MySQL體系結構概覽
- 2022 年 1 月 20 日
- 筆記
作者:IT王小二
部落格://itwxe.com
一條 SQL 語句在 MySQL 中怎麼執行的呢,這篇就來認識下 MySQL 的各個組件的作用。
一、結構組件
首先需要 MySQL 安裝的客官看這兩篇,小二演示使用的是 Docker 的安裝方式:
先上個圖,小二自己畫的,絕對的高清無碼,嘿嘿。不足之處歡迎指正哈。
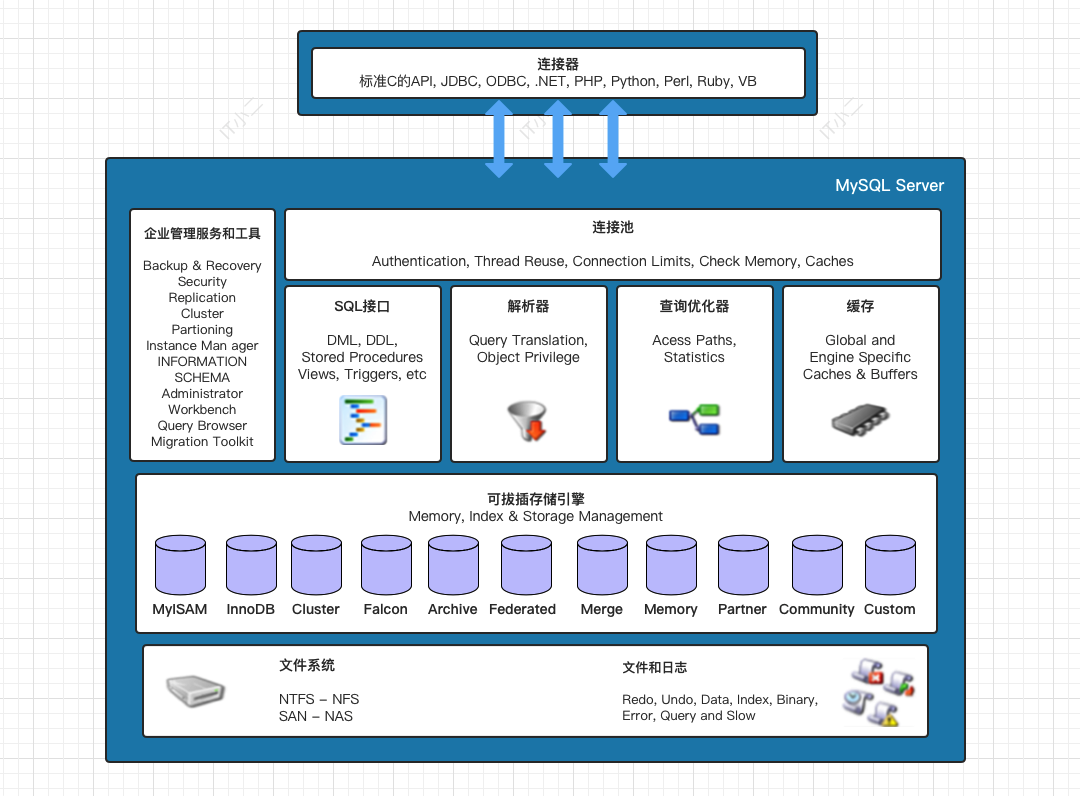
1. 企業管理服務和工具
系統管理和控制工具,例如 MySQL 備份恢復、MySQL 複製、MySQL 集群等工具。
2. 連接池
負責監聽對客戶端向 MySQL Server 端的各種請求,建立連接、許可權校驗、維持和管理連接,通訊方式是半雙工模式,數據可以雙向傳輸,但不能同時傳輸。
- 單工:數據單向發送。
- 半雙工:數據雙向傳輸,但不能同時傳輸。
- 全雙工:數據雙向傳輸,可以同時傳輸。
那麼 MySQL 是怎麼保存連接得嘞?
