之前為什麼除2,其實只是為了就導方便而已(二次方求導會下來一個2,所以除以一個2恰好抵消。)
MSE = sum([(click[i]-pred_y[i])**2 for i in range(len(pred_y))])/len(pred_y)
MSE
61.519428921458974
多重回歸
前面使用到的都是單一的自變數,即廣告費來決定點擊量,但現實中當然不止這一個因素影響著點擊量,比如廣告位的位置,顯示的時間段等都會對點擊量有所影響。因此,這個時候有會個多個自變數($x_{1},x_{2}…x_{n}$),不過其實和一個自變數的時候是一樣的,仍然把這些視為樣本點,只是現在不是二維的因此無法直接通過影像表示出來,但我們索要做的事情並沒有變:
- 構建目標函數
目標函數仍然可以使用最小二乘法,使用$E(\theta)=\frac{1}{2}(y-y_{\theta})^{2}$,其中不同的只是$y_{\theta}$發生了變化,例如一次多項式可以是:$y_{\theta}=\theta_{n}x_{n}+…+\theta_{2}x_{2}+\theta_{1}x_{1}+\theta_{0}$
這裡為了簡化,其實可以將x和$\theta$表示為向量的形式:
$$
x = \begin{bmatrix} 1 \ x_{1} \ x_{2} \ : \ x_{n} \end{bmatrix}
\theta = \begin{bmatrix} \theta_{0} \ \theta_{1} \ \theta_{2} \ : \ \theta_{n} \end{bmatrix}
$$
這樣就可以直接使用$\theta^{T}x$來表示$y_{\theta}$了,其實都是一樣的,只是表示的形式變了一點點。
2. 梯度下降法
還是和之前一樣,求導,用梯度下降法更新參數,仍然是對各個$\theta_{i}$求偏導然後進行更新。
和之前一樣,如果這裡也想使用高次的多項式的話,也是一樣的,如可以寫這樣的一個多項式:$y_{\theta}=\theta_{3}x_{2}^{2}+\theta_{2}x_{2}+\theta_{1}x_{1}+\theta_{0}$
隨機梯度下降法
在使用之前的梯度下降法的時候,我們在更新參數的這個步驟中,是求了所有的樣本的預測值與真實值差的平方和,但是當樣本量巨大的時候,每一次都全都算的話計算量太大了,而且還會陷入局部最優的情況。因此,為了能夠解決這樣的問題,我們引入了隨機梯度下降法,顧名思義,就是隨機選擇一個樣本點來更新本次的參數,而不是使用全部的樣本點來進行更新,也就是說用之前的梯度下降更新一次參數的運算量(求n個差),隨機梯度下降法可以進行n次參數的更新了!速度大大提高!
可以實際的來看一下更新的表達式的變化:
梯度下降法:
$$
\theta_{i} = \theta_{i}-\eta \sum [(y_{\theta}-y)x]
$$
隨機梯度下降法:
$$
\theta_{i} = \theta_{i}-\eta (y_{\theta k}-y_{k})*x
$$
可以看到,唯一的區別就只是在於有沒有那個$\sum $,隨機梯度下降就只是隨機選一個樣本對所有的參數進行更新。
小批量(min-batch)梯度下降法
小批量梯度下降法介於梯度下降法與隨機梯度下降法之間,每次隨機選擇m個樣本對參數進行更新,更新表達式為:
$$
\theta_{i} = \theta_{i} – \eta \sum_{k}^{m} [(f_{\theta}(x{(k)})-y{(k)})x_{i}]
$$