每個成功連接 MySQL Server 的客戶端請求都會創建或分配一個執行緒,在記憶體中分配一塊空間存儲對應的會話資訊,其中包含許可權等資訊,該執行緒負責客戶端與 MySQL Server 端的通訊,接收客戶端發送的命令,傳遞服務端的結果資訊等。
用戶的許可權表在系統表空間的 mysql 庫中的 user 表中,這就意味著,一個用戶成功建立連接後,即使你用管理員帳號對這個用戶的許可權做了修改,也不會影響已經存在連接的許可權。修改完成後,只有再新建的連接才會使用新的許可權設置。
一些有點用的命令。
MySQL 允許最大的連接數
show variables like '%max_connections%';

這個值可以在 my.cnf 文件中配置,Docker 安裝完 MySQL 版本為 5.7.36 默認值為 151 個最大允許連接數。
項目中可能會遇到 MySQL: ERROR 1040: Too many connections 的異常情況,造成這種情況的原因有兩個。
- 一種是 MySQL 配置文件中
max_connections值過小,可以在配置文件my.cnf中添加max_connections參數增大最大連接數,例如max_connections = 500。 - 一種是訪問量過高,MySQL 伺服器抗不住,這個時候就要考慮增加從伺服器分散讀壓力。
查詢當前 MySQL 伺服器接收所有的連接資訊
show processlist;
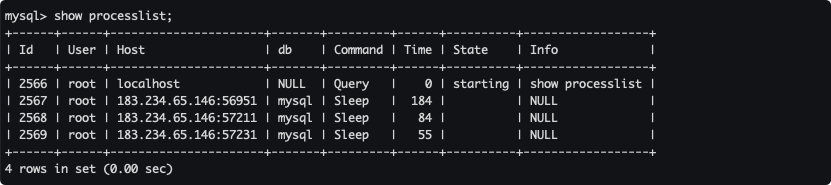
State 狀態常見的就是 Sleep 和 Query,詳解自行度娘、谷哥,一般也沒啥人看。
- Sleep:執行緒正在等待客戶端發送新的請求。
- Query:執行緒正在執行查詢或者正在將結果發送給客戶端。
資料庫閑置連接超時時間
#非互動式超時時間,如 JDBC 程式
show global variables like 'wait_timeout';
#互動式超時時間,如資料庫工具
show global variables like 'interactive_timeout';
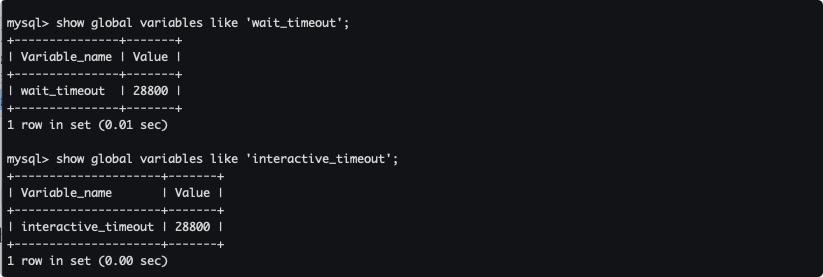
可以看到超時時間都是默認8小時,即當客戶端狀態連接後為 Sleep 的時候,如果8小時沒有收到請求那麼就會斷開連接。
MySQL狀態分析
show global status like 'Thread%';
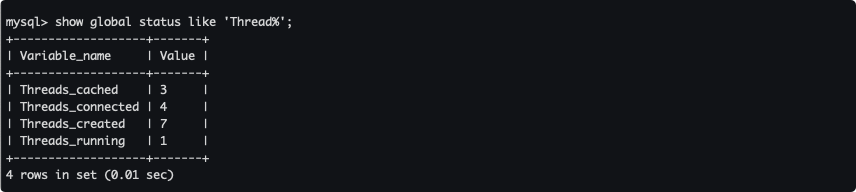
- Threads_cached:伺服器端快取連接
- Threads_connected:當前打開的連接數
- Threads_created:創建的執行緒數
- Threads_running:正在運行的執行緒
3. SQL介面
負責接收用戶 SQL 命令,如 DML,DDL 和存儲過程等,並將命令發送到其他部分,並接收其他部分返回的結果數據,將結果數據返回給客戶端。
關於這個組件小二也有點懵,那麼具體分發到哪些組件上面去了,翻了很多資料基本就是一句話解釋的,以後翻翻高性能 MySQL 看看有詳細描述沒~
4. 查詢快取
首先需要說明:在 MySQL8.0 中已經刪除了查詢快取,MySQL5.7 中仍然存在查詢快取。
如果開啟了 MySQL 快取的話,成功獲取一個 MySQL 連接後,會先到查詢快取看看,之前是不是執行過這條語句。
如果之前執行過,那麼這條語句及其結果可能會以 key-value 對的形式,被直接快取在記憶體中。key 是查詢的語句,value 是查詢的結果。如果查詢能夠直接在這個快取中找到 key,那麼這個 value 就會被直接返回給客戶端。
如果語句不在查詢快取中,就會繼續後面的執行階段,通過存儲引擎去查詢。執行完成後,執行結果會被存入查詢快取中。
如果命中快取的話那麼速度確實會很快,但是…但是…MySQL 的這個快取功能往往卻比較雞肋,為什麼這麼說呢?
涉及到快取,那當然就有和源數據保持一致性的問題,或者說同步的問題。
那麼想一想,MySQL 如果要保持查詢查詢快取數據結果的一致性,同時那個表經常性的更新數據,那麼每更新一條數據,MySQL 為了保持一致性就要把該表所有的 key 全部查詢一次,那麼對於一個頻繁更新的表來說那麼 MySQL 的壓力就太大了。
所以…,MySQL 選擇了最簡單粗暴的方式,如果該表一更新數據,就從查詢快取刪除該表所有的 key,即從查詢快取刪除不該表相關的所有查詢語句快取。
那麼既然說是雞肋,那當然還是有一點點用的,只要使用得當,那麼什麼場景下查詢快取可以發揮那麼一點點作用呢?
如果說在項目中不想引入 Redis,那麼這個查詢快取能不能在某些方面加快一些查詢速度呢,當然是可以的。
既然頻繁更新的表不適用查詢快取,那麼我們開發中幾個月才會更新一次的表不就正好合用嗎,例如常見的系統配置表、字典表等,同時 MySQL 也正好提供了按需使用的策略方式。
怎麼按需使用呢?
首先把查詢快取開啟按需配置,查詢 show global variables like "%query_cache_type%"; 如果結果為 OFF,那麼就需要在 MySQL 配置文件 my.cnf 中配置如下參數後重新啟動 MySQL 即可。
# 查詢快取開啟,OFF 關閉,ON 開啟
query_cache_type = ON
# 快取策略,0代表關閉查詢快取 OFF,1代表開啟 ON,2代表 DEMAND,DEMAND代表當sql語句中有SQL_CACHE 關鍵詞時才快取
query_cache_type=2
如果你和小二一樣的的方式安裝的 MySQL,docker 安裝默認沒有 my.cnf 文件的,那麼需要自己在 docker 映射目錄 /itwxe/dockerData/mysql/conf 下面創建文件 my.cnf,添加如下內容使用 docker restart mysql 重啟容器即可開啟查詢快取。
[mysqld]
query_cache_type = ON
query_cache_type = 2
添加 my.cnf 後重啟容器,登錄 MySQL 後可以看到查詢快取已經開起來了。

那麼接下來只需要在需要快取結果的查詢語句上面加上一個 SQL_CACHE 顯示指定即可,例如:
SELECT SQL_CACHE * FROM test_innodb WHERE id = 6;
查看一下快取的運行資訊。
show status like'%Qcache%';
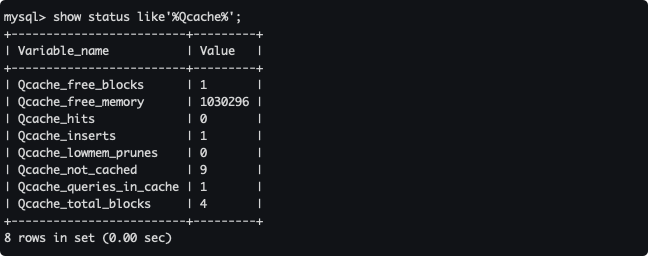
結果說明:
- Qcache_free_blocks:表示快取中相鄰記憶體塊的個數。數目大說明可能有碎片。
- Qcache_free_memory:查詢快取的記憶體大小,通過這個參數可以很清晰的知道當前系統的查詢記憶體是否夠用,是多了,還是不夠用,可以根據實際情況做出調整。預設從圖中可以看到默認大小為 1Mb(圖中以b為單位),可以在
my.cnf中通過query_cache_size = 20M指定快取大小。 - Qcache_hits:表示有多少次命中快取。
- Qcache_inserts:表示多少次未命中然後插入,意思是新的查詢 SQL 請求在快取中未找到,需要執行查詢處理,執行查詢處理後把結果 insert 到查詢快取中。
- Qcache_lowmem_prunes:該參數記錄有多少條查詢因為記憶體不足而被移除出查詢快取,通過這個值可以適當的調整快取大小。
- Qcache_not_cached:表示因為 query_cache_type 的設置而沒有被快取的查詢數量。
- Qcache_queries_in_cache:當前快取中快取的查詢數量。
- Qcache_total_blocks:快取中塊的數量。
各個參數和快取的效果可以多查詢幾遍試試就明白啦,雞肋還是有一點點用的,哈哈,當然你要是已經有了 Redis 等快取中間件就不需要查詢快取啦,同時 MySQL8.0 中也已經移除查詢快取功能。
5. 解析器
負責將接收到的 SQL 命令解析和驗證。解析器主要功能:
- 將 SQL 語句分解成數據結構,並將這個結構傳遞到後續步驟,以後 SQL 語句的傳遞和處理就是基於這個結構的。說人話就是將我們寫的 SQL 語句分解成 MySQL 認識的語法往下傳遞。
- 如果在分解構成中遇到錯誤,那麼就說明這個 sql 語句是不合理的。說人話就是看看我們寫的 SQL 語句有沒有語法錯誤。
6. 查詢優化器
負責 SQL 語句在查詢之前對查詢進行優化,這個過程會使用 optimizer trace 優化查詢 SQL,然後計算各種可以使用的索引和全表掃描的查詢成本相比較,選擇最優的查詢方式。
optimizer trace 工具會在後面的文章中說到,MySQL 到底通過什麼規則計算的查詢成本的,為什麼有時候明明有可以使用的索引最後還是走的全表掃描,在後面章節小二會提到哦,歡迎各位客官關注。
7. 可拔插存儲引擎
存儲引擎就是如何管理操作數據(存儲數據、更新數據、查詢數據等)的一種方法,當然在 MySQL 中。而可拔插就可以理解為 MySQL 提供了一個介面,只要遵循規則即可以自定義實現存儲引擎,Java中介面與實現類的關係。
8. 文件系統
文件系統主要是將資料庫的數據存儲在作業系統的文件系統之上,並完成與存儲引擎的交互。例如資料庫文件,表文件和各種日誌文件(bin log、redo log、undo log等)。
二、一條SQL語句的執行過程概覽
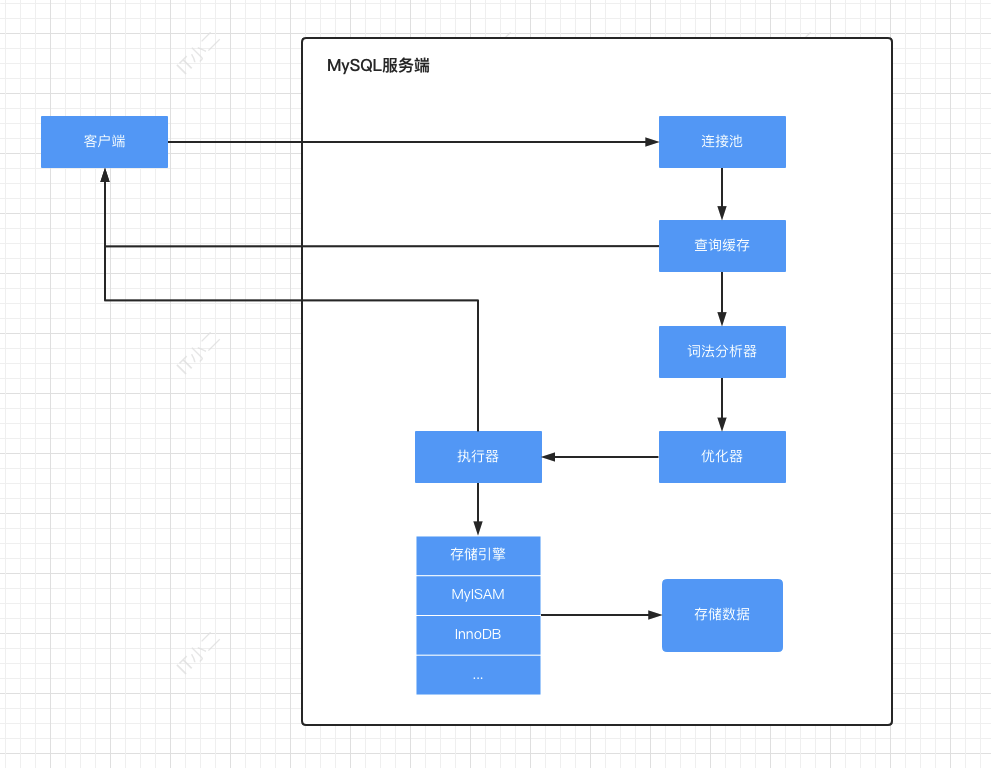
相信仔細看了查詢快取的都不會問小二為啥新增、修改、刪除都要走查詢快取了吧,嘿嘿。總覽到此結束,接下來下一篇就講講 Explain 執行計劃。
都讀到這裡了,來個 點贊、評論、關注、收藏 吧!

